LLM大模型:推荐系统应用-HLLM实战&DSIN
LLM在NLP领域独领风骚,一战成名!和NLP相比,推荐领域也有类似的业务场景:都是时序数据!既然LLM能在NLP大放异彩,在推荐领域是不是也能尝试一下了?
1、先简单总结一下推荐系统的发展历史
- 协同过滤 Collaborative Filtering:userCF、ItemCF;原理是根据user的浏览记录找到user或item之间的相似度,用以后续的推荐;
- CF连模型都算不上,就是个数学计算公式,无力生成user或item的feather embedding,所以没能力提取user或item的feather,无法捕捉复杂的规律或内在联系,导致其毫无generalize泛化能力!
- 依靠记忆做filtering,而不是model
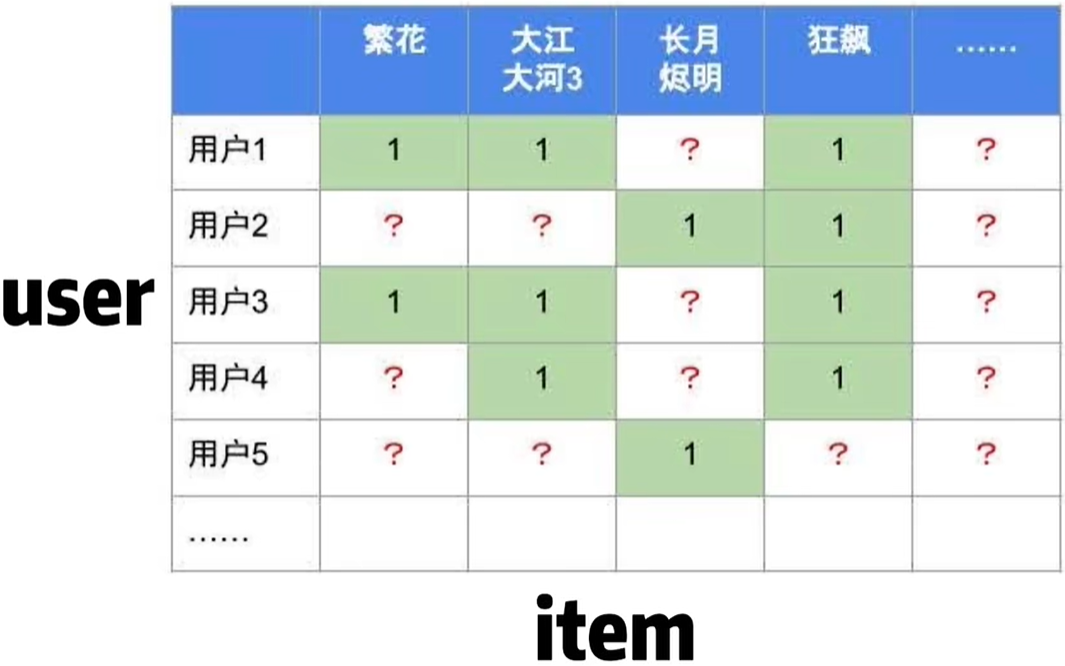
- 为了提升generalization泛化能力,此时matrix factorization横空出世了!通过矩阵分解,把user-item的空白处填上合适的数字;
- user-item是sparse的,空白过多会导致结果不稳定;
- 使用交替最小二乘ALS alternative least squre、weighted ALS做MF
- user-item是sparse的,空白过多会导致结果不稳定;
-
- MF只用了user-item的interactive信息,没用到user profile、item information
- 为了尽可能多的使用user/iem信息,又诞生了LR+特征交叉;但互联网的数据增速是爆炸式的,人工手动组合feathers效率极低;
- Factorization Machine 因子分解机:通过latent vector的内积计算特征xi之间的距离(这不就是transformer的attention机制么?),也就是weight,达到自动两两组合特征的目的!
- FFM:特征域组合
- 组合模型:GBDT用来生成离散特征,然后用LR做预测!
- 深度学习DNN:wide&deep、deep Cross、deep FM.....
2、以上各个不同阶段的推荐系统,其实核心目的就一个:构造好的feather embedding(所谓好,就是有区分度的特征,能很好地区分target label),本质还是feather engineering!为了构造好的feather embedding,各种手段都用上了,但唯独还漏掉了一个重要的因素:时序!user对于item的浏览是有先后顺序的,理论上这里面可能蕴含一些规律或关联关系(通过feather embedding来体现、捕捉关系和规律),比如user先后浏览了一次性餐具、饮料、熟食等item,推荐系统能不能准确地挖掘出user是要去露营开party了?既然transformer架构能很好地处理NLP这种时序数据,是不是也能很好地处理推荐系统的数据了?
前面提到了,机器学习要想效果好,最核心的就是feather要构造的好!上述的各种方法本质都是在构造feather,但并未考虑到item浏览顺序的时序信息,这里该怎么利用transformer架构提取user浏览item的顺序信息(进而进一步挖掘user的浏览规律)了?字节的HLLM是这么干的:
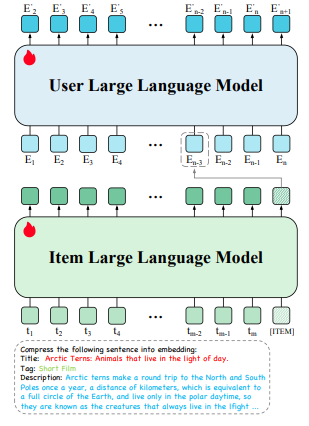
这个图示明显分了两部分:user LLM和item LLM;从下往上看:
- Item LLM:从名字就能看出来是和item相关的,这个是干啥的了?提取item feather哒!每个item都有各种属性描述,这些全是text文本,现在需要把这些文本text统一转成embedding(用来做item的feather representation),用的就是Item LLM!这里的t1、t2、t3....tm都是text文本的token,最后一个输出[ITEM]就是单个item的feather embedding啦!所以这里的第一步就完成了,得到了每个item的embedding!
- 这一步学习的都是item本身的feather
- user LLM:item的embedding有了,怎么挖掘item之间的时序(或者说顺序)信息了?此时就需要把item当成是NLP的token了,把user浏览item的顺序看成是NLP中token之间的顺序,所以就有了user LLM架构;这里面的E1、E2、E3.....En都是单个item的embedding,按照user的浏览顺序依次进入user LLM即可!
- 这一步学习的是user-item的interation
- 两个LLM的train和NLP领域一样,都是用auto regression方式训练的!
- 这一步完全没用到user profile,纯粹是根据user-item的交互预测后续的item。论文作者可能是考虑到user的点击、点赞等行为已经反应了user feather。这么做可能还消除了一些用户画像带来的刻板印象(比如男性爱打游戏、电子产品等)!user action更能反应真实的自己,更加make sense!
- 这一步是用来recall的,用户根据用户需求来控制LLM中sequence的长度达到控制recall数量的目的!
3、推荐系统常用的套路:召回->粗排->精排->重排等,上述是用于召回的(当然召回的方式绝不止使用LLM,还有其他很多召回通道),接着就是rank了,这一步该怎么使用LLM了?rank的方式之一,是对比item之间的各种率:点击率、点赞率、收藏率、评论率等,各种率高的排前面,低的排后面!问题又来了:怎么准确的计算各种率了?这里要考虑一个很重要的问题:还是时序!user前面浏览了n个item,浏览第n+1个item的概率有多大了?很明显预测第n+1个item各种率的时候要包含user前面浏览的n个item的信息(或者说必须根据前面n个item的信息来预测第n+1个item的各种率,还是那个例子:用户浏览了一次性餐盒、饮料、熟食等n个item,那么浏览第n+1个item是“帐篷、桌椅、炉灶、洁具”等的概率分别有多大?),这个该怎么实现了?这不就是transformer attention机制最擅长的么!attention机制通过内积,找到两个token之间的距离作为weight,把前面n个token的value按照weight比例加入到第n+1个token,这不就让第n+1个token顺利融入了前面n个token信息了么?这里完全可以直接拿过来用啊!HLLM是这么干的:
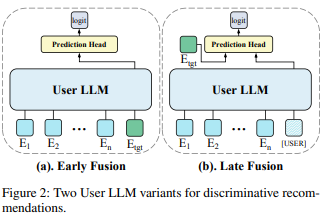
上一步不是recall么?从大量的item中召回了万八千的item,需要精准预测这些item的各种率,这里就继续使用LLM来做fusion!比如需要预测各种率的item是Etgt:
- Early Fusion:把user前面浏览的n个item和Etgt作为完整的sequence放入user LLM,这样Etgt就顺理成章地Fuse了前面n个item的信息;如果n+1的item和前面n个item距离接近、关联性强,那么attention后n+1的item的embedding数值较大,最终生成logit的数值较大,也就是各种率较高;反之如果第n+1个item个前面n个item的关联小,生成的logit也较小,后续的各种率也会较小;
- 每生成一个item的logit都要把整个user LLM跑一篇,计算量有点大!
- Later Fusion:把user前面的n个item经过user LLM融合生成embedding后,和Etgt首位拼接再经过prediction head计算logit;和Early fusion比,[USER]的embedding一旦生成完毕,可以存起来,后续和Etgt融合时直接用了,更加灵活一些!
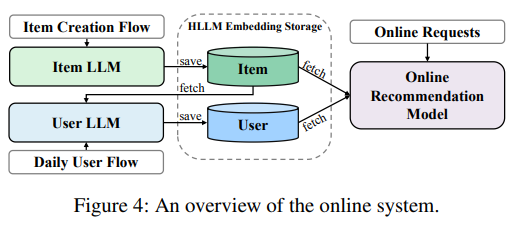
4、熟悉推荐系统的朋友都知道,推荐系统是有offline和online两条线的!offline是利用历史数据train各种model,online是实时接收用户的输入后输出推荐的item!HLLM的offline和online架构如下:
-
Item LLM Creation Flow:
-
当一个新的Item被创建时,系统会使用 Item LLM 来提取该item的feather embedding。这些feather embedding会被存储在一个专门的存储系统中,以便后续使用。
-
这个过程是offline的,通常在item被添加到系统中时进行。
-
-
User LLM Daily Flow:
-
每天,系统会更新user embedding。这一步是基于user前一天的action(如点击、购买等)来更新user feather
-
user embedding的更新也是offline进行的,目的是为了捕捉用户的最新兴趣和行为模式。
-
-
Online Recommendation Model:
-
在线推荐模型是系统的核心部分,它负责实时real-time生成推荐结果。这个模型会从存储系统中获取user和item的embedding,并结合其他可能的特征(如上下文信息、时间戳等)来生成推荐列表。
-
该模型是online real-time运行的,能够快速响应用户的请求,并提供个性化的推荐结果。
-
5、既然使用的是LLM,有些性能指标是绕不过的!
(1)user LLM和item LLM,如果已经使用text文本类做了pre-train,再用于推荐,效果比直接使用user浏览item的历史数据训练LLM更好!说明从text中通过pre-train获取的信息是能帮助推荐系统这类downStream task的!尤其是item LLM,本身就是大量的text描述!
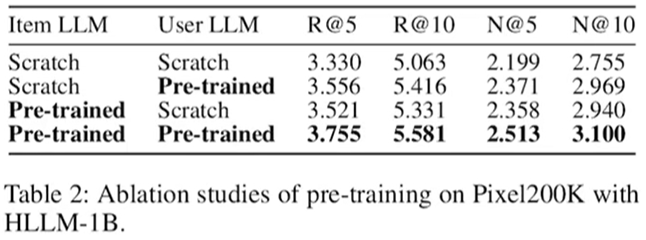
(2)pre-train训练的model,使用的token越多,后续的推荐的效果越好!token越多,引入的world knowledge越多嘛!注意:这里有1T+chat训练,效果反而差一些,轻微下降,因为SFT是训练model问答能力的,和推荐没啥业务关系,所以性能下降也是make sence的!
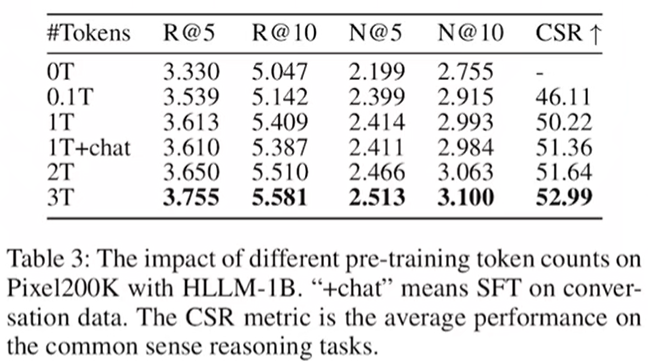
(3)两个LLM的model都来自pre-train,参数都要learnable最好,不能一个改变、另一个不动!仔细看数据:item LLM如果frozen,整个系统的性能会非常差,侧面说明了item LLM更重要!item LLM提取的feather是整个系统的入口,只有item LLM提取的feather好了,后续才能提升性能!也说明需要在自己的垂直领域微调,直接从现成的item LLM是不行的!
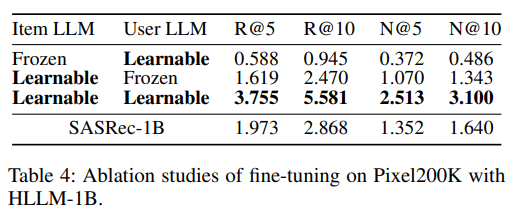
(4)item LLM参数越大,提取的feather,性能越好!
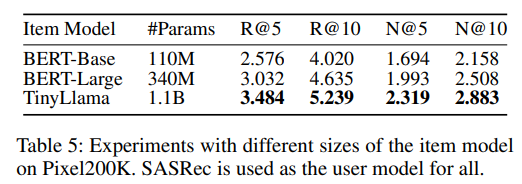
user LLM也是参数越大,效果越好!但是参数量提升的效果是不如item LLM明显的!所以又一次证明了item LLM比user LLM重要!
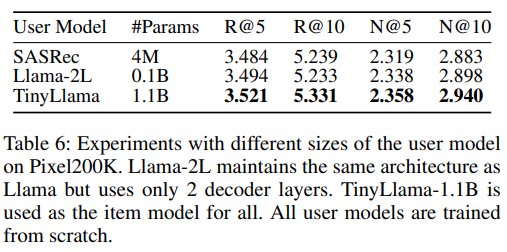
(5)数据量增加,对recall的精确率是有明显提升的!
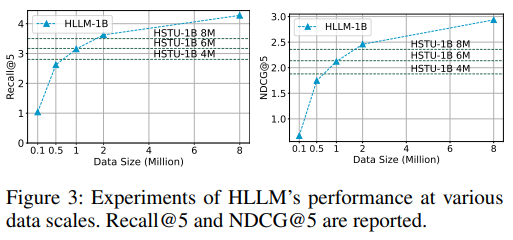
(6)和其他同类推荐系统比的效果: 就HLLM自身而言,1B相比7B,性能确实差一些,但是差距也就一点点,对于字节这种大厂来说,提升一点点带来的绝对收益也是很大的!但是对一般的小公司而言,1B明显比7B更划算了!
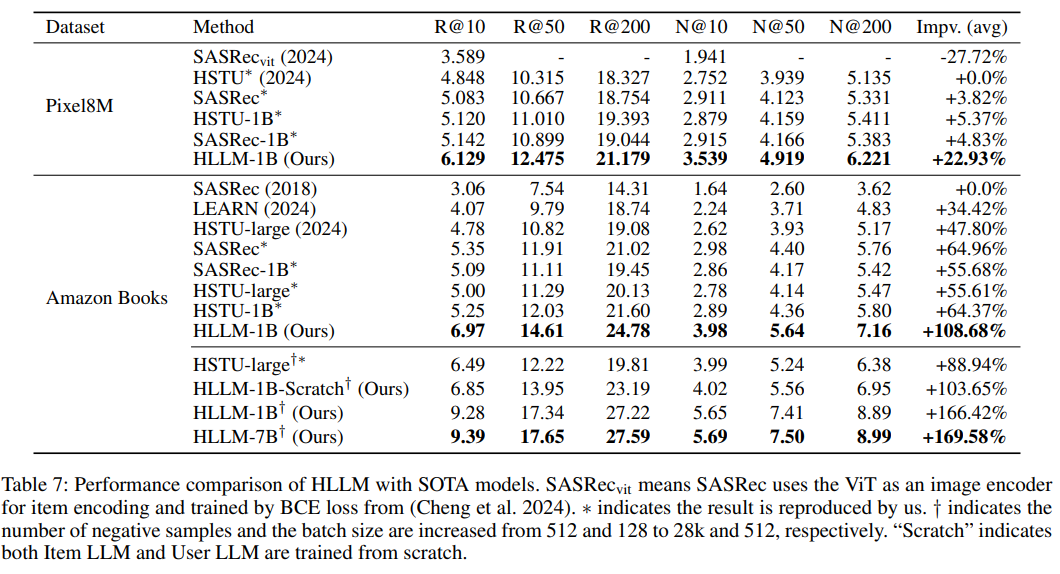
(7)上面是在recall阶段的提升,还有rank也需要对比。因为rank阶段可能没有好的公开数据集,作者在他们自己的数据集上测试:Finally, we test HLLM in online A/B experiments of the ranking task. Key metrics have shown a significant increase of 0.705%. 整体提升了0.705%;对于字节这种大体量的系统而言,提升这个数值已经非常了不起了!
6、HLLM是近期字节发布的,其实在更早的2019年,就有研究人员使用transformer+Bi-LSTM做推荐了, 名曰:Deep Session Interest Network(DSIN):深度会话兴趣网络
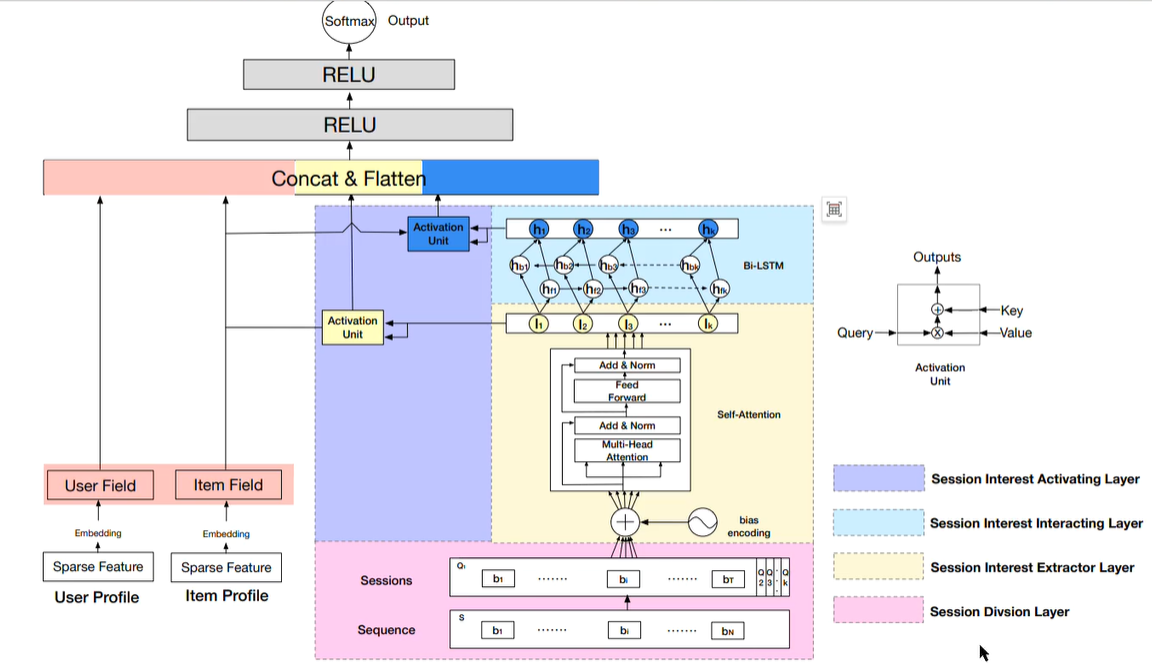
DSIN的特点:
- 把user的action sequence切分成了不同的session,比如两个item之间的行为间距超过30minitus,就会被划分到不同的session,通过这种方式初步聚合user不同的兴趣点!
- 左边分别提供user profile和item profile,统一转成embedding的形式
- 重点是右边的,明星啊分成了两部分:
- self-attention:
- 捕捉session中不同item之间的依赖关系,识别出哪些item特征对当前预测最为重要,从而更好地理解用户的兴趣。
- session中item的信息在最后一个item的value embedding中融合
-
Bi-LSTM:
-
结合了前向LSTM和后向LSTM,能够同时学习到session中每个时间点的过去和未来的信息。这对于理解用户在session中的行为模式特别重要,因为用户的兴趣可能会受到之前和之后行为的影响;
-
更全面地理解session数据,因为它不仅考虑了session的当前状态,还考虑了session的历史和未来信息(session之间的兴趣迁移)。这对于推荐系统来说是非常有价值的,因为它可以帮助模型更准确地预测用户的兴趣;
-
- self-attention:
总结:
1、LLM运用在推荐系统:
- embedding,还是提取user或item的特征
- inference的能力:
- 比如有人买了气球、帐篷,这人是不是要去露营办party了?既然是露营,要不要再推荐点其他的产品?比如饮料、食品、一次性餐具等
- 这个功能理论上也可以通过reinforcement learning实现:prompt是用户user profile、user浏览item的记录,response就是LLM输出的后续item的各种率和reason,使用GRPO就能实现!user LLM的最后一个token是融合了前面N个item的信息,然后用最后的这个token适配downsteam task!所以这里和直接拼成prompt没本质区别!
- 另一种reinforcement learning DPO也可以用于推荐系统
- 回想一下DPO的算法:LLM生成多个response,user选择一个最喜欢的作为positive,其他两个不喜欢的作为negative
- 推荐系统不也一样能这么干么:页面给user展示了N个item,user只点击了其中几个,那么这些点击的item就是positive,没有点击的就是negative
- 用户自己都不知道用什么关键词检索,当时能根据当时的context合理推荐item
- 比如有人买了气球、帐篷,这人是不是要去露营办party了?既然是露营,要不要再推荐点其他的产品?比如饮料、食品、一次性餐具等
2、推荐系统会不会也像NLP一样,使用LLM进入pre-train阶段了?
参考:
1、https://arxiv.org/pdf/2409.12740 HLLM: Enhancing Sequential Recommendations via Hierarchical Large Language Models for Item and User Modeling
https://github.com/bytedance/HLLM 源码;从其论文发布的性能测试看,pre-train 7B的效果比1B的好,但是提升的并不明显!对于字节这样的大厂, 因为流量基数很大,所以哪怕性能只提升0.01%,绝对数值也能提升很大!这里为了做测试,暂时使用1B的模型尝试。测试时使用论文推荐的tinyLLama 1B的模型和amazon books训练数据!整个目录结构如下:
这两个amazon_books数据集,一个是interactive,存放了user-item的交互信息;另一个是information,存放了item的信息!执行命令如下:
python3 main.py \ --config_file overall/LLM_deepspeed.yaml HLLM/HLLM.yaml \ --loss nce \ --epochs 5 \ --dataset amazon_books \ --train_batch_size 16 \ --MAX_TEXT_LENGTH 256 \ --MAX_ITEM_LIST_LENGTH 10 \ --checkpoint_dir /root/HLLM-main \ --optim_args.learning_rate 1e-4 \ --item_pretrain_dir /root/.cache/modelscope/hub/models/chaoscodes/TinyLlama-1___1B-intermediate-step-240k-503b \ --user_pretrain_dir /root/.cache/modelscope/hub/models/chaoscodes/TinyLlama-1___1B-intermediate-step-240k-503b \ --text_path /root/HLLM-main \ --text_keys '["title", "description"]' \ --gradient_checkpointing True \ --stage 2
因为使用的只是1B的模型,RTX 3080 Ti / 12 GB足够使用了;运行一共耗费7小时!

2、https://www.bilibili.com/video/BV1wyZnY2EYy/?spm_id_from=333.337.search-card.all.click&vd_source=241a5bcb1c13e6828e519dd1f78f35b2 HLLM,字节跳动大模型相关推荐系统
4、https://www.bilibili.com/video/BV1EE421G7dg?spm_id_from=333.788.recommend_more_video.4&vd_source=241a5bcb1c13e6828e519dd1f78f35b2 聊一聊推荐系统是如何一步一步发展到今天的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号