
Colocation Join 是在 Doris 0.9 版本中引入的新功能。旨在为某些 Join 查询提供本地性优化,来减少数据在节点间的传输耗时,加速查询。
1、基本理论
Join 的常见连接类型分为以下几种:
- INNER JOIN
- OUTER JOIN
- CROSS JOIN
- SEMI JOIN
- ANTI JOIN
Join 的常见算法实现包含以下几种:
- Nested Loop Join
- Sort Merge Join
- Hash Join
分布式系统实现 Join 数据分布的常见策略有:
- Shuffle Join
- Broadcast Join
- Colocate/Local Join
Colocate/Local Join 就是指多个节点 Join 时没有数据移动和网络传输,每个节点只在本地进行 Join,能够本地进行 Join 的前提是相同 Join Key 的数据分布在相同的节点。
shuffle join 和 broadcast join 中, 参与join的两张表的数据行, 若满足join条件, 则需要将它们汇合在一台节点上, 完成join; 这两种join方式, 都无法避免节点间数据网络传输带来额外的延迟和其他开销。
2、名词解释
- Colocation Group(CG):一个 CG 中会包含一张及以上的 Table。一个CG内的Table 按相同的分桶方式和副本放置方式, 使用Colocation Group Schema描述. -- (组合分组)
- Colocation Group Schema(CGS): 包含CG的分桶键,分桶数以及副本数等信息。
- Colocate Parent Table:将决定一个 Group 数据分布的 Table 称为 Parent Table。(当创建表时, 通过表的 PROPERTIES 的属性 "colocate_with" = "group_name" 指定表归属的CG; 如果CG不存在, 说明该表为CG的第一张表, 称之为Parent Table, Parent Table的数据分布(分桶键的类型,数量和顺序, 副本数和分桶数)决定了CGS; 如果CG存在, 则检查表的数据分布是否和CGS一致.)
- Colocate Child Table:将一个 Group 中除 Parent Table 之外的 Table 称为 Child Table。
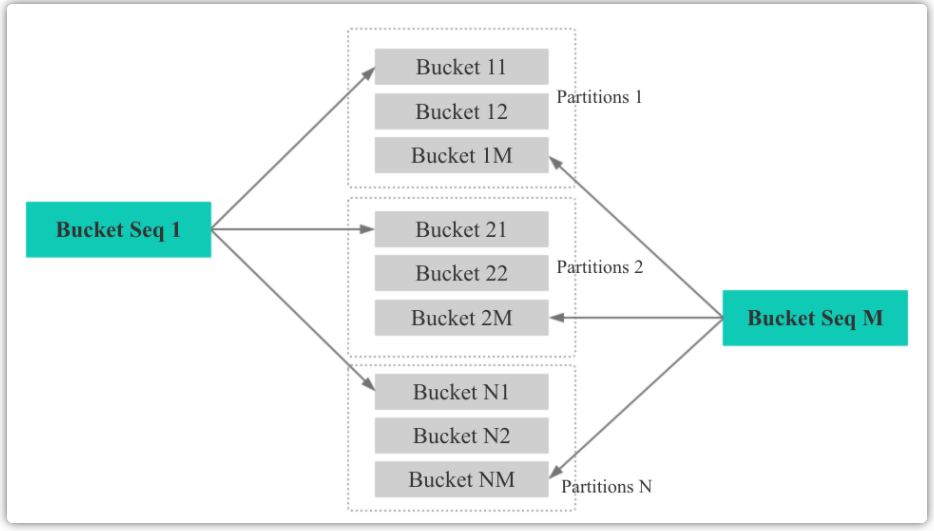
- Bucket Seq:如下图,如果一个表有 N 个 Partition, 则每个 Partition 的第 M 个 bucket 的 Bucket Seq 是 M。
![]()
3、基本原理
Colocation Join 功能,是将一组拥有相同 CGS 的 Table 组成一个 CG。并保证这些 Table 对应的分桶副本会落在相同一组BE 节点上。使得当 CG 内的表进行分桶列上的 Join 操作时,可以直接进行本地数据 Join,减少数据在节点间的传输耗时。
为了使得 Table 能够有相同的数据分布,同一 CG 内的 Table 必须保证下列约束:
- 1、同一CG 内的 Table 的分桶键的类型, 数量和顺序完全一致,并且桶数一致; 这样才能保证多张表的数据分片能够一一对应的进行分布控制。
- 2、同一个 CG 内所有表的所有分区(Partition)的副本数必须一致。如果不一致,可能出现某一个 Tablet 的某一个副本,在同一个 BE 上没有其他的表分片的副本对应。
- 分桶键:即在建表语句中 DISTRIBUTED BY HASH(col1, col2, ...) 中指定一组列。分桶键决定了一张表的数据通过哪些列的值进行 Hash 划分到不同的 Bucket Seq中。
- 同CG的table的分桶键的名字可以不相同, 分桶列的定义在建表语句中的出现次序可以不一致, 但是在 DISTRIBUTED BY HASH(col1, col2, ...) 的对应数据类型的顺序要完全一致.
- 3、同一个 CG 内所有表的分区键, 分区数量可以不同.
所以我们在数据导入时保证本地性的核心思想就是两次映射,对于 colocate tables,我们保证相同 Distributed Key 的数据映射到相同的 Bucket Seq,再保证相同 Bucket Seq 的 buckets 映射到相同的 BE

具体实现:
第一步:我们计算 Distributed Key 的 hash 值,并对 bucket num 取模,保证相同 Distributed Key 的数据映射到相同的 Bucket Seq。

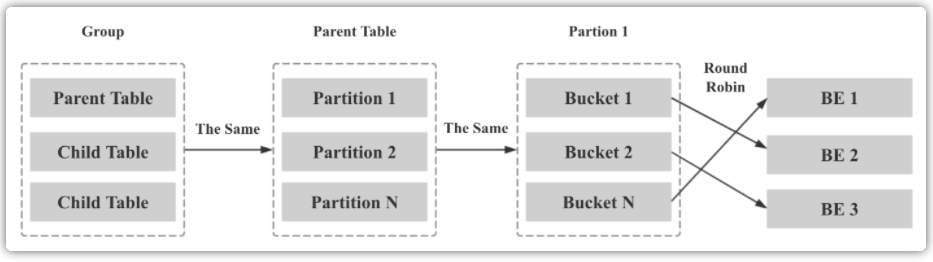
第二步:将同一个 Colocate Group 下所有相同 Bucket Seq 的 Bucket 映射到相同的 BE,方法如下:
- 1、Group 中所有 Table 的 Bucket Seq 和 BE 节点的映射关系和 Parent Table 一致
- 2、Parent Table 中所有 Partition 的 Bucket Seq 和 BE 节点的映射关系和第一个 Partition 一致
- 3、Parent Table 第一个 Partition 的 Bucket Seq 和 BE 节点的映射关系利用原生的 Round Robin 算法决定
![]()
4、使用方式
1、建表
建表时,可以在 PROPERTIES 中指定属性 "colocate_with" = "group_name",表示这个表是一个 Colocation Join 表,并且归属于一个指定的 Colocation Group。如下图:

说明:
- 如果指定的 Group 不存在,则 DorisDB 会自动创建一个只包含当前这张表的 Group。
- 如果 Group 已存在,则 DorisDB 会检查当前表是否满足 Colocation Group Schema。如果满足,则会创建该表,并将该表加入 Group。同时,表会根据已存在的 Group 中的数据分布规则创建分片和副本。
- Group 归属于一个 Database,Group 的名字在一个 Database 内唯一。在内部存储是 Group 的全名为 dbId_groupName,但用户只感知 groupName。
2、删除
当 Group 中最后一张表彻底删除后(彻底删除是指从回收站中删除。通常,一张表通过 DROP TABLE 命令删除后,会在回收站默认停留一天的时间后,再删除),该 Group 也会被自动删除。
3、查看 Group 信息
以下命令可以查看集群内已存在的 Group 信息
- SHOW PROC '/colocation_group';
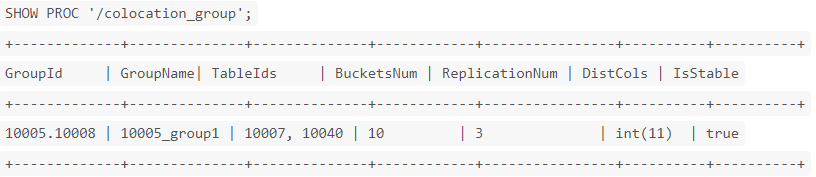
结果示例:
其中:
- GroupId:一个 Group 的全集群唯一标识,前半部分为 db id,后半部分为 group id。
- GroupName:Group 的全名。
- TabletIds:该 Group 包含的 Table 的 id 列表。
- BucketsNum:分桶数。
- ReplicationNum:副本数。
- DistCols:Distribution columns,即分桶列类型。
- IsStable:该 Group 是否稳定(稳定的定义,见 下面 Colocation 副本均衡和修复)。
通过以下命令可以进一步查看一个 Group 的数据分布情况:
- SHOW PROC '/colocation_group/10005.10008';
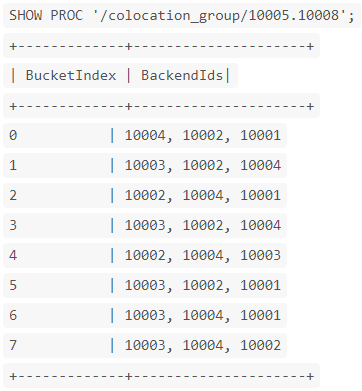
结果示例:
其中:
- BucketIndex: 分桶序列的下标。
- BackendIds: 分桶中数据分片所在的 BE 节点 id 列表。
注意:以上命令需要 AMDIN 权限。暂不支持普通用户查看。
4、修改表 Group 属性
可以对一个已经创建的表,修改其 Colocation Group 属性。示例:
- ALTER TABLE tbl SET ("colocate_with" = "group2");
如果该表之前没有指定过 Group,则该命令检查 Schema,并将该表加入到该 Group(Group 不存在则会创建)。如果该表之前有指定其他 Group,则该命令会先将该表从原有 Group 中移除,并加入新 Group(Group 不存在则会创建)。
也可以通过以下命令,删除一个表的 Colocation 属性:
- ALTER TABLE tbl SET ("colocate_with" = "");
5、其他相关操作
当对一个具有 Colocation 属性的表进行增加分区(ADD PARTITION)、修改副本数时,DorisDB 会检查修改是否会违反 Colocation Group Schema,如果违反则会拒绝。
5、Colocation 副本均衡和修复
Colocation 表的副本分布需要遵循 Group 中指定的分布,所以在副本修复和均衡方面和普通分片有所区别。
Group 自身有一个 Stable 属性:
- 当 Stable 为 true 时,表示当前 Group 内的表的所有分片没有正在进行变动,Colocation 特性可以正常使用。
- 当 Stable 为 false 时(Unstable),表示当前 Group 内有部分表的分片正在做修复或迁移,此时,相关表的 Colocation Join 将退化为普通 Join。
1、副本修复
- 副本只能存储在指定的 BE 节点上。所以当某个 BE 不可用时(宕机、Decommission 等),需要寻找一个新的 BE 进行替换。
- DorisDB 会优先寻找负载最低的 BE 进行替换。替换后,该 Bucket 内的所有在旧 BE 上的数据分片都要做修复。迁移过程中,Group 被标记为 Unstable。
2、副本均衡
DorisDB 会尽力将 Colocation 表的分片均匀分布在所有 BE 节点上。
对于普通表的副本均衡,是以单副本为粒度的,即单独为每一个副本寻找负载较低的 BE 节点即可。
而 Colocation 表的均衡必须保证同一个 colocate group 下所有 bucket 的数据本地性,所以我们 balance 的单位是 colocate group。
- 注1:当前的 Colocation 副本均衡和修复算法,对于异构部署的 DorisDB 集群效果可能不佳。所谓异构部署,即 BE 节点的磁盘容量、数量、磁盘类型(SSD 和 HDD)不一致。在异构部署情况下,可能出现小容量的 BE 节点和大容量的 BE 节点存储了相同的副本数量。
- 注2:当一个 Group 处于 Unstable 状态时,其中的表的 Join 将退化为普通 Join。此时可能会极大降低集群的查询性能。如果不希望系统自动均衡,可以设置 FE 的配置项 disable_colocate_balance 来禁止自动均衡。然后在合适的时间打开即可。
3、核心思路:
- 新增一个 daemon 线程专门处理 colocate table 的 balance,并让正常的 balance 线程不处理 colocate table 的 balance。
4、何时 balance
- 有 BE 节点新增,删除,down 掉时。
5、balance 的粒度:
- 正常 balance 的粒度是 bucket,但是对于 colocate table,我们必须保证同一个 colocate group 下所有 bucket 的数据本地性,所以我们 balance 的单位是 colocate group。
6、balance 对查询的影响:
- 当一个 colocate group 正在 balance 时,colocate join 会退化为原始的 shuffle join 或 broadcast join。
7、balance 流程:
- 1、为需要复制或迁移的 Bucket 选择目标 BE
- 2、标记 colocate group 的转态为 balancing
- 3、对于需要复制或迁移的 Bucket,发起 Clone Job,Clone Job 会从 Bucket 的现有副本复制一个新副本目标 BE
- 4、更新 backendsPerBucketSeq(维护 Bucket Seq 到 BE 映射关系的元数据)
- 5、当一个 colocate group 下的所有 Clone Job 都完成时,标记 colocate group 的转态为 stable
- 6、删除冗余的副本
6、FE 配置项
1、disable_colocate_relocate: 是否关闭 DorisDB 的自动 Colocation 副本修复。默认为 false,即不关闭。该参数只影响 Colocation 表的副本修复,不影响普通表。
2、disable_colocate_balance: 是否关闭 DorisDB 的自动 Colocation 副本均衡。默认为 false,即不关闭。该参数只影响 Colocation 表的副本均衡,不影响普通表。
3、disable_colocate_join:可以通过改该变量在 session 粒度关闭 colocate join功能
7、FAQ
一句话总结,凡是不能进行 Colocate Join 的场景都会自动退化为原始的 Shuffle Join 或者 Broadcast Join。
1、支持多张表进行 Colocate Join 吗?
- 支持
2、支持 Colocate 表和正常表 Join 吗?
- 支持
3、Colocate 表支持用非分桶的 Key 进行 Join 吗?
- 支持:不符合 Colocate Join 条件的 Join 会使用 Shuffle Join 或 Broadcast Join
4、如何确定 Join 是按照 Colocate Join 执行的?
- explain 的结果中 Hash Join 的孩子节点如果直接是 OlapScanNode, 没有 Exchange Node,就说明是 Colocate Join
5、如何修改 colocate_with 属性?
- ALTER TABLE example_db.my_table set ("colocate_with"="target_table");
6、如何禁用 colocate join?
- set disable_colocate_join = true; 就可以禁用 Colocate Join,查询时就会使用 Shuffle Join 或 Broadcast Join
参考资料

 浙公网安备 33010602011771号
浙公网安备 33010602011771号