数据库
事务
数据库事务(Database Transaction) ,是指作为单个逻辑工作单元执行的一系列操作,要么完全地执行,要么完全地不执行。事务处理可以确保除非事务性单元内的所有操作都成功完成,否则不会永久更新面向数据的资源。通过将一组相关操作组合为一个要么全部成功要么全部失败的单元,可以简化错误恢复并使应用程序更加可靠。一个逻辑工作单元要成为事务,必须满足所谓的ACID(原子性、一致性、隔离性和持久性)特性。事务是数据库运行中的逻辑工作单位,由DBMS中的事务管理子系统负责事务的处理。
ACID特性
原子性(Atomicity):
原子性是指事务包含的所有操作要么全部成功,要么全部失败回滚,因此事务的操作如果成功就必须要完全应用到数据库,如果操作失败则不能对数据库有任何影响。
一致性(Consistency):
事务开始前和结束后,数据库的完整性约束没有被破坏。比如A向B转账,不可能A扣了钱,B却没收到。
隔离性(Isolation):
隔离性是当多个用户并发访问数据库时,比如操作同一张表时,数据库为每一个用户开启的事务,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离。同一时间,只允许一个事务请求同一数据,不同的事务之间彼此没有任何干扰。比如A正在从一张银行卡中取钱,在A取钱的过程结束前,B不能向这张卡转账。
持久性(Durability):
持久性是指一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作。
事务的并发问题
1、脏读:事务A读取了事务B更新的数据,然后B回滚操作,那么A读取到的数据是脏数据
2、不可重复读:事务 A 多次读取同一数据,事务 B 在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果因此本事务先后两次读到的数据结果会不一致。
3、幻读:幻读解决了不重复读,保证了同一个事务里,查询的结果都是事务开始时的状态(一致性)。
例如:事务T1对一个表中所有的行的某个数据项做了从“1”修改为“2”的操作,这时事务T2又对这个表中插入了一行数据项,而这个数据项的数值还是为“1”并且提交给数据库。 而操作事务T1的用户如果再查看刚刚修改的数据,会发现还有跟没有修改一样,其实这行是从事务T2中添加的,就好像产生幻觉一样,这就是发生了幻读。
事务的隔离级别
读未提交:另一个事务修改了数据,但尚未提交,而本事务中的SELECT会读到这些未被提交的数据(脏读)
不可重复读:事务 A 多次读取同一数据,事务 B 在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果因此本事务先后两次读到的数据结果会不一致。
可重复读:在同一个事务里,SELECT的结果是事务开始时时间点的状态,因此,同样的SELECT操作读到的结果会是一致的。但是,会有幻读现象
串行化:最高的隔离级别,在这个隔离级别下,不会产生任何异常。并发的事务,就像事务是在一个个按照顺序执行一样
范式
第一范式
属于第一范式关系的所有属性都不可再分,即数据项不可分。
第二范式
若某关系R属于第一范式,且每一个非主属性完全函数依赖于任何一个候选码,则关系R属于第二范式。(没有非主属性对码的部分依赖)
第三范式
非主属性既不传递依赖于码,也不部分依赖于码。(没有非主属性对码的传递依赖)
索引
索引是帮助数据库高效获取数据的排好序的数据结构(二叉搜索树、红黑树、Hash表、B-Tree)
二叉搜索树
因为二叉搜索树不平衡,如果数据是单调的,树就退化成一条链
红黑树
每个节点要么是黑色,要么是红色。根节点是黑色。叶子节点是黑色。每个红色结点的两个子结点一定都是黑色。任意一结点到每个叶子结点的路径都包含数量相同的黑结点。
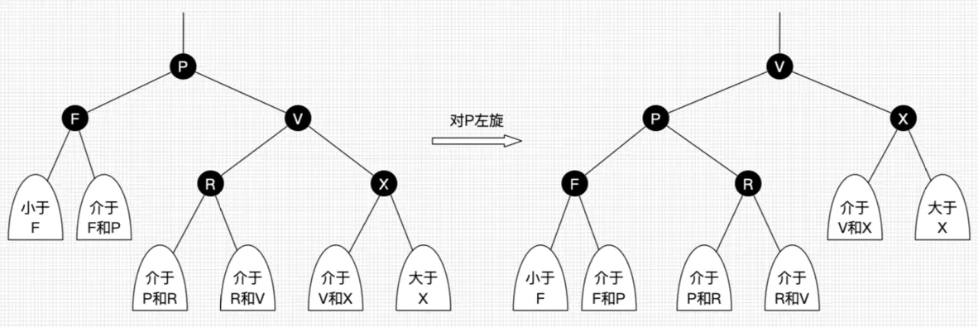
虽然红黑树比较平衡,但因为红黑树是二叉树,如果数据量很大,树的高度会变得很大(几十),从磁盘到内存I/O次数很多,但我们期望树的高度在3-5之间。
因此我们不难想到,可以使得每个节点存更多的元素,便有了B-Tree
B-Tree
叶节点具有相同的深度
叶节点的指针为空
所有索引元素不重复
节点中的数据索引从左到右递增排列
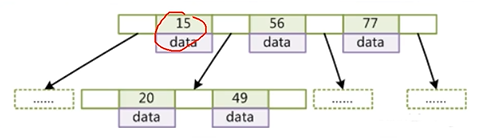
MySQL中对每个节点大小有限制(16KB),如果可以不在非叶子节点存date,就可以使得在同样大小的节点中存放更多的索引。
B+树
非叶子节点不存储data,只存储索引(冗余),可以放更多的索引
叶子节点包含所有索引字段
叶子节点用指针连接,提高区间访问的性能
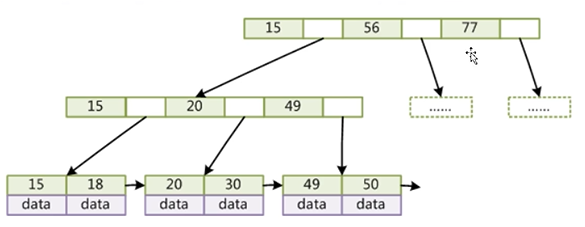
指针:更方便的支持范围查找(>20,定位到20之后不需要再回到根节点)
存储引擎
MyISAM存储引擎
索引文件和数据文件是分离的(非聚簇)
.frm表结构文件 MYD数据 MYI索引数据
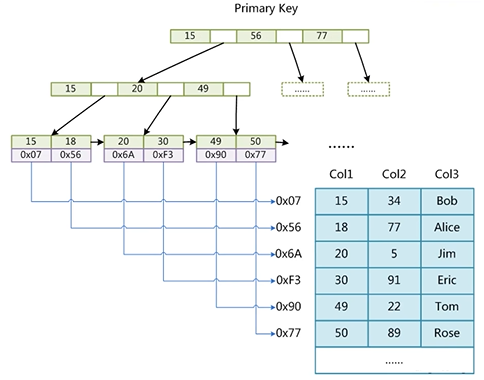
InnoDB存储引擎
表数据文件本身就是按B+Tree组织的一个索引结构文件
聚集索引-叶节点包含了完整的数据记录
为什么非主键索引结构叶子节点存储的是主键值? (一致性和节省存储空间)
.frm表结构文件 ibd索引和数据

InnoDB 和Mylsam的区别:
1)事务:MyISAM类型不支持事务处理等高级处理,而InnoDB类型支持,提供事务支持以及外键等高级数据库功能。
2)性能:MyISAM类型的表强调的是性能,其执行速度比InnoDB类型更快。
3)行数保存:InnoDB 中不保存表的具体行数,也就是说,执行select count () from table时,InnoDB要扫描整个表来计算有多少行,但是MyISAM只要简单的读出保存好的行数即可。注意的是,当count ()语句包含where条件时,两种表的操作是一样的。
4)索引存储:对于AUTO_ INCREMENT 类型的字段,InnoDB 中必须包含只有该字段的索引,但是在MyISAM表中,可以和其他字段一起建立联合索引。MyISAM 支持全文索引(FULLTEXT) 、压缩索引,InnoDB 不支持。
MyISAM的索引和数据是分开的,并且索引是有压缩的,内存使用率就对应提高了不少。能加载更多索引,而Innodb是索引和数据是紧密捆绑的,没有使用压缩从而会造成Innodb比MyISAM体积庞大不小。
InnoDB存储引擎被完全与MySQL服务器整合,InnoDB存储引擎为在主内存中缓存数据和索引而维持它自己的缓冲池。InnoDB 存储它的表&索引在一个表空间中,表空间可以包含数个文件(或原始磁盘分区)。这与MyISAM表不同,比如在MyISAM表中每个表被存在分离的文件中。InnoDB表可以是任何尺寸,即使在文件尺寸被限制为2GB的操作系统上。
适合建立索引的情况:
(1)在经常需要搜索的列上,可以加快搜索的速度;
(2)在作为主键的列上,强制该列的唯一性和组织表中数据的排列结构;
(3)在经常用在连接的列上,这些列主要是一些外键,可以加快连接的速度;
(4)在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的;
(5)在经常需要排序的列上创建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间;
(6)在经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度。
参考:
https://www.bilibili.com/video/BV1aE41117sk?from=search&seid=17029850644712707531

 浙公网安备 33010602011771号
浙公网安备 33010602011771号