HDFS客户端读写流程图
一、HDFS客户端写流程

1.客户端请求上传数据到服务器
2.服务器接收到这个请求,然后到自己的元数据里面去查询,元数据中是否记录了该文件的存在
3.NN响应客户端是否可以上传
4.服务器会发送再次请求,需要上传多大的数据文件
5.服务器会根据上传文件大小进行调度,返回要上传的DataNode节点
6.客户端接收队列数据:
通过pop方法,取出第一个节点的地址,然后访问该节点,并吧剩下的其他节点的IP地址带过去;
第一个DN接收数据,再从队列中取出第一个,继续把剩下的IP带过去,直到最后一个节点结束;
最后一个节点收到信息之后,想源地址发送确认消息,确认到第一个DN的时候,DN会把确认消息返回给客户端;
7.datanode反顺序依次应答,直到应答给客户端
8.客户端向datanode上传文件块
9.上传文件块后,各datanode会通过心跳将位置信息汇报给namenode
注:如果上传文件块时,某个datanode节点挂掉了,该节点的上节点直接连接该节点的下游节点继续传输,最终在第7步汇报后,namenode会发现副本数不足,触发datanode复制更多副本
10.客户端重复上传操作,逐一将文件块上传,同时dataNode汇报块的位置信息,时间线重叠
11.所有块上传完毕后,namenode将所有信息存在元数据中,客户端关闭输出流
二、HDFS客户端读流程
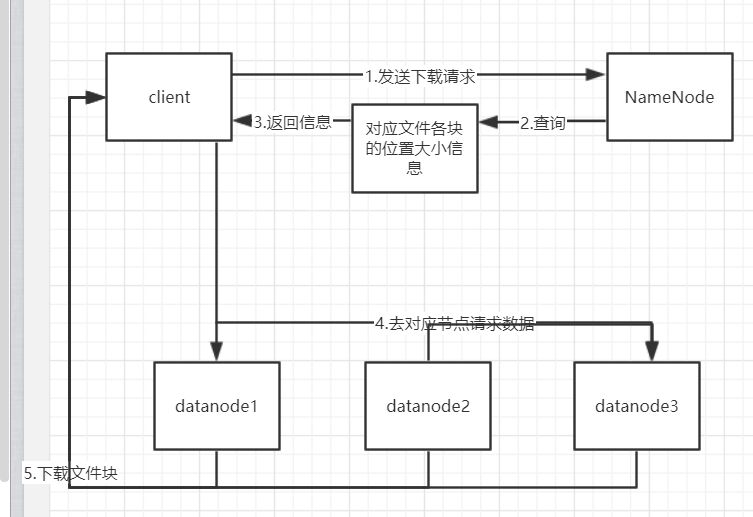
1.用户操作客户端查看文件,客户端带着文件名向namenode发起下载请求
2.namenode在元数据中查找该文件对应各个块的大小位置信息,返回给客户端
3.namenode向位置datanode节点发起下载请求
4.datanode向客户端传输块数据
5.客户端下载完成所有块后会验证datanode中的MD5,保证块数据的完整性,最后关闭输入流
三、元数据,Checkpoint
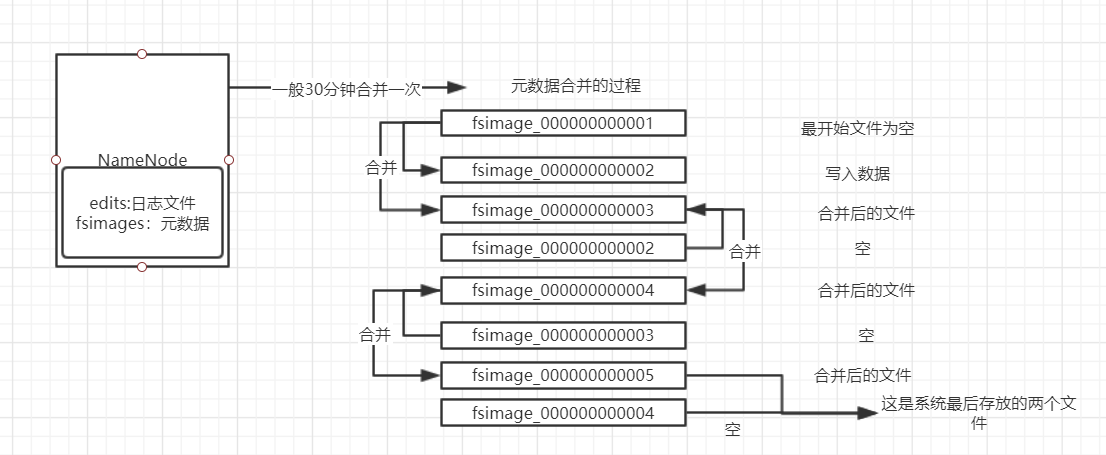
3.1 元数据
1.元数据:元数据是我们内存的一块空间
2.元数据:是一个文件,fsimage_0000000000XX文件就是元数据
3.元数据:就是一个小型的数据库,里面存放了所有文件的位置
3.2 Secondarynamenode
1.secondarynamenode实际上是对NameNode数据的一个备份
2.secondarynamenode是为了防止NameNode机器挂掉
3.secondarynamenode不能和NameNode放在一起
可以修改hdfs-site.xml配置文件来指定secondarynamenode的地址
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadp02:50090</value>
</property>
3.3 Checkpoint
1.辅助Namenode请求主Namenode停止使用edits文件,暂时将新的写操作记录到一个新文件中,如edits.new。
2.辅助Namenode节点从主Namenode节点获取fsimage和edits文件(采用HTTP GET)
3.辅助Namenode将fsimage文件载入到内存,逐一执行edits文件中的操作,创建新的fsimage文件
4.辅助Namenode将新的fsimage文件发送回主Namenode(使用HTTP POST)
5.主Namenode节点将从辅助Namenode节点接收的fsimage文件替换旧的fsimage文件,用步骤1产生的edits.new文件替换旧的edits文件(即改名)。同时更新fstime文件来记录检查点执行的时间

 浙公网安备 33010602011771号
浙公网安备 33010602011771号