LLM大模型:deepseek浅度解析(二):R1的GRPO原理
chatGPT3.5、4.0、4o这些版本发布后,因为效果相比以往的NLP产品比,确实有质的提升,所以引起了很大的轰动。但也有部分AI学术巨头吐槽说transformer架构根本不是真正的AGI,原理上讲本质就是个统计模型:通过海量训练数据的统计信息来计算next token的概率,并不具备真正的思考和逻辑推理,最经典的例子就是3.11和3.8这两个版本哪个大!所以openai紧接着推出了chatGPT-o1模型,内部代号"strawberry",核心就是通过reinforcement learning模拟人的思维,在逻辑推理强的领域,比如数学、编程、物理等有明显的提升!deepseek也不例外的啦,自己也用reinforcement learning做了long-cot训练,效果和openai基本持平,稍微好一点,这么好的性能,都是怎么实现的了?
1、先来回顾一下reinforcement learning常见的算法:
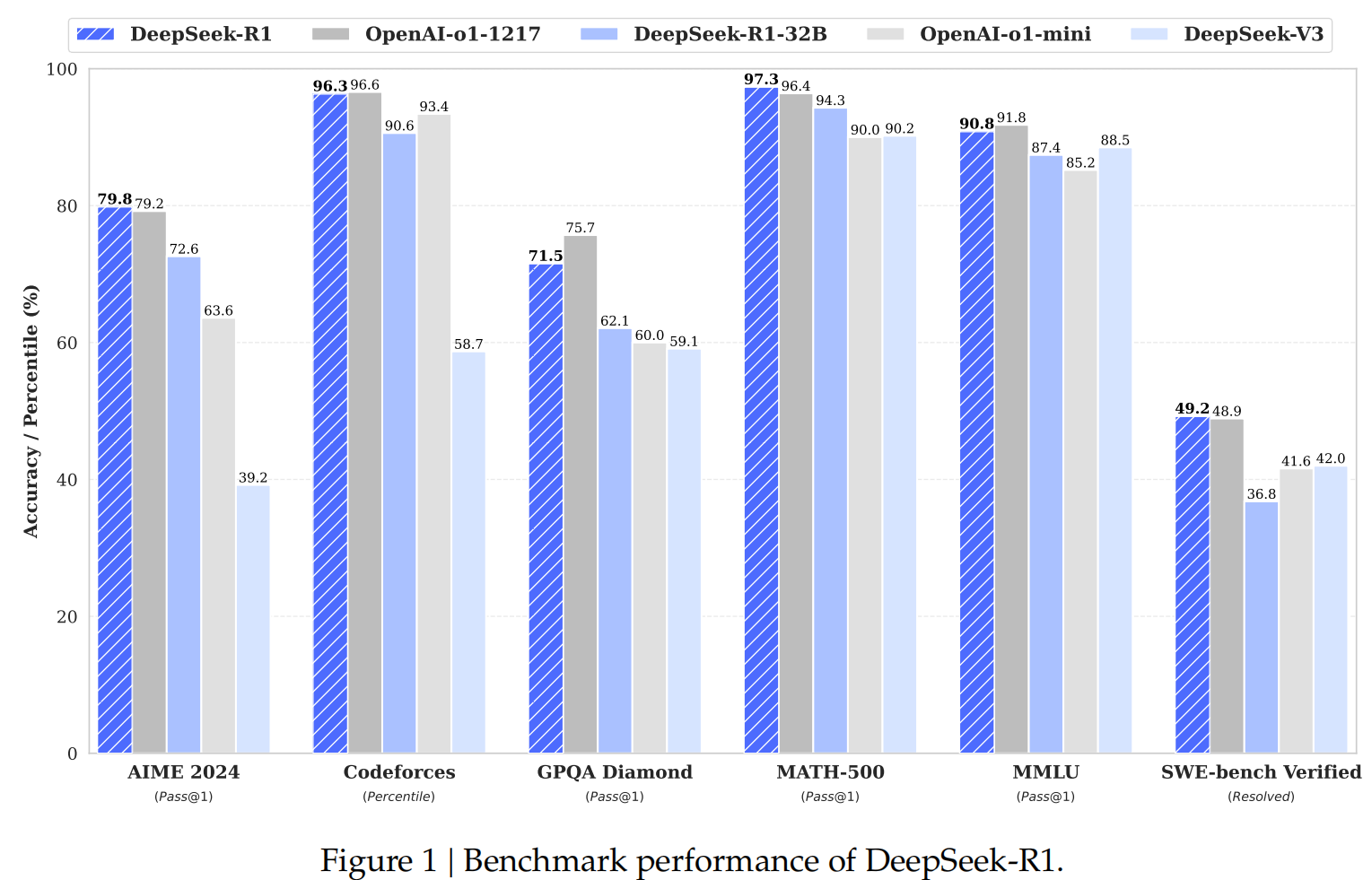
(1)DPO:https://www.cnblogs.com/theseventhson/p/18252727 我之前介绍过,原理就是让LLM的回复尽量接*人工chosen的答案,原理reject的答案,loss如下:
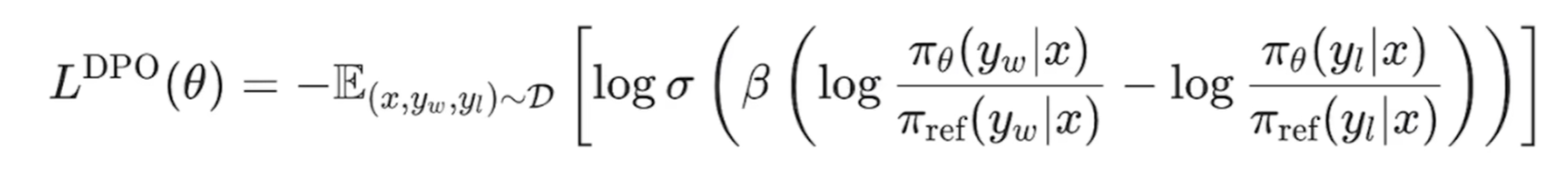
deepseek既然没选DPO,肯定是有原因的,DPO的缺点如下:
- 需要人工标注成对的数据:{prompt; chosen; reject} 这类格式,耗时耗力,成本高;而且,这种标注方式难以泛化,因为现实中很多问题并没有明确的“优”或“劣”之分。
- 训练数据集不一定是当前所需要训练的模型生成的,或者说不是当前训练模型的采样,也可能会影响泛化性能
- 分母pai_ref是正则项,如果正则项设置得过大,模型会受到过多的惩罚,导致模型过于简单,无法捕捉到数据中的复杂模式。这种情况下,模型可能会在训练过程中变得不稳定,难以收敛到一个好的解;站在业务角度理解:训练的模型可能会过度依赖pai_ref,这会导致模型“死记硬背”pai_ref的回答,而失去自己灵活生成答案的能力。具体来说,如果pai_ref的“推理过程”很长(比如多步推理),直接用DPO优化可能会让模型学*到极端的答案模式,导致模型变得“僵化”甚至无法适应新的问题,所以这里deepseek用了long-cot对模型做了训练!
上述缺陷是DPO的原理决定的:要想LLM的回复偏向于人类喜好,又要防止过拟合,避免“灾难性遗忘”,只能加上正则项pai_ref(初衷是希望model既能学到人类偏好,又不能远离base model);但是pai_ref如果过大,惩罚过大,会导致模型过于简单(更倾向于接*base model,"吸收"训练数据的pattern较少),无法捕捉到训练数据中的复杂模式,无法回答推理复杂的问题;
(2)PPO:在reinforcement learning中,直接优化policy model会导致不稳定的训练,模型可能因为过大的参数更新而崩溃。最直观的解决办法就是限制policy的更新幅度,使得每一步训练都不会偏离当前policy太多,同时高效利用采样数据,并且使用advantage function评价某个动作的相对好坏。网络架构如下:
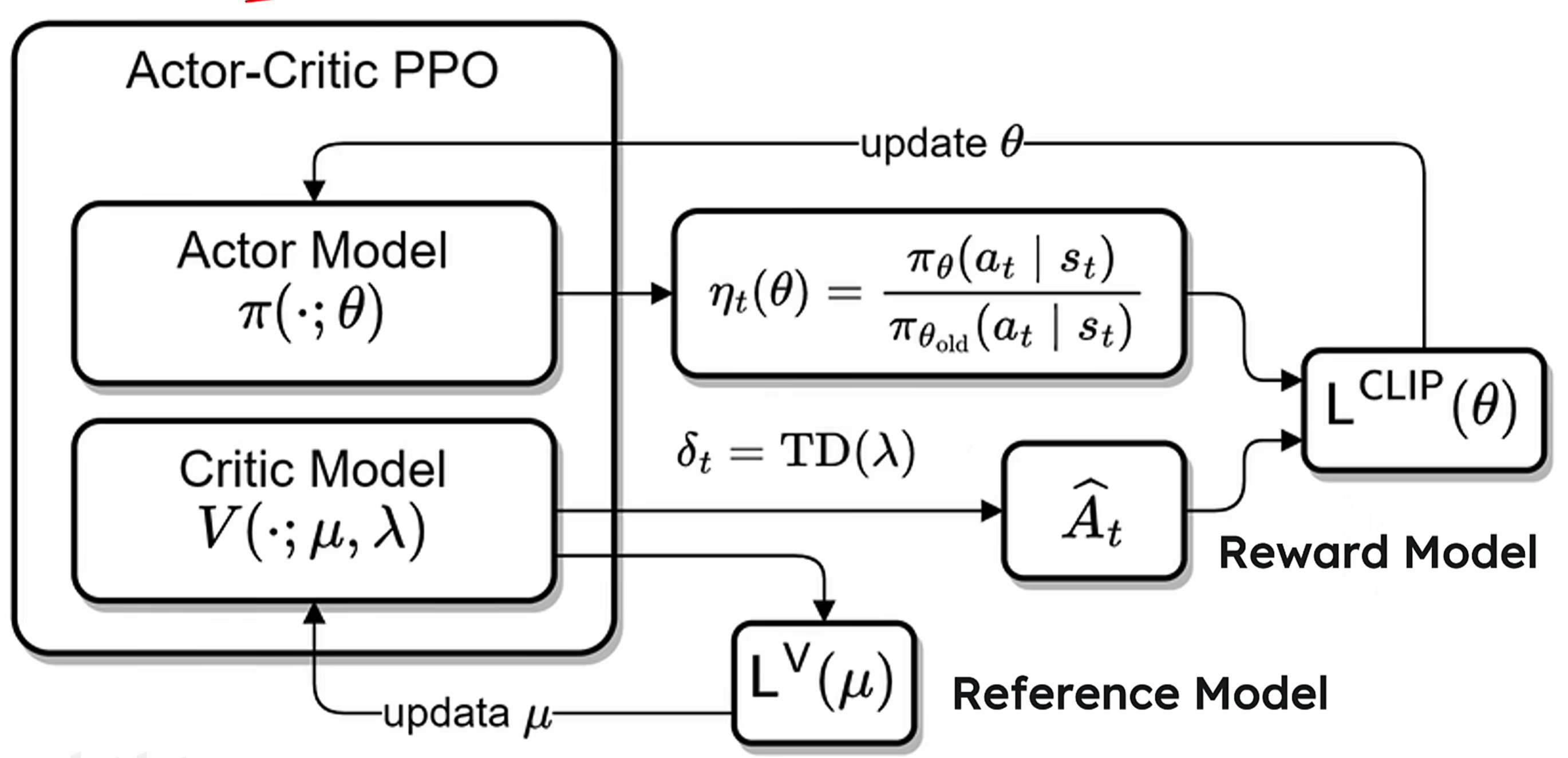
PPO的loss函数如下:

直观理解:教练训练学员踢球,如果学员每次射门的动作都完全不同,这就是policy过度更新,是学不会射门的;如果每次射门动作变化太少,这就是更新不足,也学不到新知识的,难以进步;只有射门的动作适当调整,才能达到既定目的;PPO 的机制就像一个“适度改进”的规则,告诉球员在合理范围内调整射门动作,同时评估每次踢球的表现是否优于平均水平。PPO也有缺陷:依赖于Critic模型对状态价值进行估计可能会使得算法更加难以泛化。这是因为:
-
value估计的难度:某个特定state的value评估,涉及到对未来所有可能reward的预测,这是一个非常复杂的问题。如果Critic模型无法准确预测这些奖励,那么它提供的价值估计就会不准确,从而影响策略的学*。
-
泛化能力的挑战:Critic模型需要在各种不同的状态下都能提供准确的价值估计,这要求模型具有很强的泛化能力。然而,泛化能力的提升往往需要大量的数据和复杂的模型结构,这可能会增加算法的复杂性和计算成本。比如有些action当前的value低,但后续其他action的value会很高,比如两军作战时故意诈败、诱敌深入,诈败这个action本身看起来像失败,value肯定低,但后续的诱敌深入value很高啊,这就要求Critical能真确识别当前action的value了!
此外,PPO除了训练policy model,还要训练critical model,对算力和显存的要求都不低;同时,训练样本的reward是sparse的,只对整个response打分,不对单个token打分!所以PPO的缺陷也很明显!
2、(1)基于上述的各种reinforcement learning的算法都有缺陷,deepseek都没采用,而是采用了Group Relative Policy Optimization的算法!先来看看GROP和PPO之间的架构对比, 如下:
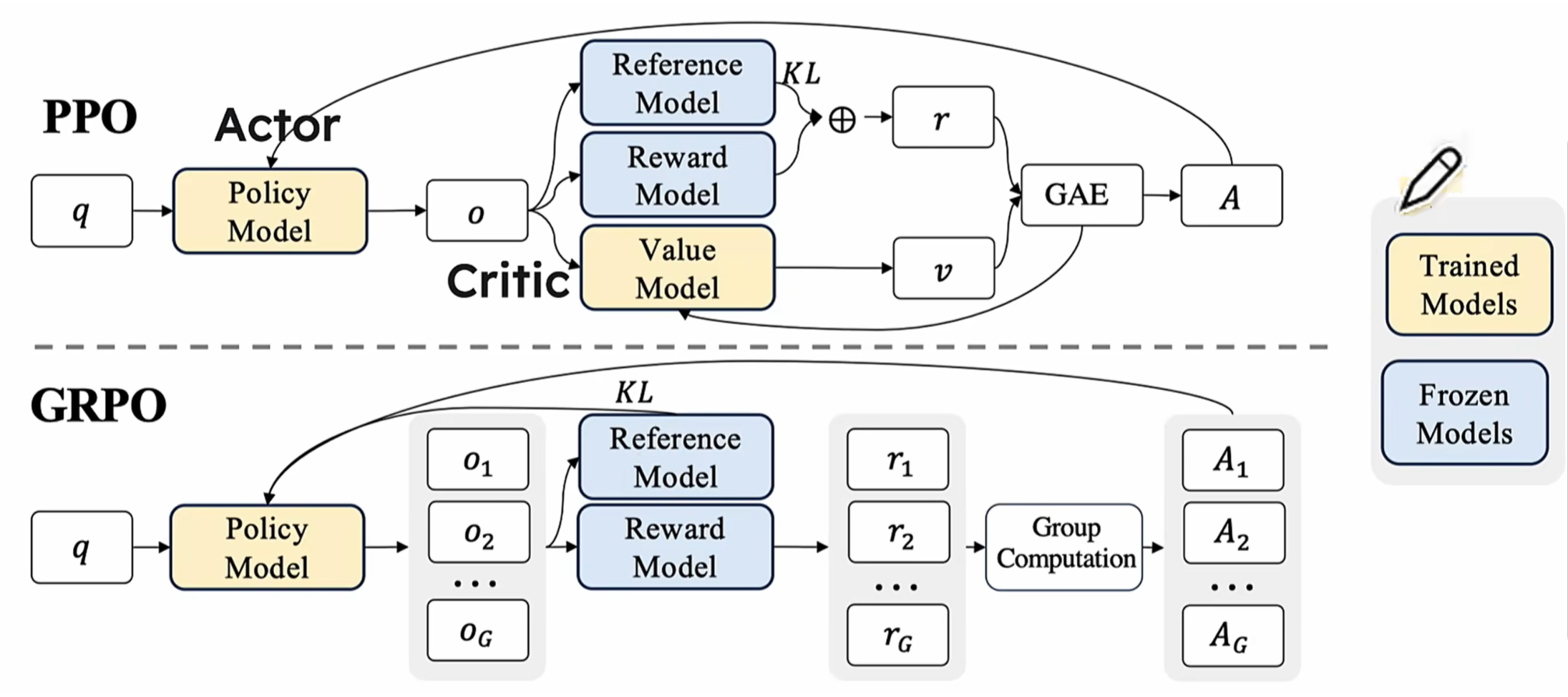
看出来了有啥明显区别了么?
- GRPO对同一个prompt,输出了多个response;
- GRPO去掉了value model
- GRPO得到多个reward,这些reward经过group computation得到了对应数量的advantage值
(1.1)上述的这些改变,都是为啥了?有什么精妙的地方?
- value model也是个model,也要训练的,也有预测不准确的时候;少了一个可能不准确的model,结果就多了一份准确性
- 那么问题来了:既然没有value model,怎么评价action的好坏了?这里用了advantage计算value,也就是当前action的reward和mean相比,谁更大;如果大于mean,就是好的action,这种action就要鼓励policy model往这些超过均值的action靠拢!!因为有了output score的计算公式,所以不再需要value model了!也即是说下面的Ai公式替代了value model!GRPO主要的创新之一:每次生成多个output,用规则计算每个output的reward,然后往高reward的方向演进(像不像生物基因突变后的进化啊)!
![]()

或者这样理解:某个state下有多个action,找到价值高的action靠拢!这个思路和PPO不能说非常相似,只能说完全一样!

- Q(S,a)评估:因为范围可能非常广泛,导致方差很大;但是A(S,a)采用的是相对advantage,方差比Q(S,a)小很多,训练过程更加平滑稳定!
(1.2)GRPO的reward函数如下:reward函数中加入了policy model和reference model的KL divergent,而不是像PPO那样在reward中添加KL惩罚项,从而避免了复杂化Advantage的计算;reward函数这么一大坨,有哪些精妙之处了?

既然Ai体现的是oi的优势,所以policy model肯定要往Ai大的oi靠拢,这个怎么引导model输出Ai大的oi了?其实整个loss函数最核心的就是下面这部分了:
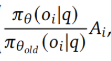
这个公式学名叫importance sampling,思路是让new、old这两个policy做对比,得到的结果作为系数weight对Ai的值进行调整!详细说明如下:
- 分子是new model得到oi的概率,分母是old model得到oi的概率,如果这个概率比值>1,说明new model更倾向于生成oi这个结果,作为调整Ai的weight(原理和attention的dot product是一样的);
- Ai是oi的相对优势评分,如果Ai>0,说明oi相对其他o是有优势的,model需要奖励;
- 注意:这里的Oi是完整的一个输出sequence,所以Ai也是针对完整的output sequence计算的,而不是单个token!整个过程描述:
- 先用old policy生成Oi,计算出Oi的概率pai_old; 同样的Oi,再让new policy计算生成的概率pai_new即可!因为vocab词表是固定的,所以decoder经过softmax后,肯定能找到Oi中每个token的生成概率!
- 比如“我爱中国”这个sequence,在old policy中生成的概率是0.2*0.4*0.1*0.8=0.0064,在new policy中生成的概率是0.2*0.4*0.8*0.8=0.0512,对比之下,同一个Oi,在new policy下生成的概率是old policy的0.0512/0.0064=8倍!
- 注意:这里的Oi是完整的一个输出sequence,所以Ai也是针对完整的output sequence计算的,而不是单个token!整个过程描述:
- weight * Ai,本质就是计算当前oi的score,score决定了当前的答案oi到底好不好;所以理想的情况是:Ai>0,说明对应的oi是好的action,应该往oi倾斜;如果weight大于1,说明new model倾向于oi,刚好和Ai契合,让整个reward最大化!
- 用这个替代了PPO的value model,让基准稳定,让policy model的训练更加平滑!
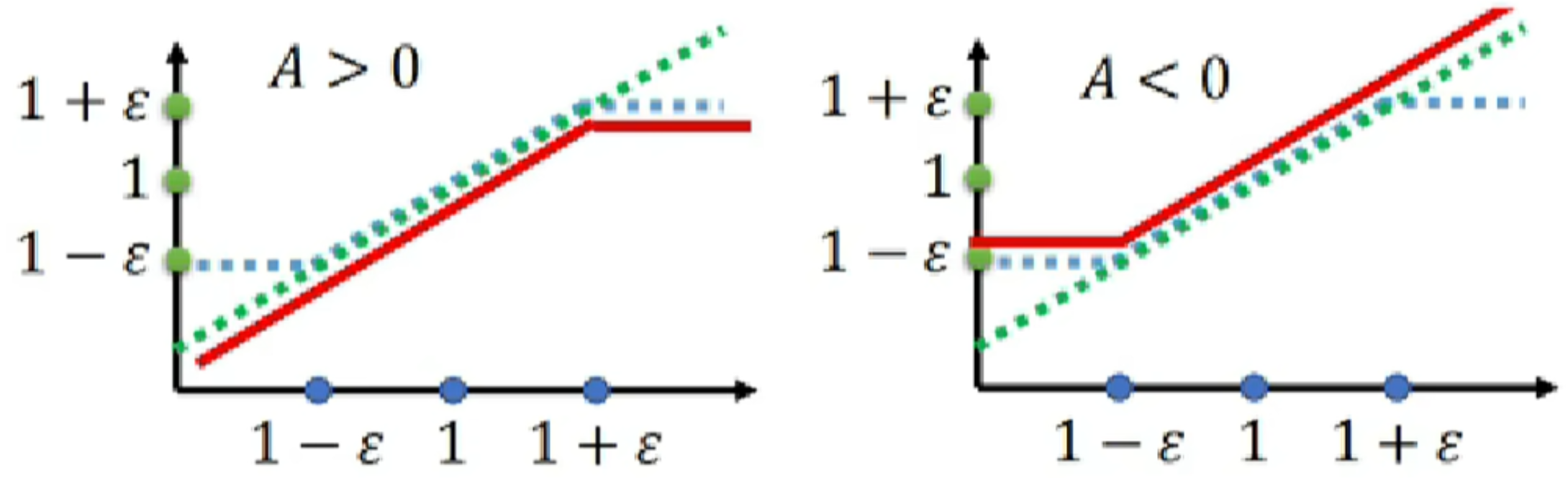
(1.3)clip的作用容易理解:把比值压缩在[1-€,1+€]区间内,防止在优化过程中变化过大,导致模型崩溃或剧烈震荡,于是得到了蓝色折线;
(1.4)表达式中还有比较特立独行的额就是正则项D_kl了!标准的KL是这样的:

但是deepseek的KL是这样的:

这又是为啥了?
-
第一项是当前policy与reference policy间差异,类似开车时的路线偏差
-
第二项是用 Log 计算策略变化的相对速度,通过对数压缩实现非线性制约(类似二阶导数),负号形成反向阻尼, 类似增加刹车效果提升稳定性;核心是控制new mode和reference model偏离的速度,不能太快,避免reward波动过大!
-
第三项提供固定的基线偏差避免数值上异常波动
(2)reward modeling:其实我个人觉得reward model才是强化学*的核心,这个直接决定了policy model输出的output好坏,也决定了policy model参数更新的方向!这里面的创新点:
- reward其实分两块:
- 判断output是否correct
- 既然是cot,那么也要求policy model按照特定的format输出,所以额外还有一个format reward model that enforces the model to put its thinking process between ‘<think>’ and ‘</think>’ tags.
- GRPO用简单粗暴的规则计算output的rewards值,并未使用neural netwrod计算reward,节约了算力,这也是R1成本低的原因之一!
同时没有使用mento carle tree search,也没有使用process reward model:
- MCTR:句子的state太多,无法做tree search。比如句子上线长度10000个token,每个token取值有2000种,那么整个state(也就是tree node)有2000^10000个,这么大的量,是遍历不完的
- process reward model缺陷:
- 不好确认reward的颗粒度,比如token级别?句子级别?cot级别?
- 还是涉及到训练样本的标注问题,成本高
- reward如果用贪心算法,容易陷入局部最优
- reward hacking:学到了“歪门邪道”,比如正确答案都是中文回答的,但中文回答又很少,reward model可能就会觉得所有的中文回答都是好的!
(3)基于上述的reinforcement learning算法,deepseek采用了比较大胆激进的做法:跳过SFT,直接针对base model上reinforcement learning,得到了R1-Zero版本;这种情况只给正确答案,具体的推理过程让LLM自己输出,这样做就像让小学生做初中生的数学题一样,只给答案,不给解题过程,让小学生自己想解题过程。deepseek团队公开的数据如下:
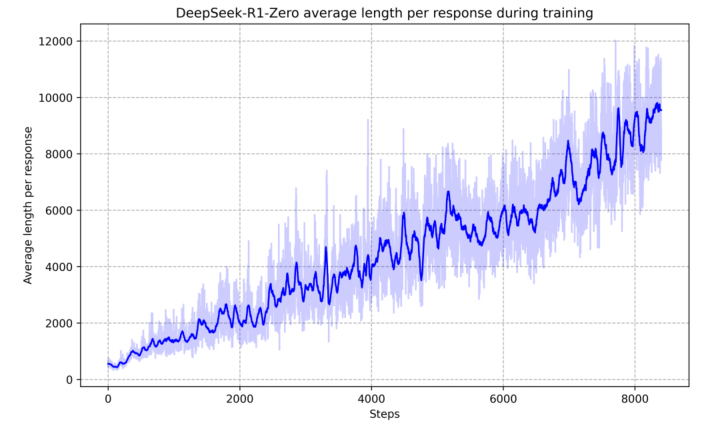
上面的图反应了:
- 即使不用sft,model也有reasoning能力
-
使用多数投票策略(例如对一条prompt采样多次,取出现次数最多的那个答案)可以进一步增强模型性能
-
随着训练steps的增加,r1-zero倾向于产出更长的response(long-cot,应该是long response的reward比short response高,更加利于rethinking),并且还出现了反思行为,这就是aha moment;根本原因还是model在训练过程中,掌握了reinforcement learning的探索路径,自然能够应对一些没有见过的场景!

R1-zero的性能对比测试:准确率基本是稳步上升的,并没有上蹿下跳,说明reward的方法是有效的!

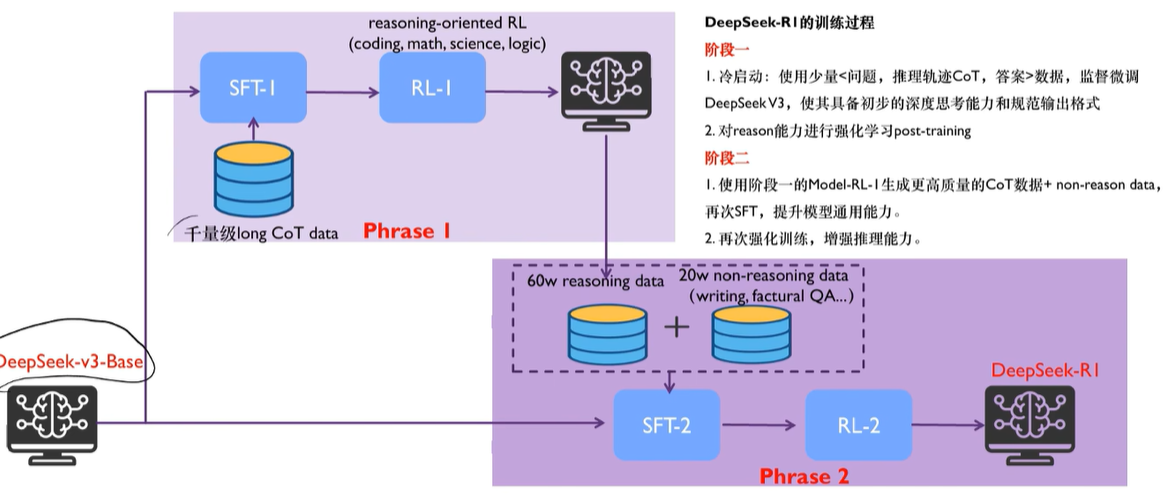
R1-zero这么牛,deepseek团队为啥还要继续推出R1了?说明R1-Zero也是有明显缺陷的,比如:poor readability,and language mixing,也就是model搜索找到的路径人未必能看懂,整个reasoning的过程不太符合人类预期,或者说经常中英文混杂语无伦次有点乱,所以基于R1-zero,又改进了一版:使用thousands of long-cot的数据,基于checkpoint fine-tuned 模型做SFT(生成清晰思维链的初始策略,本质是告诉模型解题过程,解决R1-Zero遇到的杂乱无章reasoning的问题)和reinforcement learning,得到了R1版本,也就是大家日常使用的那个版本!R1的训练流程总结:https://space.bilibili.com/3546611527453161/dynamic
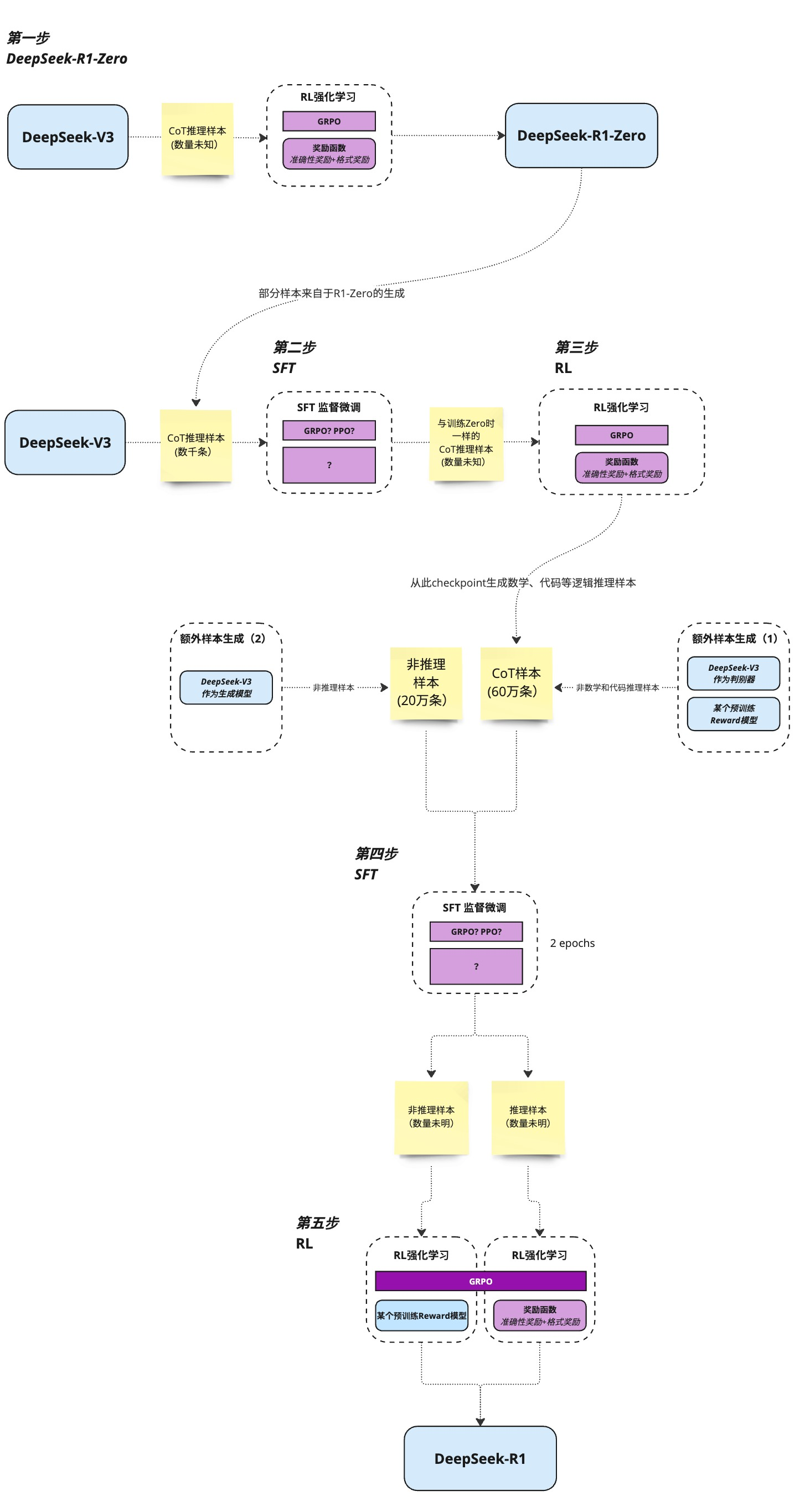
- R1成本低的原因之一:人工标注的数据也就几千条,剩余的数据都是base model或中间过渡model生成的,为了保证数据质量,用了规则或base model做检验,只保留高质量数据!base model和reasoning model的架构没变,是一样的,只是训练的数据和流程做了改进!
- 另一个要点:SFT和RL分别都做了两次,这是为啥?我个人觉得这是在借鉴人的学*思维方式:观察 Observe、判断 Orient、决策 Decide、行动 Act。SFT的作用是observe、orient,RL的作用是Decide、Act;每次迭代,都让model的能力螺旋上升!这里为什么是2轮,不是多轮了?可能是研发团队发现2轮的效果已经够好了,所以没在继续第3、4、5.....轮;总结如下:
- SFT:提供初始“种子”,定义输出规范并加速收敛,避免纯 RL 的冷启动缺陷(如果没有SFT,直接上RL,那么model初期会没有明确方向地随机探索,response全是杂乱无章的格式,就像无头苍蝇一样到处乱撞,浪费时间和算力)
- RL:通过自我迭代探索更优策略(aha moment),突破 SFT 数据局限,实现超越人类标注的推理能力,也就是提升泛化能力generalization ability
- 整个过程和GRPO的原理不是一样的么?让LLM产生很多output,然后选择reward高的output让LLM继续学*(通过update 参数让reward高的output概率变大),这不就是人工手动实现GRPO么?llama3把这个流程循环了6次;
简单讲:SFT提供了response的template格式,RL增强model的泛化能力(出现aha moment);R1和其他LLM的对比测试:
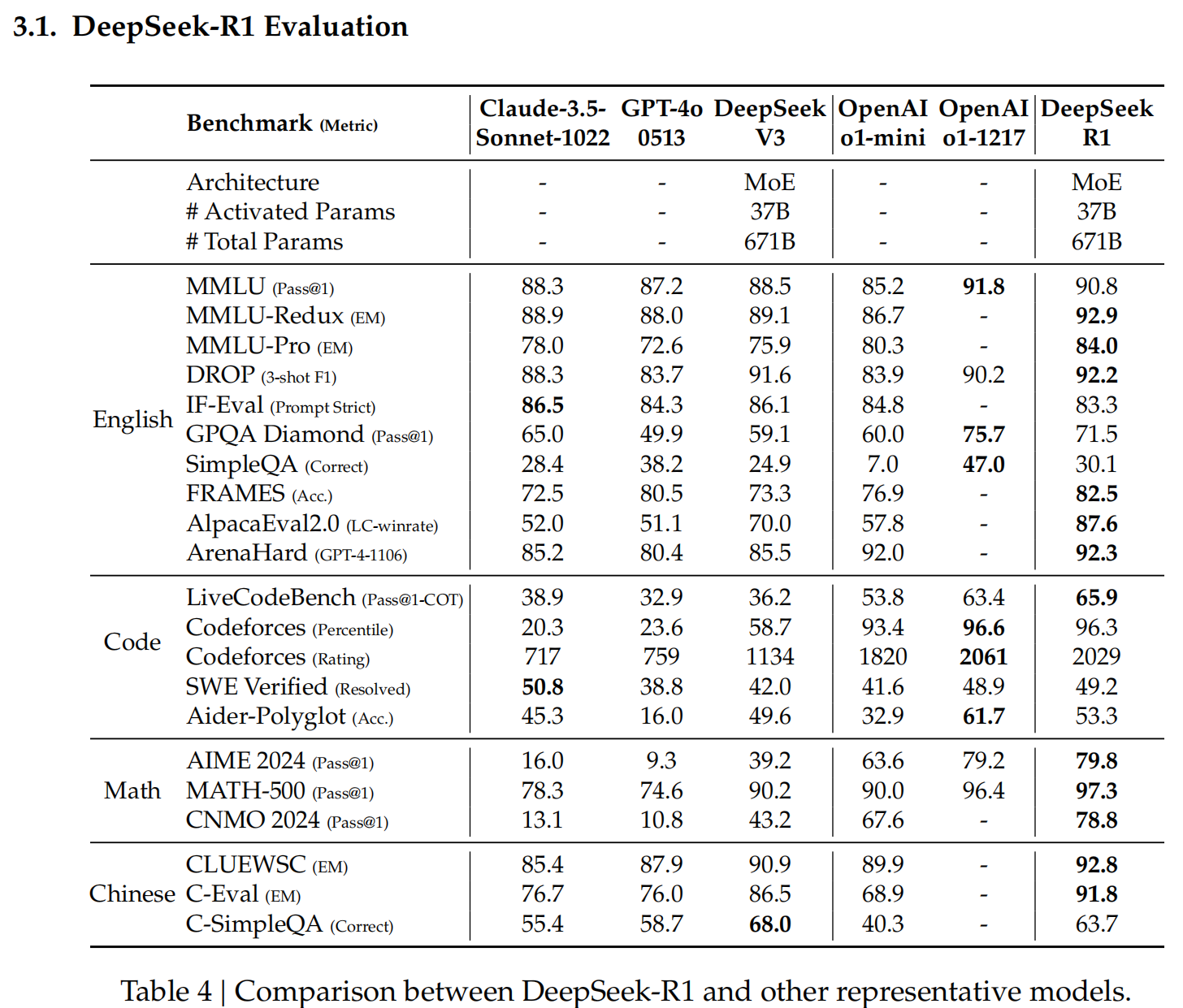
用R1蒸馏后的小模型效果对比:小模型能力差,并不是因为参数少,而是之前的训练方式不对;如果有好的teacher model,用teacher(必须要有COT能力的)蒸馏训练小模型,在某些细分的垂直领域,效果比直接用reinforcement learning训练小模型好!(大模型输出的是概率分布soft target,包含了很多dark knowledge;小模型如果自己用SFT或RL学,目标是hard target,信息少了很多;详见:https://www.cnblogs.com/theseventhson/p/18303028 ) 从下面的对比就能看出,distll中1.5B模型的性能在某些特定数据集上达到了GPT-4O的水平,32B的性能达到了o1-mini的水平,小模型也能有大能力啊!
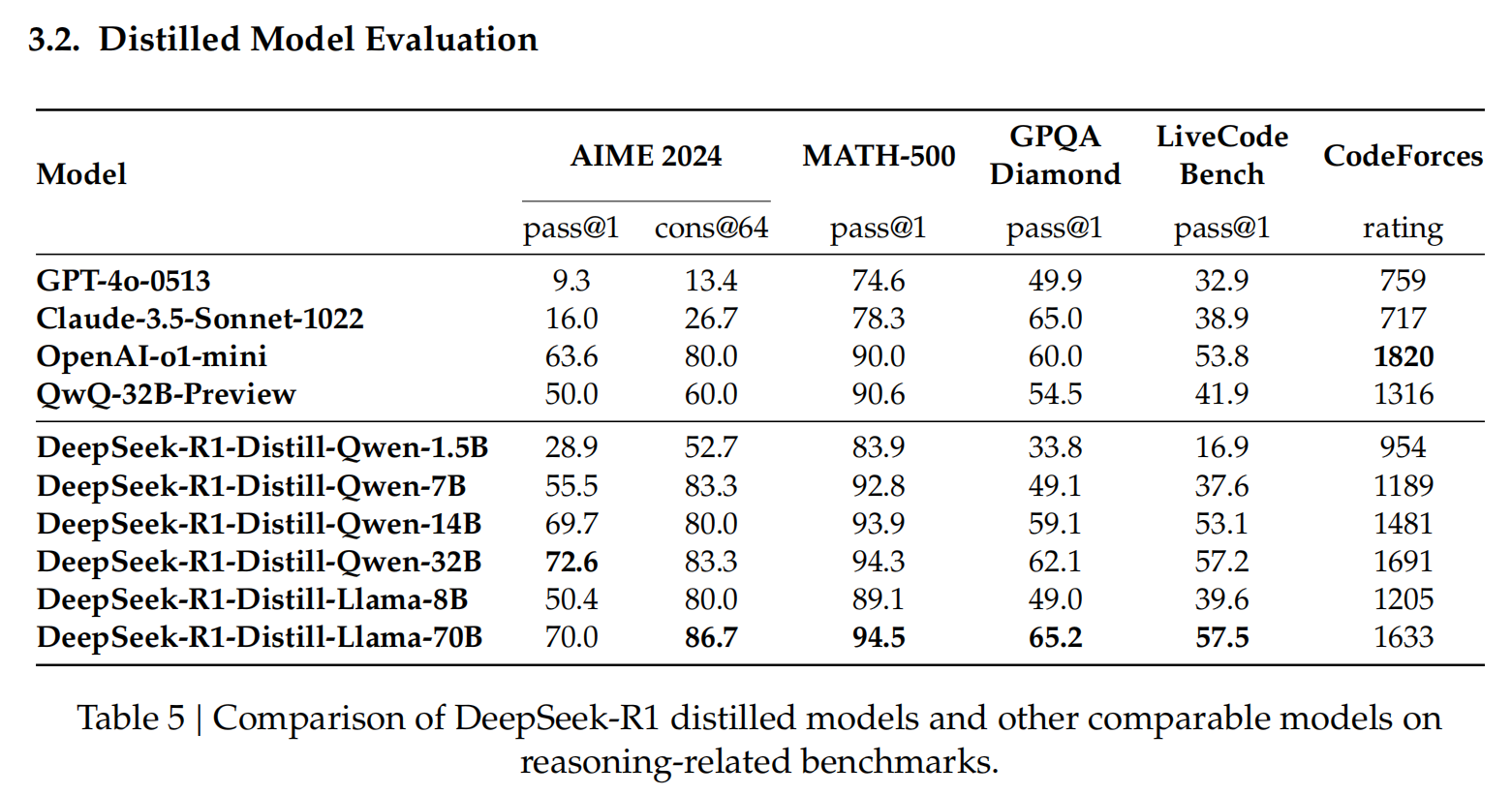
base model都是QWQ32B,原始模型、R1-Zero方法微调的模型、distllation模型的结果对比:蒸馏的效果明显是最好的

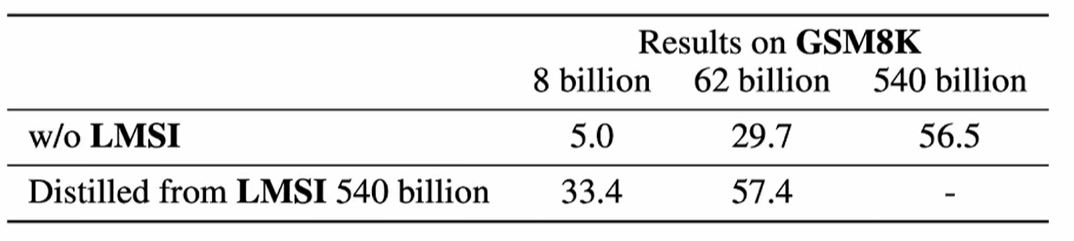
llama3的论文早在deepseek-R1前就发现了这个现象:用具有COT能力的大模型distllation得到的小模型,性能比不具备COT的pre-train大模型还好!比如62B是用具备COT能力的大模型蒸馏得到的,性能比540B的pre-train模型效果还好!
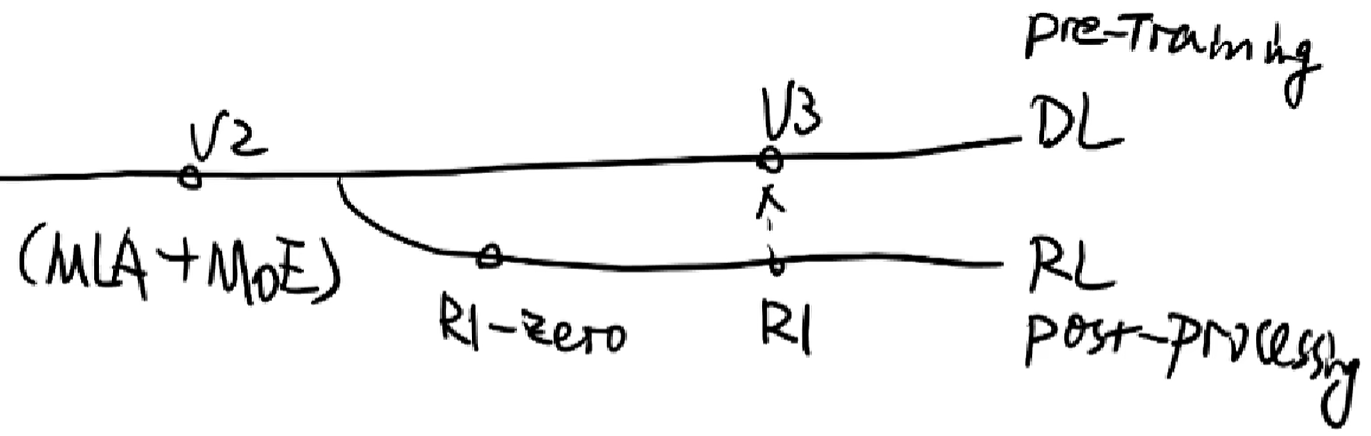
(4)deepseek大模型的演进:
R1成本低的原因:
- value model被Ai的计算公式替代; reward model计算r也被一些规则替代(详见 https://www.cnblogs.com/theseventhson/p/18699462 ),这两者都不是通过neural network实现的,不再需要标注数据;整个流程只剩poliy model需要train了!
- 初始人工标注的数据也就数千条,这部分标注的成本不高。利用这部分数据初步SFT微调base model,得到一个中间过渡model;然后用这个过渡model生成R1所需的大量cot数据和non-reasoning data;R1所需的数据主要由过渡版本生成的,所以数据的成本也不高(当然过渡版本本身肯定有性能问题,所以生成的样本数据需要用规则或base model判断一下质量,只保留质量好的数据)!这可以无限“套娃”,互相增强,可以让“子子孙孙model无穷尽也”!这种方式一旦自动化,也能让model实现自我迭代、自我更新 self - evaluation!
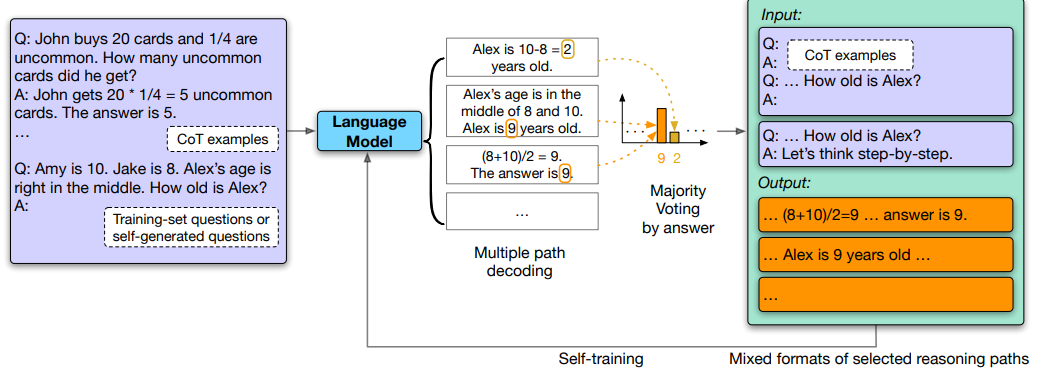
deepseek的这个思路其实在2022.10月份的时候就有人提出了,论文地址: https://arxiv.org/pdf/2210.11610.pdf Large Language Models Can Self-Improve;原论文的思路:通过self-consistance找到正确的response,然后用这些response反过来self-train自己的LLM,本质还是人工手动实现GRPO!这些正确的response多次被用于SFT,让LLM产生的概率越来越大,最终的response也就越正确!经过多次迭代后,正确response生成的概率被极大强化了,所以这个叫“强化学*”!
以下纯属个人观点:
1、reforcement learning模拟人的思考过程,是通往AGI的必经之路(但不一定是最终的路线,后续基于reforcement learning可能会诞生新的训练和学*机制)
2、即使使用了RL训练模型,但base model仍然是基于transformer架构,仍然不具备真正意义的AGI,只不过是经过RL后逻辑推理问题能力有所提升,在一定程度上弥补了transfomer架构的缺陷!
3、aha moment是最值得关注的,这就代表了自我反思、自我评价,如果所有的model在做RL的时候都能出现aha moment,那后续model就能自己迭代,不需要人为干预了,这才是真正的智能!
4、传统的RL和Deepseek的GRPO核心区别:
-
传统RL:大量包含解题步骤的高质量数据和精确的reward function,然后大力出奇迹训练!
- 有long-cot,属于是有标准答案的这种,所以model完全按照long-cot去拟合靠拢,本质是按照训练数据的标准答案、解题过程去学*,没有多个答案之间互相对比(没有答案的优劣区分),有点像填鸭式的应试教育
-
GROP:reward灵活,每个问题生成多个responce,找到最优的几个,引导model向最优的方向靠拢;
- 解题时有多个答案,互相比较,找到最优的解题思路;
- 没有标准的cot答案(只有最终的答案), 需要model自己做大量探索,找到最优cot,所以model有aha moment,泛化性好一些;有点像刚毕业的小年轻,*惯了在学校学*标准答案,但是工作后可能没标准答案了,需要自己探索,只能不停地各种试错,最终找到解决问题的最优路径;
- 这样做前期100多step输出的reason格式很混乱,所以R1在R1-zero的基础上先用long-cot做SFT,让model的responce先按照既定的template输出,适当减少一些探索的step,提升train效率
5、这里的SFT和RL作用的核心区别:
- SFT:规范模型输出格式(带上reasoning和answer标签),很难学到数据背后的数学规律和metaCOT,还是只能学到next token的生成概率;换句话说,泛化能力差,只负责记忆,获取人类的先验知识(坏处就是可能会限制LLM的search能力)!
- RL:通过试错和尝试(GRPO只看结果,过程由模型自己摸索和尝试,这就是概率模型的好处:探索的过程可能产生“基因突变”;探索过程explore & exploit,这是RL产生generalization的根因),鼓励模型在最大化奖励过程中学*到推理背后的规律,获得的泛化性和推理表现上界更高;
- 通过消耗大量算力search找到最优路径:searching for optimal reasoning trajectories by using computational resources
deepseek-R1-Zero不用SFT,而是直接RL,可能是借鉴AlphaGo的思路:直接用RL下围棋,去掉了使用SFT掌握人类先验知识的步骤,让RL不但掌握了人类的知识,还通过explore&exploit学到了新的知识,走出了move37这一步,打败了人类!


参考:
3、https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf https://github.com/chenzomi12/AIFoundation/tree/main/09News/00others

 浙公网安备 33010602011771号
浙公网安备 33010602011771号