
如何利用火焰图定位 Java 的 CPU 性能问题
常见 CPU 性能问题
你所负责的服务(下称:服务)是否遇到过以下现象:
- 休息的时候,手机突然收到大量告警短信,提示服务的 99.9 line 从 20ms 飙升至 10s;
- 正在敲代码实现业务功能时,收到业务/客服同事电话,反馈系统打不开;
- 下班后,收到运维同学电话,服务器监控告警提示“某个机器的负载(Load Average)从 0.1、0.5、0.8 突然间飙升至 9.73、10.67、10.49”。
结果:引发雪崩的场景如下图所示:

通常造成这几种现象的根本原因主要有以下 3 点。
- 服务在某个时间点运行了某一个定时器,但因为最近业务数据量增加,导致提取了大量数据到服务进行计算。
- 外部系统因为系统问题/数据量增加/逻辑修改,向消息中间件推送比平常多 10 倍的消息,此时服务消费了 MQ 消息,将消息内容放入一个新线程进行异步处理。而给消息中间件返回消息已处理完成,导致消息中间件一直给服务推送消息。
- 上线一个可以从 C 端触发需要大量 CPU 计算的功能,上线后使用的用户比预估量高 5 倍。
我们再来回顾一下之前的过程,如下图所示:

从现象到结果(CPU 问题),再到追溯原因这一过程,通常是通过对时间点、查日志、找上下游问题、Code Review、推测出问题代码,从而得出最终结论。但这种方式的缺点是耗时较长,且不能保证得到的结果一定是真实的。
利用工具定位 CPU 性能问题
借助Flame Graph(下称 CPU 火焰图),来定位 CPU 性能问题。
在实际工作中,使用 CPU 火焰图用于量化框架中的性能,包括代码编译消耗的时间、代码缓存、其他系统内库及内核代码执行的时间,通常用于定位 CPU 使用率问题。生成火焰图的方式有基于 Perf 或者Arthas。
利用 Perf 生成火焰图
从 Linux 系统原生提供的性能分析工具 perf 命令(performance 的缩写)说起,该命令执行后,会返回 CPU 正在执行的函数名以及调用栈(stack)。 通常,它的执行频率是 99Hz(每秒 99 次)。如果 99 次都返回同一个函数名,那就证明 CPU 同一秒钟都执行同一个函数,可能存在性能问题。具体可以通过执行以下 perf 命令获取对应的性能日志:
1 perf record -F 99 -p PID -g
该命令返回一个用于记录 CPU 调用栈的文本文件,该文件长达几十万甚至上百万行,输出的日志文件并不方便阅读,所以需要有一个将日志文件转成火焰图的工具——perf report。
1 perf report -n --stdio
perf report 命令可以很好地将数百个堆栈跟踪样本汇总为文本。类似的代码路径合并在一起,文本输出的信息为树形图,而每个叶子上都有 CPU 占用的百分比。从左上角到右下角读取路径,
- perf 可以通过命令生成 CPU 在执行什么,但并不能直接显示 Java 进程的调用栈。那用什么方式可以与 Java 进程的调用栈结合起来生成火焰图呢?
- perf_events:标准 Linux 分析器,用于生成系统堆栈。
- perf-map-agent:提供转换 perf_events 带有 Java 标示的 JVMTI 代理。
- Misc:生成全部 Java 进程的堆栈信息。
- Flame Graph:通过已经生成的 Java 堆栈信息,生成火焰图。
火焰图种类
火焰图(Flame Graph):最普通/朴素的火焰图,标示了每一个调用栈的深度与执行时间。
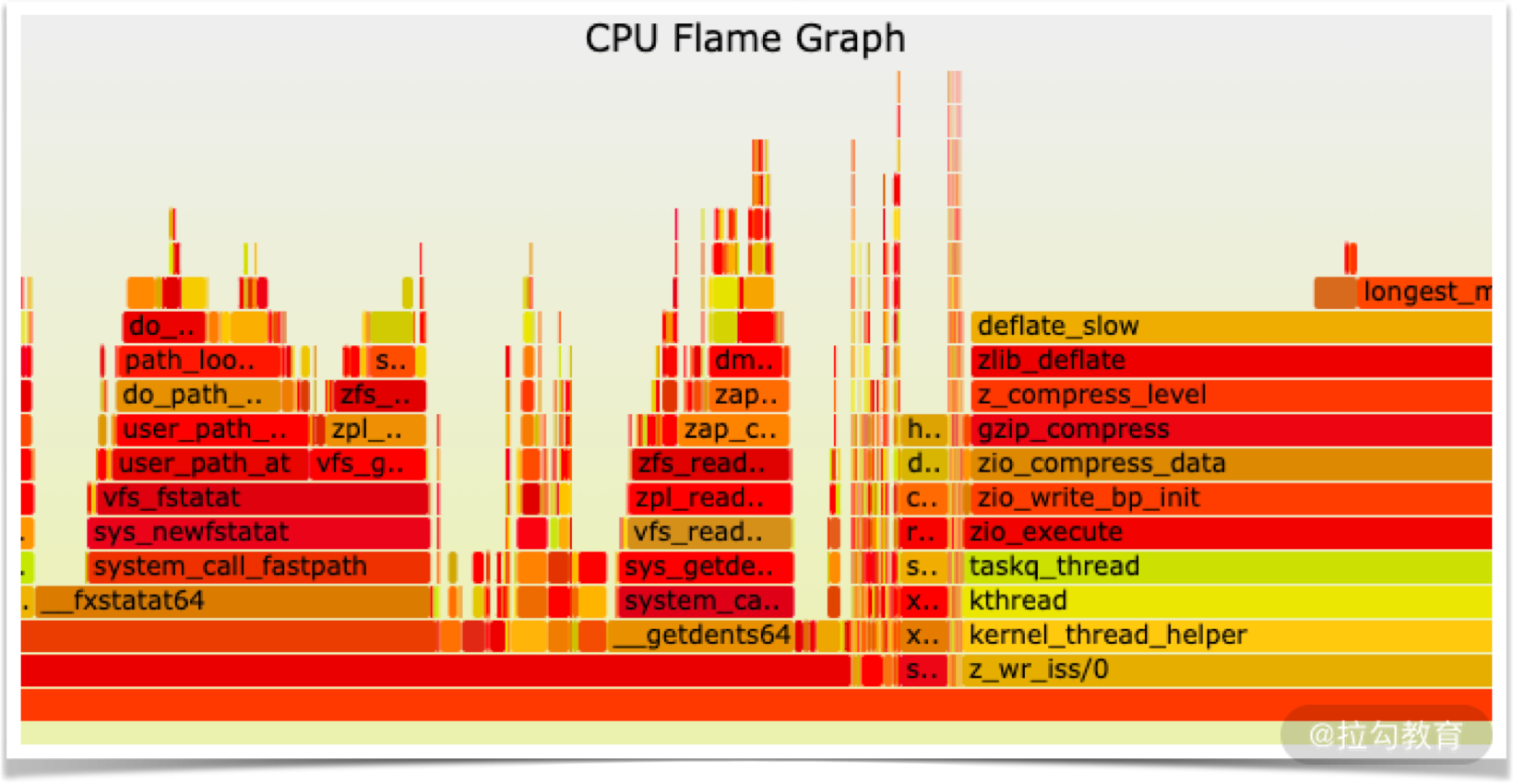
红蓝微分火焰图(Differential Flame Graph):有两个值列,用于显示计数之前和之后。使用第二列(“之后”或“现在”)调整火焰图的大小,然后使用 2-1 的增量进行着色:正极为红色,负极为蓝色。pl 工具获取两个折叠样式的概要文件(使用 stackcollapse 脚本生成)并发出这两列输出。

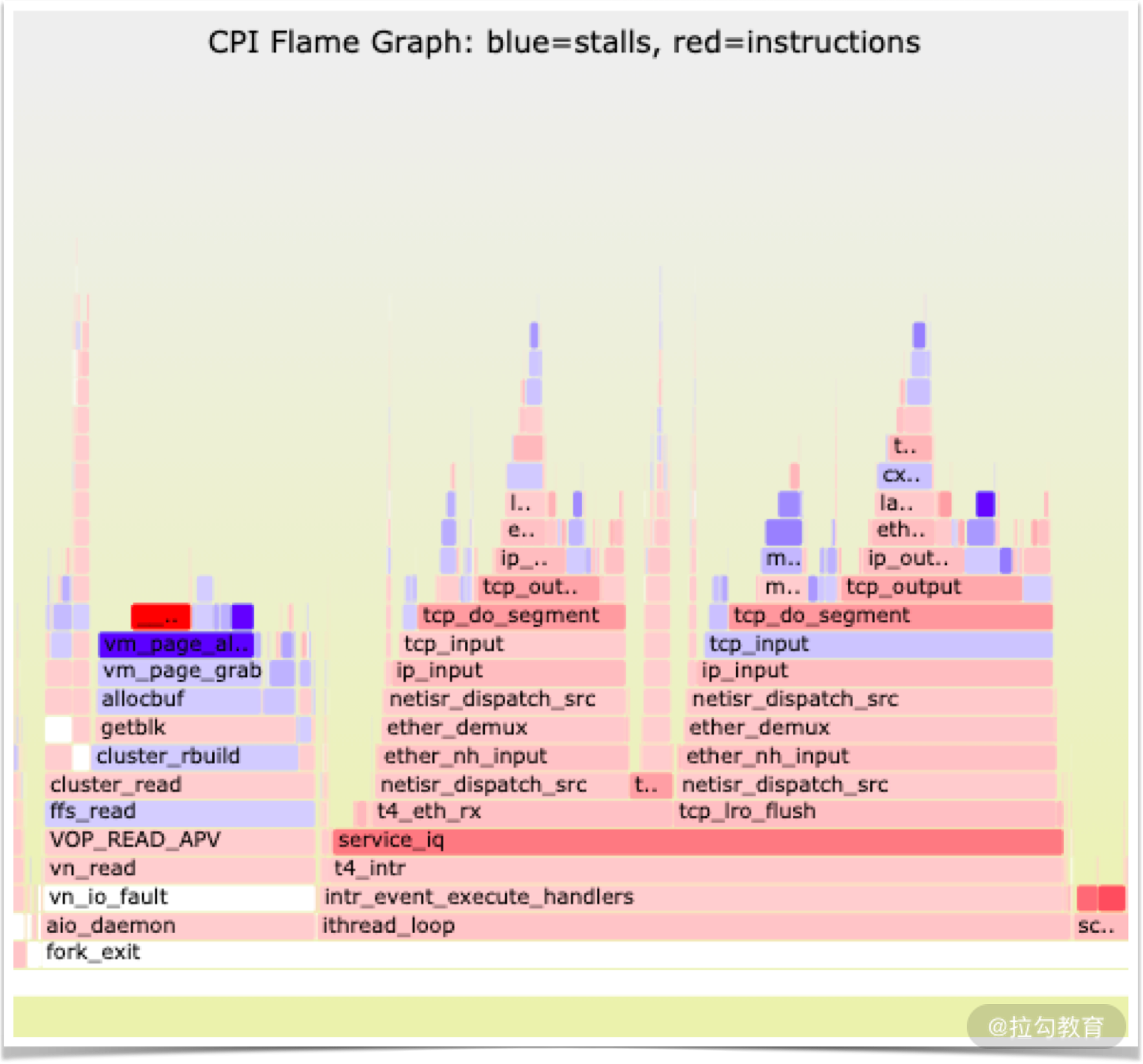
CPI 火焰图(CPI Flame Graph):测量每条指令的平均周期(CPI)比率,越高的值意味着完成指令需要更多的周期(通常指等待内存 I/O 的“停滞周期”),往往作为一个全系统的指标来研究。
CPI(平均每条指令的平均时钟周期数)=(CPU 时间/IC 指令数)*频率
耗时分析方法

请看以上实际的火焰图例子,例子中包含各种叠起来并且大小不一的图形,那如何得知哪个方法耗时最多?下面我们来分析一下如何阅读上述火焰图。
- Y 轴:栈深度
- X 轴:CPU 耗时
- 长方形:一个栈(方法)
- 长度:出现在监视器中的时长(占用 CPU 的时间)
- 其他:从左到右的顺序只是按照字母排序,并无意义
通过上述分析,我们知道了图中各种数字的含义。因为下面调用栈的耗时是依赖于上面调用栈,所以越往上的调用栈长方形越长,CPU 在该调用栈的耗时越多。因此,上图中耗时最多的方法应该是 f()。
总结一下,阅读火焰图的方式主要有以下两种。
- 从下到上:从父到子方法追查。
- 从左到右:先找出占用最多时间的栈,关注最宽的方法。
如何排查线上 CPU 问题
定位到 CPU 问题后,接下来开始排查线上问题。
- 压测环境:在压测环境,我们可以通过压测与监控工具,发现性能问题。利用 CPU 火焰图,在压测时,通过对 CPU 进行定时采样,定位具体占用 CPU 调用栈。
- 模拟环境:建立一个基于线上,但与其隔离的模拟环境。通过流量复制工具,将线上流量复制到模拟环境。再通过对 CPU 进行定时采样,将采样的日志生成火焰图,从而定位具体占用 CPU 调用栈。
下图是一个线上发生 CPU 性能问题的例子:

如果线在顶部代表 CPU 空闲,线在底部代表 CPU 繁忙。该问题是在用户量不多的服务中发生的,此时可以先回顾一下问题的过程。
时间点 1 发布了一个包含监控功能与业务功能的版本。慢慢地 CPU 开始繁忙起来。到时间点 2,CPU 使用率超过 50%,持续了 3 小时。在时间点 3 实施过重启操作,CPU 使用率回归正常,但慢慢地也在往上增加。在时间点 4 ,回滚业务功能,但CPU 没有降下来。在时间点 5 实施回滚监控功能,服务恢复正常。
在上述处理线上 CPU 问题的过程中,采取了回滚版本让服务恢复正常。但如何才能定位 CPU 在哪里被占用最多呢?这时候,CPU 火焰图就需要登场了。
在压测环境,使用压测工具(ab/wrk/jmeter 等)对服务的 URL 进行随机参数的请求。发现 CPU 在压测开始 10 分钟之后,CPU 慢慢上升,服务响应越来越慢。此时使用 perf 工具对 CPU 进行采样,通过火焰图工具将采样的日志生成包含调用栈的火焰图。
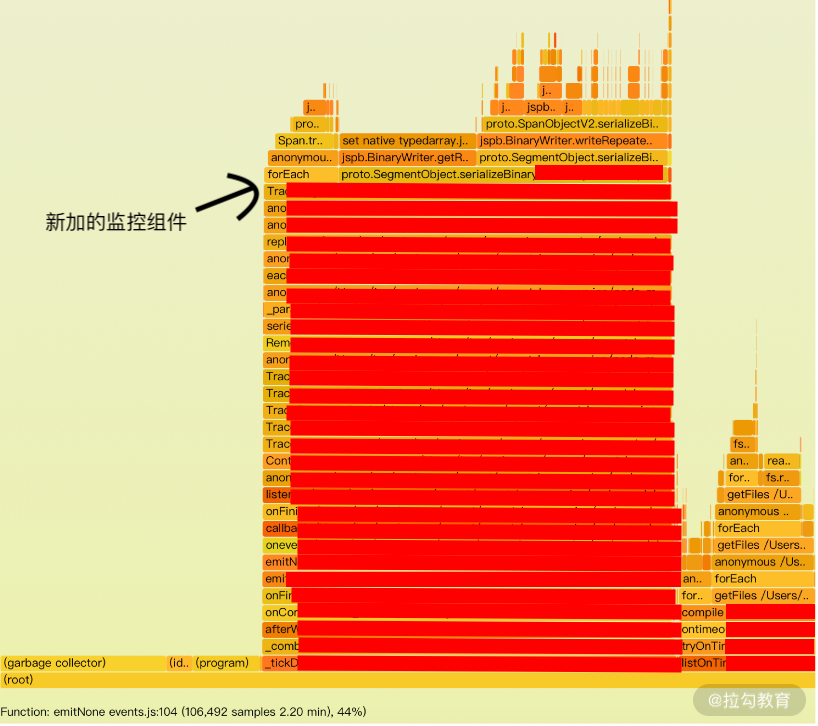
从上图中可以看出,大部分时间在执行服务中的逻辑,指向新加的服务监控组件。但此时问题在于:监控组件创建 span 时应该是根据路径作为 key,指向已缓存的数据可以加快处理时间。
而实际情况则是将参数也放到了缓存 key 中,所以缓存没命中,导致key一直在创建,长期地占用 CPU 在计算 key 是否有命中,从而产生 CPU 性能问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号