谈到大数据,大家首先想到的肯定是Hadoop,近年来互联网技术的快速增长催生了各类大体量数据的爆发,Hadoop最大的贡献在于帮助企业将那些低价值的事件流数据转化为高价值的聚合数据,为企业的经营决策提供数据支撑。但Hadoop擅长的是存储和获取大规模数据,但是它并不提供任何性能上的保证。从这个角度来讲,我们可以把Hadoop看作是一个很好的后端、批量处理和数据仓库系统。在一个需要高并发并且保证查询性能和数据可用性的场景下,Hadoop并不能满足需求, 因此而引出了我们今天要介绍的主角: Druid集群。
Druid是一套基于大数据集之上做实时统计分析而设计的开源系统,主要特点包含分布式、列存储、内存数据库、实时分析。当前版本 0.10.0 (官网:http://druid.io), 主要作者:杨仿金同学已回到中国,另一老外成立自己的公司,在Druid集群之上提供商业化服务,包含PloySQL、Pivot等增值化组件。

在五横一竖常规的大数据架构中,从数据采集、数据处理、数据分析、数据访问、数据应用每一层均提供N多可供选择的组件包,可谓是“百花齐放”、能让您选花了眼。Druid 主要优势在于实时流式数据的处理与高效OLAP分析,与其它开源组件优劣对比见上图。

Druid集群主要包含了以下几类角色:
Ø RealNode:封装了导入和查询事件数据的功能,经由这些节点导入的事件数据可以立刻被查询
Ø HistoricalNode:封装了加载和处理由实时节点创建的不可变数据块(segment)的功能。在很多现实世界的工作流程中,大部分导入到Druid集群中的数据都是不可变的,因此,历史节点通常是Druid集群中的主要工作组件。
Ø BrokerNode:扮演着历史节点和实时节点的查询路由的角色。
Ø CoordinatorNode:主要负责数据的管理和在历史节点上的分布。协调节点告诉历史节点加载新数据、卸载过期数据、复制数据、和为了负载均衡移动数据。
Ø 除了上面介绍的节点角色外,Druid还依赖于外部的三个组件:ZooKeeper, Metadata Storage, Deep Storage,数据与查询流的交互如上图,简述如下:
ü ① 实时数据写入到实时节点,会创建索引结构的Segment
ü ② 实时节点的Segment经过一段时间会转存到DeepStorage
ü ③ 元数据写入MySQL; 实时节点转存的Segment会在ZooKeeper中新增一条记录
ü ④ 协调节点从MySQL获取元数据,比如schema信息(维度列和指标列)
ü ⑤ 协调节点监测ZK中有新分配/要删除的Segment,写入ZooKeeper信息:历史节点需要加载/删除Segment
ü ⑥ 历史节点监测ZK, 从ZooKeeper中得到要执行任务的Segment
ü ⑦ 历史节点从DeepStorage下载Segment并加载到内存/或者将已经保存的Segment删除掉
ü ⑧ 历史节点的Segment可以用于Broker的查询路由
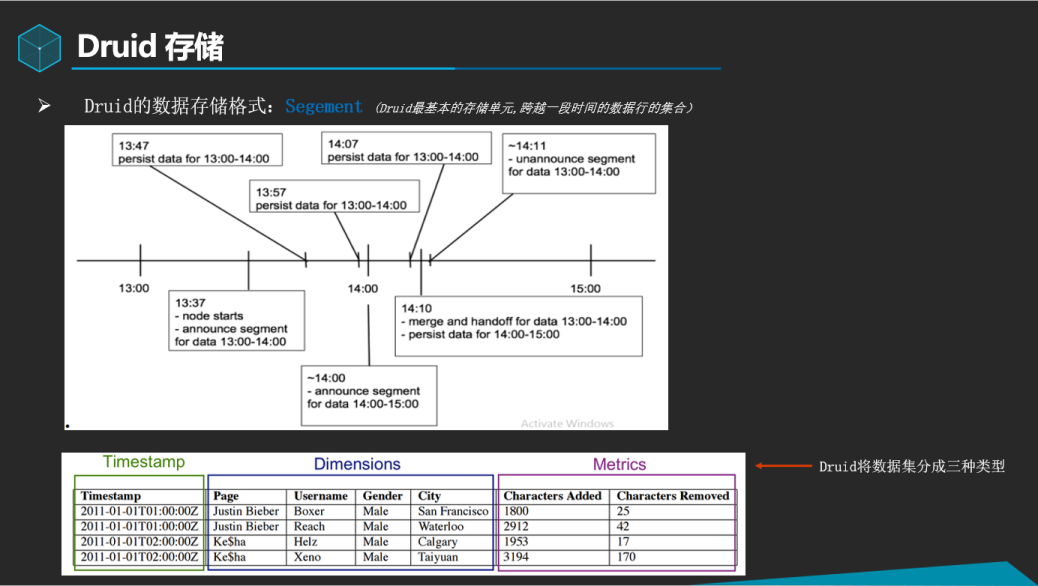
实时节点在处理数据导入、持久化、合并和传送这些阶段都是流动的,并且在这些处理阶段中不会有任何数据的丢失,数据流图如上:
Ø 节点启动于13:47,并且只会接受当前小时和下一小时的事件数据。当事件数据开始导入后,节点会宣布它为13:00到14:00这个时间段的Segment数据提供服务
Ø 每10分钟(这个时间间隔是可配置的),节点会将内存中的缓存数据刷到磁盘中进行持久化,在当前小时快结束的时候,节点会准备接收14:00到15:00的事件数据,一旦这个情况发生了,节点会准备好为下一个小时提供服务,并且会建立一个新的内存中的索引。
Ø 随后,节点宣布它也为14:00到15:00这个时段提供一个segment服务。节点并不是马上就合并13:00到14:00这个时段的持久化索引,而是会等待一个可配置的窗口时间,直到所有的13:00到14:00这个时间段的一些延迟数据的到来。这个窗口期的时间将事件数据因延迟而导致的数据丢失减低到最小。
Ø 在窗口期结束时,节点会合并13:00到14:00这个时段的所有持久化的索引合并到一个独立的不可变的segment中,并将这个segment传送走,一旦这个segment在Druid集群中的其他地方加载了并可以查询了,实时节点会刷新它收集的13:00到14:00这个时段的数据的信息,并且宣布取消为这些数据提供服务。

上图为我们正式集群DataSource 存储结构示意图,所有的NoSQL中都有数据分片的概念,比如ES的分片,HBase的Region,都表示的是数据的存储介质.为什么要进行分片,因为数据大了,不能都存成一个大文件吧?所以要拆分成小文件以便于快速查询. 伴随拆分通常都有合并小文件

通过实时采集充电日志,以按区域、场站等维度实时分析充电相关的指标分析为场景进行案例分享
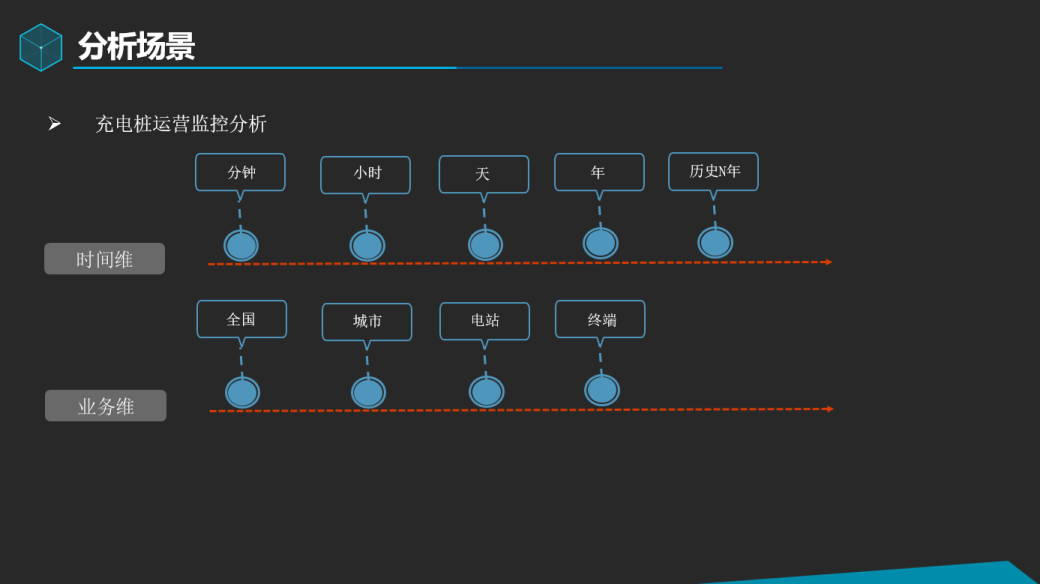
分享案例统计维度如上图

数据流处理示意图

扩展Grafana可视化组件的数据源插件、UI插件

按区域实时监控每分钟充电指标,通过选择左上角的导航面板中不同的区域,触发Dashboard内其它面板数据刷新

基于场站实时监控,支持全文检索或选择高级过滤的方式快速定位电站,选中第一列的小眼睛,行背景变绿,触发当前电站下面板内其它部件数据刷新。

同样原理,更细粒度下到终端的实时监控。
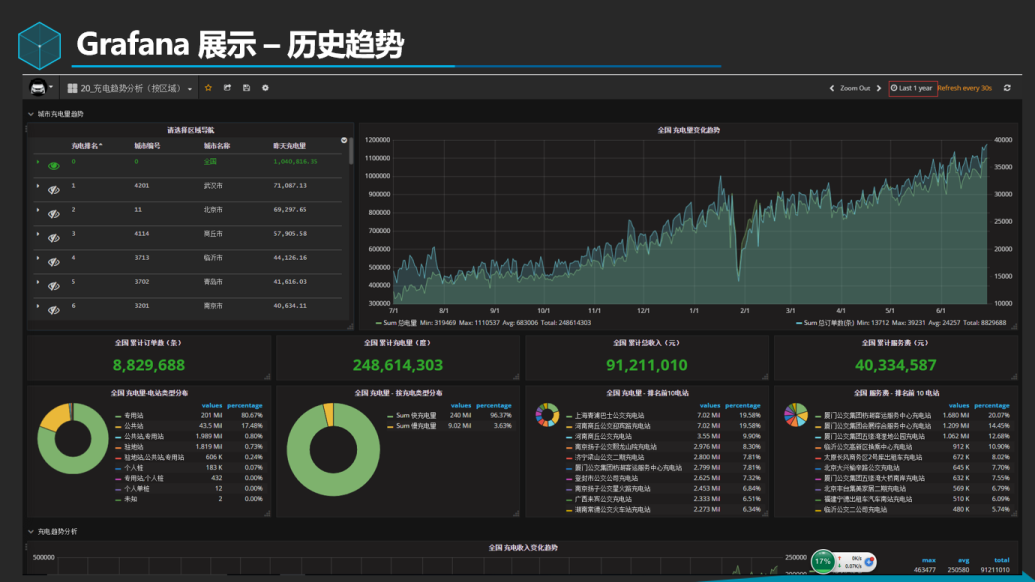
历史年度数据趋势分析
大数据需要伴随着业务的驱动来发挥其应有的价值,需要大家的共同参与来一步步夯实其底层的基础平台,期待着下一期更精彩的技术分享。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号