SHAP:以credit card fraud detection为例做anomaly detection可视化分析解释
之前做了bitcoin price预测的可视化解释,这次继续做个anomaly detection相关的业务,就用比较常见的信用卡欺诈检测啦,还是用天池上现成的数据集,如下:https://tianchi.aliyun.com/dataset/92665

这次用application_data来做测试,这是一个典型二分类数据集,target=1表示至少有一笔贷款逾期超过X天,target=0表示还未逾期!废话少说,直接上代码:
import pandas as pd import numpy as np import xgboost as xgb from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelEncoder import shap import matplotlib.pyplot as plt # 1. 数据加载与预处理 def load_and_preprocess_data(): df = pd.read_csv('application_data.csv') categorical_cols = df.select_dtypes(include=['object']).columns for col in categorical_cols: df[col] = df[col].fillna('Unknown').astype(str) le = LabelEncoder() df[col] = le.fit_transform(df[col]) df = df.fillna(df.median()) exclude_cols = ['SK_ID_CURR', 'TARGET'] features = [c for c in df.columns if c not in exclude_cols] X = df[features] y = df['TARGET'] return train_test_split(X, y, test_size=0.2, random_state=42) # 2. 模型训练 def train_model(X_train, y_train): model = xgb.XGBClassifier(n_estimators=200, max_depth=5, random_state=42) model.fit(X_train, y_train) return model # 3. SHAP解释器初始化 def initialize_shap_explainer(model, X_test): explainer = shap.TreeExplainer(model) shap_values = explainer(X_test) return explainer, shap_values # 4. 可视化函数集合 def plot_summary_bar(shap_values, X_test): shap.plots.bar(shap_values, show=False) plt.title("Feature Importance (Bar Plot)") plt.tight_layout() plt.savefig("summary_bar.png", dpi=300) plt.close() def plot_summary_detail(shap_values, X_test): shap.summary_plot(shap_values.values, X_test, show=False) plt.title("Feature Impact Distribution") plt.tight_layout() plt.savefig("summary_detail.png", dpi=300) plt.close() def plot_force_plot(explainer, shap_values, X_test, idx=0): plt.figure(figsize=(20, 4)) shap.plots.force(shap_values[idx], matplotlib=True, show=False) plt.title(f"Force Plot for Sample {idx}") plt.tight_layout() plt.savefig(f"force_plot_{idx}.png", dpi=300, bbox_inches='tight') plt.close() def plot_waterfall_plot(explainer, shap_values, idx=0): plt.figure(figsize=(10, 6)) shap.plots.waterfall(shap_values[idx], show=False) plt.title(f"Waterfall Plot for Sample {idx}") plt.tight_layout() plt.savefig(f"waterfall_plot_{idx}.png", dpi=300) plt.close() def plot_dependence_plots(shap_values, X_test, features=None): if features is None: features = X_test.columns[:5] for feature in features: shap.dependence_plot(feature, shap_values.values, X_test, show=False) plt.title(f"Dependence Plot: {feature}") plt.tight_layout() plt.savefig(f"dependence_{feature}.png", dpi=300) plt.close() def plot_heatmap(shap_values, X_test): # 只取前 2000 个样本用于绘图 subset_size = 2000 shap_values_subset = shap_values[:subset_size] # 特征排序 feature_order = np.argsort(np.abs(shap_values.values).mean(0))[::-1] # 绘图 shap.plots.heatmap( shap_values_subset, feature_order=feature_order, show=False ) plt.title(f"Heatmap (First {subset_size} Samples)") plt.tight_layout() plt.savefig("heatmap.png", dpi=300) plt.close() def plot_cohort_analysis(shap_values, X_test): """按收入分组的特征重要性对比""" # 创建收入分组(三分位数) income_groups = pd.qcut(X_test['AMT_INCOME_TOTAL'], q=3, labels=['Low', 'Medium', 'High']) # 修复:将布尔掩码转换为 NumPy 数组 for group in ['Low', 'Medium', 'High']: group_mask = (income_groups == group).values # 使用 .values 转换为 numpy array group_shap = shap_values[group_mask] plt.figure(figsize=(10, 6)) shap.plots.bar(group_shap, show=False) plt.title(f"Feature Importance for {group} Income Group") plt.tight_layout() plt.savefig(f"beeswarm_income_{group}.png", dpi=300) plt.close() def plot_interaction_values(explainer, X_test): # 直接获取交互作用值(避免使用 .cohorts()) interaction_values = explainer.shap_interaction_values(X_test[:100]) # 绘制交互作用图(注意参数顺序) shap.summary_plot( interaction_values, X_test[:100].values, feature_names=X_test.columns.tolist(), show=False ) plt.title("Feature Interaction Values") plt.tight_layout() plt.savefig("interaction_values.png", dpi=300) plt.close() def plot_partial_dependence(model, X_test): feature_names = X_test.columns.tolist() explainer = shap.TreeExplainer(model) shap_values = explainer(X_test) shap.partial_dependence_plot( feature_names[0], model.predict, X_test, feature_expected_value=True, show=False ) plt.title(f"Partial Dependence: {feature_names[0]}") plt.tight_layout() plt.savefig("partial_dependence.png", dpi=300) plt.close() def plot_beeswarm_plot(shap_values): # 新版蜂群图直接传入 Explanation 对象 shap.plots.beeswarm( shap_values, max_display=10, # 显示最重要的前10个特征 show=False ) plt.title("Beeswarm Plot") plt.tight_layout() plt.savefig("beeswarm_plot.png", dpi=300) plt.close() # 5. 执行所有可视化 def run_all_visualizations(): X_train, X_test, y_train, y_test = load_and_preprocess_data() model = train_model(X_train, y_train) explainer, shap_values = initialize_shap_explainer(model, X_test) plot_summary_bar(shap_values, X_test) plot_summary_detail(shap_values, X_test) plot_force_plot(explainer, shap_values, X_test, idx=0) plot_waterfall_plot(explainer, shap_values, idx=0) plot_dependence_plots(shap_values, X_test) plot_cohort_analysis(shap_values, X_test) plot_interaction_values(explainer, X_test) plot_partial_dependence(model, X_test) plot_beeswarm_plot(shap_values) plot_heatmap(shap_values, X_test) # 主程序入口 if __name__ == "__main__": run_all_visualizations()
这里一口气展示10张图,挨个详细分析credit fraude的可视化分析解释!
1、先看最重要的:feather importance,如下:

影响力最大的两个特征是外部评分,这个分数具体是怎么得到的原作者并未说明,只能顺数看后续的feather:
- AMT_GOODS_PRICE:消费贷中商品价格;价格越高,需要贷款的金额越多,逾期还不上的风险越大?比如房贷这类大宗贷款;
- AMT_CREDIT:贷款金额,同上:金额越大,还款压力越大,逾期还不上的压力也就越大!
- DAYS_EMPLOYED:客户当前工作的开始时间;越长说明收入越高,还款压力越小,逾期的风险越小
与之对应的还有另外一个heatmap:这里抽样了2000个样本,每个样本的每个feather的SHAP值大小展示如下:

越红说明该feather的值越容易导致target=1,也就是违约;越蓝说明越安全,不容易违约;从上图可以看到:source3、source2、GOODS_PRICE、CREDIT、source1这几个特征蓝色和红色的块明显比其他特征多,说明这几个特征的区分度很大,所以明显更重要!
2、 上面只展示了特征的重要性,这些特征的影响到底是正面的还是负面的?注意:因为target=1代表逾期违约,所以SHAP值越大,说明逾期违约概率越大;SHAR值越小(越负),违约的概率越低,方向别搞反了!
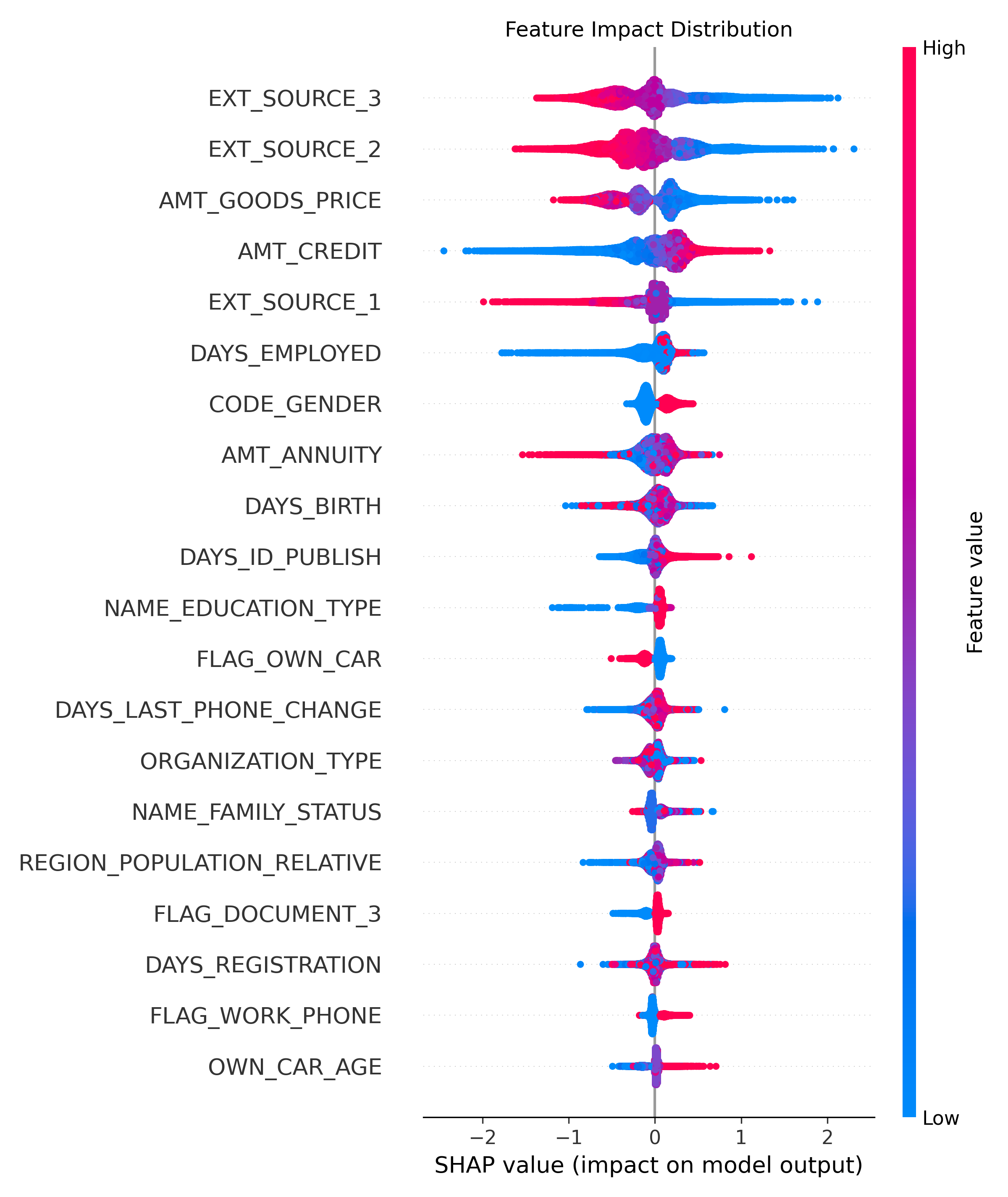
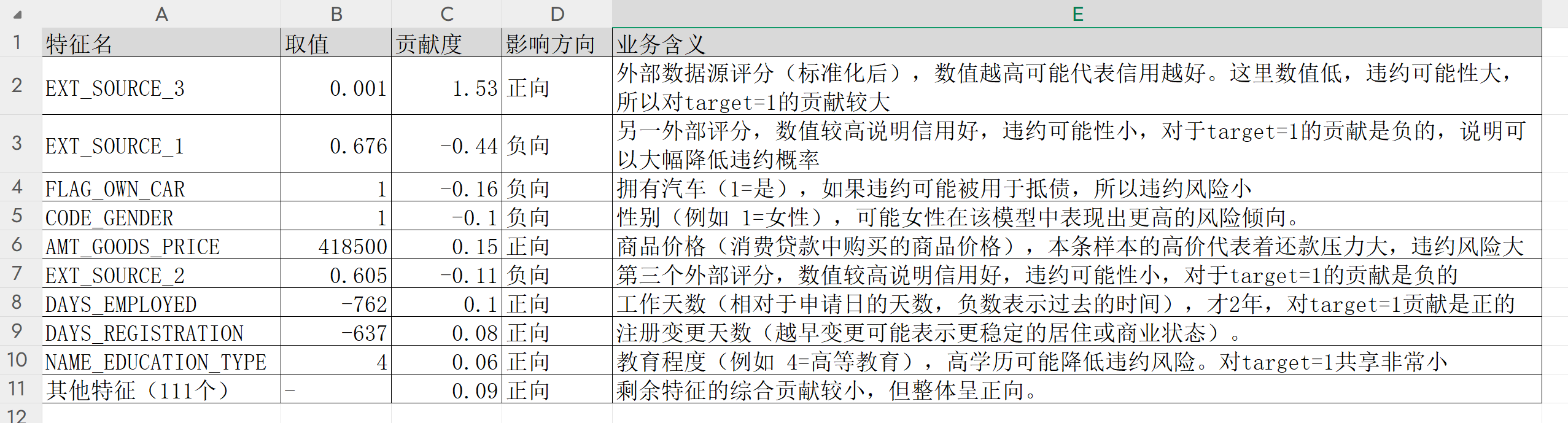
- 前面两个特征:外部的评分,特征值越高(红色),SHAP 负影响力越大,说明违约的概率越低! AMT_GOODS_PRICE:该特征可能是一个关键的转折点特征,其值的变化会对模型预测结果产生较大波动;
- 低贷款金额(蓝色) :小额度商品贷款可能被视为高风险(如短期周转困难),或则被贷款客户滥用,导致模型预测违约概率升高(负向影响)。
- 高贷款金额(红色) :大额度商品贷款可能对应更严格的审核流程或优质客户群体,导致模型预测违约概率降低(正向影响),典型的比如房贷、车贷;
- AMT_CREDIT:特征值越高(红色),SHAP 值越低,表明该特征对模型预测结果的负向贡献越大。贷款金额越大,越容易逾期!反之,越低越不容易逾期!
- DAYS_EMPLOYED:相对于申请日的天数,负数表示过去的时间;工作时间越长(负数越小),违约概率越低!
- AMT_ANNUITY:每期偿还的金额越大,违约的概率越低,可能是因为贷款年限低?或者说大金额代码审核严格,都是优质客户?
3、WaterFall Plot:单条数据是怎么影响最终结果的了?如下:展示了每个特征如何累加影响最终预测值(f(x) = -1.114)
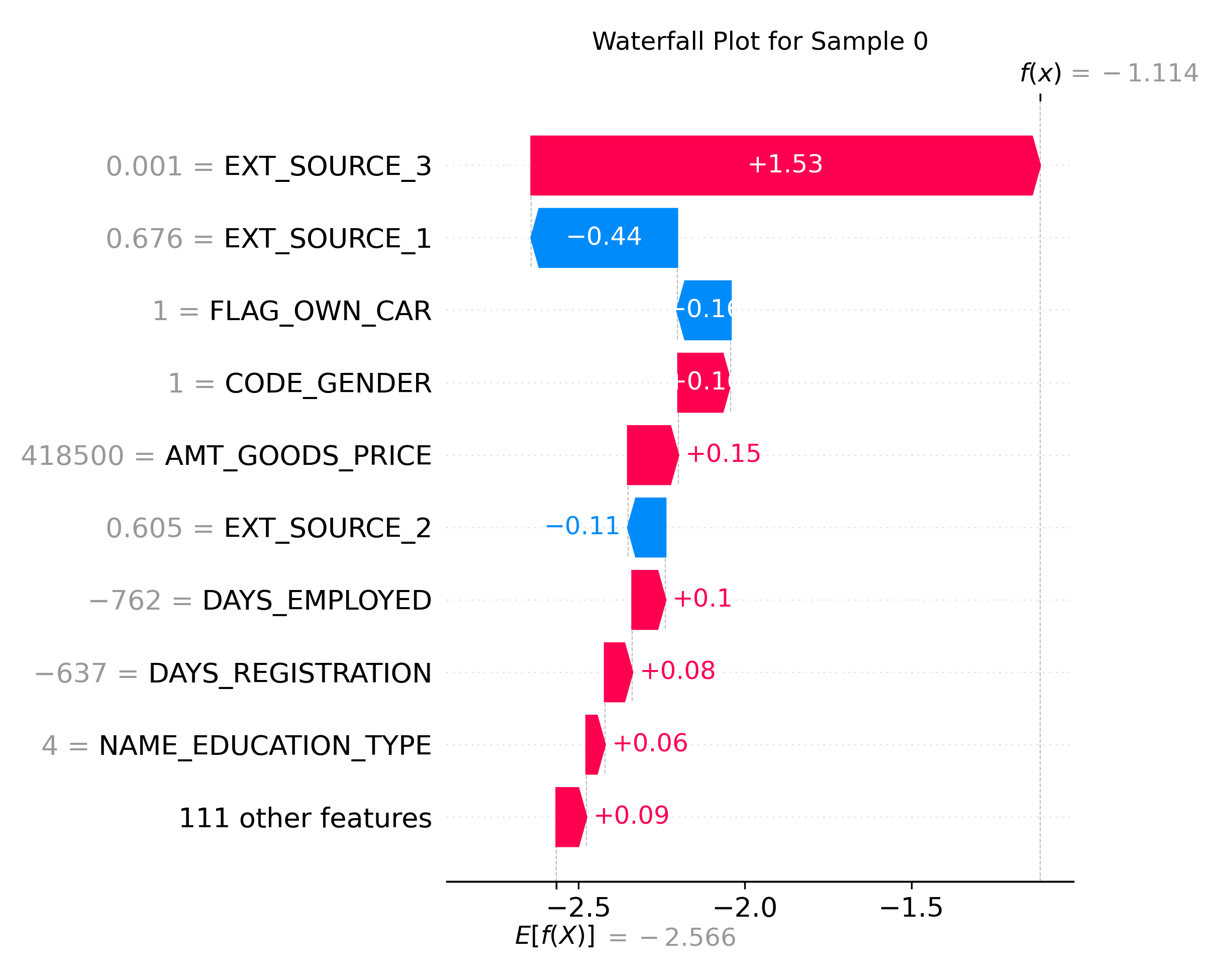
每个值对最终结果的影响力度:
4、依赖图:
(1)CHILDREN和住宅面积的依赖:
- 横轴:CNT_CHILDREN家庭小孩数量,最多有12个小孩的!
- 纵轴:
- SHAP Value:小孩数量对结果的影响;越红违约概率越高!
- toal area amound:家庭住宅面积大小

- CNT_CHILDREN=0或1时,住宅面积越大,违约概率越低(下面红色多,上面蓝色多),可能是因为有房产抵押,所以不敢随意违约?
- CNT_CHILDREN=2时,住宅面积越大,违约概率越大(上面红色点明显比下面多),是因为养小孩太过于烧钱,经济压力太大导致的?
- CNT_CHILDREN=3或4时,住宅面积大或小对于违约的概率接近,要结合其他feather派判断了!
(2)GENDER和age的依赖关系:

- gender = 0的时候,age大的违约概率小;age小的大约有一半概率违约
- gender=1的时候,age大的违约概率大,age小的大约一半概率违约
(3)NAME_CONTRACT_TYPE贷款类型和贷款年金之间的依赖关系:
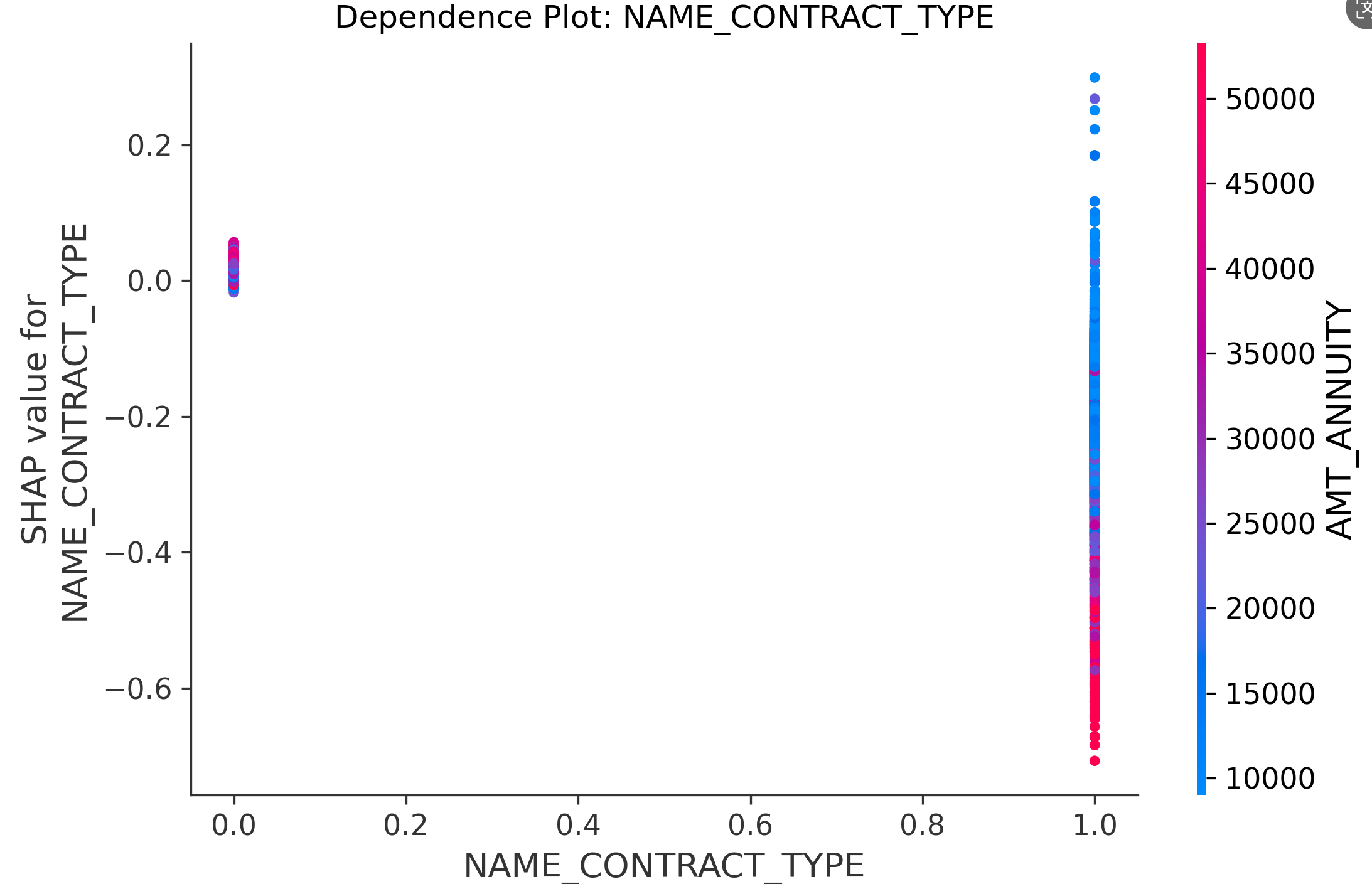
- 贷款类型=0的用户,不论ANNUITY大小,SHAP值集中在0附近,说明这部分用户是否违约是不受ANNUITY影响的!
- 贷款类型=1的用户,ANNUITY>35000(鲜红)的SHAP全是负的,违约概率很低!ANNUITY<15000(湛蓝)的,SHAP值正负都有,几乎对称,所以违约概率大概一半!
参考:
1、https://www.bilibili.com/video/BV1vcJVzZEz3/?spm_id_from=333.1007.tianma.45-2-176.click&vd_source=241a5bcb1c13e6828e519dd1f78f35b2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号