
3.Rem
Rem是一个相对单位,与em的差别在于,rem是相对于根节点html的font-size,而em是相对于父元素的font-size。使用rem实际是用媒体查询来修改根节点html的字体大小,那么使用rem的元素大小也会发生相应的改变,所以只要写一份css的媒体查询就可以适配所有屏幕了,但是在有一些浏览器下不够精准,可以通过JS根据屏幕宽度来动态计算根节点的font-size,一般此JS放在head部分。
媒体查询计算:
总结公式:设计稿任意尺寸PX*(设备屏幕宽度/设计稿尺寸的宽度)/ font-size。
使用JS计算:
获取当前窗口的宽度,大于750按750计算,
font-size=设备宽度/设计图宽度的百分之一 ,尽量控制1rem=100px,这样便于测量和计算
注意问题:
1.不是所有的浏览器默认字体大小都是16px,所以根元素的字体大小设置为62.5%不准确。
2.每个浏览器对最小font-size的支持,不尽相同。js动态计算的font-size值太小时,会导致超小屏上UI显示效果比预想中的偏大。
rem的优点:
1.实现强大的屏幕适配布局,
我们现在切页面布局的常用单位是px,这是一个绝对单位,但是不是所有的手机屏幕宽度都是设计图的大小,如果使用流式布局、限死宽度来做,都有一些弊端,比如说流式布局的宽度是采用百分比,但是高度不变,在大屏浏览器下显得极不协调。
2.没有屏幕字体缩放的问题,
如果说750px设计图的字体大小是36px,那么如果在375px的手机上就会显得非常突兀,而rem的就是通过不同的屏幕宽度改变根元素font-size的大小来实现的。
3.没有em多次使用计算麻烦的问题
Em是相对于父元素的大小,当层次较多时,容易遇到无法预知的风险,而且麻烦,而rem是统一相对元素,没有这种弊端。
4.Flex布局的理解
传统的布局方案是基于盒状模型的,依赖于display+ position+ float属性,但是这些属性有时候对于特殊布局,比如说垂直居中的实现不是很方便,而flex布局可以简便、完整、响应式的实现各种页面布局,比盒状模型提供更大的灵活性。
任何一个容器都可以使用flex布局,webkit内核的浏览器必须加上-webkit前缀,设置容器为flex布局以后,float、clear、vertical-align属性将失效。容器默认存在两根轴,水平的主轴和垂直的交叉轴,里面的每一个元素被称为项目。
容器的属性:
flex-direction:决定项目的排列方向(4)
flex-wrap:项目在一条轴线上排不下,如何换行(3)
flex-flow:是flex-direction和flew-wrap的简写形式,默认为row nowrap
justify-content:项目在水平主轴上的排列方式,左对齐,右对齐,居中,两端对齐,每个项目元素两侧的间隔相等
align-items:项目在交叉轴上如何对齐,项目第一行文字的基线对齐,stretch如果项目未设置高度或auto,则占满整个容器的高度
align-content:项目有多根轴线的对齐方式
项目的属性:
order:定义项目的排列顺序,数值越小,排列越靠前
flex-grow:放大比例,如果所有项目都为1,则等分,有一个项目为2,则占据的空间是其他项目的两倍。
flex-shrink:缩小比例,当空间不足时,所有项目等比例缩小,如果其他项目都为1,只有一个项目的属性值为0,则空间不足时,不缩小,负值无效。
flex-base:在分配多余空间之前,项目占据的主轴空间,
flex: flex-grow, flew-shrink, flex-basis的简写,默认值为0 1 auto。
align-self:允许单个项目与其他项目不一样的对齐方式
主要思想:给予容器控制内部元素高度和宽度的能力。
5.flex应用实例:
1.flex制作导航栏
传统的方式,用float或者display-inblock实现,但是这两种方法都会存在问题,浮动会影响父级元素都样式,需要清除浮动,盒状模型有时候会遇到间隙问题,需要把font-size的值设置为0,如果设置好了css属性之后增加多余的导航还需要修改css代码但是flex恨方便,并且是弹性布局,在外层容器上设置display=flex属性,在内置元素上设置flex=1;这样所有的单个导航都始终等分导航栏区域。
2.实现宽度固定高度不定的垂直居中对齐
三种方法,外层display=table,内层设置display=table-cell和vertical-align=middle
margin-top=50%和transform: translateY(-50%)实现
外层设置display=flex,align-items: center;
3.左右弹性布局,
左右沿主轴图文对齐外层:display: flex; justify-content: space-around; 内层左边width=100px;右边width=200px
固定百分比布局:外层:display:flex,内层:左边flex=1;右边flex=1;中间flex=2;输入框布局
左边定宽,右边为剩余全部宽度:外层:display:flex,内层左边flex=200px;右边flex:1
3.底部footer固定在底部,但是不是fixed定位
html和body的height高度为100%,body设置display=flex,flex-dircetion=column; main的flex=1;footer设置定高
4.实现流式布局
外层:display: flex;flex-wrap: wrap;align-content: flex-start;
内层:flex:0 0 33.33%;box-sizing:border-box
6.Ie8兼容问题
1.box-shadow,border-radius: 在属性前面加上-webkit前缀,设置behavior属性,并在项目中引入pie. htc文件。
2.不支持nth-child,但是支持first-child,
3.对background的各个属性兼容性不良好
使用ie独有的filter滤镜显示背景图片,
4.不支持header、nav标签
7.seo优化:(搜索引擎)
定义:SEO(Search Engine Optimization)搜索引擎优化,是为了增加页面在搜索引擎自然搜索结果中的收录数量以及提升排序位置而做的优化行为。
原理:在搜索引擎网站上,比如百度,在其后台有一个非常庞大的数据库,里面存储了海量的关键词,而每个关键词又对应着很多网址,这些网址是百度程序从互联网上一点一点下载收集而来的,这些程序称之为“搜索引擎蜘蛛”或“网络爬虫”。这些的“蜘蛛”每天在互联网上爬行,从一个链接到另一个链接,下载其中的内容,进行分析提炼,找到其中的关键词,如果“蜘蛛”认为关键词在数据库中没有而对用户是有用的便存入数据库。反之,如果“蜘蛛”认为是垃圾信息或重复信息,就舍弃不要,继续爬行,寻找最新的、有用的信息保存起来提供用户搜索。当用户搜索时,就能检索出与关键字相关的网址显示给访客。一个关键词对用多个网址,因此就出现了排序的问题,相应的当与关键词最吻合的网址就会排在前面了。在“蜘蛛”抓取网页内容,提炼关键词的这个过程中,就存在一个问题:“蜘蛛”能否看懂。如果网站内容是flash和js,那么它是看不懂的,会犯迷糊,即使关键字再贴切也没用。相应的,如果网站内容是它的语言,那么它便能看懂,它的语言即SEO。
方法:
1.重视网页三要素TDK的写作
title:网页标题直接影响关键字的排名情况,describe:网页描述,keywords网页关键字,
2.简化代码结构,有利于搜索引擎抓取有用的内容。
页面尽量采用DIV+CSS形式;所有js、css采用外联方式,css放在网页的上面,js最好放在页面下面,加快页面加载速度,图片采用css精灵拼成一张图进行定位只用,减少请求次数。
3、每个页面只能出现一次H1标签,H2标签可以多次
H1权重很高,普通认为仅次于title,一般资讯详情、商品详情页的标题,都放在H1里
4、图片一定要添加Alt属性,title属性可选
seo不认识图片上的内容,只能通过alt属性来判断
5、重要的内容优先加载
6、图片大小声明,图片一定要定义宽高大小,如果图片大小不做定义的话,页面需要重新渲染,就会影响到速度。
7、链接可根据实际需求添加title属性,不要在div标签上加href属性。
当链接文字过长被省略号截断的话,用title属性,用户可以在鼠标滑到链接上面的时候显示全链接文字。非特殊性链接,链接地址一定要写入href属性,不能为了省事,直接用div加个click事件当链接,在视觉上和使用上确实实现了链接效果,但是对于SEO优化非常不好,蜘蛛目前对于js支持很差,基本无法读取里面的链接地址。
8、 页面内容尽量不要做成flash、图片、视频
这些东西蜘蛛是抓不到的,就算是必须的,也要生成响应的静态页面。很多网站看着很炫,全站flash,看着是很爽,做SEO优化的就要抓狂了,全站没有一个连接。
9、 除首页外别的页面最好要加上面包屑导航,导航结构一定要清晰
每个面包屑导航要能一次链接返回上个导航,这样蜘蛛会把整个网站串起来。
10、做好404页面
一般会加首页链接及错误提示,并测试其返回状态码404:(1)、用户体验友好,可以留住用户,不至于直接关页面;(2)、蜘蛛友好,可以返回抓取其他页面。
11、网站结构呈扁平状树型,目录结构不宜过深
每个页面离首页最多点击不超过3次,过深不利于搜索引擎的抓取。
8.前端优化
定义:
从用户访问资源到资源完整的展现在用户面前的过程中,通过技术手段和优化策略,缩短每个步骤的处理时间从而提升整个资源的访问和呈现速度。
目的:
2. 从服务商角度而言,优化能够减少页面请求数、或者减小请求所占带宽,能够节省可观的资源。
总之,恰当的优化不仅能够改善站点的用户体验并且能够节省相当的资源利用。
8.jQuery
jQuery 是一个高效、精简并且功能丰富的 JavaScript 工具库,它提供的 API 易于使用且兼容众多浏览器,这让诸如 HTML 文档遍历和操作、事件处理、动画和 Ajax 操作更加简单。
1、你觉得 jquery 有哪些好处?
jQuery 是轻量级的 javascript 框架。
强大的选择器,$()
出色的 DOM 操作的封装,比如说:html()方法读取或者设置元素的innerHtml,attr()方法读取或者设置元素的属性
可靠的事件处理机制:比如说ready事件,jQuery中的ready事件,它的作用有些类似于window中的onload事件,只不过二者的区别在于,onload事件是要等到网页中的dom节点加载完成,并且css进行样式渲染后,JavaScript中进行了预加载后再执行,而ready事件呢,是在网页中的标签被解析为DOM节点是就执行其中的函数,直白点说,ready执行的比onload早。
完善的 ajax 封装:
load( url, [data], [callback] ) :载入远程 HTML 文件代码并插入至 DOM 中
jQuery.get( url, [data], [callback] ):使用GET方式来进行异步请求
jQuery.post( url, [data], [callback], [type] ) :使用POST方式来进行异步请求
jQuery.getScript( url, [callback] ) : 通过 GET 方式请求载入并执行一个 JavaScript 文件。
jQuery.ajax( options ) : 通过 HTTP 请求加载远程数据
出色的浏览器的兼容性
支持链式操作,隐式迭代,$(‘div.popup’).removeClass(‘hidden’).addClass(‘up’)
支持丰富的插件,时间插件、日期插件、表单验证插件、富文本编辑器和其他的自定义滚动插件等。
jquery 的文档也非常的丰富
2. jquery 对象和 dom 对象如何转换?
1. jquery 转 DOM 对象:
jQuery 对象是一个数组对象,可以通过[index]的丰富得到 DOM 对象还可以
通过 get[index]去得到相应的 DOM 对象。
2. DOM 对象转 jQuery 对象:
$(DOM 对象)
3 $(document).ready()方法和 window.onload 区别?
答: 两个方法有相似的功能,但是在实行时机方面是有区别的。
1 window.onload 方法是在网页中所有的元素(包括元素的所有关联文件)完全加载到浏览器后才执行的。
2 $(document).ready() 方法可以在 DOM 载入就绪时就对其进行操纵,并调用执行绑定的函数。
9.Bootstrap
Bootstrap 是一个基于 HTML、CSS、JAVASCRIPT的用于快速开发 Web 应用程序和网站的前端框架。
优点:
移动设备优先
浏览器兼容性较好
容易上手
响应式设计,能够自适应于台式机。平板电脑和手机。
为开发人员提供简介统一的方案
开源,
提高开发效率
缺点:css框架对于一个小项目来说有点臃肿,
如果有自己特殊的需求,就需要重新定制样式
会有兼容问题,虽然网上存在很多兼容IE的办法,但需要引入其他文件,有些还不小,势必导致加载速度变慢,影响用户体验。
10.跨域请求
跨域是指一个域下的文档或脚本试图去请求另一个域下的资源。
当协议、域名、端口号中任意一个不相同时,都算作不同域。不同域之间相互请求资源,就算作“跨域”。
解决方法:
1.代理:通过后台获取其他域名下的内容,然后再把获得的内容返回到前端,这样因为在同一个域名下,就不会出现跨域问题。
2.跨域资源共享(CORS)
普通跨域请求:只服务端设置Access-Control-Allow-Origin即可,前端无须设置。
3.用jsonp解决主流浏览器get请求的跨域数据访问的问题。
通常为了减轻web服务器的负载,我们把js、css,img等静态资源分离到另一台独立域名的服务器上,在html页面中再通过相应的标签从不同域名下加载静态资源,而被浏览器允许,基于此原理,我们可以通过动态创建script,再请求一个带参网址实现跨域通信,指定返回一个callback函数。
4.document.domain + iframe跨域
此方案仅限主域相同,子域不同的跨域应用场景。
实现原理:两个页面都通过js强制设置document.domain为基础主域,就实现了同域。
5、 location.hash + iframe跨域
实现原理: a欲与b跨域相互通信,通过中间页c来实现。 三个页面,不同域之间利用iframe的location.hash传值,相同域之间直接js访问来通信。
具体实现:A域:a.html -> B域:b.html -> A域:c.html,a与b不同域只能通过hash值单向通信,b与c也不同域也只能单向通信,但c与a同域,所以c可通过parent.parent访问a页面所有对象。
6.window.name + iframe跨域
window.name属性的独特之处:name值在不同的页面(甚至不同域名)加载后依旧存在,并且可以支持非常长的 name 值(2MB)。
https://segmentfault.com/a/1190000011145364
11.zepto
zepto是jQuery的轻量级替代品,因为它的API和jQuery相似,而文件更小。
zepto和jquery的区别:
1.jQuery 操作 ul 元素时,添加 id 不会生效。Zepto 操作 ul 元素时,添加 id 会生效。
2.事件触发的区别:使用 jQuery 时 load 事件的处理函数不会执行。使用 Zepto 时 load 事件的处理函数会执行。
3.事件委托的区别:点击class=a是弹出a事件,并将a事件的class改为b,点击b事件就是弹出b事件,
在 Zepto 中,当 a 被点击后,依次弹出了内容为”a事件“和”b事件“的弹出框。说明虽然事件委托在.a上可是却也触发了.b上的委托。但是在 jQuery 中只会触发 .a 上面的委托。
原因:在 Zepto 中代码解析的时候,document上所有的click委托事件都依次放入到一个队列中,点击的时候先看当前元素是不是.a,符合则执行,然后查看是不是.b,符合则执行。在 jQuery 中代码解析的时候,document上委托了2个click事件,点击后通过选择符进行匹配,执行相应元素的委托事件。
4.width() 和 height() 的区别 Zepto 由盒模型(box-sizing)决定; jQuery 会忽略盒模型,始终返回内容区域的宽/高(不包含padding、border)。Zepto 无法获取隐藏元素宽高,jQuery 可以。
12.VUE
Vue.js 是一个JavaScriptMVVM库,是一套构建用户界面的渐进式框架。它是以数据驱动和组件化的思想构建的,采用自底向上增量开发的设计。
特点:
1 轻量级框架,没有任何依赖。
2 API设计很清晰,简单易学。
3 Vue的两个核心点就是响应数据绑定和组合的视图组件。指令只封装 DOM 操作,而组件代表一个自给自足的独立单元 优雅的组件化设计,组件间沟通简单方便。
4 生命周期明确。
5 PC端和移动端均十分适用。
6 Vue社区也迅速壮大,太多的第三方组件,方便完善你的项目。
vue引入第三方插件的步骤:
1.安装插件依赖
2.修改webpack的配置文件 文件目录及名称:build/webpack.base.conf.js
3.在组件中import插件资源并使用
vue双向绑定数据的原理
首先要对数据进行劫持监听,所以我们需要设置一个监听器Observer,用来监听所有属性。如果属性发上变化了,就需要告诉订阅者Watcher看是否需要更新。因为订阅者是有很多个,所以我们需要有一个消息订阅器Dep来专门收集这些订阅者,然后在监听器Observer和订阅者Watcher之间进行统一管理的。接着,我们还需要有一个指令解析器Compile,对每个节点元素进行扫描和解析,将相关指令对应初始化成一个订阅者Watcher,并替换模板数据或者绑定相应的函数,此时当订阅者Watcher接收到相应属性的变化,就会执行对应的更新函数,从而更新视图。因此接下去我们执行以下3个步骤,实现数据的双向绑定:
1.实现一个监听器Observer,用来劫持并监听所有属性,如果有变动的,就通知订阅者。
2.实现一个订阅者Watcher,可以收到属性的变化通知并执行相应的函数,从而更新视图。
3.实现一个解析器Compile,可以扫描和解析每个节点的相关指令,并根据初始化模板数据以及初始化相应的订阅器
使用vue的过程
定义View
定义Model
创建一个Vue实例或"ViewModel",它用于连接View和Model
Vue.js的常用指令
-
v-if指令
-
v-show指令
-
v-else指令
-
v-for指令
-
v-bind指令
-
v-on指令
webpack+vue+vueRouter模块化构建完整项目实例超详细步骤
1. 确认已经安装node环境和npm包管理工具然后新建项目文件名为vuedemo
2.npm init -y 初始化项目
3.安装vue项目依赖,(*拓展:npm install 在安装 npm 包时,有两种命令参数可以把它们的信息写入 package.json 文件,一个是npm install --save另一个是 npm install --save-dev,他们表面上的区别是--save 会把依赖包名称添加到 package.json 文件 dependencies 键下,--save-dev 则添加到 package.json 文件 devDependencies 键下,
--save-dev 是你开发时候依赖的东西,--save 是你发布之后还依赖的东西。*)
4.安装webpack,webpack-dev-server
5.npm install --save-dev babel-core babel-loader babel-preset-es2015 安装babel,babel的作用是将es6的语法编译成浏览器认识的语法es5
6.npm install --save-dev vue-loader vue-template-compiler 安装vue-loader,用来解析vue的组件,.vue后缀的文件
7.npm install --save-dev css-loader style-loader 用来解析css
8.npm install --save-dev url-loader file-loader 用于打包文件和图片
9.npm install --save-dev sass-loader node-sass 用于编译sass
10.npm install --save-dev vue-router 安装路由
https://segmentfault.com/a/1190000008602934
13.Ajax
使用ajax的原因
1.传统的Web网站,提交表单,需要重新加载整个页面。
2.如果服务器长时间未能返回Response,则客户端将会无响应,用户体验很差。
3.服务端返回Response后,浏览器需要加载整个页面,对浏览器的负担也是很大的。
4.浏览器提交表单后,发送的数据量大,造成网络的性能问题。
ajax定义:
1.AJAX = 异步 JavaScript 和 XML。
2.AJAX 是一种用于创建快速动态网页的技术。
3.通过在后台与服务器进行少量数据交换,可以使网页实现异步更新。
4.可以在不重新加载整个网页的情况下,对网页的某部分进行更新。
原理:
Ajax的原理简单来说通过XmlHttpRequest对象来向服务器发异步请求,从服务器获得数据,然后用javascript来操作DOM而更新页面。这其中最关键的一步就是从服务器获得请求数据。
ajax技术的核心或者说负责ajax进行同步或者异步服务器请求是XMLHttpRequest对象。在用使用ajax技术时,其实就是操作XMLHttpRequest进行相应的业务。
方法:
1.创建XMLHttpRequest对象 xhr=new XMLHttpRequest(); //要是支持XMLHttpRequest的则采用XMLHttpRequest生成对象,要是支持win的ActiveXobiect则采用ActiveXobiect生成对象。
2. 使用open方法创建一个请求,设置请求方式如GET POST OPTION DELETE等,请求路径,同步请求或者是异步请求(true表示异步请求,false表示同步请求),xhr.open('请求方式','请求url',是异步|同步)
3.使用send发送一个请求 不传值时可以写null,get或者post请求传值时可以键值对写 username=zhangsan&pwd=12345
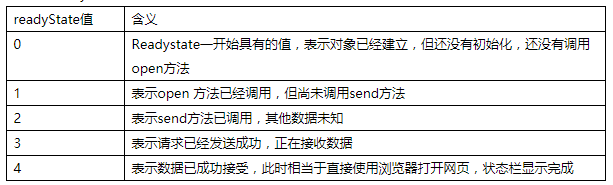
4.使用onreadystatechange事件捕获请求的状态变化
5.使用readyState属性判断请求状态

Git是目前世界上最先进的分布式版本控制系统。
SVN是集中式版本控制系统
git工作流程:
1. 克隆 Git 资源作为工作目录。
2. 在克隆的资源上添加或修改文件。
3. 如果其他人修改了,你可以更新资源。
4. 在提交前查看修改。
5. 提交修改。
6. 在修改完成后,如果发现错误,可以撤回提交并再次修改并提交。
基本概念:
工作区:就是你项目的目录(可见目录)。
缓存区:英文叫stage, 或index。一般存放在”git目录”下的index文件(.git/index)中,所以我们把暂存区有时也叫作索引(index)。
版本库:工作区有一个隐藏目录.git,这个不算工作区,而是Git的版本库。
常用命令:
1.配置个人的用户名称和电子邮件地址:
$ git config --global user.name "wyndam"
$ git config --global user.email "only.night@qq.com"
2.差异分析工具
$ git config --global merge.tool vimdiff ,习惯了用beyond compare工具
4.查看配置信息 git config –list
5.新建本地仓库 git init
6.复制远程仓库 git clone
7.git add 命令可将该文件添加到缓存
8.git status 命令用于查看项目的当前状态。
9.git diff 命令显示已写入缓存与已修改但尚未写入缓存的改动的区别
10.提交代码到本地仓库 git commit
11.git reset HEAD 命令用于取消已缓存的内容。
12.从缓存以及工作目录删除文件 git rm
13.git merge
14.Git 查看提交历史 git log
15.添加远程库 git remote add
16.查看当前的远程库 git remote
17.从远端仓库提取数据并尝试合并到当前分支: git pull
18.推送到远程仓库 git push
19.删除远程分支 git push
20.删除本地仓库的远程仓库链接 git remote rm
15.IIS
iis由微软公司提供的基于运行Microsoft Windows的互联网基本服务。
一般我们只能在本机上才可以开到我们的项目,这个是不需要连网的,如果想让我们的项目在网站中打开,别人也可以看到,就需要把我们的项目部署到服务器上了,输入IP就可以看到我们的项目
安装步骤:
1.开始 -> 控制面板 ->程序(或程序与功能)->打开或关闭windows功能 ,选中Internet 信息服务下面的所有选项
2.安装成功后打开Internet信息服务(IIS)管理器,填写添加网站的名称,选择网站的物理路径,绑定好网站的IP地址,并分配好端口号,点击确定。
3.添加默认文档:选中新建的网站,在右侧‘功能试图’中选择‘默认文档’,双击进入添加名称为login.aspx
4.编辑应用程序池,选择刚刚添加到项目,双击已建立的应用程序池。.NET Framework版本选择“.NET Framework v4.0.30319”,托管管道模式选择“集成”。
5.点击新建的网站 → 点击内容视图 → 选择起始页 → 右击浏览
遇到问题:
1.权限问题 报错500.19-Internal Server Error
选择——编辑权限——安全——编辑
2.可以运行出来 但是出现类似于FTP形式的列表样式
在默认文档中 添加 网站的起始页 后缀
16.HTTP协议:
定义:HTTP协议就是超文本传输协议,是用于从万维网(WWW:World Wide Web )服务器基于TCP/IP通信协议传输超文本(传递数据;HTML 文件, 图片文件, 查询结果等)到本地浏览器的传送协议。
浏览器作为HTTP客户端通过URL向HTTP服务端即WEB服务器发送所有请求。Web服务器根据接收到的请求后,向客户端发送响应信息。
工作流程:
一次HTTP操作称为一个事务,其工作过程可分为四步:
1)首先客户机与服务器需要建立连接。只要单击某个超级链接,HTTP的工作开始。
2)建立连接后,客户机发送一个请求给服务器,请求方式的格式为:统一资源标识符(URL)、协议版本号,后边是MIME信息包括请求修饰符、客户机信息和可能的内容。
3)服务器接到请求后,给予相应的响应信息,其格式为一个状态行,包括信息的协议版本号、一个成功或错误的代码,后边是MIME信息包括服务器信息、实体信息和可能的内容。
4)客户端接收服务器所返回的信息通过浏览器显示在用户的显示屏上,然后客户机与服务器断开连接。
17.当我们打开浏览器,在地址栏中输入URL,然后我们就看到了网页。 原理是怎样的呢?
1.域名的解析:如上图所示浏览器接收到你输入的域名之后会现在浏览器本地的缓存里面查询看是否有该域名,然后依次访问系统缓存,路由缓存,由这里便开始我们的递归搜索;向DNS服务器发起查询请求
2.和服务器建立好TCP连接
3.客户端向服务器发送响应的请求
4.服务器处理请求,并返回一个HTML页面
5.浏览器开始显示HTML页面
6.断开连接
18.GET和POST的区别
1. GET提交的数据会放在URL之后,以?分割URL和传输数据,参数之间以&相连,如EditPosts.aspx?name=test1&id=123456. POST方法是把提交的数据放在HTTP包体中.
2. GET提交的数据大小有限制(因为浏览器对URL的长度有限制),而POST方法提交的数据没有限制.
3. GET方式需要使用Request.QueryString来取得变量的值,而POST方式通过Request.Form来获取变量的值。
4. GET方式提交数据,会带来安全问题,比如一个登录页面,通过GET方式提交数据时,用户名和密码将出现在URL上,如果页面可以被缓存或者其他人可以访问这台机器,就可以从历史记录获得该用户的账号和密码.
19、http协议和https协议的区别
https协议是用SSL加密的进行信息交换,简而言之就是http协议的安全版
https协议需要到ca申请证书,一般免费证书很少,需要交费。
http是超文本传输协议,信息是明文传输,https 则是具有安全性的ssl加密传输协议。
http和https使用的是完全不同的连接方式用的端口也不一样,前者是80,后者是443。
http的连接很简单,是无状态的。
HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议 要比http协议安全。
20、会话跟踪方式
1.什么是会话
客户端打开与服务器的连接发出请求到服务器响应客户端请求的全过程称之为会话 。
2.什么是会话跟踪
对同一个用户对服务器的连续的请求和接受响应的监视 。
3.为什么要进行会话跟踪
浏览器与服务器之间的通信是通过HTTP协议进行通信的,而HTTP协议是”无状态”的协议,它不能保存客户的信息,即一次响应完成之后连接就断开了,下一次的请求需要重新连接,这样就需要判断是否是同一个用户,所以才应会话跟踪技术来实现这种要求。
4.会话跟踪常用的方法:
- URL重写:在URL结尾添加一个附加数据以标识该会话,把会话ID通过URL的信息传递过去,以便在服务器端进行识别不同的用户。
- 隐藏表单域:将会话ID添加到HTML表单元素中提交到服务器,此表单元素并不在客户端显示。
- Cookie: Cookie是Web服务器发送给客户端的一小段信息,客户端请求时可以读取该信息发送到服务器端,进而进行用户的识别。客户端可以采用两种方式来保存这个Cookie对象,一种方式是保存在客户端内存中,称为临时Cookie,浏览器关闭后 这个Cookie对象将消失。另外一种方式是保存在 客户机的磁盘上,称为永久Cookie。以后客户端只要访问该网站,就会将这个Cookie再次发送到服务器上,前提是 这个Cookie在有效期内。这样就实现了对客户的跟踪。
- Session :每一个用户都有一个不同的session,各个用户之间是不能共享的,是每个用户所独享的,在session中可以存放信息。在服务器端会创建一个session对象,产生一个sessionID来标识这个session对象,然后将这个sessionID放入到Cookie中发送到客户端,下一次访问时,sessionID会发送到服务器,在服务器端进行识别不同的用户。Session是依赖Cookie的,如果Cookie被禁用,那么session也将失效。因为Session是用Session ID来确定当前对话所对应的服务器Session,而Session ID是通过Cookie来传递的,禁用Cookie相当于失去了Session ID,也就得不到Session了。此时可以考虑URL重写和表单隐藏域。
21、同源
同源:两个文档同源需满足
- 协议相同
- 域名相同
- 端口相同
22、前端自动化构建工具——gulp
简介:gulp是基于Nodejs的前端自动任务运行器,它能自动化地完成javascript/sass/less/html/image/css 等文件的的测试、检查、合并、压缩、格式化、浏览器自动刷新、部署文件生成,并监听文件在改动后重复指定的这些步骤。
原理:Gulp 这类工具的原理很简单,主要是实现各种转换流来实现对文件的处理,然后再进行输出。

优点:Gulp 为你的工作流而服务,自动运行那些费事费力任务。
能够帮我合并压缩代码
为了避免浏览器缓存问题,对于新发布的代码,需要能加上md5值,并且能自动修改我的html中对js/css的引用
使用:1.先安装node.js,里面会带有npm工具。
2.再用npm来全局安装gulp npm install --global gulp。
3.进入项目目录,再安装一下项目的依赖npm install --save-dev gulp, --save-dev会自动加入到package.json中。
4.每一个项目都需要一个gulpfile.js文件,我们后续的代码和配置就都在这个文件里面了。
5.gulp实现文件的压缩
var gulp = require('gulp'),//导入工具包 require('node_modules里对应模块') var minifyHtml= require("gulp-minify-html"); gulp.task('minify-html',function() {//定义一个minify-html任务(自定义任务名称) gulp.src('src/**/*.html')//要压缩的html文件 .pipe(minifyHtml())//压缩 .pipe(gulp.dest('build')); }); gulp.task('default',['minify-html']);
6.gulp执行添加时间戳
主要插件:
var md5 = require("gulp-md5-plus"); gulp.src("./src/*.css") .pipe(md5(10,'./output/index.html')) .pipe(gulp.dest("./dist"));
将md5哈希值(长度:10)附加到静态/ js文件夹中的每个文件,然后使用md5ed文件名替换输出/ html /中的链接文件名; 最后将所有这些存储到输出文件夹中。
Gulp 核心 API:
gulp.src:获取文件
gulp.dest:写入文件
gulp.tasks:注册任务
gulp.watch:监控文件的改动
23、前端自动化构建工具——webpack
webpack 是一个打包工具
核心思想:把文件分成一个个的模,按需加载这些文件。
原理:将你的应用打包为多个文件. 如果你的单页面应用有多个页面, 那么用户只从下载对应页面的代码. 当他么访问到另一个页面, 他们不需要重新下载通用的代码。能够编译打包 CSS, 做 CSS 预处理, 编译 JS 方言, 打包图片等。
webpack是一个前端模块化方案,更侧重模块打包,我们可以把开发中的所有资源(图片、js文件、css文件等)都看成模块,通过loader(加载器)和plugins(插件)对资源进行处理,打包成符合生产环境部署的前端资源。
使用步骤:
1.在node环境下安装webpack以及下载一下所需要的模块。
2.搭建项目结构,src下面是代码开发目录,dist下面地编译打包输出目录,node_modules是所使用的nodejs模块。
3.webpack相关配置。
24、require.js
这段代码依次加载多个js文件。这样的写法有很大的缺点。首先,加载的时候,浏览器会停止网页渲染,加载文件越多,网页失去响应的时间就会越长;其次,由于js文件之间存在依赖关系,因此必须严格保证加载顺序(比如上例的1.js要在2.js的前面),依赖性最大的模块一定要放到最后加载,当依赖关系很复杂的时候,代码的编写和维护都会变得困难。
优点:
(1)实现js文件的异步加载,避免网页失去响应;
(2)管理模块之间的依赖性,便于代码的编写和维护。
使用require.js的步骤
1.是先去官方网站下载最新版本,下载后,假定把它放在js子目录下面,就可以加载了。
<script src="js/require.js"></script>
有人可能会想到,加载这个文件,也可能造成网页失去响应。解决办法有两个,一个是把它放在网页底部加载,另一个是写成下面这样:
<script src="js/require.js" defer async="true" ></script>
async属性表明这个文件需要异步加载,避免网页失去响应。IE不支持这个属性,只支持defer,所以把defer也写上。
2.加载require.js以后,下一步就要加载我们自己的代码了。假定我们自己的代码文件是main.js,也放在js目录下面。那么,只需要写成下面这样就行了:
<script src="js/require.js" data-main="js/main"></script>
data-main属性的作用是,指定网页程序的主模块。在上例中,就是js目录下面的main.js,这个文件会第一个被require.js加载。由于require.js默认的文件后缀名是js,所以可以把main.js简写成main。
25.less和sass的区别

 浙公网安备 33010602011771号
浙公网安备 33010602011771号