LLM大模型:TTRL: Test-Time Reinforcement Learning分析
1、现在大模型在pre-train完成后,肯定还要做post-train,主要目的是学会chat,并且对齐人类的偏好,主要方式就是SFT和RL,详见:https://www.cnblogs.com/theseventhson/p/18760256;做LLM,有三大要素:算力、算法、token数据了!算力本质是财力,有钱啥都能买到!算法就是网络结构,目前最流行的还是transformer架构(后续会不会被manba替代?),剩下的就是token数据了!post-train阶段非常耗费人力、时间的就是标记数据了!为了节约数据标注的成本,很多主流的LLM都采用模型自己迭代生成数据训练自己的方式,这种方式最早是google在2022年提出来的:LARGE LANGUAGE MODELS CAN SELF-IMPROVE,被成为Pseudo-Labeling!大概的思路如下:
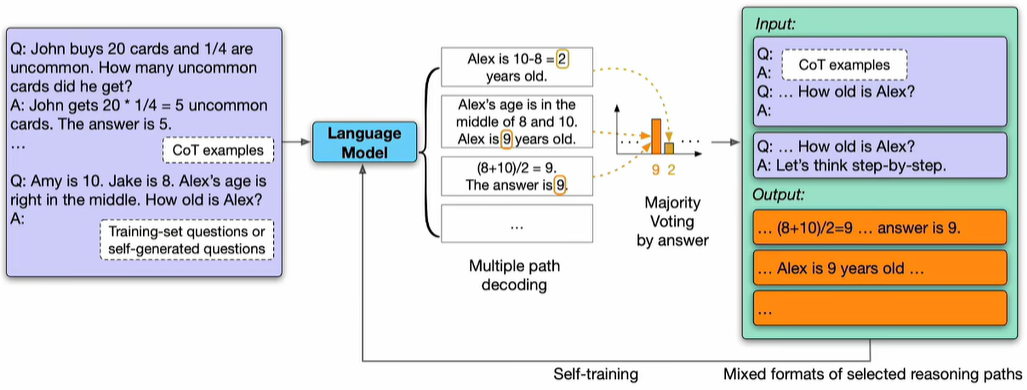
怎么样,整个过程简单吧,这就是所谓的self-training。不过这里用的是supervised fine-tuning,还没做RL!这种self-training“左脚踩右脚”一直做循环迭代下去结果会怎样了?如果每次迭代性能都会提升,最终岂不是能让模型的性能上天了?那还有必要费那么大力气收集和清洗训练数据么?那称霸大模型领域的不就是google了么?但事实并非如此啊,说明这样多次迭代肯定是有问题的!具体的问题又是什么了?nature的一篇论文揭晓:https://www.nature.com/articles/s41586-024-07566-y?utm_campaign=CONR_NAJRN_ATT1_AP_CNCM_002E7_natcover ,图示如下:
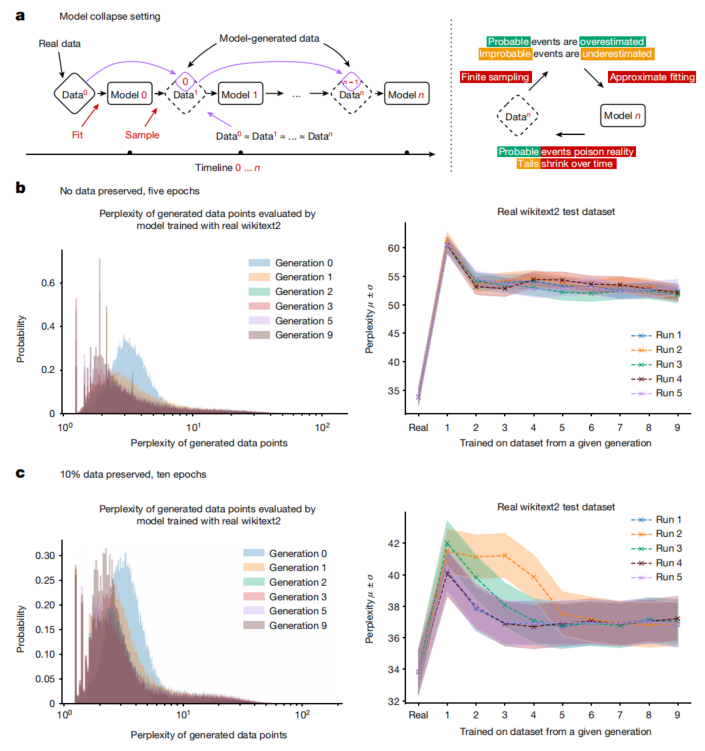
上面的图看起来比较复杂,但是揭示了多次迭代效果不好的根本原因:perplexity降低,数据多样性缺失!这个也不难理解:大模型用decoder生成token的时候,会通过top K、top P、beamsearch + tempreture调节等方式生成next token!迭代的次数越多,这些筛选token的范围就越窄,导致token的多样性越小,token的重复度越来越高!by the way:不管是pre-train,还是post-train,训练样本一定要去重哦!
2、既然这种self-training无法多次迭代,是不是“左脚踩右脚”提升模型性能的方式全都不行了?好像也不这么绝对,近期有团队发文,提出了TTRL:Test-Time Reinforcement Learning的方法:https://arxiv.org/abs/2504.16084;先看看效果和流程,如下所示:
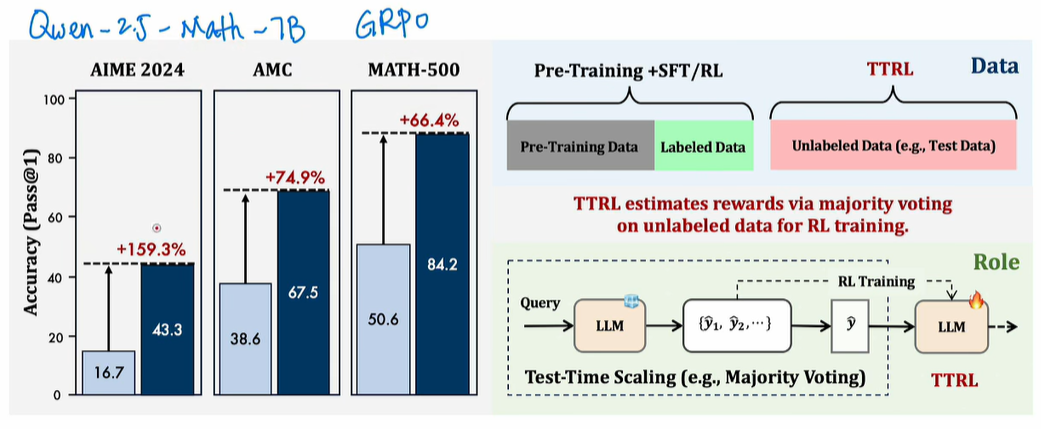
在Qwen 7B的大模型,使用TTRL方式做fine-tune,效果比不使用的提升巨大!具体流程也不复杂,和之前google提出的那种majority voting的方法类似,只不过是在RL之后才这么干的
- pre-train和post-train没啥特别的,正常训练;post-train的Labeled Data是人工标注的;
- 经过SFT/RL后,labeled data耗尽,但还想继续提升model的性能,怎么办了?只能用unLabeled Data训练了,这又改怎么操作了?
- 借鉴之前google的majority voting思路:输入query后,让LLM生成M个response,通过majority voting,找到最终的answer,然后对每个response打分:和answer一样的得1分,不一样的的0分,这样一来就得到了reward信号,最后根据这些reward信号调整policy model,流程示意如下:
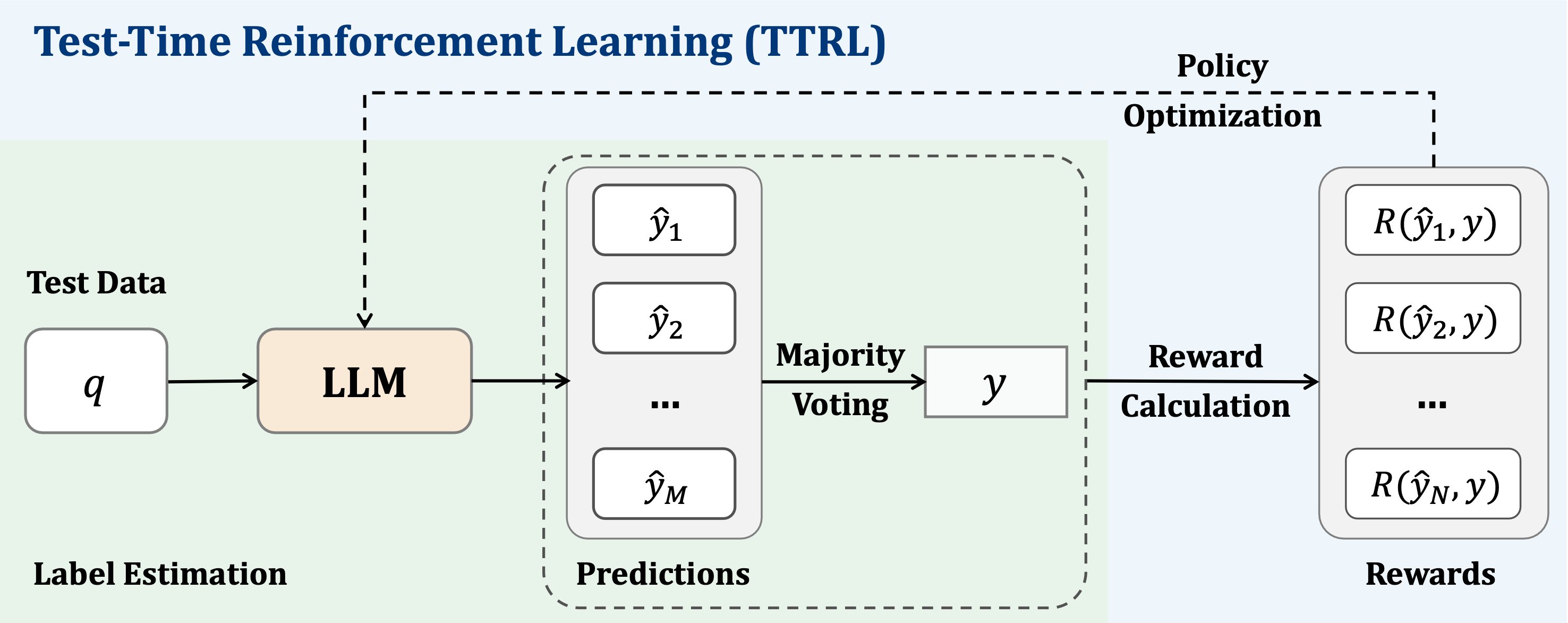
那么问题来了:同样都是majority voting,为啥TTRL这里没出现model collapse?为啥直观感觉比google的LARGE LANGUAGE MODELS CAN SELF-IMPROVE效果要好?仔细比对两者,发现还是有明显不同点的:
- TTRL:通过majority voting 得到的是reward信号,后续通过reward更新policy model的参数
- google LARGE LANGUAGE MODELS CAN SELF-IMPROVE:直接使用majority voting得到的response做SFT训练,非RL;
这么一看,原因是不是非常明显了:TTRL使用的是RL,而google的LARGE LANGUAGE MODELS CAN SELF-IMPROVE使用的是SFT,所以核心区别就是RL和SFT的区别了;SFT只是RL的一种特殊情况,RL相比SFT做了大量的exploration,所以”眼界“相比开阔很多,遇到out of distribution数据的时候,性能自然也要好很多(就是泛化能力强),这点从其他论文也能印证,比如alphaZero的:经过RL产时间训练,大约在第40小时后就超过人类了!
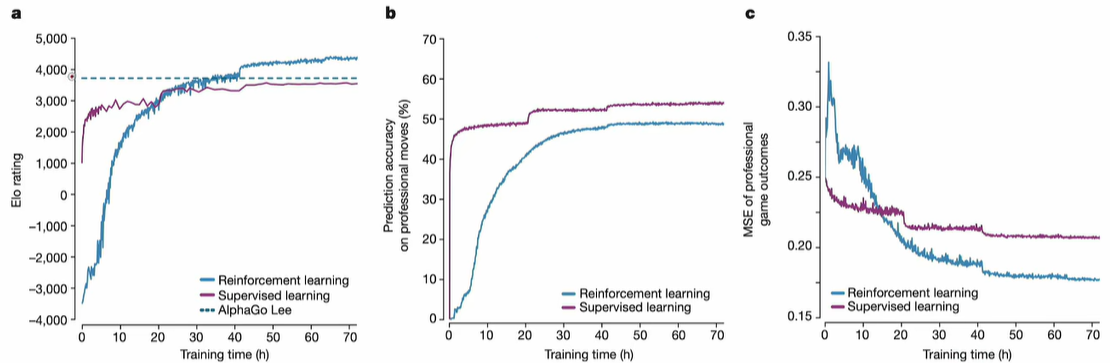
另一篇论文也印证了这点 (https://arxiv.org/abs/2501.17161 SFT Memorizes,RL Generalizes:A Comparative Study of Foundation Model Post-training) :遇到了OOD数据,RL因为经过了大量探索,效果明显比SFT好很多!by the way:这里是不是也说明一点,对于anomaly detection(寻找OOD),经过RL后的效果是不是会好很多了?
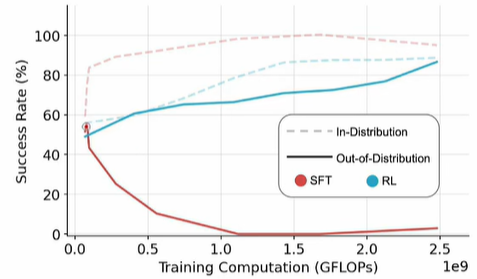
不论是SFT,还是RL,label都来自majority voting,万一majority voting得到的结果本身就是错的了?这种情况下,如果只使用SFT做self-training,那么LLM肯定会被严重误导,导致性能下降!但是使用RL了?结果明显会好很多,原因如下:

如上图所示:假设LLM的回答是1、1、2、2、2、4、5、6,现在分两种情况:
- 如果有true label = 3,那么所有的response都是错的,那么所有的reward都是0
- 如果没有true label,那就只能用majority voting啦,其中2最多,那么等于2的reward就是1,其他的是0
- 因为true label=3,response=2的reward就错了,这么来计算,reward hit rate,也就是reward本身的准确率=5/8=62.5%!
发现端倪了么?如果只用SFT,一旦majority voting出错,整个训练数据完全就是错的了!但如果使用RL的方式,即使positive reward是错的,但negative reward还是对的啊!所以使用RL,即使majority voting错了,但negative信号是对的,相比SFT,有一定的容错性!总结一下,TTRL没出现model collapse的原因:
- 用的是RL,不是SFT,期间存在大量exploration,弥补了生成数据的多样性问题
- reward的nagetive信号是对的,在一定程度上弥补了majority voting错误的影响
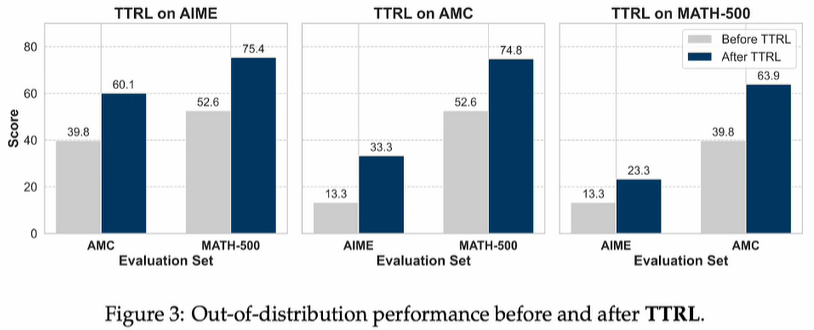
3、作者试了一下:用TTRL方式,分别在AIME上训练,然后用AMC、MATH-500测试,有明显提升;同理,在AMC上训练,用AIME、MATH-500测试,也有明显提升;说明TTRL没有过拟合,有一定的泛化能力,我个人猜测是RL带来的!
既然reward信号来自majority voting,那TTRL的上线岂不就是majority voting的准确率了?作者团队又做了测试,发现TTRL居然还能超越majority voting的上限,如下:
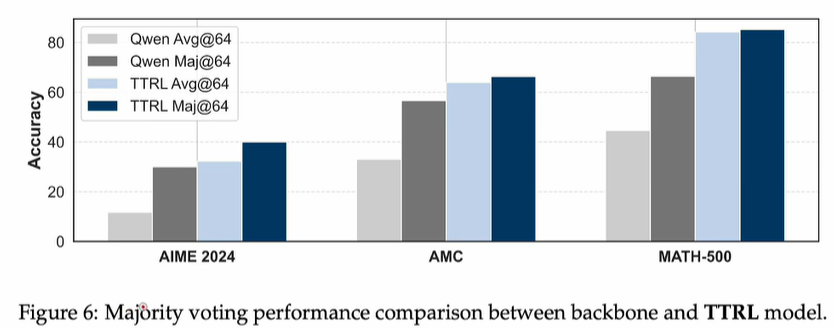
我个人猜测:还是要归功于RL,做了大量exploration,发现了一些隐藏的trick!
4、之前通过model自己产生数据、自己训练的self-train(SFT)方式,因为多次迭代后数据多样性降低导致model collapse,现在换成RL的方式,是不是就能实现”左脚踩右脚“的方式把性能提升到天上去了?别高兴太早,清华大学的一项研究又来泼冷水了:
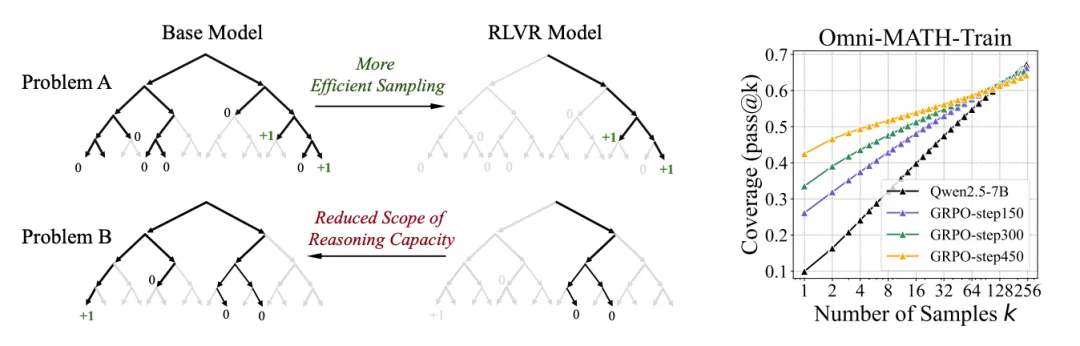
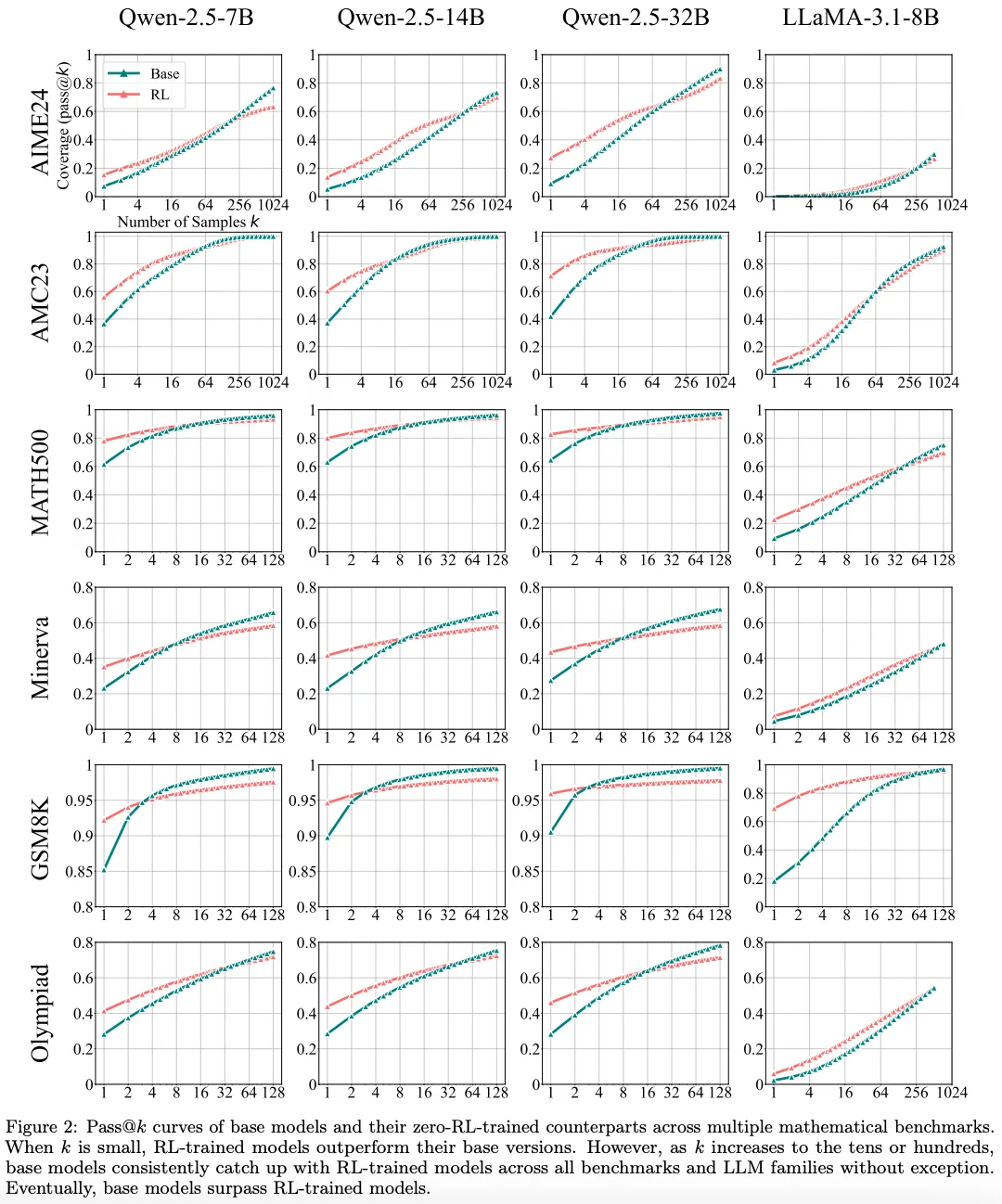
我个人观点:LLM的性能好不好,能不能像人类一样思考,核心还是看网络结构;目前的transformer架构,和传统的RNN、LSTM等相比,性能确实提升很多,但距离人类的智商还相差甚远;通过RL的方式可以适当弥补和提升泛化性,但因为网络架构的限制,天花板还是看得见的!
参考:
1、https://github.com/PRIME-RL/TTRL
https://arxiv.org/abs/2504.16084 TTRL: Test-Time Reinforcement Learning
https://arxiv.org/abs/2504.13837 Does Reinforcement Learning Really Incentivize ReasoningCapacity in LLMs Beyond the Base Model?
https://www.bilibili.com/video/BV1aV5XzWEWF/?spm_id_from=333.1007.tianma.4-2-12.click&vd_source=241a5bcb1c13e6828e519dd1f78f35b2 颠覆认知:强化学习无法诱发新的推理能力?清华黄高团队新作必看!RL无法发现新的知识,只是能快速找到reward最大的路径!所以RL能大程度提升效率,但是无法让model顿悟!真正想要模型变强,还是需要像蒸馏那样引入外部知识,或则探索能突破基础模型边界的新范式!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号