异常处理、序列化与I/O流、集合与泛型
使用try/catch/finally块进行异常处理,finally指令无论如何都会执行,如果try或catch块有return指令,会跳到finally然后再回到return指令。多重异常处理(多个catch块),catch块要从小排到大,最大的是Exception,它包含了所有的异常,但是不建议写,因为包含所有反而不知道具体是哪个异常,无法处理。
Java序列化就是指把Java对象转换为字节序列的过程;Java反序列化就是指把字节序列恢复为Java对象的过程。
Serializable接口是标记用接口,唯一目的是声明有实现它的类是可以被序列化的,序列化程序会将对象版图上所有东西存储起来,被对象的实例变量所引用的所有对象都会被序列化,这意味着引用的所有对象必须是可以被序列化的(即对象类要继承Serializable接口),否则应该把他标记成transient(表示不能或不应该被序列化)
将序列化对象写入文件:FileOutputStream file = new FileOutputStream("df.ser");ObjectOutputStream os = new ObjectOutputStream(file);os.writeObject(对象引用);os.close();
解序列化:FileInputStream file = new FileInputStream("df.ser");ObjecIntputStream os = new ObjectInputStream(file);os.readObject(对象引用);os.close();transient标记后,还原时恢复成null或者默认值,static变量不会被序列化,还原时会保持类中原本的样子。
InputStream 是字节输入流的所有类的超类,一般我们使用它的子类,如FileInputStream等;OutputStream是字节输出流的所有类的超类,一般我们使用它的子类,如FileOutputStream等
InputStreamReader 是字节流通向字符流的桥梁,它将字节流转换为字符流;OutputStreamWriter是字符流通向字节流的桥梁,它将字符流转换为字节流
BufferedReader 由Reader类扩展而来,提供通用的缓冲方式文本读取,readLine读取一个文本行,从字符输入流中读取文本,缓冲各个字符,从而提供字符、数组和行的高效读取。BufferedWriter 由Writer 类扩展而来,提供通用的缓冲方式文本写入, newLine使用平台自己的行分隔符,将文本写入字符输出流,缓冲各个字符,从而提供单个字符、数组和字符串的高效写入。
对泛型来说,extends对于接口或类都可以适用,表示“是一个......”,即此处的extends同时表示继承(extends)和实现(implements)。
public <T extends Animal>void take(ArrayList<T> list)不同于public void take(ArrayList<Animal> list),<T extends Animal>是方法声明的一部分,表示任何被声明为Animal或者Animal的子类的ArrayList都是合法的,但是ArrayList<Animal> list代表只有Animal的ArrayList合法。
hashCode()默认的行为会返回每个对象特有的序号(大部分版本都是依据内存位置来计算此序号,所以不会有相同的序号),如果想要把两个不同的对象视为相等,必须重写从Object继承下来的hashCode()方法和equals()方法。if(a.equals(b)&&a.hashCode() == b.hashCode()){//a和b是相等的}
HashSet就是通过hashcode和equals来判断对象有没有重复出现
1.如果两个对象相等,则hashcode必须相同,且对其中一个对象调用equals()必须返回true,即a.equals(b),则b.equals(a),但是hashcode相同的两个对象不一定相等。
2.hashCode()默认是对在heap上的对象产生独特的值,如果没有重写该方法,则该class的两个对象不可能认为是相同的,equals()默认执行==的比较,即测试两个引用是否对上heap上同一个对象,如果没有重写equals(),两个对象不可能相同。
3.若equals()被覆盖过,则hashcode()也必须被覆盖,即a.equals(b),则a.hashCode()==b.hashCode(),但是a.hashCode()==b.hashCode()不一定a.equals(b)
TreeSet的元素必须是Comparable(集合中的元素必须是实现Comparable的类型 或者 使用重载、取用Comparator参数的构造方法)
数组的类型是在运行期间才检查的,但是集合的类型检查只会发生在编译期间
万用字符:?,在方法参数中使用万用字符,编译器会阻止任何可能破坏引用参数所指集合的行为,即可以操作集合元素,但是不可以新增集合元素,例如ArrayList<? extends Pet>
UNIX 系统下, IO 模型一共有 5 种: 同步阻塞 I/O、同步非阻塞 I/O、I/O 多路复用、信号驱动 I/O 和异步 I/O。
Java 中 3 种常见 IO 模型:BIO、NIO、AIO
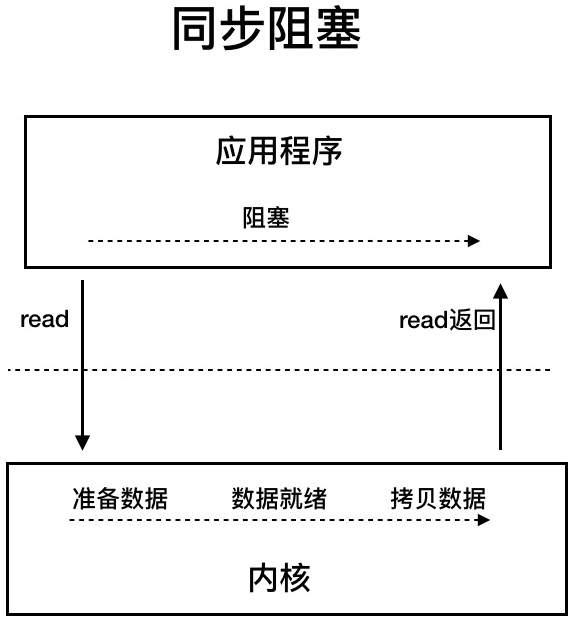
BIO :属于同步阻塞 IO 模型 ,同步阻塞 IO 模型中,应用程序发起 read 调用后,会一直阻塞,直到在内核把数据拷贝到用户空间。在客户端连接数量不高的情况下,是没问题的。但是,当面对十万甚至百万级连接的时候,传统的 BIO 模型是无能为力的。因此,我们需要一种更高效的 I/O 处理模型来应对更高的并发量。
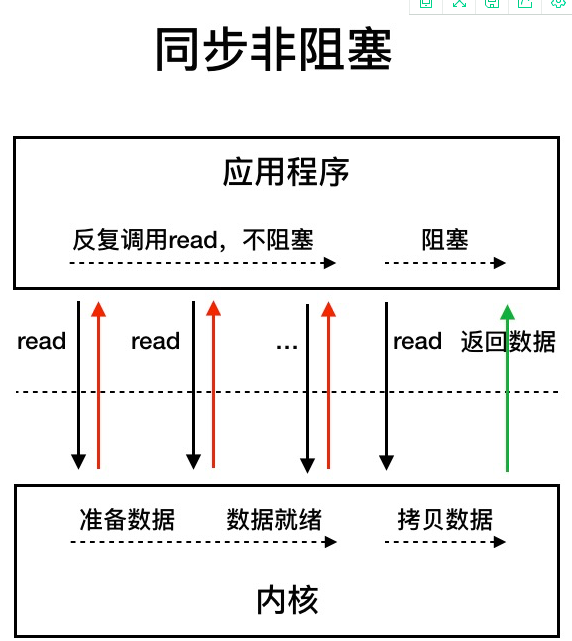
NIO:Java 中的 NIO 于 Java 1.4 中引入,对应 java.nio 包,提供了 Channel , Selector,Buffer 等抽象。NIO 中的 N 可以理解为 Non-blocking,不单纯是 New。它支持面向缓冲的,基于通道的 I/O 操作方法。 对于高负载、高并发的(网络)应用,应使用 NIO 。ava 中的 NIO 可以看作是 I/O 多路复用模型。也有很多人认为,Java 中的 NIO 属于同步非阻塞 IO 模型。
I/O多路复用:IO 多路复用模型中,线程首先发起 select 调用,询问内核数据是否准备就绪,等内核把数据准备好了,用户线程再发起 read 调用。read 调用的过程(数据从内核空间->用户空间)还是阻塞的。IO 多路复用模型,通过减少无效的系统调用,减少了对 CPU 资源的消耗。

AIO:AIO 也就是 NIO 2。Java 7 中引入了 NIO 的改进版 NIO 2,它是异步 IO 模型。异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号