CSapp lab5 MAlloc Lab以及段错误处理 && CSapp第九章学习 2 Linux虚拟内存系统与Linux进程虚拟地址空间
上个博客CSapp lab5 MAlloc Lab && CSapp第九章学习 1 更加深入的计算机体系结构学习 - TheDa - 博客园 (cnblogs.com)遗留的问题:缺页处理程序如何定位Disk当中的缺失页的位置?
QQQQQQQQQQQQQQ注意以上问题!!!!!!!!!!!!!!!!
在《程序员的自我修养》学习笔记 && Linux环境下的编译,链接综合学习 - TheDa - 博客园 (cnblogs.com)这篇博客已经有了对于Linux进程地址空间的一些学习和介绍。

如图所示。
首先,必须知道,Linux各进程有独立的地址空间。
我们对于段很熟悉。前面已经介绍了Linux的分页机制。段就是在分页的基础上分段,如上图所示。
我们还需要关心的有Linux的虚拟内存管理的数据结构。
首先,Linux的进程是由task_struct这个数据结构来管理的。
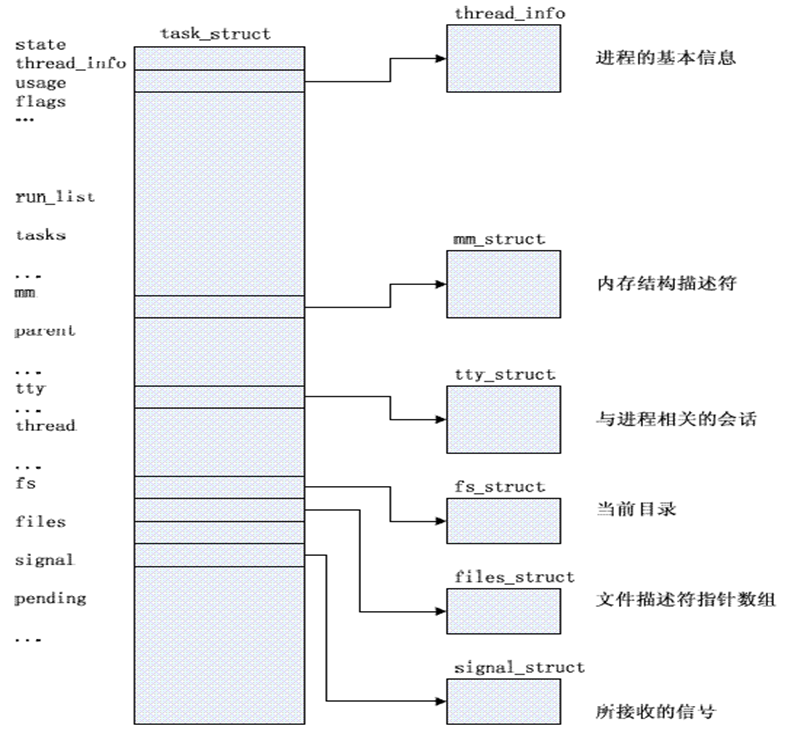
我们关心的是task_struct当中的mm,它指向的是mm_struct。mm_struct描述的是进程的虚拟地址空间。
如CSapp上的下图所示:

或者用我本科时学习Linux操作系统的图:

mm_struct的源代码描述如下:
struct mm_struct { struct vm_area_struct * mmap; /*指向VMA链表表头的指针*/ rb_root_t mm_rb; /*指向进程红黑树的根*/ struct vm_area_struct * mmap_cache; /*指向最后使用的VMA*/ pgd_t * pgd; /*指向进程页目录表的指针*/ atomic_t mm_users; /*用户空间数*/ atomic_t mm_count; /* 访问mm_struct结构的计数*/ int map_count; /* VMA的数量 */ struct rw_semaphore mmap_sem; /*读写信号量*/ spinlock_t page_table_lock; /*保护任务页表和mm->rss*/ struct list_head mmlist; /*所有活动mm的列表*/ unsigned long start_code, end_code, start_data, end_data; /*分别为代码段、数据段的 首地址和终止地址*/ unsigned long start_brk, brk, start_stack; /*堆位置及栈顶地址*/ unsigned long arg_start, arg_end, env_start, env_end; /*分别为参数区、环境变量区的首地址和终止地址*/ unsigned long rss, total_vm, locked_vm; /*驻留内存页框总数,VMA总数及被锁 VMA总数*/ unsigned long def_flags; unsigned long cpu_vm_mask; unsigned long swap_address; unsigned dumpable:1; mm_context_t context; /*和具体硬件结构有关的MM上下文*/ };
我们对于mm_struct所感兴趣的字段有两个,一是pgd,二是mmap。
pgd指向的是页全局目录(第一级页表)的虚拟地址,CR3指向的是页全局目录(第一级页表)的物理地址。(这句话不确定是否正确)
当内核kernel运行这个进程的时候,就会把pgd放在CR3控制寄存器中(这句话是CSapp的原话)。Linux的进程切换会更加复杂,但是这个东西不是我们在这里讨论的。
mmap指向一个vm_area_struct的首地址。

一个vm_area_struct指向的就是一个vma(虚拟内存区域)。如上图,这些vma是按照地址顺序排序的,如果vma的数目太大的话,就会使用AVL树排序。
vm_area_struct的代码如下:
struct vm_area_struct { struct mm_struct * vm_mm; /*指向进程的mm_struct结构体*/ unsigned long vm_start; /*虚拟区域的开始地址*/ unsigned long vm_end; /*虚拟区域的终止地址*/ /*每个进程的虚存区域链表,按地址排序*/ struct vm_area_struct vm_next; /*指向下一个vm_area_struct结构体,链表的首地址由*/ /*mm_struct中成员项mmap指出*/ pgprot_t vm_page_prot; /*该VMA的访问权限*/ unsigned short vm_flags; /*指出虚存区域的操作特性*/ struct rb_node vm_rb; /*红黑树*/ struct list_head shared; struct vm_operations_struct * vm_ops; /*该结构体中包含着指向各种操作的函数的指针*/ /* 后援存储器的信息*/ unsigned long vm_pgoff; /*PAGE_SIZE单元中的偏移量*/ unsigned long vm_offset; /*该区域的内容相对于文件起始位置的偏移量,或相对于共享内存首址的偏移量*/ struct file * vm_file;/* 若虚存区域映射的是磁盘文件或设备文件的内容,则vm_file指向这个文件,否则为NULL*/ void * vm_private_data; /*共享内存页表vm_pte */ };
对于vm_area_struct来说,比较重要的字段如下:(来自CSapp上的原话)

基于上述的数据结构,我们再来剖析一下完整的Linux缺页异常处理。
首先发生缺页时,必定是MMU持有某一个虚拟地址A,触发了缺页异常,转到内核kernel当中的缺页异常处理程序。
下面是CSapp当中的原话:



这一段是有关缺页时的一些基础权限之类的问题,可以用下图总结:
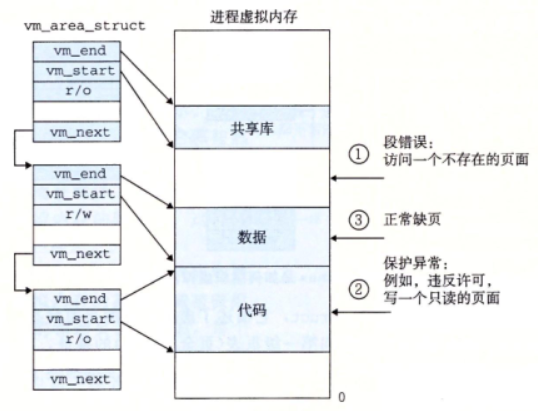
但是我更为关心的是这个至今还未解决的问题:如何通过VA找到Disk当中的Page?
这个问题的答案在CSapp第三版 9.8内存映射当中。

需要通过内存映射将Disk当中的程序和数据加载到Memory当中。
可是书上还是没有具体说是怎么映射的。现在进入CSapp lab Malloc Lab。
用户级内存映射使用如下两个函数,但是这里我们不详细讨论他们。mmap函数用来创建新的vma,然后将对象隐射到这些区域当中。munmap用来删除虚拟内存区域。


但是实际中,更常用的是动态内存分配。
动态内存分配维护的虚拟内存区域就叫做heap(堆)。
对于每个进程,当然堆不同。内核维护一个变量brk,指向进程中堆的顶部。
然后结合这张图了解一下什么是内存分配器:



在CSapp的Malloc Lab实验当中,需要实现自己的动态内存分配函数:malloc、free、realloc。

malloc函数如上图所示。
malloc函数可以基于mmap和munmap函数实现,但是在这个实验中不被允许。也可以基于sbrk函数实现,但是这也不被允许。
动态内存分配器干的是什么活呢?CSapp给我们举了一个例子:

在实现动态内存分配器的时候,需要注意到的一个很重要的问题就是fragmentation(碎片)问题。fragmentation分为internal fragmentation(内部碎片)以及external fragmentation(外部碎片)。
内部碎片就是上面的需要分配的内存对齐的问题。
外部碎片就是虚拟内存中的vma之间的,难以插入大vma的碎片。
所以动态内存分配器需要干的就是,对于vma,空闲块,分配块的放置,分割,合并,释放等问题。
放置块涉及first fit(首次适配法),next fit(下一次适配法),best fit(最佳适配法)等placement policy(放置策略)。
合并空闲块想一想就是一个非常复杂的过程。我们在完成CSapp的这个实验的时候参考书上9.9.12的代码以及https://www.cnblogs.com/liqiuhao/p/8252373.html这个大佬的博客。
CSapp MallocLab实验发生段错误怎么处理:
首先,我们知道CMU设计的MallocLab这个实验需要我们在实验目录下首先输入make,来生成mdriver这个可执行文件。然后输入
 以及
以及

这两条命令,就能够得到测试结果了。
但是遗憾的是,很多小伙伴像我一样,make成功了,但是输入这两条测试命令的时候显示段错误。
为什么呢?
首先我们了解一下make干了什么。
我不太明白,但是打开Makefile这个文件:
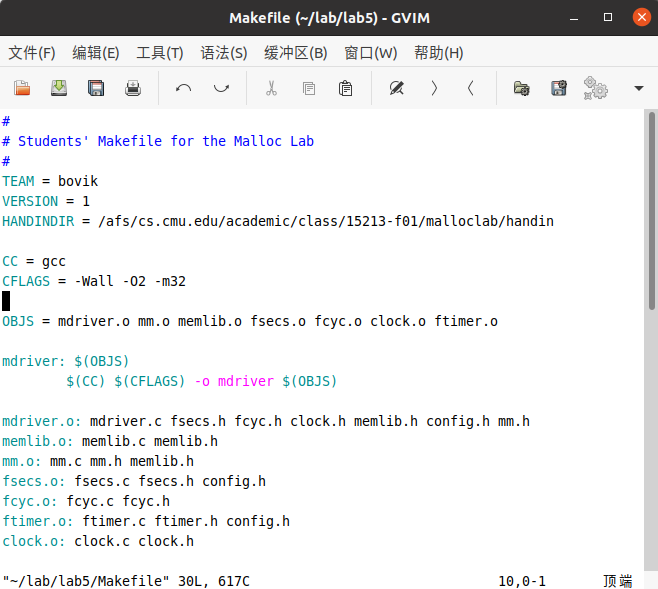
注意,一开始是没有-m32这个编译参数的。所以你执行make的时候就是编译出64位的可执行程序mdriver。
然而在mm.c的

这句话就是发生段错误的原因。
在32位的程序中,这段代码是没问题的,因为32位程序中的指针显然只有32bit,但是64位的程序中的指针是有64bit的。然而后面的(unsigned int)类型的数据,无论是在32位或者是64位的程序,都是32bit也就是4B的。
所以,我们rm mdriver,将现有的mdriver删掉,然后再make重新生成新的mdriver。
在make之前,首先将上面的CFLAGS加上一个-m32
然后make
但是很遗憾:

我们注意到上面的gcc -Wall -O2 -m32 -o mdriver ............
再看看下面的,显然就是生成的mdriver的之前的各种.o文件还是64bit的。所以,我们执行7次这样的类似操作:

注意编译参数加上-c 即只编译不链接。
然后我们不make了。
直接gcc -Wall -O2 -m32 -o mdriver mdriver.o mm.o ........就可以,完整的代码在上面的图片里有。
最后生成的mdriver是可以用的!直接


成功得到测试结果!
当然,我觉得NB的大佬可以直接对于make相关的文件修改使得make适配64位的机器。当然make本质上就是一个编译链接的脚本,我们手动编译链接也是可以的。
成功地跑了别人的代码,最重要的还是如何读懂别人的代码。
很重要的一个前置知识,在CSapp第三版9.9.11当中。
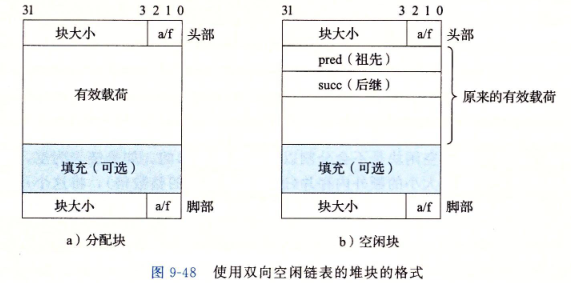
普通的堆块:

改进之后的堆块

这个东西解决的是释放当前block的时候,如何合并前面的空闲block以及后面的空闲block。
我们知道,块就是一系列VMA和空闲区域,它们按照地址升序的顺序串在一起。(不知道是否准确,VMA一定是被占用的)
我们知道,VMA只有单向链表,这里的block也是只有单向链表。(具体是怎么实现的不太清楚)从当前的Block只能知道下一个block的起始地址,然后通过下一个block头部的信息就能够知道下一个block是否空闲,是否能合并。
如果没有如图的东西,由于链表的单向性,我们只能从第一个block开始一个一个向后找,直到找到我们当前释放的block,并每次链表跳转都记录前一个block的起始地址。(虽然我们知道释放的block的起始地址的前面一点点地方就是前一个块,但是没有办法知道这个block的起始地址呀)
显然如CSapp的书上所说,这样做的开销是很大的。
正确的优化方法就是如上面,每个block的尾部地址都加一个和块开头一样的块信息。这样,我们在释放当前块的时候,当前块首地址前面的一点点就是前面的block的全部信息了。
而且这里是隐式空闲链表,我们可以实现为显式空闲链表。
显式空闲链表还使用了分离链表以及分离适配。
正式分析程序。
前面的一些宏都是书上的,在P599上面。
首先分析一下malloc函数。

程序员希望这个函数能自动在堆上分配大小为size的block。
因此,
/* * mm-naive.c - The fastest, least memory-efficient malloc package. * * In this naive approach, a block is allocated by simply incrementing * the brk pointer. A block is pure payload. There are no headers or * footers. Blocks are never coalesced or reused. Realloc is * implemented directly using mm_malloc and mm_free. * * NOTE TO STUDENTS: Replace this header comment with your own header * comment that gives a high level description of your solution. */ #include<stdio.h> #include<stdlib.h> #include<assert.h> #include<unistd.h> #include<string.h> #include "mm.h" #include "memlib.h" /********************************************************* * NOTE TO STUDENTS: Before you do anything else, please * provide your team information in the following struct. ********************************************************/ team_t team = { /* Team name */ "TheDa", /* First member's full name */ "Wuruohan", /* First member's email address */ "1150562000@qq.com", /* Second member's full name (leave blank if none) */ "", /* Second member's email address (leave blank if none) */ "" }; /* single word (4) or double word (8) alignment */ #define ALIGNMENT 8 //对齐字节数目 #define ALIGN(size) ((((size) + (ALIGNMENT-1)) /(ALIGNMENT))*(ALIGNMENT)) //对齐宏定义 #define SIZE_T_SIZE (ALIGN(sizeof(size_t))) #define WSIZE 4 //32位处理器中一个字的大小是4B #define DSIZE 8 //32位处理器中一个双字的大小是8B /* 每次扩展堆的块大小(系统调用“费时费力”,一次扩展一大块,然后逐渐利用这一大块) */ #define INITCHUNKSIZE (1<<6) //堆的初始大小 #define CHUNKSIZE (1<<12) //扩展堆的最小大小 #define LISTMAX 16 //这里的空闲块链表,按照1,2,4,8的大小分类,最大2的32次方大小 #define MAX(x, y) ((x) > (y) ? (x) : (y)) #define MIN(x, y) ((x) < (y) ? (x) : (y)) #define PACK(size, alloc) ((size) | (alloc)) //size是block大小,alloc是block的分配属性,这两个信息一起设置 #define GET(p) (*(unsigned int *)(p)) //读取位于p指针位置的一个字 #define PUT(p, val) (*(unsigned int *)(p) = (val)) //将val的值写入p指针位置 #define SET_PTR(p, ptr) (*(unsigned int *)(p) = (unsigned int)(ptr)) //p指针位置的值变成指针ptr指向的地址 #define GET_SIZE(p) (GET(p) & ~0x7) //得知这个block的大小 #define GET_ALLOC(p) (GET(p) & 0x1) //得知这个block是否被分配了 #define HDRP(ptr) ((char *)(ptr) - WSIZE) //ptr可以是当前block的首地址,得到当前block的首地址 #define FTRP(ptr) ((char *)(ptr) + GET_SIZE(HDRP(ptr)) - DSIZE) //ptr可以是当前block的首地址,得到当前block的尾部地址 #define NEXT_BLKP(ptr) ((char *)(ptr) + GET_SIZE((char *)(ptr) - WSIZE)) //ptr可以是当前block的首地址,ptr-4B指向的位置是当前block的头信息,因此得到下一个block的首地址 #define PREV_BLKP(ptr) ((char *)(ptr) - GET_SIZE((char *)(ptr) - DSIZE)) //ptr可以是当前block的首地址,ptr-4B*2指向的位置是上一个block的尾部信息,因此得到上一个block的首地址 #define PRED_PTR(ptr) ((char *)(ptr)) //显示空闲链表祖先指针 #define SUCC_PTR(ptr) ((char *)(ptr) + WSIZE) //显示空闲链表后继指针,向低地址方向,就是开头空闲链表方向 #define PRED(ptr) (*(char **)(ptr)) // #define SUCC(ptr) (*(char **)(SUCC_PTR(ptr))) // void *segregated_free_lists[LISTMAX];//空闲链表,在这里遍历空闲块 static void *extend_heap(size_t size);//扩展推 static void *coalesce(void *ptr);//合并相邻的Free block static void *place(void *ptr, size_t size);//在prt所指向的free block块中allocate size大小的块,如果剩下的空间大于2*DWSIZE,则将其分离后放入Free list static void insert_node(void *ptr, size_t size);//将ptr所指向的free block插入到分离空闲表中 static void delete_node(void *ptr);//将ptr所指向的块从分离空闲表中删除 static void *extend_heap(size_t size)//扩展堆,扩展大小为Size的堆空间,返回堆扩展得到的空闲block的ptr { void *ptr; size = ALIGN(size);//首先对齐内存 if ((ptr = mem_sbrk(size)) == (void *)-1)//系统调用“sbrk”,看看是否能够成功扩大这么大的堆空间 //如果成功的话返回新的堆上界地址brk(堆是向上生长的,高字节方向) return NULL; PUT(HDRP(ptr), PACK(size, 0));//设置头部大小是size,属性为空闲 PUT(FTRP(ptr), PACK(size, 0));//设置尾部大小是size,属性为空闲 PUT(HDRP(NEXT_BLKP(ptr)), PACK(0, 1));// 注意这个块是堆的结尾,设置一下结尾块 ,头尾信息结构 insert_node(ptr, size);/* 设置好后将其插入到分离空闲表中 */ return coalesce(ptr);/* 另外这个free块的前面也可能是一个free块,可能需要合并 */ } static void insert_node(void *ptr, size_t size)//将ptr指向的大小为size的block插入空闲链表segregated_free_lists当中 { int listnumber = 0; void *search_ptr = NULL; void *insert_ptr = NULL; while ((listnumber < LISTMAX - 1) && (size > 1))/* 通过块的大小找到对应的链 */ { size >>= 1; listnumber++; } /* 找到对应的链后,在该链中继续寻找对应的插入位置,以此保持链中块由小到大的特性 */ search_ptr = segregated_free_lists[listnumber]; while ((search_ptr != NULL) && (size > GET_SIZE(HDRP(search_ptr)))) { insert_ptr = search_ptr; search_ptr = PRED(search_ptr);//insert_ptr的后一个指针是search_ptr } //最终得到的插入位置是insert_ptr,分情况将该block插入该空闲块链表当中 if (search_ptr != NULL)//说明插入位置的后一个块不是空,插入位置不是最后一个 { if (insert_ptr != NULL)//在中间插入 { //注意隐式空闲链表和显式空闲链表 SET_PTR(PRED_PTR(ptr), search_ptr);//插入块高地址方向是search_ptr SET_PTR(SUCC_PTR(search_ptr), ptr);// SET_PTR(SUCC_PTR(ptr), insert_ptr);//插入块低地址方向是insert_ptr SET_PTR(PRED_PTR(insert_ptr), ptr);// } else//插入位置的后面有block,插入指针为NULL,那么只能是在开头位置插入了 { SET_PTR(PRED_PTR(ptr), search_ptr); SET_PTR(SUCC_PTR(search_ptr), ptr); SET_PTR(SUCC_PTR(ptr), NULL); segregated_free_lists[listnumber] = ptr;//设置该条空闲链首指针 } } else { if (insert_ptr != NULL)//在结尾插入 { SET_PTR(PRED_PTR(ptr), NULL); SET_PTR(SUCC_PTR(ptr), insert_ptr); SET_PTR(PRED_PTR(insert_ptr), ptr); } else//该链为空,这是第一次插入 { SET_PTR(PRED_PTR(ptr), NULL); SET_PTR(SUCC_PTR(ptr), NULL); segregated_free_lists[listnumber] = ptr; } } } static void delete_node(void *ptr)//将ptr指向的block从空闲块链表删除 { int listnumber = 0; size_t size = GET_SIZE(HDRP(ptr));//得到当前块大小 while ((listnumber < LISTMAX - 1) && (size > 1))//通过块的大小找到对应的空闲链 { size >>= 1; listnumber++; } if (PRED(ptr) != NULL)//高地址方向,也就是后继块不为空 { if (SUCC(ptr) != NULL)//前向block不为空,中间删除 { SET_PTR(SUCC_PTR(PRED(ptr)), SUCC(ptr)); SET_PTR(PRED_PTR(SUCC(ptr)), PRED(ptr)); } else//前向block为空,删除空闲块链开头block { SET_PTR(SUCC_PTR(PRED(ptr)), NULL); segregated_free_lists[listnumber] = PRED(ptr); } } else//前向block为空,结尾删除 { if (SUCC(ptr) != NULL)//低地址方向,也就是前向块不为空 { SET_PTR(PRED_PTR(SUCC(ptr)), NULL); } else//整条空闲链就这一个block { segregated_free_lists[listnumber] = NULL; } } } static void *coalesce(void *ptr)//尽可能合并ptr指向的block周围的空闲块,mm_free调用,堆扩展调用,返回新block的ptr { _Bool is_prev_alloc = GET_ALLOC(HDRP(PREV_BLKP(ptr)));//低地址方向block分配了吗 _Bool is_next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(ptr)));//高地址方向block分配了吗 size_t size = GET_SIZE(HDRP(ptr));//当前block大小 /* 另外注意到由于我们的合并和申请策略,不可能出现两个相邻的free块 */ if (is_prev_alloc && is_next_alloc)//前后block均被分配了 { return ptr; } else if (is_prev_alloc && !is_next_alloc)//只有低地址方向block被分配,高地址方向未分配 { delete_node(ptr);//合并前先删除该空闲块 delete_node(NEXT_BLKP(ptr));//删除高地址方向空闲块 size += GET_SIZE(HDRP(NEXT_BLKP(ptr)));//修改size PUT(HDRP(ptr), PACK(size, 0));//新block的ptr位置就是ptr PUT(FTRP(ptr), PACK(size, 0));//注意size已经改变了,FTRP可以正常使用 } else if (!is_prev_alloc && is_next_alloc)//只有高地址方向block被分配,低地址方向未分配 { delete_node(ptr);//合并前先删除该空闲块 delete_node(PREV_BLKP(ptr));//删除低地址方向空闲块 size += GET_SIZE(HDRP(PREV_BLKP(ptr)));//修改size PUT(FTRP(ptr), PACK(size, 0));//新block的脚部分位于原ptr的foot PUT(HDRP(PREV_BLKP(ptr)), PACK(size, 0));//新block的头部分位于低地址方向空闲块ptr的头 ptr = PREV_BLKP(ptr);//ptr变为低地址方向空闲块ptr } else//前后两个块都是free块,这时将三个块同时合并 { delete_node(ptr); delete_node(PREV_BLKP(ptr)); delete_node(NEXT_BLKP(ptr)); size += GET_SIZE(HDRP(PREV_BLKP(ptr))) + GET_SIZE(HDRP(NEXT_BLKP(ptr))); PUT(HDRP(PREV_BLKP(ptr)), PACK(size, 0)); PUT(FTRP(NEXT_BLKP(ptr)), PACK(size, 0)); ptr = PREV_BLKP(ptr); } insert_node(ptr, size);//将合并好的free块加入到空闲链接表中 return ptr; } //在ptr所指向的空闲块中插入size大小的块,如果剩下的空间大于2*DWSIZE,则将其分离后放入Free list,返回最终块被分配的位置 static void *place(void *ptr, size_t size) { size_t ptr_size = GET_SIZE(HDRP(ptr)); size_t remainder = ptr_size - size;//在ptr所指向的空闲块中插入size大小的块后剩余的空间大小 delete_node(ptr);//从空闲链表当中删除ptr if (remainder < DSIZE * 2)//如果剩余的大小小于最小块,只需要设置ptr指向block被分配即可 { PUT(HDRP(ptr), PACK(ptr_size, 1)); PUT(FTRP(ptr), PACK(ptr_size, 1)); } else if (size >= 96)//消除外部碎片的策略,如果插入的是大块,从该空闲块ptr的高地址方向放起 { PUT(HDRP(ptr), PACK(remainder, 0));//注意这一步已经修改了ptr所指向的未分配block的size PUT(FTRP(ptr), PACK(remainder, 0));//新的空闲块就生成了 PUT(HDRP(NEXT_BLKP(ptr)), PACK(size, 1));//由于ptr的size已经修改,下一个分配block就可以这样访问,修改分配block的属性 PUT(FTRP(NEXT_BLKP(ptr)), PACK(size, 1)); insert_node(ptr, remainder);//将空闲块插入空闲块链 return NEXT_BLKP(ptr); } else//消除外部碎片的策略,如果插入的是小块,从该空闲块ptr的低地址方向放起 { PUT(HDRP(ptr), PACK(size, 1));//ptr指向的位置放分配block PUT(FTRP(ptr), PACK(size, 1)); PUT(HDRP(NEXT_BLKP(ptr)), PACK(remainder, 0));//原理同上 PUT(FTRP(NEXT_BLKP(ptr)), PACK(remainder, 0)); insert_node(NEXT_BLKP(ptr), remainder); } return ptr; } int mm_init(void)//初始化堆 { int listnumber; char *heap; for (listnumber = 0; listnumber < LISTMAX; listnumber++)//初始化分离空闲链表 { segregated_free_lists[listnumber] = NULL; } if ((long)(heap = mem_sbrk(4 * WSIZE)) == -1)//首先开辟一个4*WSIZE大小的空间 return -1; PUT(heap, 0);//堆的头部 PUT(heap + (1 * WSIZE), PACK(DSIZE, 1));//2*WSIZE的空block PUT(heap + (2 * WSIZE), PACK(DSIZE, 1)); PUT(heap + (3 * WSIZE), PACK(0, 1));//堆的尾部块 if (extend_heap(INITCHUNKSIZE) == NULL)//扩展堆,得到初始大小的堆 return -1; return 0; } void *mm_malloc(size_t size)//自动在堆上分配大小为size的block,并返回分配的block的起始地址 { if (size == 0) return NULL; if (size <= DSIZE)//因为是按照双字对齐,如果大小小于DSiZE,那么分配DSIZE加上2*4B的头尾信息 { size = 2 * DSIZE; } else { size = ALIGN(size + DSIZE);//显然大小还要加上头尾信息 } int listnumber = 0; size_t searchsize = size; void *ptr = NULL; while (listnumber < LISTMAX)//首先找到合适的空闲块链表 { if (((searchsize <= 1) && (segregated_free_lists[listnumber] != NULL)))//找到合适的空闲块链了 { ptr = segregated_free_lists[listnumber]; while ((ptr != NULL) && ((size > GET_SIZE(HDRP(ptr)))))//然后在该空闲块链表上遍历 { ptr = PRED(ptr); } if (ptr != NULL)//找到了 break; } searchsize >>= 1; listnumber++; } if (ptr == NULL)//没有合适大小的block那么我们就需要扩展堆的大小 { if ((ptr = extend_heap(MAX(size, CHUNKSIZE))) == NULL) return NULL; } /* 在free块中allocate size大小的块 */ ptr = place(ptr, size); return ptr; } void mm_free(void *ptr)//释放ptr所指向的分配block { size_t size = GET_SIZE(HDRP(ptr)); PUT(HDRP(ptr), PACK(size, 0));//修改该block的分配属性 PUT(FTRP(ptr), PACK(size, 0)); insert_node(ptr, size); coalesce(ptr);//先插入,再合并 } void *mm_realloc(void *ptr, size_t size)//将之前malloc分配的空间修改分配大小,返回重新分配的block的地址 { void *new_block = ptr; int remainder; if (size == 0) return NULL; if (size <= DSIZE)//内存对齐 { size = 2 * DSIZE; } else { size = ALIGN(size + DSIZE); } if ((remainder = GET_SIZE(HDRP(ptr)) - size) >= 0)//如果size小于原来块的大小,直接返回原来的块 { return ptr; } //现在势必要借用虚拟内存了,size有点大 else if( (!GET_ALLOC(HDRP(NEXT_BLKP(ptr)))) && GET_SIZE(HDRP(NEXT_BLKP(ptr)))>0 )//如果后面的一个block是空闲块 { if((remainder = GET_SIZE(HDRP(ptr)) + GET_SIZE(HDRP(NEXT_BLKP(ptr))) - size)>=0)//如果加上后面的空闲块可以完成 { delete_node(NEXT_BLKP(ptr)); PUT(HDRP(ptr), PACK(size , 1)); PUT(FTRP(ptr), PACK(size , 1)); PUT(HDRP(NEXT_BLKP(ptr)), PACK(remainder, 0)); PUT(FTRP(NEXT_BLKP(ptr)), PACK(remainder, 0)); insert_node(NEXT_BLKP(ptr), remainder); } else//如果加上后面的空闲块不能完成,空闲块后面可能是利用块,也可能是结尾,是结尾的情况直接扩展堆会包含,因为扩展堆会合并空闲块 { if( !GET_SIZE(HDRP(NEXT_BLKP(NEXT_BLKP(ptr)))) )//如果后面一个空闲块的后面还是结尾 { remainder=size-GET_SIZE(HDRP(ptr))-GET_SIZE(HDRP(NEXT_BLKP(ptr)));//还差多少 if (extend_heap(MAX(remainder, CHUNKSIZE)) == NULL) return NULL; delete_node(NEXT_BLKP(ptr));//后面一个是彻底被吸收了 remainder=MAX(remainder, CHUNKSIZE); PUT(HDRP(ptr), PACK(GET_SIZE(HDRP(ptr)) + GET_SIZE(HDRP(NEXT_BLKP(ptr))) + remainder, 1)); PUT(FTRP(ptr), PACK(GET_SIZE(HDRP(ptr)) + GET_SIZE(HDRP(NEXT_BLKP(ptr))) + remainder, 1)); } else//那么就不能利用后面的空闲块了 { new_block = mm_malloc(size); memcpy(new_block, ptr, GET_SIZE(HDRP(ptr))); mm_free(ptr); } } } else if(!GET_SIZE(HDRP(NEXT_BLKP(ptr))) )//如果后一个block就是空,当前是结尾 { remainder=size-GET_SIZE(HDRP(ptr));//还差多少 if (extend_heap(MAX(remainder, CHUNKSIZE)) == NULL) return NULL; remainder=MAX(remainder, CHUNKSIZE); PUT(HDRP(ptr), PACK(GET_SIZE(HDRP(ptr)) + remainder, 1)); PUT(FTRP(ptr), PACK(GET_SIZE(HDRP(ptr))+ remainder, 1)); } /* else if (!GET_ALLOC(HDRP(NEXT_BLKP(ptr))) || !GET_SIZE(HDRP(NEXT_BLKP(ptr))))//如果高地址方向的下一块没有被分配,或者没有下一块了,这个块已经结束了 { if ((remainder = GET_SIZE(HDRP(ptr)) + GET_SIZE(HDRP(NEXT_BLKP(ptr))) - size) < 0) { if (extend_heap(MAX(-remainder, CHUNKSIZE)) == NULL) return NULL; remainder += MAX(-remainder, CHUNKSIZE); } delete_node(NEXT_BLKP(ptr)); PUT(HDRP(ptr), PACK(size + remainder, 1)); PUT(FTRP(ptr), PACK(size + remainder, 1)); } //没有可以利用的连续free块,而且size大于原来的块,这时只能申请新的不连续的free块、复制原块内容、释放原块 */ else//直接选择malloc一个新的出来 { new_block = mm_malloc(size); memcpy(new_block, ptr, GET_SIZE(HDRP(ptr))); mm_free(ptr); } return new_block; }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号