SHAP:以bitcoin price预测为例的机器学习算法可视化解析
1、传统机器学习按照目标划分,无非就是两种:分类、回归;不论是哪种,对于业务部门来说都有一大“硬伤”:可解释性!本人以前在某厂数据运营部做数据相关工作,平日里一大痛点:需要给业务人员做各种解释!比如使用xgboost发现某个账号被盗用的风险较大,提交运营人员后,别人会反问:为啥这个账号风险大?总要给个合理的说法吧!如果直接冻结客户资金,人家不投诉才怪了!所以传统机器学习最重要的一点:结果的可解释性!包括但不限于:
- 特征维度那么多,哪些维度对结果的影响是最大的?
- 影响大的维度中,哪些是正面影响?哪些是负面影响?
- 单条数据的判定结果中,哪些因素对结果是正面影响?负面影响?
- 这么多的影响因素,哪些是线性的?哪些是非线性的?
- 灵魂拷问:需要站在业务角度:
- 为啥客户的账号风险大?
- 为啥这个客户流失的风险大?
- 为啥这笔支付是违法犯罪的?
- 为啥客户点击这个广告的概率大?
.............................................
所以对于机器学习判定的结果,可解释性是非常重要的!
2、SHAP 库官网的介绍: SHAP (SHapley Additive exPlanations) is a game theoretic approach to explain the output of any machine learning model. It connects optimal credit allocation with local explanations using the classic Shapley values from game theory and their related extensions (see papers for details and citations). 在SHAP库中,特征筛选的核心原理是通过计算每个特征的Shapley值,从而评估其对模型预测的贡献度;具体的公式如下:

这个公式可以反应sharpley值对最终预测结果的影响度!最核心的就是shapley值的计算了,公式如下:

公式的含义是:遍历所有不包含特征 i 的特征子集 S,计算该特征在这些子集中的边际贡献,并按照权重进行加权平均 。说人话:如果不包含特征i,结果预测的准不准?如果不准,说明特征i非常重要,这一点也可以从梯度下降来验证:某个特征做loss的时候能让梯度急剧下降,loss明显减少,说明是非常明显的!举个例子:一个数据集有10个特征维度x1~x10,为了区分哪些特征维度重要与否,先不使用x1,只使用x2~x10,看看预测误差是多少;再加上x1特征,再看看预测误差是多少,就能知道x1特征的重要性了!比如没用x1特征,loss误差是100;使用了x1特征,loss误差大幅减小到30,说明x1的作用是非常明显的!但是如果使用x1后loss误差只减少到95,说明x1的作用不明显!
3、实际操作SHAP也简单,直接调用现成的接口就行了;这里使用阿里云天池提供的bitcoin样本数据bitcoin_dataset.csv,是bitcoin的价格和对应的特征属性。部分列的说明:
- btc_market_price:bitcoin每日价格
- btc_total_bitcoins:流通中的bitcoin总量
- btc_market_cap:bitcoin总市值
- btc_trade_volume:bitcoin每日的交易量
- btc_blocks_size:当天生成的所有bitcoin区块的总大小
...........
数据集下载地方:https://tianchi.aliyun.com/dataset/90319 这里还有bitcoin很多其他相关数据集,我这里暂时用这个最大的做测试!
废话少说,直接上代码:
import pandas as pd import numpy as np import xgboost as xgb from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error import shap import matplotlib.pyplot as plt # 1. 数据加载与预处理 def load_data(path): df = pd.read_csv(path, parse_dates=['Date']) # 基础特征工程 df['Date'] = pd.to_datetime(df['Date']) df['day_of_week'] = df['Date'].dt.dayofweek df['month'] = df['Date'].dt.month # 移除目标变量 X = df.drop(['btc_market_price', 'Date'], axis=1) y = df['btc_market_price'] return X, y # 2. 模型训练 def train_model(X, y): # 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=42) # 训练XGBoost模型 model = xgb.XGBRegressor( n_estimators=200, max_depth=5, learning_rate=0.1, subsample=0.8, colsample_bytree=0.7, random_state=42 ) model.fit(X_train, y_train) # 评估模型 y_pred = model.predict(X_test) rmse = np.sqrt(mean_squared_error(y_test, y_pred)) print(f"Model RMSE: {rmse:.2f}") return model, X_train, X_test # 3. SHAP解释 def explain_model(model, X_train, X_test): explainer = shap.Explainer(model) shap_values = explainer(X_test) return explainer, shap_values # 4. 特征重要性排序图 def plot_feature_importance(shap_values, X_train): plt.figure(figsize=(10, 6)) shap.summary_plot(shap_values.values, X_train, plot_type="bar", show=False) plt.title("Feature Importance Ranking") plt.tight_layout() plt.savefig("feature_importance.png", dpi=300) plt.show() # 5. 特征效果分布图(Beeswarm) def plot_beeswarm(shap_values, X_data): plt.figure(figsize=(10, 6)) shap.summary_plot(shap_values.values, X_data, show=False) # 使用与SHAP值对应的特征数据 plt.title("Feature Effects Distribution") plt.tight_layout() plt.savefig("beeswarm_plot.png", dpi=300) plt.show() # 6. 单样本预测解释 def plot_force_plot(explainer, shap_values, X_test, idx=0): plt.figure(figsize=(20, 4)) shap.force_plot( explainer.expected_value, shap_values[idx].values, X_test.iloc[idx], matplotlib=True, show=False ) plt.title(f"Force Plot for Sample {idx}") plt.tight_layout() plt.savefig(f"force_plot_{idx}.png", dpi=300) plt.close() # 7. 依赖图分析 def plot_dependence_plots(shap_values, X_train): features = ['btc_total_bitcoins', 'btc_market_cap', 'btc_trade_volume', 'btc_miners_revenue'] for feature in features: plt.figure(figsize=(8, 6)) shap.dependence_plot( feature, shap_values.values, X_train, interaction_index="auto", show=False ) plt.title(f"Dependence Plot for {feature}") plt.tight_layout() plt.savefig(f"dependence_plot_{feature}.png", dpi=300) plt.close() # 8. 交互效应分析(补充重要指标) def plot_interaction_effects(shap_values, X_train): # 市值与交易量的交互效应 plt.figure(figsize=(8, 6)) shap.dependence_plot( "btc_market_cap", shap_values.values, X_train, interaction_index="btc_trade_volume", show=False ) plt.title("Market Cap vs Trade Volume Interaction") plt.tight_layout() plt.savefig("interaction_marketcap_volume.png", dpi=300) plt.close() # 主流程执行 if __name__ == "__main__": # 数据路径修改为你的实际路径 data_path = "bitcoin_dataset.csv" # 加载数据 X, y = load_data(data_path) # 训练模型 model, X_train, X_test = train_model(X, y) # SHAP解释 explainer, shap_values = explain_model(model, X_train, X_test) # 可视化分析 - 所有图表使用对应的数据 plot_feature_importance(shap_values, X_test) plot_beeswarm(shap_values, X_test) plot_force_plot(explainer, shap_values, X_test, idx=0) plot_dependence_plots(shap_values, X_test) plot_interaction_effects(shap_values, X_test) # 如果需要训练集上的SHAP值 train_shap_values = explainer(X_train) plot_beeswarm(train_shap_values, X_train) # 分析训练集特征影响 print(f"SHAP values shape: {shap_values.values.shape}") print(f"Features shape: {X_test.shape}") # 应输出相同的第一维度(样本数):SHAP values shape: (n_samples, n_features)
代码整体的思路很简单:先做预处理,把数据集划分成train和test,然后训练xgboost模型,最后用test数据集测试;完成这一系列后就是本次的重点了:上各种图标!
(1) feather importance:特征的重要性,筛选出对结果影响最重要的特征,如下图:
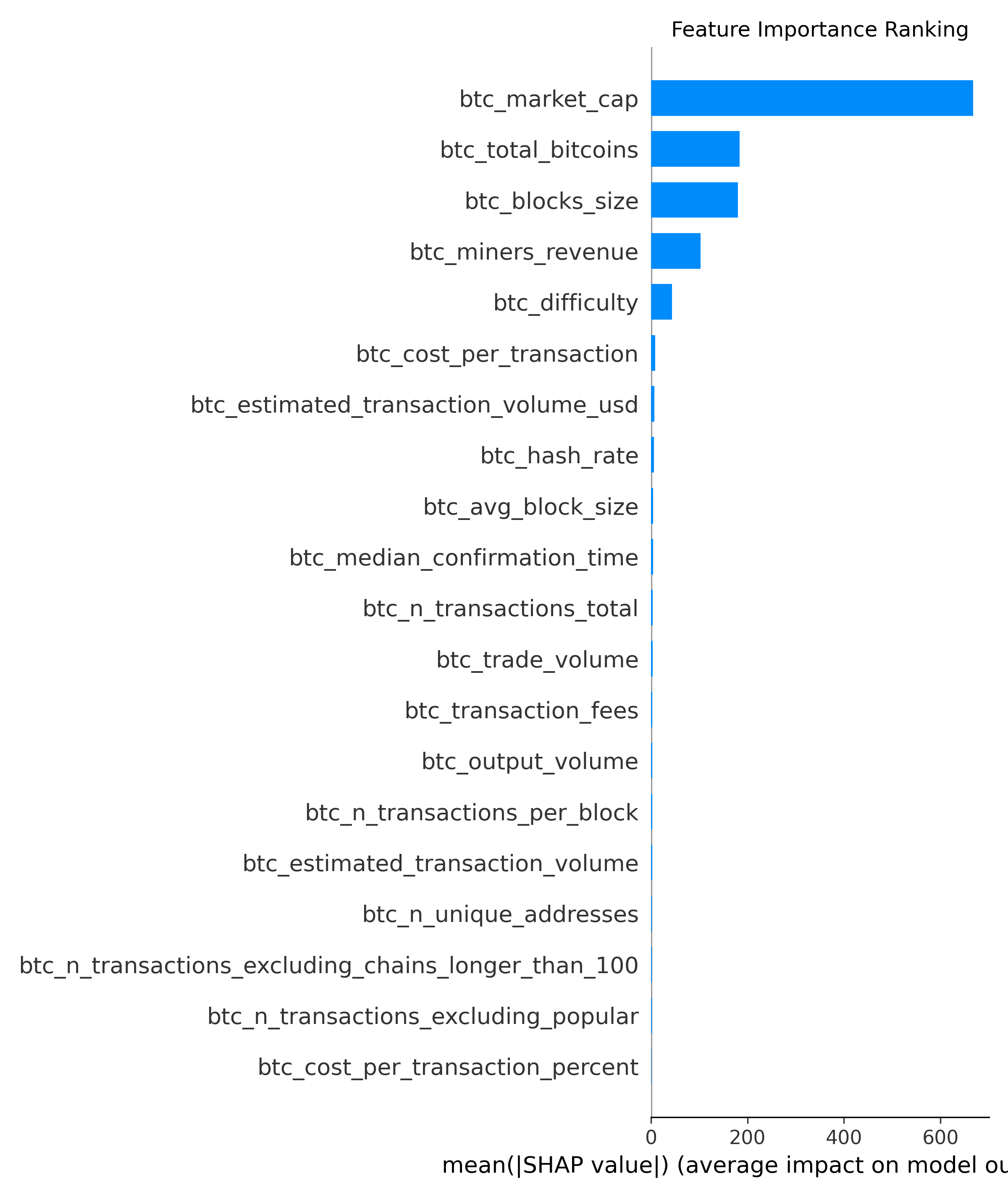
从图示看,对bitcoin price影响最大的几个特征:
- btc_market_cap:bitcoin总市值,这个数值越大,说明参与bitcoin交易的资金越多,自然price也就越高!不过我觉得这个因子和bitcoin价格的相关性很强,但并不是因果:比如cap大,price自然高! price高,cap自然大!所以用cap指标预测price我个人觉得不靠谱!
- btc_total_bitcoins:流通中bitcoin的总数,个人觉得是市场活跃度的体现;
- btc_blocks_size:当天生成的所有bitcoin区块的总大小,也是市场活跃度的体现;较大的block能记录更多交易,提升市场活跃度,进而推高价格!
- btc_miners_revenue:矿工的收入,这个和price也是强相关的,但并不一定是因果关系!price高,手续费就高,矿工收入自然就高;矿工收入高,挖矿更积极,产生的block也多,更利于记账,直接促进交易!
- btc_difficultly:挖矿难度,越难产出的bitcoin越少,导致bitcoin越珍贵???
(2) 上面梳理了importance feather,但这些feather对结果是正面作用,还是负面作用了?继续看 Beeswarm 图,如下:
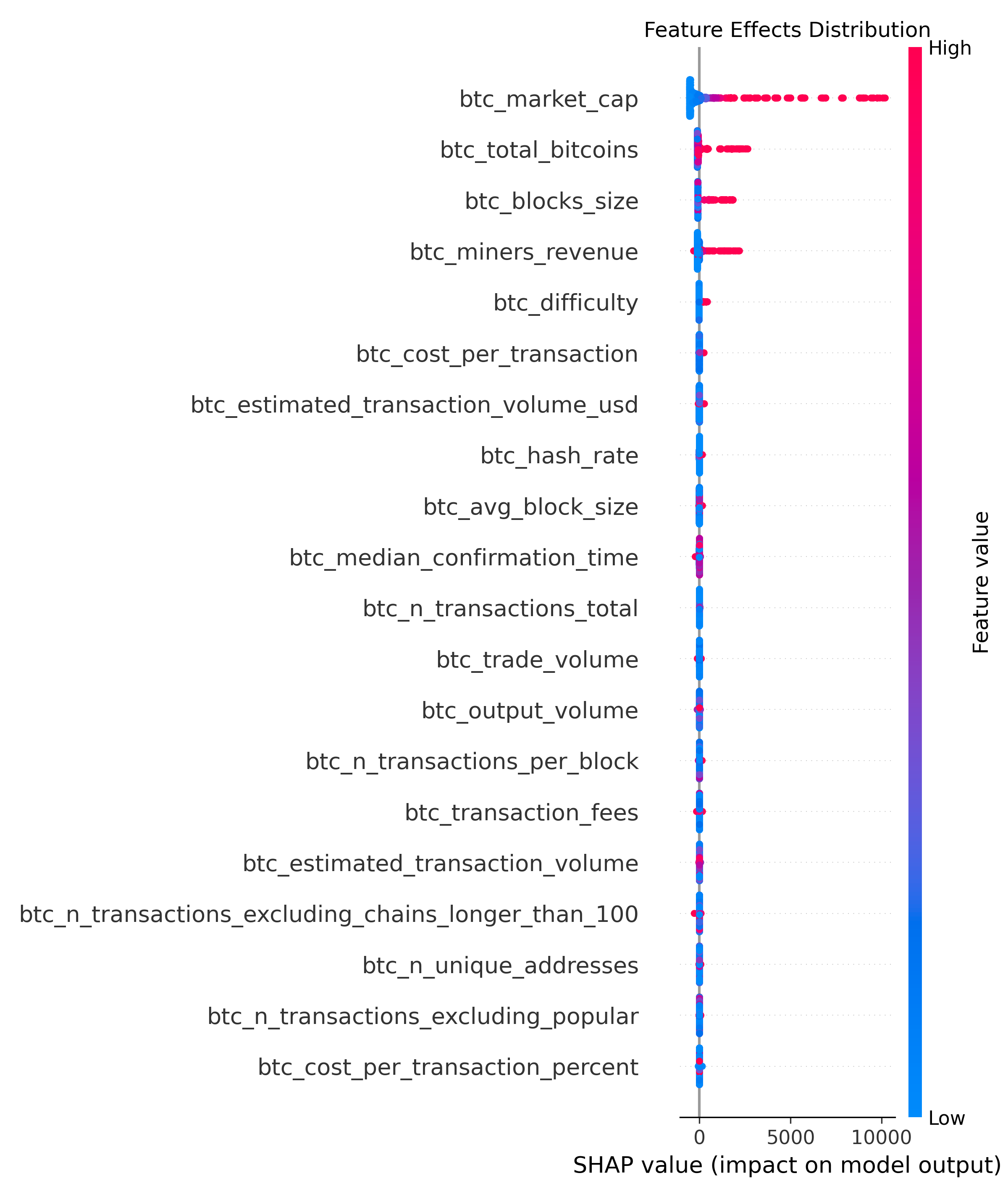
横轴(SHAP Value)表示每个特征对模型预测结果的贡献值(SHAP 值);红色是影响大的点,蓝色是影响低的点。越往左正面影响越大,越往右负面影响越大!
- btc_market_cap:大部分点是红色的,而且特别靠左,说明大部分点对price是正面影响的!
- btc_total_bitcoins、btc_blocks_size、btc_miners_revenue等同上:红色的点比较靠左,说明SHAP值较大,对结果正面影响较大!
- btc_difficultly:红色的非常少,大部分是蓝色,说明是负相关的,可能是挖矿太难,参与者少,进而降低价格!
(3)对于单个样本,比如预测出price是1w,那么这个值是怎么得出来的?哪些因子又直接影响这个值了?这次就看force plot了!红色表示正向贡献,蓝色表示负向贡献,长度代表影响大小!

block_size、total_bitcoins、miner_revenue等负面影响最大!正面影响的因子几乎为0;可能是:
- block_size:当天所有block_size平均大小较小,能记录的交易数量少,影响了市场活跃度
- total_bitcoins:流通的bitcoins多了,price降低
- miner_revenue:矿工收入低,影响积极性,间接降低price
(4)dependency依赖分析:下图表展示了比特币的总供应量 (btc_total_bitcoins) 对模型预测结果(即比bitcoin_price)的影响,通过 SHAP 值来衡量。同时,右侧的颜色条表示了另一个特征 btc_market_cap 的取值范围,用于观察其与 btc_total_bitcoins 的交互效应。
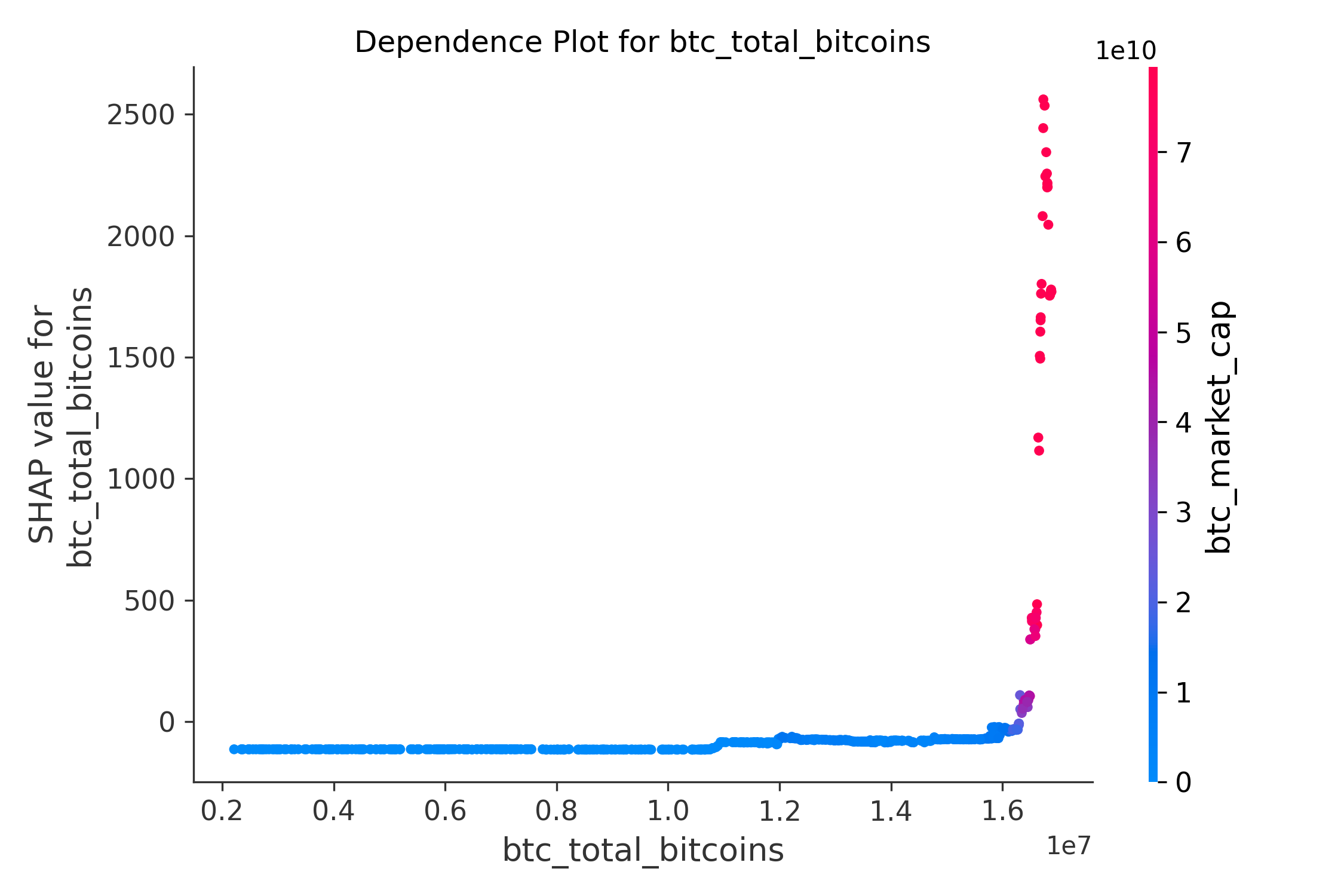
- 横轴左侧的蓝色点集中分布在 SHAP 值接近 0 的区域,表明总供应量较低时,对模型预测结果的影响较小;这可能是因为市场初期,比特币的总供应量较少,市场整体活跃度较低,价格波动主要受其他因素(如交易量、哈希率等)驱动
- 横轴右侧的红色点集中在较高的 SHAP 值区域,表明总供应量较高时,对模型预测结果的正向推动作用显著增强(这里有个明显的接近90度直线拉升);这可能是因为随着bitcoin的普及和总供应量的增加,市场流动性增强,市值也随之增长,进一步推动价格上涨
(5)interaction 因子之间交互分析
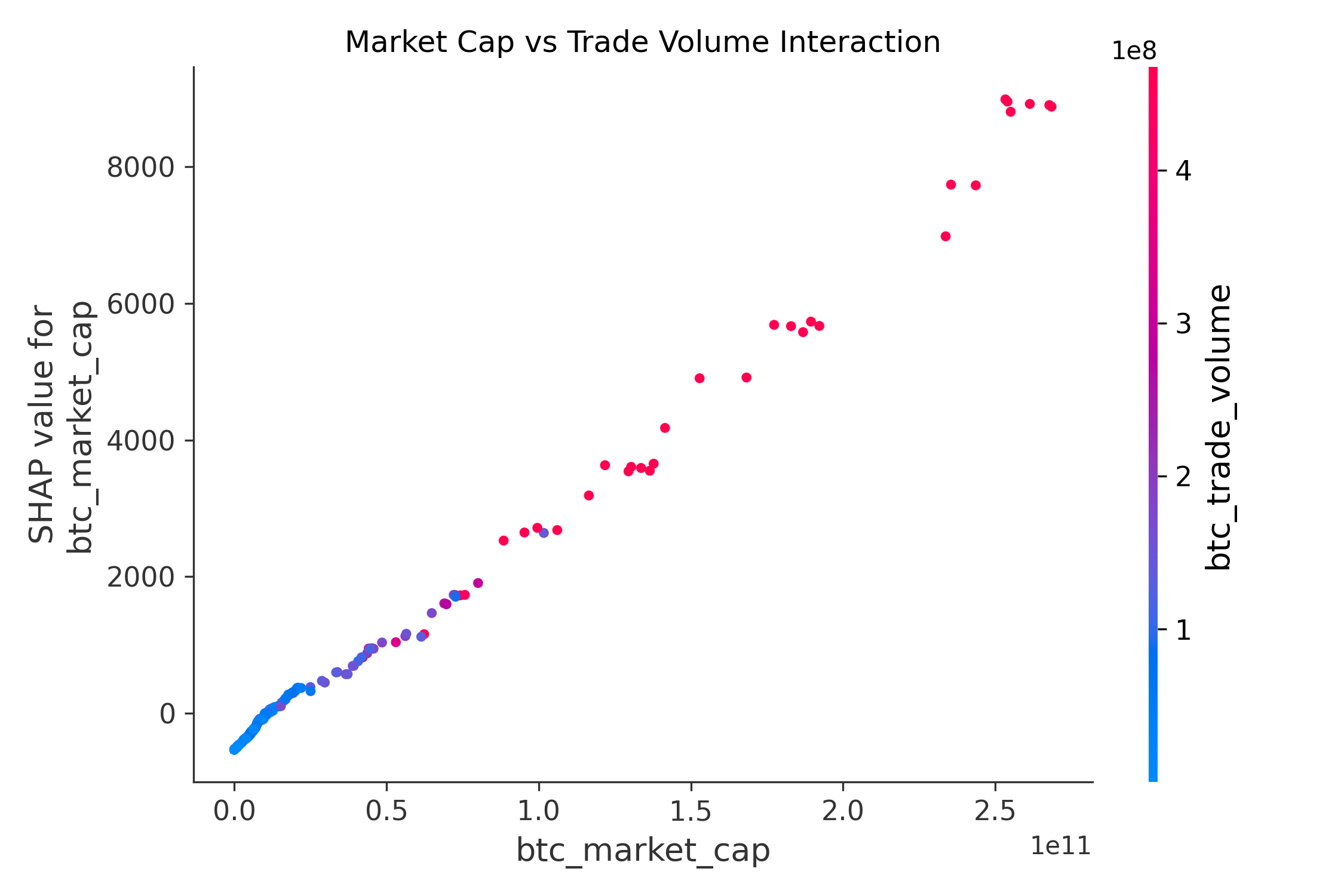
- cap越高,SHAP 值越大,说明对price的正向贡献越大。
- 在相同的cap下,交易量较高的样本(红色点)往往具有更高的 SHAP 值,说明高交易量放大了市值对价格的正向影响。 结论 :交易量在一定程度上增强了市值对价格的影响力。
- 当cap较低时(横轴左侧),SHAP 值较小,且cap的影响相对不显著(颜色变化不大);这表明在低市值阶段,市场整体活跃度较低,交易量对价格的影响较弱
- 总结:bitcoin的cap是影响价格的主要因素,cap越高,对价格的正向推动作用越强;trade volume 在cap的基础上起到了调节作用,高交易量进一步增强了市值对价格的正向影响
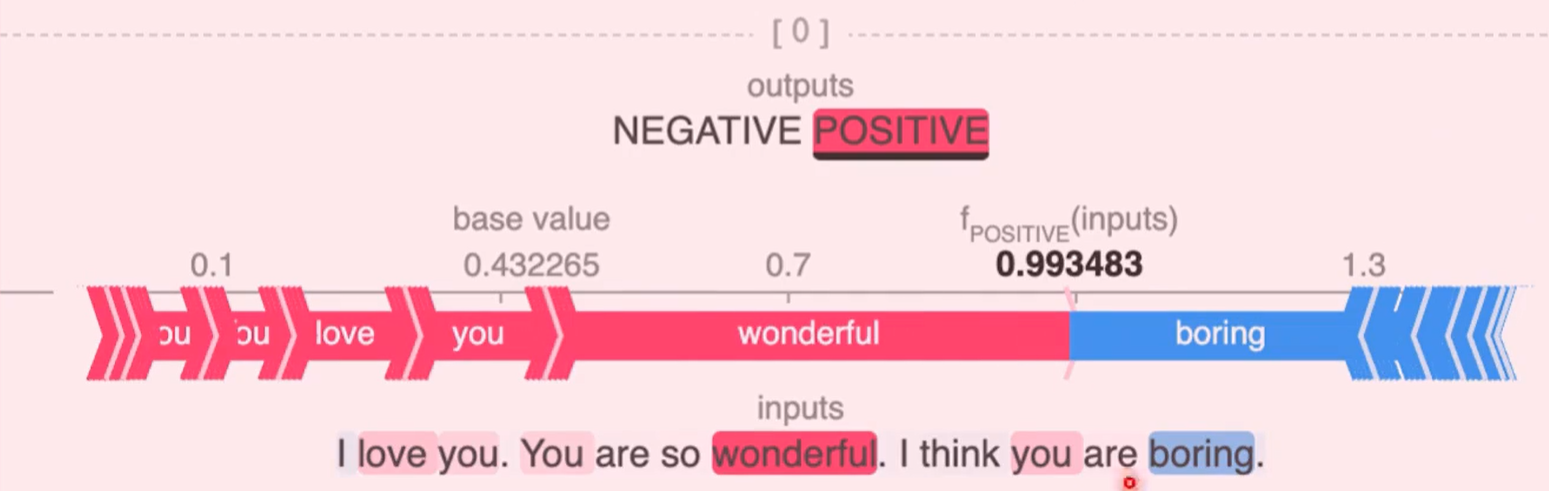
4、上面以bitcoin price为例说明SHAP可视化解释的案例;事实上,除了传统的机器学习模型,SHAP也能解释近几年最火爆的LLM,例如: 某些token的正负面情绪!
参考:
1、https://tianchi.aliyun.com/dataset/ 天池数据集
https://tianchi.aliyun.com/dataset/90319
2、https://cloud.tencent.com/developer/article/2356269 机器学习可解释性神器shap入门
3、https://shap.readthedocs.io/en/latest/ Welcome to the SHAP documentation

 浙公网安备 33010602011771号
浙公网安备 33010602011771号