
DorisDB提供了多种导入方式,用户可以根据数据量大小、导入频率等要求选择最适合自己业务需求的导入方式。
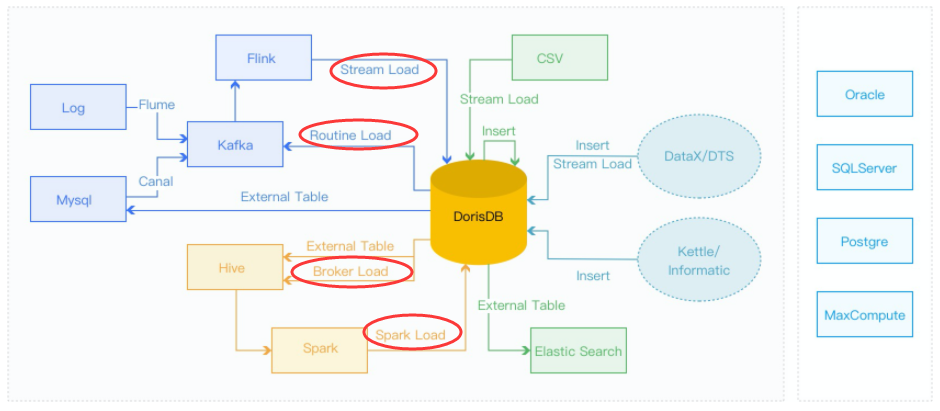
数据导入:
- 1、离线数据导入:如果数据源是Hive/HDFS,推荐采用 Broker Load 导入, 如果数据表很多导入比较麻烦可以考虑使用Hive外表直连查询,性能会比Broker load导入效果差,但是可以避免数据搬迁,如果单表的数据量特别大,或者需要做全局数据字典来精确去重可以考虑 Spark Load 导入。
- 2、实时数据导入:日志数据和业务数据库的binlog同步到Kafka以后,优先推荐通过 Routine load 导入DorisDB,如果导入过程中有复杂的多表关联和ETL预处理可以使用Flink处理以后用 stream load 写入DorisDB
- 3、程序写入DorisDB:推荐使用Stream Load
- 4、Mysql数据导入:推荐使用Mysql外表,insert into new_table select * from external_table 的方式导入
- 5、DorisDB内部导入:可以在DorisDB内部使用 insert into tablename select 的方式导入,可以跟外部调度器配合实现简单的ETL处理
- 6、其他数据源导入:推荐使用 DataX 导入
外部表:
- DorisDB支持以外部表的形式,接入其他数据源。
- 外部表指的是保存在其他数据源中的数据表。
- 目前DorisDB已支持的第三方数据源包括 MySQL、HDFS、ElasticSearch,Hive。
重点目录:
- 1.1 Broker Load
- 1.2 Spark Load
- 1.3 Stream Load
- 1.4 Routine Load
- 2.1 MySQL外部表
- 2.2 ElasticSearch外部表
1.1 Broker Load
在Broker Load模式下,通过部署的 Broker 程序,DorisDB可读取对应数据源(如HDFS, S3、阿里云 OSS、腾讯 COS)上的数据,利用自身的计算资源对数据进行预处理和导入。这是一种异步的导入方式,用户需要通过MySQL协议创建导入,并通过查看导入命令检查导入结果。
1、名词解释
- Broker:Broker 为一个独立的无状态进程,封装了文件系统接口,为 DorisDB 提供读取远端存储系统中文件的能力。
- Plan:导入执行计划,BE会执行导入执行计划将数据导入到DorisDB系统中。
2、语法:
-
LOAD LABEL db_name.label_name (data_desc, ...) WITH BROKER broker_name broker_properties [PROPERTIES (key1=value1, ... )] data_desc: DATA INFILE ('file_path', ...) [NEGATIVE] INTO TABLE tbl_name [PARTITION (p1, p2)] [COLUMNS TERMINATED BY column_separator ] [FORMAT AS file_type] [(col1, ...)] [SET (k1=f1(xx), k2=f2(xx))] [WHERE predicate] broker_properties: (key2=value2, ...)
说明:
1)、Label:导入任务的标识。每个导入任务,都有一个数据库内部唯一的Label。Label是用户在导入命令中自定义的名称。
- 通过这个Label,用户可以查看对应导入任务的执行情况,并且Label可以用来防止用户导入相同的数据。
- 当导入任务状态为FINISHED时,对应的Label就不能再次使用了。
- 当 Label 对应的导入任务状态为CANCELLED时,可以再次使用该Label提交导入作业。
2)、data_desc:每组 data_desc表述了本次导入涉及到的数据源地址,ETL 函数,目标表及分区等信息。
示例 :参见:https://www.kancloud.cn/dorisdb/dorisdb/2146000
1.2 Spark Load
Spark Load 通过外部的 Spark 资源实现对导入数据的预处理,提高 DorisDB 大数据量的导入性能并且节省 Doris 集群的计算资源。主要用于初次迁移、大数据量导入 DorisDB 的场景(数据量可到TB级别)
1、基本原理

Spark Load 任务的执行主要分为以下几个阶段:
- 1、用户向 FE 提交 Spark Load 任务;
- 2、FE 调度提交 ETL 任务到 Spark 集群执行。
- 3、Spark 集群执行 ETL 完成对导入数据的预处理。包括全局字典构建(BITMAP类型)、分区、排序、聚合等。
- 4、ETL 任务完成后,FE 获取预处理过的每个分片的数据路径,并调度相关的 BE 执行 Push 任务。
- 5、BE 通过 Broker 读取数据,转化为 DorisDB 存储格式。
- 6、FE 调度生效版本,完成导入任务。
2、预处理流程:
- 1、从数据源读取数据,上游数据源可以是HDFS文件,也可以是Hive表。
- 2、对读取到的数据完成字段映射、表达式计算,并根据分区信息生成分桶字段bucket_id。
- 3、根据DorisDB表的Rollup元数据生成RollupTree。
- 4、遍历RollupTree,进行分层的聚合操作,下一个层级的Rollup可以由上一个层的Rollup计算得来。
- 5、每次完成聚合计算后,会对数据根据bucket_id进行分桶然后写入HDFS中。
- 6、后续Broker会拉取HDFS中的文件然后导入DorisDB BE节点中。
3、基本操作参见:https://www.kancloud.cn/dorisdb/dorisdb/2146001
1.3 Stream Load
Stream Load 是一种同步的导入方式,用户通过发送 HTTP 请求将本地文件或数据流导入到 DorisDB 中。Stream Load 同步执行导入并返回导入结果。用户可直接通过请求的返回值判断导入是否成功。
1、主要流程:
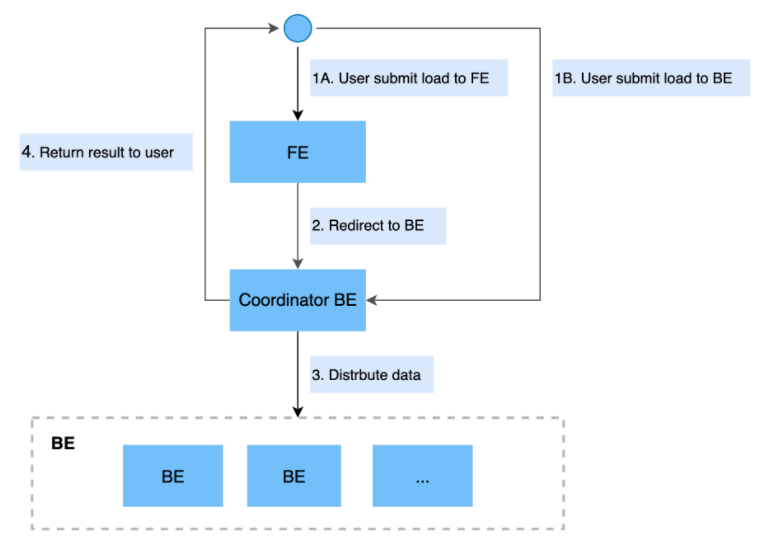
说明:
- Stream Load 中,用户通过HTTP协议提交导入命令。
- 如果提交到FE节点,则FE节点会通过HTTP redirect指令将请求转发给某一个BE节点,用户也可以直接提交导入命令给某一指定BE节点。
- 该BE节点作为Coordinator节点,将数据按表schema划分并分发数据到相关的BE节点。
- 导入的最终结果由 Coordinator节点返回给用户。
2、基本操作参见:https://www.kancloud.cn/dorisdb/dorisdb/2146002
1.4 Routine Load
Routine Load 是一种例行导入方式,DorisDB通过这种方式支持从Kafka持续不断的导入数据,并且支持通过SQL控制导入任务的暂停、重启、停止
1、基本原理
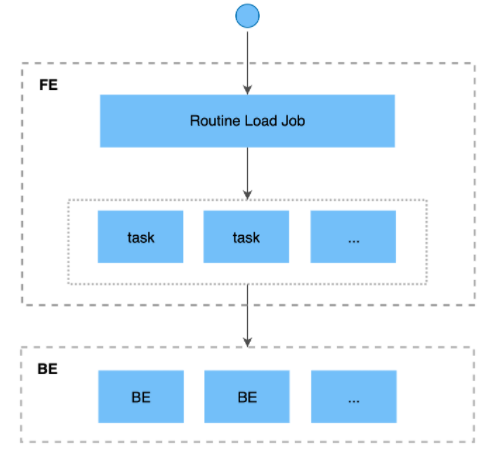
导入流程说明:
- 1、用户通过支持MySQL协议的客户端向 FE 提交一个Kafka导入任务。
- 2、FE将一个导入任务拆分成若干个Task,每个Task负责导入指定的一部分数据。
- 3、每个Task被分配到指定的 BE 上执行。在 BE 上,一个 Task 被视为一个普通的导入任务,通过 Stream Load 的导入机制进行导入。
- 4、BE导入完成后,向 FE 汇报。
- 5、FE 根据汇报结果,继续生成后续新的 Task,或者对失败的 Task 进行重试。
- 6、FE 会不断的产生新的 Task,来完成数据不间断的导入。
2、基本操作参见:https://www.kancloud.cn/dorisdb/dorisdb/2146003
2.1 MySQL外部表
星型模型中,数据一般划分为维度表和事实表。维度表数据量少,但会涉及UPDATE操作。目前DorisDB中还不直接支持UPDATE操作(可以通过Unique数据模型实现),在一些场景下,可以把维度表存储在MySQL中,查询时直接读取维度表。
在使用MySQL的数据之前,需在DorisDB创建外部表,与之相映射。DorisDB中创建MySQL外部表时需要指定MySQL的相关连接信息,如下图。
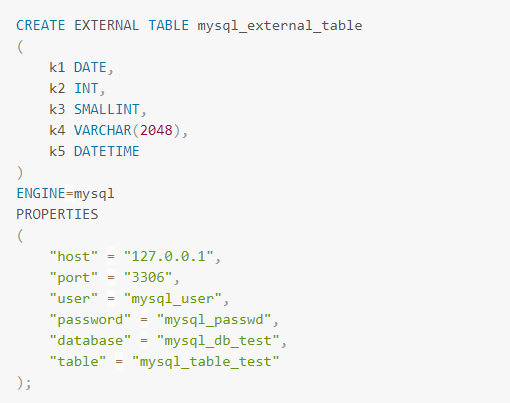
2.2 ElasticSearch外部表
DorisDB与ElasticSearch都是目前流行的分析系统,DorisDB强于大规模分布式计算,ElasticSearch擅长全文检索。DorisDB支持ElasticSearch访问的目的,就在于将这两种能力结合,提供更完善的一个OLAP解决方案。
1、建表示例
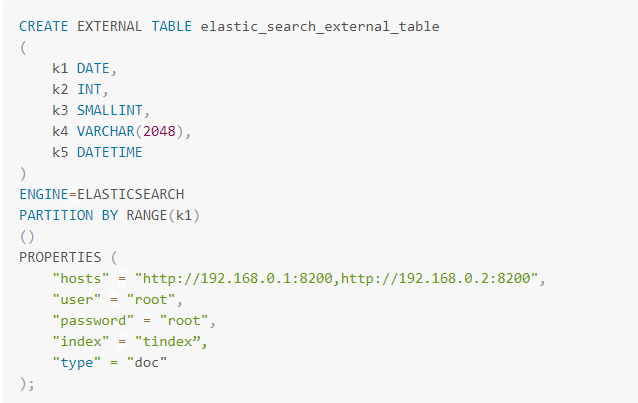
2、谓词下推
DorisDB支持对ElasticSearch表进行谓词下推,把过滤条件推给ElasticSearch进行执行,让执行尽量靠近存储,提高查询性能。目前支持哪个下推的算子如下表。
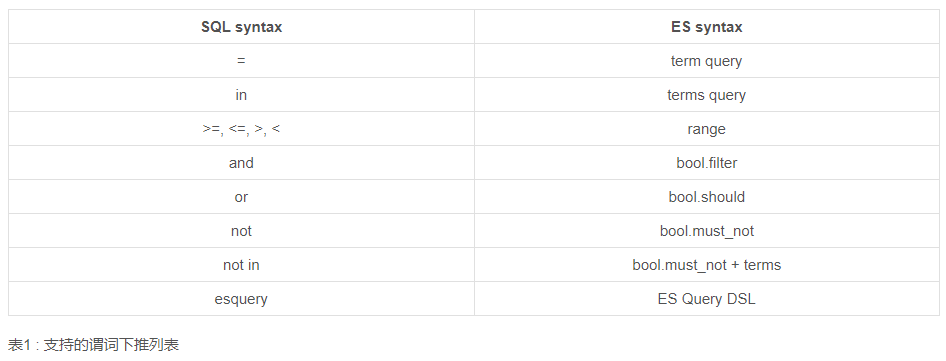
3、详细说明参见:https://www.kancloud.cn/dorisdb/dorisdb/2146013
参考资料:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号