LLM大模型:Qwen3解析
5.1除了deepseek-prover-v2发布,Qwen也发布了3版本,官方展示的性能对比测试如下:
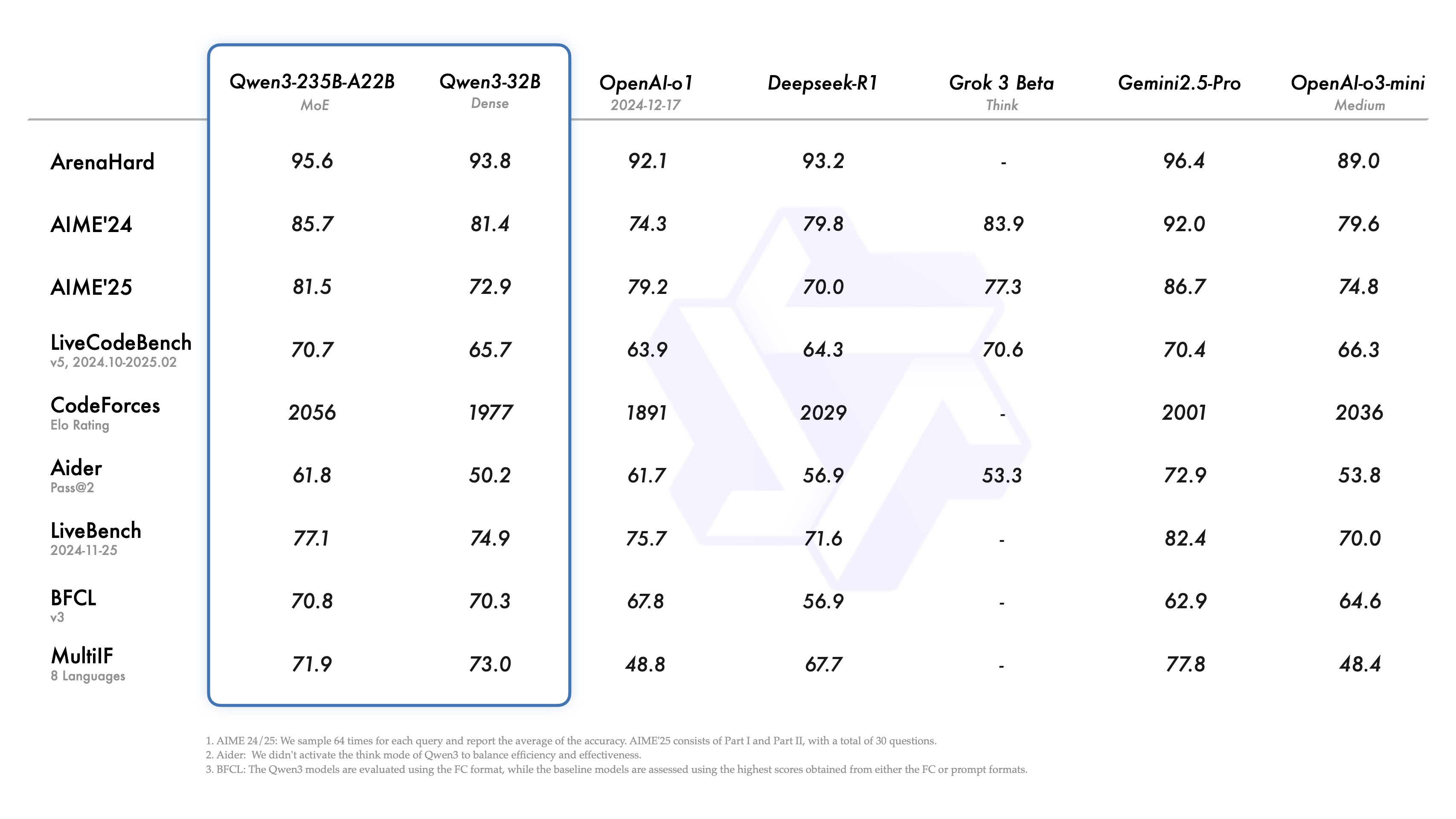
既然是官方发布的,效果肯定比友商的好,否则没必要发布出来了!那么灵魂拷问又来了:这么好的性能是怎么来的?大模型性能决定要素:
- 算力:迭代次数多,性能明显好
- 数据:互联网高质量数据筛选
- 网络架构:核心是做feather engineing
- transformer从架构上讲,并不具备人一样的思考能力;本质就是个统计模型,根据上文预测next token符号;transformer架构带来的技术红利已经接近尾声!换句话说,模型的性能已经接近天花板,后续要重点发力基于agent的各种应用了!
- 训练方式:SFT、RL、指令遵循、格式遵循
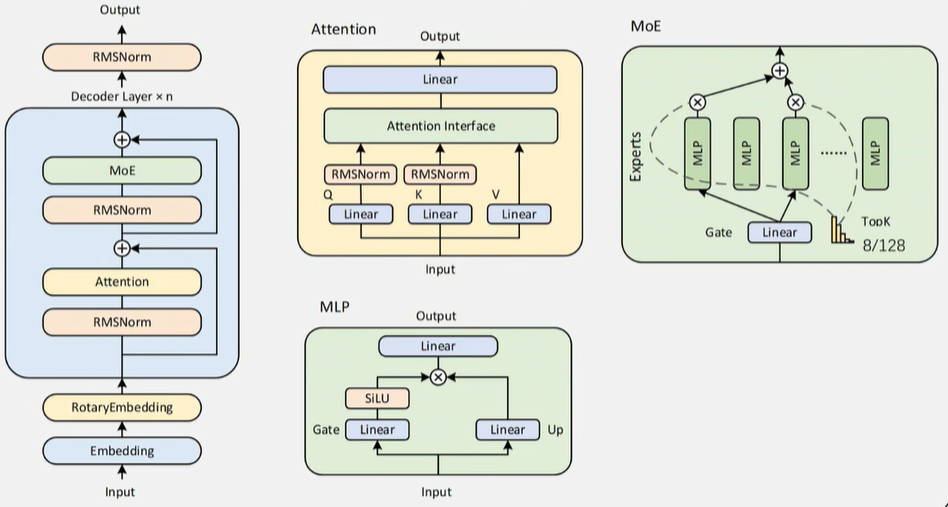
1、(1)网络架构:目前市面上主流LLM任然采取的是transformer架构,暂时没发现一款大规模商用的LLM采用manba架构的。Qwen3仍然采用的是经典的transformer架构,但是如果完全使用原始的transformer,模型在性能上怎么超过友商了?所以经典的transformer架构必须要更改!Qwen是这么干的:
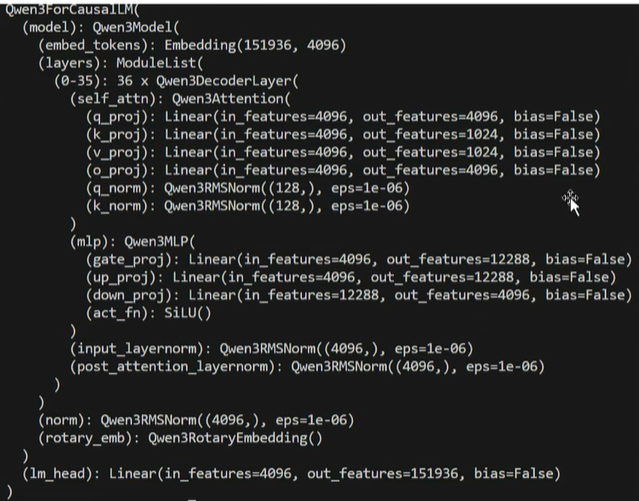
上面这个看着有点抽象,换个图就容易理解了:
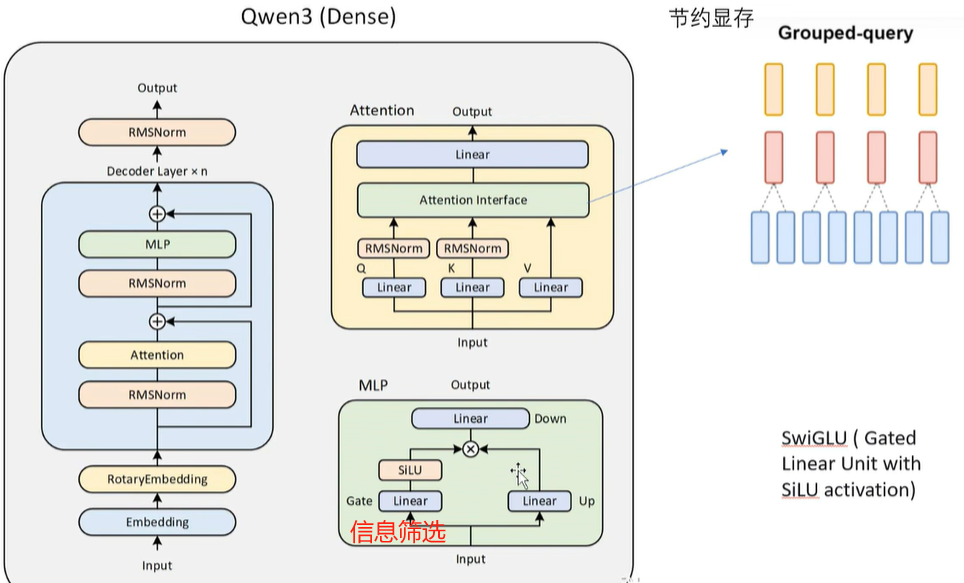
网络结构主要的改进点:
- attention层:
- 使用了grouped query attention:主要是节约显存
- Q和K做attention前分别做了RMSNorm:分别做归一化,主要是为了后续梯度下降时快速收敛,避免来回震荡
- MLP层:经典的MLP就是多层全连接,但这里明显多了linear层,核心目的是做信息筛选(通过乘以矩阵过滤某些不重要的信息),所以取名Gate。经过Gate后才是相乘来融合信息,最终再经过linear降维进入output
(2) LLM已经火了2.5年啦,chat功能已经非常成熟,头部厂商之间怎么拉开差距了?agent是下一个非常重要的结点!只有对agent支持非常好的model才能在激烈的竞争中脱颖而出,所以支持long-context的LLM就有优势了,Qwen3对context长度的支持如下:
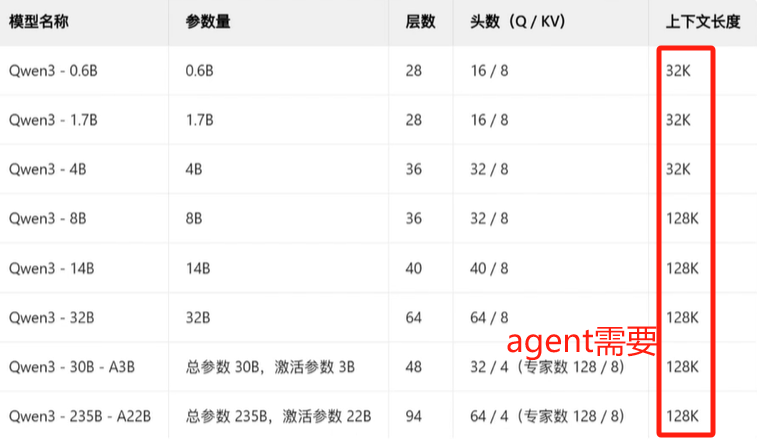
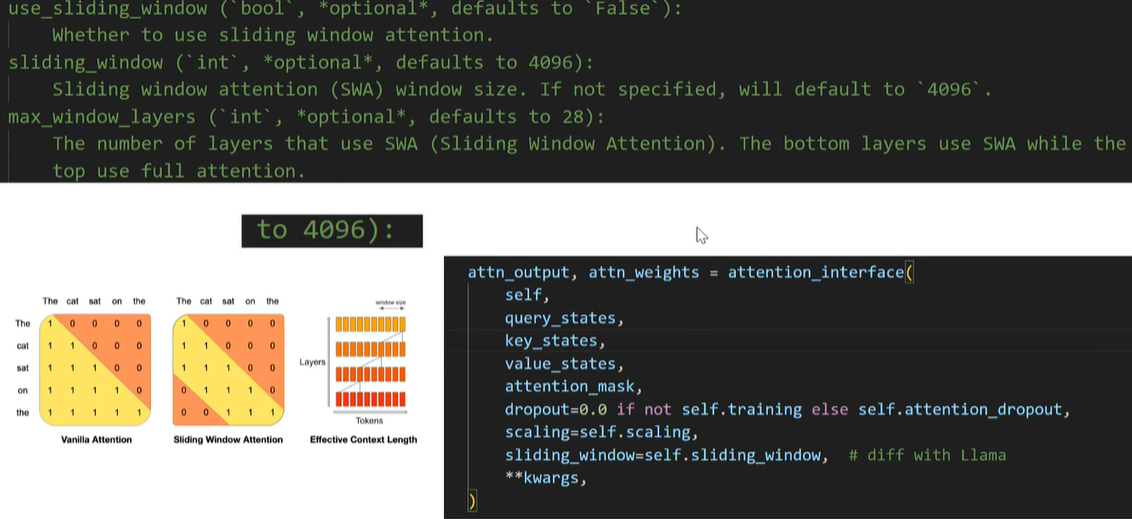
最长已经到128K了,这么长的context,attention怎么做?attention的算法是找到距离接近的token,然后把value按照weight比例加过来,核心目的做信息融合:距离近的value多融合一些,距离远的就少融合一些;从业务上讲意义接近的token之间的距离不会太远,比如几十万字的书,某个章节内部的token之间距离较近,章节之间的token距离不会那么近了,所以站在业务角度:短距离内的token再计算相似度就行了,距离太远其实已经没啥业务关联了,没必要做attention!按照这个思路,Qwen3把attention的距离缩短到了4096个,也就是4k的距离,使用的是sliding windows实现的,图示如下:
(3)大参数model还是用MOE,推理的时候选择top 8个expert计算:
2、 网络架构定了,数据了?主要来自这么几类:
-
网络爬取的高质量文本;LLM火了2年多,互联网上肯定充斥着大量的AI写作内容,这些AI生成的内容perplexity不高,多样性肯定不如人工写的内容,所以质量肯定不如人工的高,工程上要想办法区分开来,否则model训练肯定受影响!
-
使用awen2.5-VL从PDF文档中提取的内容:这是个多模态的model,应该是从图片提取文本
-
由Qwen2.5-Math和awen2.5-Coder合成的专业领域数据:
- LLM最核心的竞争力之一就是推理能力了!要想推理能力强,必然要使用大量逻辑严密的数据训练,刚好math、code就是逻辑要求最严格的细分领域!
- math、code的结果很好验证,非常适合RL训练
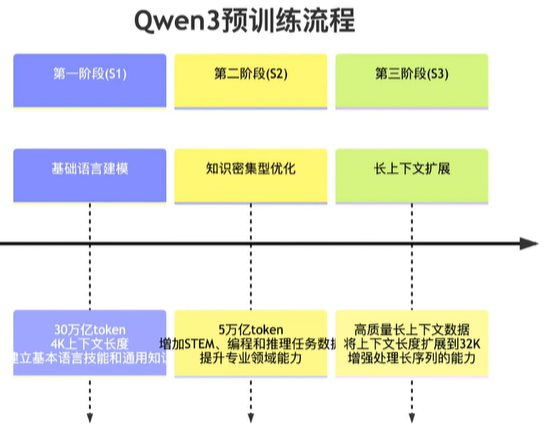
pre-train 3个阶段的训练流程和对应数据情况:
3、数据准备妥当后,就要train了;总所周知,LLM目前train的范式分别是pre-train、post-train;pre-train没啥说的,核心是post-train了,一般先做SFT,再做RL;Qwen3也不例外,也是这个套路,不过因为需求多样,post-train做了4个阶段:
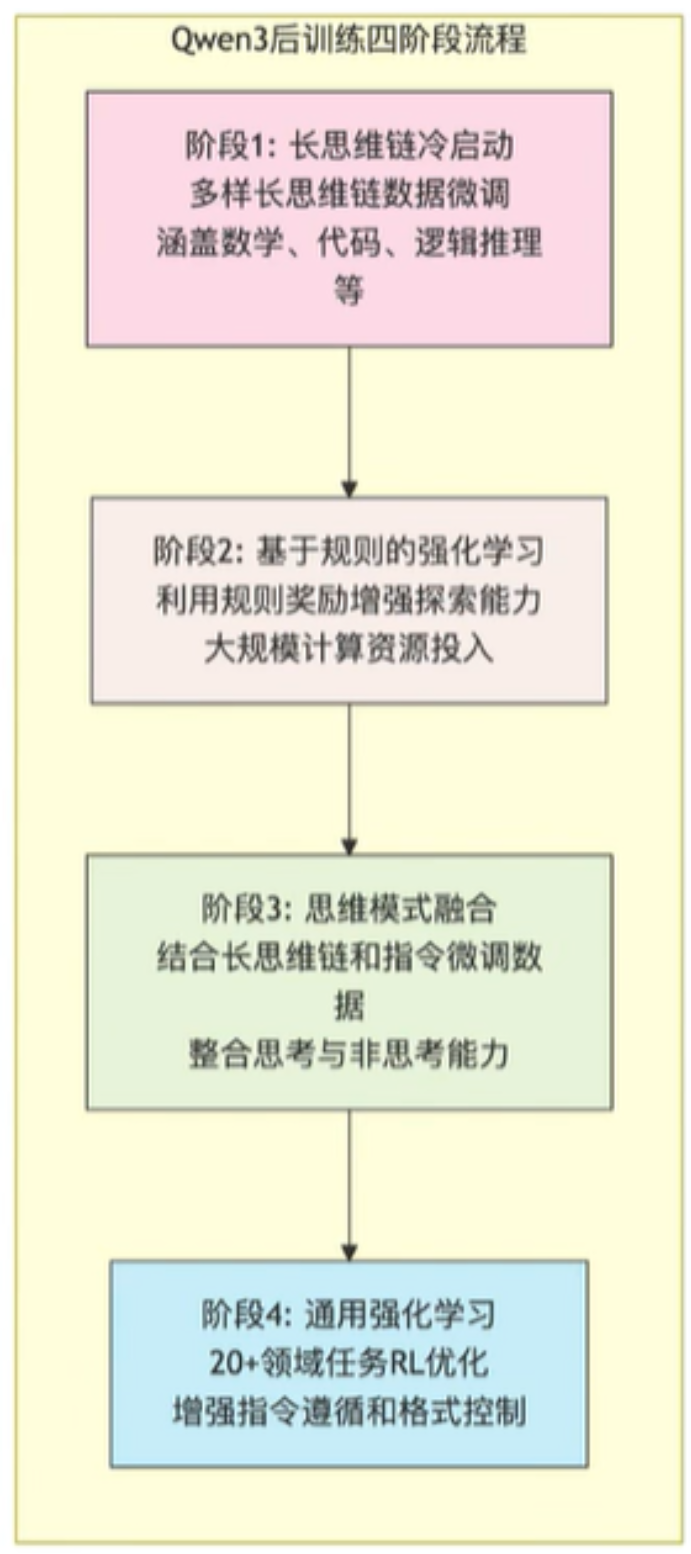
- 阶段1:使用math、code、long-cot、STEM等问题做SFT,让model具备这些领域的知识,配备基础的推理能力
- 阶段2:做大规模的RL,利用基于规则(code、math等很容易判断对错)的reward让model做大量的exploration,提升其探索、专研能力
- 阶段3:在一份包括long-cot数据和常用的instruction数据的组合数据上对模型进行微调,将非思考模式整合到思考模型中,确保了推理和快速响应能力的无缝结合。
- 并不是所有的问题都要深度思考,比如用户问1+1等于多少?这种简单问题还做long-cot这种思考推理那就是浪费用户时间和自己的算力;所以也要用一些non-cot数据训练,让model学会快速响应和回复!
- 阶段4:在包括指令遵循、格式遵循和Agent 能力等在内的 20 多个通用领域的任务上应用了RL,以进一步增强模型的通用能力并纠正不良行为。
- 让model严格遵循指令输出response,比如输出json格式的数据;或则按照agent的需求输出结果,所以这一步需要加强训练,以便输出的格式符合预期!
大模型训练完后,为了方便不同层级和场景的用户使用,需要蒸馏成不同的尺寸,概括一下整个train和distillation的过程,如下:
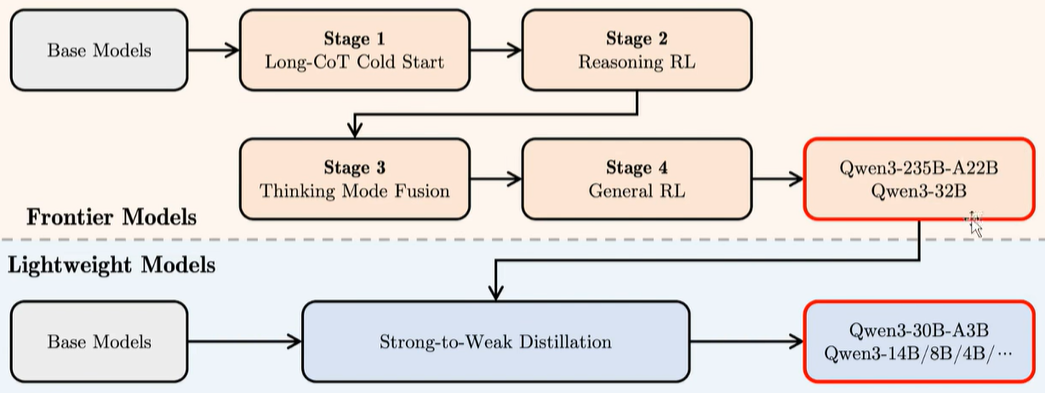
frontier models经过pre-train和4和阶段的post-train后,得到了大参数模型,然后通过distillation得到一系列不同参数的小模型!
4、Qwen3还有一个明显的特点是支持两种不同的思考模式:
- 思考模式:在这种模式下,模型会逐步推理,经过深思熟虑后给出最终答案。这种方法非常适合需要深入思考的复杂问题。
- 非思考模式:在此模式中,模型提供快速、近乎即时的响应,适用于那些对速度要求高于深度的简单问题:自动带上think标签,并且标签里面是空的;
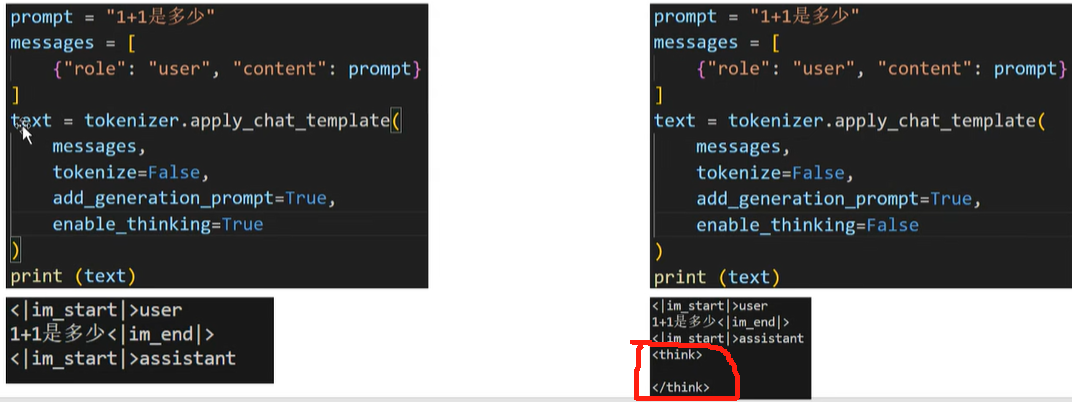
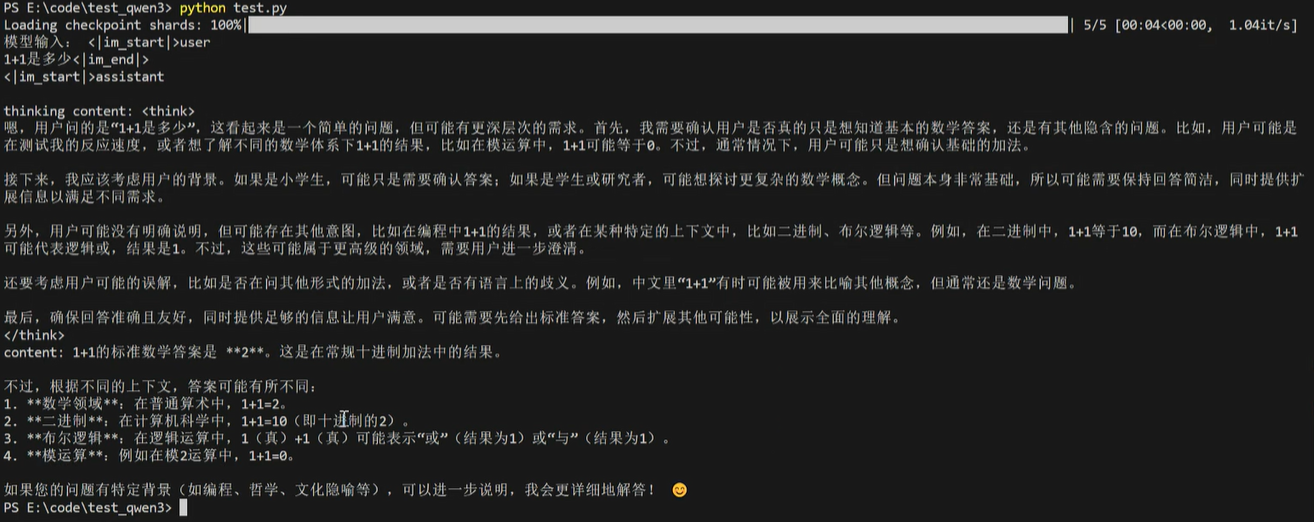
两种不同的思考模式直接通过设置enable_thinking参数即可!如果不需要思考,prompt直接加上<think></think>标签作为pre-fill,让model认为think阶段已经结束,直接输出结果;如果需要思考,prompt完全不加上<think></think>标签,model回答的时候发现没有think过程,自动补上这个过程,所以控制是否思考就是在prompt加上think标签即可!这么做主要还是依赖model的指令遵从能力, 也就是在post-train的阶段4训练得到的能力!RL的时候如果model没有按照要求输出标签,reward设置为负数;如果按要求输出,reward就是正数,多迭代几次,model就学会了遵从指令,按照要求判断是否输出think标签!思考模式下回答问题的格式:先是think标签展示推理过程,然后是最终的结果!
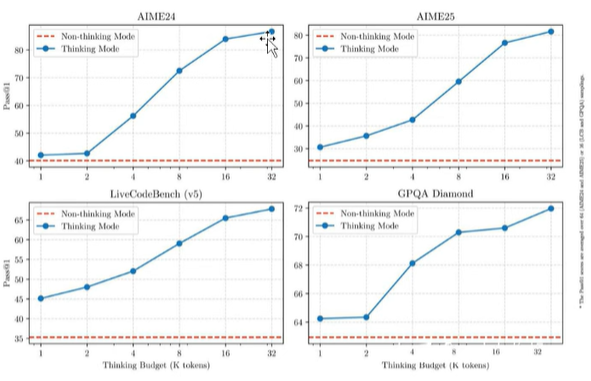
官方披露的数据来看:thinking model的token多,性能明显高很多!
参考:
2、https://github.com/QwenLM/Qwen3
3、https://qwenlm.github.io/blog/qwen3/
4、https://qwen.readthedocs.io/en/latest/getting_started/quickstart.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号