第四课 KNN最近邻算法
中国有句俗语“近朱者赤,近墨者黑”,这句话非常精准地点出了KNN最近邻算法的精髓。
1、算法思想
KNN算法在分类任务和回归任务上有稍许不同,但主流程是相同的,下面分别阐述。
1)分类任务
对于某个待分类点P,先找出距离P点最近的N个邻居,然后使用投票的方式统计出P点对应的分类,即统计这N个邻居分属哪些类别,然后将出现次数最多的类别作为某个点的分类。
图1是借用网上的图片来描述KNN原理,图1中绿色的圆点是待分类点,而实线圆和虚线圆代表算法选取的N值不同,实线圆代表N=3个邻居,虚线圆代表N=5个邻居,对于实线圆的情形,3个邻居中有2个邻居是三角形,1个邻居是正方形,所以圆中心的银色待分类点的类别是三角形。对于虚线圆的分析类同实线圆,区别只在于N=5。
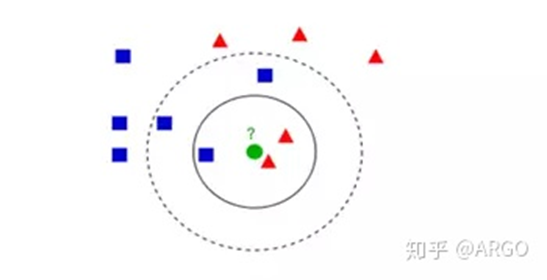
图1 KNN分类任务原理图
2)回归任务
对于某个待求数值点P,先找出距离P点最近的N个邻居,然后计算这N个邻居的平均值,该平均值即P点的取值。
仍以图1中的例子,分析思路同理分类任务,区别在于最后求取圆中心绿点的值时,对实线圆的情形,其取值是2个三角形和1个正方形的平均值,虚线圆的求取类同。
2、SkLearn中的KNN算法的使用
SkLearn中封装有KNN算法的实现,实现类为KNeighborsClassifier和KNeighborsRegressor,其中KNeighborsClassifier是分类器,用于分类任务,而KNeighborsRegressor是回归器,用于回归任务。
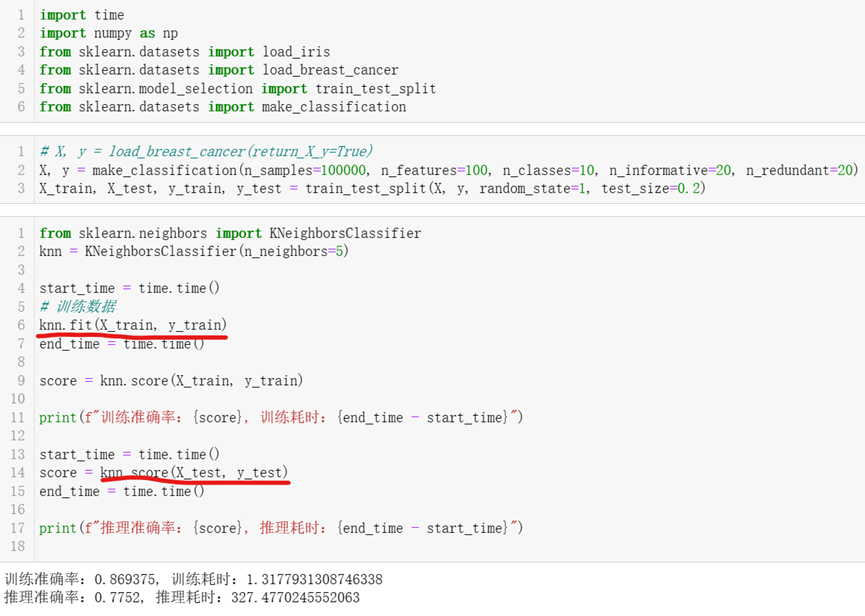
代码中先调用make_classification函数构造100,000条数据做分类任务,然后调用train_test_split将这10,000条数据的80,000条用于训练过程,剩下的20,000条数据用于测试; 然后代码构建KNeighborsClassifier类的实例,并传入超参数n_neighbor=5,即选用最近的5个邻居来定夺待分类点的类别; 之后调用KNeighborsClassifier的fit函数进行训练,其实KNN的训练过程基本也没干啥事,属于平时不看书,只是吃喝玩乐,然后临近考试,考前一天晚上突击一把,第二天直接上考场那种; 训练完毕后,代码调用KNeighborsClassifier的score函数对测试集进行预测并打分。
从执行结果看,KNN的测试准确率在77%左右,2万条数据耗时5分半,估且不论准确率如何,单从耗时看5分半的时间,是绝对不可让用户接受的,这也是KNN死掉的主要原因,但KNN的思想却保留了下来,一直为其他算法所借用。
3、小结
KNN是一种惰性计算方法,所以导致其被AI领域淘汰,但其算法思想却保留了下来,为其他算法借鉴和使用,比如:“近朱者赤,近墨者黑”的思想,被NLP的深度学习算法Embedding所借鉴; 而KNN统计N个邻居的分类或均值的思想,被集成学习等所借鉴采用。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号