Oracle Schema Objects——Index
索引主要的作用是查询优化.
查看执行计划的权限:查看执行计划plustrace:set autotrace trace exp stat(SP2-0618、SP2-0611)
Oracle索引Index
索引
- 就像一个目录,很快搜索数据
- 目的---用于加快数据的访问
- 缺点---占据额外空间,影响DML操作的效率(在表上进程操作时,同时会更新索引的键值)。
- 索引也是段对象,会占用一定的空间。
索引的种类
- 按数据的组织方式
– B-tree B树索引
– Bitmap 位图索引
– TEXT 全文索引
|
创建索引: |
create index idx_t_part on t_part(id); |
|
查看索引大小: |
SQL> desc t; SQL> desc user_segments; SQL> select sum(bytes) from user_segments where segment_name='T';
SQL> create index idx_t on t(name); SQL> select sum(bytes) from user_segments where segment_name='IDX_T';
注意:上面红色部分一定要写大写。 |
|
(SQL语句的资源消耗情况) |
set autotrace trace exp stat; set autotrace off; |
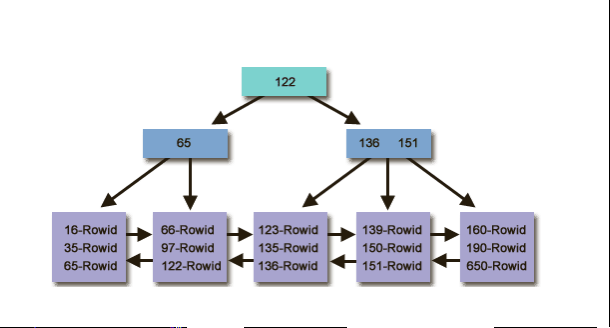
- B-tree 索引
- 想象一下书的目录
- 这类索引很快,可以使用如下语句查看
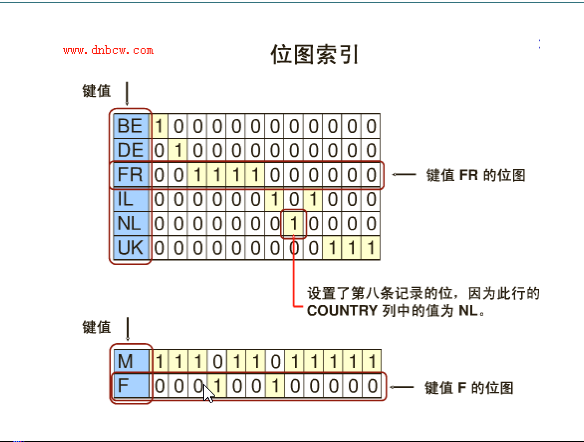
- Bitmap 位图索引
- 字段重复率很大时,B-tree就没有意义了
- 用在数据仓库比较多
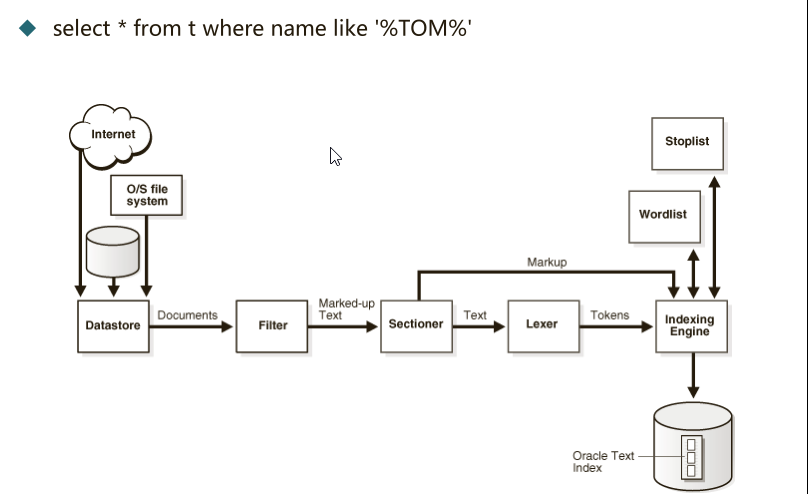
- TEXT 全文索引
- Select * from t where name like ‘%TOM%’
索引基本介绍
- 在数据库之中,索引是一种专门用于数据库查询操作性能的一种手段。
- 在Oracle之中为了维护这种查询性能,需要对某一类数据进行指定结构的排列。
- 但是在Oracle之中,针对于不同的情况会有不同的索引使用,
- 主要讲解Oracle中的:B树索引、降序索引、位图索引、函数索引。
B*Tree索引
- B树索引(又写为:B*Tree)是最为基本的索引结构,在Oracle之中默认建立的索引就是此类型索引。
- 一般B树索引在检索高基数数列(该列上的重复内容较少或没有)的时候可以提供高性能的检索操作。
- 实现方式
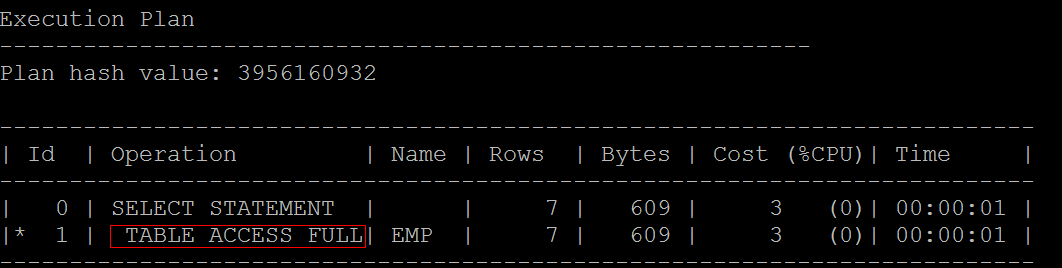
- 默认情况下,如果要使用查询,需要采用逐行扫描.
- 如果emp有500万条,那么这500万条记录都要被扫描.
- 如果200万条已经没有满足条件的数据了,但是默认还是需要全部索引.
- 逐行扫描就表示全表扫描,
- 可以打开跟踪(需要权限):SET AUTOTRACE ON
- 查询工资大于1500的全部雇员:SELECT * FROM emp WHERE sal>1500 ;
TABLE ACCESS FULL
如果不想全部查询,就要将数据以树的形式展现出来。
在树排列时,要利用ROWID找到对应数据.利用ROWID实现的查询很快.
如果emp表中的工资数据为:“1300、2850、1100、1600、2450、2975、5000、3000、1250、950、800”,则现在可以按照以下的原则进行树结构的绘制:
- 取第一个数据作为根节点;
- 比根节点小的数据放在左子树,比根节点大的数据放在右子树
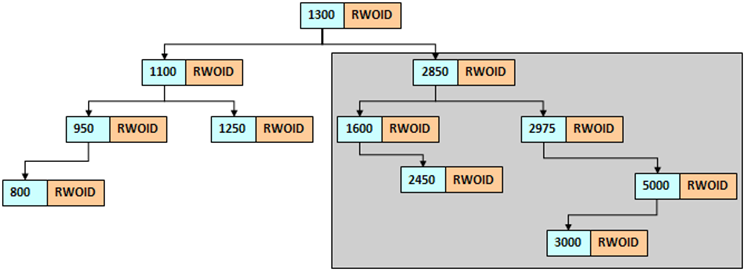
B树索引
- B-Tree索引由分支块(branch block)和叶块(leaf block)组成。
|
分支块(branch block) |
树结构中,位于最底层底块被称为叶块, 包含每个被索引列的值和行所对应的rowid。 |
|
叶块(leaf block) |
在在叶节点的上面是分支块,用来导航结构, 包含了索引列(关键字)范围和另一索引块的地址。 |
创建B*Tree索引
CREATE INDEX [用户名.]索引名称 ON [用户名.]表名称 (列名称 [ASC | DESC] , …) ;
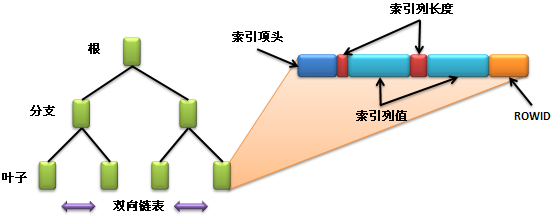
主要包含的组件如下所示:
|
叶子节点(Leaf Node) |
包含直接指向表中的数据行(即:索引项); |
|
分支节点(Branch Node) |
包含指向索引里其他的分支节点或者是叶子节点; |
|
根节点(Root Node) |
一个B树索引只有一个根节点,是位于最顶端的分支节点。 |
每一个索引项都由下面三个部分组成:
|
索引项头(Entry Header) |
存储了行数和锁的信息; |
|
索引列长度和值 |
两者需要同时出现,定义了列的长度而在长度之后保存的就是列的内容; |
|
ROWID |
指向表中数据行的ROWID,通过此ROWID找到完整记录。 |
在数据字典user_indexes,user_ind_columns;中查看INDEX 对象
范例:最好的索引是在高基数列上使用.
|
在emp.sal字段上创建emp_sal_ind索引 |
|
CREATE INDEX emp_sal_ind ON emp(sal) ; |
|
查询:现在是根据基数扫描方式查询 |
|
SELECT * FROM c##scott.emp WHERE sal>1500 ;
|
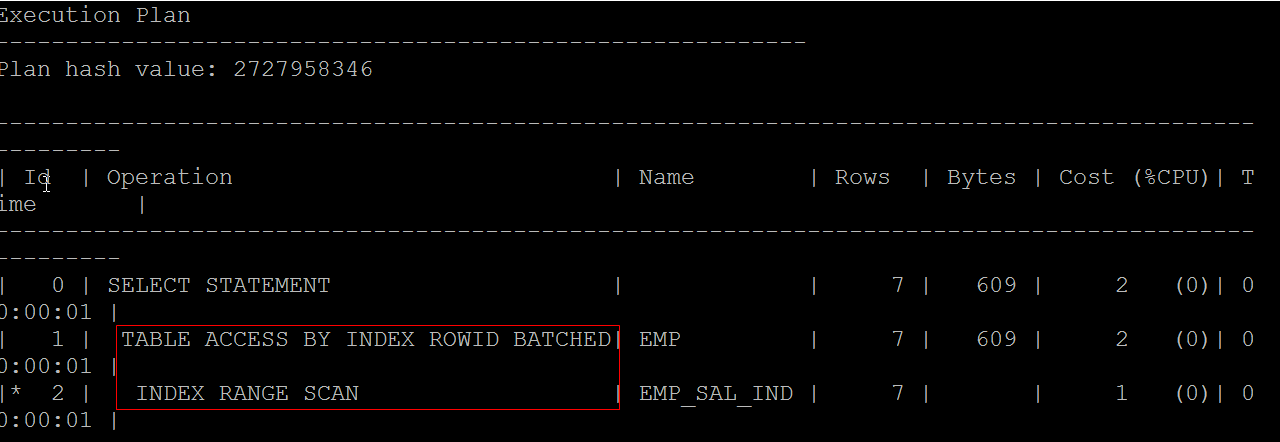
索引不一定能提升性能.如果数据量大,到处都是多表关联,提升性能最好的做法是通过冗余字段,减少多表查询.
索引如果要正常操作,必须维持这一棵树,如果表中的数据要被频繁修改,每次都要重复修改树。
如果要保持高速查找,要接收频繁更新.方法是用时间换空间,牺牲实时性.
降序索引
|
在hiredate字段上设置降序索引 |
|
CREATE INDEX emp_hiredate_ind_desc ON c##scott. emp(hiredate) ; |
|
查询在1981年雇佣的雇员信息 |
|
SELECT * FROM c##scott.emp WHERE hiredate BETWEEN TO_DATE('1981-01-01','yyyy-mm-dd') AND TO_DATE('1981-12-31','yyyy-mm-dd') ORDER BY hiredate DESC ;
|
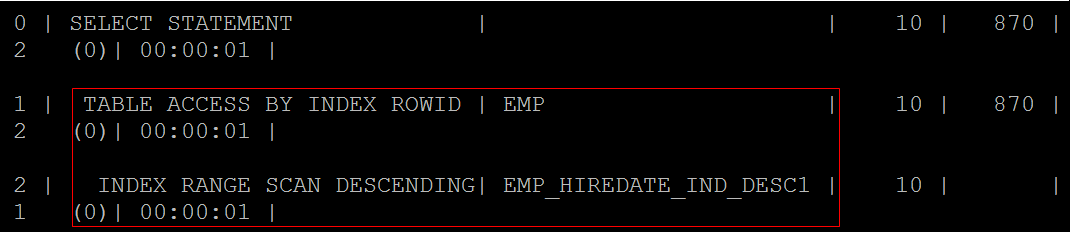
函数索引(b树索引的衍生品)
|
创建函数索引 |
|
CREATE INDEX emp_ename_ind ON emp(LOWER(ename)) ; |
|
查询在1981年雇佣的雇员信息 |
|
SELECT * FROM c##scott.emp WHERE LOWER(ename)='smith' ; |
位图索引
- 如果说现在某一列上的数据都属于低基数(Low - Cardinality)列的时候就可以利用位图索引来提升查询的性能,
- 例如:表示雇员的数据表上会存在部门编号(deptno)的数据列,而在部门编号列上现在只有三种取值:10、20、30 ,在这种情况下使用位图索引是最合适的。
位图索引原理
- 对于表中的每一数据行的位图包含了deptno = 10、deptno = 20或dept = 30值,现在一共只包含了3个基数,如果说现在表中有30W条记录,那么最终这些列也只分为了3组,这样在进行位图查找的时候可以非常的方便和快捷。同时,位图索引以一种压缩数据的格式存放,因此所占用的磁盘空间要比B*Tree索引小很多。
创建位图索引
- CREATE BITMAP INDEX [用户名.]索引名称 ON [用户名.]表名称 (列名称 [ASC | DESC] , …) ;
|
在deptno字段上设置位图索引 |
|
CREATE BITMAP INDEX emp_deptno_ind ON emp(deptno) ; |
|
根据部门编号查找雇员信息 |
|
SELECT * FROM c##scott.emp WHERE deptno=10 ; SELECT * FROM c##scott.emp WHERE deptno=10 AND deptno=20 ; |
删除索引
- 于索引本身需要进行自身数据结构的维护,所以一般而言会占用较大的磁盘空间。并且随着表的增长,索引所占用的空间也会越来越大。那么对于数据库之中那些不经常使用的索引就应该尽早删除。索引是以Oracle对象存在的,所以用户可以直接利用DROP语句进行索引的删除。
- 删除索引
- DROP INDEX 索引名称 ;
|
删除emp_sal_ind索引 |
|
DROP INDEX emp_sal_ind ; |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号