LLM大模型:reasoning model没有思考能力,大模型泡沫破灭?
这轮AI热潮起于2022.10月chatGPT 3.5的发布,其智能程度颠覆了以往任何同类产品,一下就引爆了关注!后来持续迭代,又率先提出了COT的模式:在正式回答问题前先think一段,根据整个思考的过程再给出最终的答案,这就是o1;尽管LLM的效果是越来越好,但还是有人跳出来“唱反调”,吐槽LLM并不是真正的AGI,也无法通往AGI,这里面最出名的就是Yann LeCun了,他一针见血地指出:LLM本质就是个statistic model,完全没有人类的思考能力,即使加上了reinforcement learning(DPO/PPO/GRPO等),也只是增加了正确答案出现的概率(或则说是正确路径被采样的概率增加),但并未从根本上解决问题;对于Yann LeCun大佬的观点,我个人是认同的:transformer架构和以前的word2vector、RNN、LSTM相比,确实有breakthrough进展,核心的就是attention机制:通过计算token之间的距离作为weight,把前面token的value语义写入后续的token,由此得到了较为精准的语义表达,最终得到embedding!这种机制和人脑思考的完全不同,为了弥补hallucination等缺陷,又采取了多种reinforcement learning来弥补,性能确实有一定的提升,但还远未达到人类的智力水平,所以部分网友对于LLM的评价:创造力不足,但是记忆力好(训练预料的信息都被压缩到Nerual节点了嘛)!所以简单的问题可以找LLM提供答案,复杂的问题只能自己拆解成多个简单的问题,然后再让LLM回答了!所以LLM的能力边界到底在哪?
1、近日,apple研究人员发了一篇论文:The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity 通过设置不同复杂度的问题,测试出了reasoning model的Strengths和Limitations.
large reasoning model的训练,最常用的就是math和code数据集,用这两个也容易理解:结果好验证,reward信号很准确。但只用这两类数据,缺陷也是有的:
- pre-train的时候可能已经用过了测试的数据集,也就是data contamination,并且也没法控制环境的复杂度。model的思考过程cot有没有啥问题了,也没有很好地研究过;
-
model性能随着问题复杂度是怎么变化的?这种变化在reasoning和non-reasoning之间怎么区别?reasoning局限性在哪?想进一步提高的改进方向在哪?
-
reasoning是否有generalization的能力?或者说只是pattern matching?
先说第一个data contamination问题,对比如下:

- math-500:小学水平的数学题,比较简单,所以model是否thinking,是否reasoning的区别不大,性能几乎是一样的
- AIME24:高中奥数水平,较难;thinking的效果明显比no-thinking要好,gap还是很大的!
- AIME25:human performance是比AIME24好的,说明AIME25比AIME24要简单,但为啥thinking和no-thinking的gap居然变大了?按照在match-500上的经验,gap不应该变小么?可能是data contamination: LLM训练的时候使用了AIME24,但没使用过AIME 25,25的数据没泄露;
基于以上原因,研究reasoning的时候可以使用puzzle,好处在于:complexity复杂度是可以精准控制的,所以不用担心data contamination的问题!
2、hanoi tower问题都知道吧,尤其是计算机科班出身的人,在学递归编程时必学这个!hanoi最大的优点就是可以灵活、精准地控制复杂度:增加或减少disk的数量即可!

研究人员测试的结果展示如下:

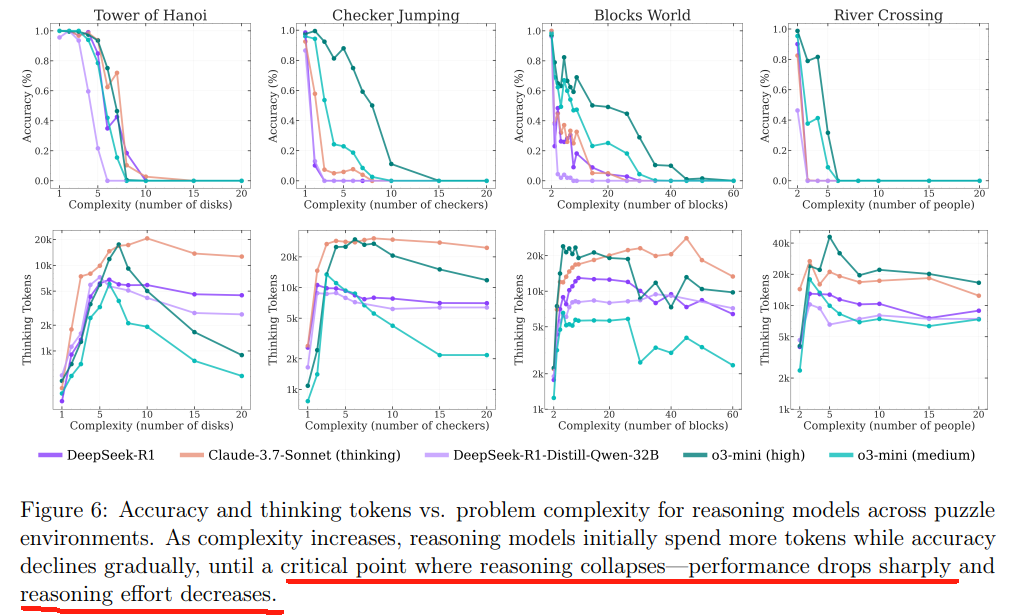
- 当disk数量<=3的时候,thinking和no-thinking的准确率是一样的,没任何区别;thinking的回答长度比no-thinking长很多,这里就有明显的over thinking了;再观察position within thoughts发现,在出现correction solutions时,token的position已经接近0.6了,也就是前面60%的token都是铺垫,直到60%的地方才出现correct答案,这也印证了现在的LLM有over thinking的毛病,这些问题耗费了大量算力,最终都肥了NVIDIA这类硬件厂家......
- 4=< disk <= 9的时候,thinking和no-thinking的准确率都断崖下跌,不过thinking的准确率任然好于no-thinking;然而thinking性能提升也是有代价的:response length也是成倍地增长!position within thoughts最高涨到了接近0.8,也就是说thinking产生的token,前面80%都没卵用,产生了大量的浪费.......
- disk>=10:这才是最炸裂的!复杂度达到一定程度是,是否thinking已经不重要了,因为准确率都一样啦,直接降到0,所以在position within thoughts中这段数据直接没啦!
这个测试说明:目前即使经过reinforcement learning训练后的LLM,在遇到非常复杂的任务时,准确率仍然很低,说明reinforcement learning的generalization能力有限!为了进一步证实这个猜想,研究人员还做了其他类型的puzzle,如下:

表现和hanio一样:复杂到一定程度后,thinking和non-thinking已经没本质区别了!也应证了上面的观点:任务复杂到一定程度,reinforcement learning也无力回天!
3、和上面的结论一下:简单环境下thinking和non-thinking没区别!复杂环境直接“躺平”不干了!只有在中间难度的环境下thinking比non-thinking有较大优势!

4、复杂度达到一定的threshold,model直接collapses!
5、总结:
- reinforcement learning不是万能的,但在media level下,thinking相比non-thinking还是有优势的!
- 虽说LLM不是人类的思维方式,但截止目前效果的提升是有目共睹的!人在遇到新问题时,第一反应就是回溯自己以前有没有遇到过类似的问题,从以前的经验中找答案,这不也是一种pattern matching么?不管LLM用哪种reasoning方式,只要效果好就行了嘛!
参考:
2、https://www.arxiv.org/abs/2506.06941 The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity
3、https://garymarcus.substack.com/p/a-knockout-blow-for-llms A knockout blow for LLMs?
4、https://www.anthropic.com/research/tracing-thoughts-language-model Tracing the thoughts of a large language model

 浙公网安备 33010602011771号
浙公网安备 33010602011771号