Python_pandas
详细教程:https://www.gairuo.com/p/pandas-sheet
https://geek-docs.com/pandas/python-pandas-series/python-pandas-series-filter.html
一、pandas简介
pandas是基于NumPy构建的一个强大的Python数据分析的工具包。
主要功能:
- 具备对其功能的数据结构:DataFrame、Series
- 集成时间序列功能
- 提供丰富的数学运算和操作
- 灵活处理缺失数据
安装方法
pip install pandas
二、pandas.Series
- Series是一种类似于一维数组的对象,由一组数据和一组与之相关的数据索引组成。
- Series比较像列表 (数组)和字典的结合体
2.1 创建方式
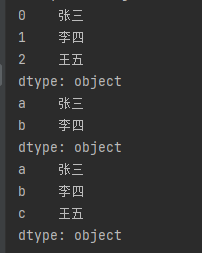
import pandas as pd # 当传入值为列表时,数据索引从0开始自增 sr = pd.Series(["张三", "李四", "王五"]) print(sr) # 当传入值为字典时,数据索引为key sr = pd.Series({'a': "张三", 'b': "李四"}) print(sr) # 通过index参数指定数据索引 sr = pd.Series(["张三", "李四", "王五"], index=["a", "b", "c"]) print(sr)
2.2 特性
- Series对象是可迭代对象,for 循环可遍历所有值
- 算数运算: sr*2、sr1+sr2。注:pandas在运算时,会按索引进行对齐然后计算。如果存在不同的索引,则结果的索引是两个操作数索引的并集。
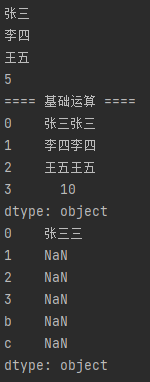
import pandas as pd # 当传入值为列表时,标签索引从0开始自增 sr = pd.Series(["张三", "李四", "王五", 5]) sr1 = pd.Series({0: "三", "b": "四", "c": "五"}) # for循环可遍历所有值 for i in sr: print(i) # 支持算数运算 print("==== 基础运算 ====") print(sr * 2) # 两个sr运算时,只有索引值相同的数据才会进行计算,不相同部分结果为NaN print(sr + sr1)
2.3 常用属性和方法
index:获取数据索引列表
values:获取数据列表
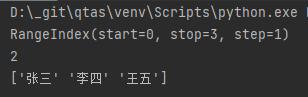
import pandas as pd # 当传入值为列表时,标签索引从0开始自增 sr = pd.Series(["张三", "李四", "王五"]) # 获取索引列表 print(sr.index) print(sr.index[-1]) # 获取数据列表 print(sr.values)
sum():当数据类型为数字时,可用该方法求和
max():最大值
min():最小值
mean():平均值
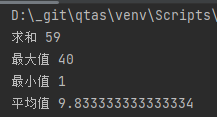
import pandas as pd sr = pd.Series([1, 4, 6, 40, 4, 4]) print("求和", sr.sum()) print("最大值", sr.max()) print("最小值", sr.min()) print("平均值", sr.mean())
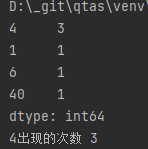
value_counts():统计每个字符出现的次数
import pandas as pd sr = pd.Series([1, 4, 6, 40, 4, 4]) c = sr.value_counts() print(c) print("4出现的次数", c[4])
2.4 取值
2.4.1 索引和切片取值
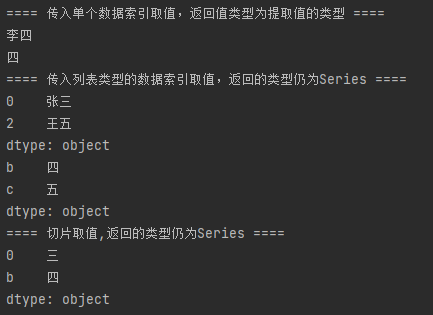
import pandas as pd # 当传入值为列表时,标签索引从0开始自增 sr = pd.Series(["张三", "李四", "王五", 5]) sr1 = pd.Series({0: "三", "b": "四", "c": "五"}) # 取值 print("==== 传入单个数据索引取值,返回值类型为提取值的类型 ====") print(sr.get(1)) print(sr1["b"]) print("==== 传入列表类型的数据索引取值,返回的类型仍为Series ====") print(sr.get([0, 2])) print(sr1[['b', 'c']]) print("==== 切片取值,返回的类型仍为Series ====") print(sr1[:2])
2.4.2 使用loc和iloc方法取值
- loc:通过数据索引值获取值。与直接通过索引值取值一样。
- iloc:通过数据下标索引获取值。与直接通过下标切片取值一样
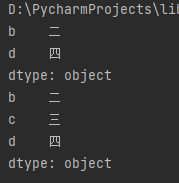
import pandas as pd sr = pd.Series({"a": "一", "b": "二", "c": "三", "d": "四"}) # loc:通过数据索引值获取值 print(sr.loc[["b", "d"]] # iloc:通过数据下标获取值 print(sr.iloc[1:])
2.4.3 比较运算取值
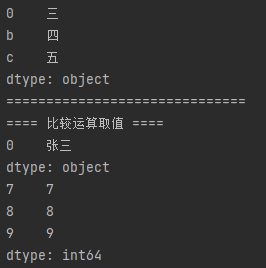
import pandas as pd # 当传入值为列表时,标签索引从0开始自增 sr = pd.Series(["张三", "李四", "王五", 5]) sr1 = pd.Series({0: "三", "b": "四", "c": "五"}) print(sr1) print("=" * 30) print("==== 比较运算取值 ====") # 获取值为 张三的值 print(sr["张三" == sr]) # 获取大于6的值 sr3 = pd.Series(range(10)) print(sr3[sr3 > 6])
2.5 数据处理
- dropna() 去除NaN
- fillna(填充值) 将NaN替换为指定值
- isnull() 判断是否是空值
- notnull() 判断是不是非空值
- round() 对数据进行四舍五入
-
astype(type) 将数据转化成对应类型。比如 sr.astype(str)将sr数据的格式转化成字符串
- str.slice() 截取数据
import pandas as pd sr1 = pd.Series([1.1235, 3.1114, 4]) sr2 = pd.Series([5.2356, 5.2111, 6, 7]) sr = sr1 + sr2 print(sr) print("-" * 30) # 去除NaN print(sr.dropna()) print("-" * 30) # 以0填充空值 print(sr.fillna(0)) print("-" * 30) # 四舍五入 print(sr.round(2)) print("-" * 30)
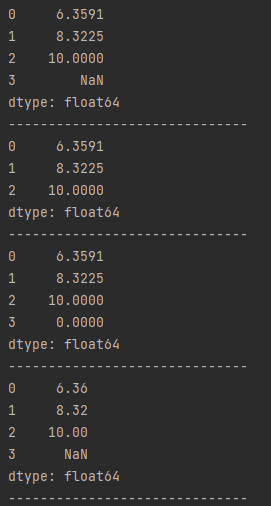
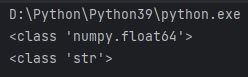
import pandas as pd sr = pd.Series([3.1114, 4]) print(type(sr[0])) sr = sr.astype(str) print(type(sr[0]))
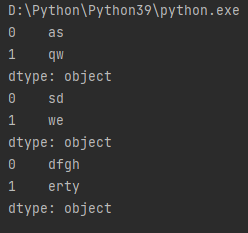
import pandas as pd sr1 = pd.Series(["asdfgh", "qwerty"]) # 截取前两位 print(sr1.str.slice(stop=2)) # 截取第3~4位 print(sr1.str.slice(start=1, stop=3)) # 截取第3位及之后 print(sr1.str.slice(start=2))
三、pandas.DataFrame
- DataFrame是一种表格型的数据结构,是一组有序的Series列。
- DataFrame可以看做是由Series组成的字典。
3.1 创建方式
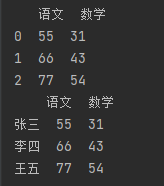
import pandas as pd # 不指定数据索引。 数据索引从0自增 df_data = {"语文": [55, 66, 77], "数学": [31, 43, 54]} df = pd.DataFrame(df_data) print(df) # 指定数据索引。 数据索引从0自增 df_data = {"语文": [55, 66, 77], "数学": [31, 43, 54]} df = pd.DataFrame(df_data, index=["张三", "李四", "王五"]) print(df)
3.2 取值
3.2.1 通过字典方式和loc方法进行索引取值
- 通过字段方式索引取值需要先传入列索引,再传入行索引进行取值。如果只传入列索引,获取到是对应的列值,类型为 Series
- 通过loc方法索引取值需要先传入行索引,再传入列索引进行取值。如果只传入行索引,获取到的是对应行值,类型为 Series
import pandas as pd # 指定数据索引。 df_data = {"语文": [55, 66, 77], "数学": [31, 43, 54], "英语": [88, 44, 22]} df = pd.DataFrame(df_data, index=["张三", "李四", "王五"]) print(df) print("=" * 30) # 通过字段方式获取值 # sr1 = df["语文"] sr1 = df.get("语文") # 获取语文科目的所有成绩 print(sr1) # 通过loc方法获取值 sr2 = df.loc["李四"] # 获取李四的所有成绩 print(sr2) # 只传入第1个索引获取到的是 Series 数据对象 print(type(sr1), type(sr2)) # 获取语文科目 李四的成绩 print("索引方式获取 李四的语文成绩", df.get("语文").get("李四")) print("使用loc方法索引方式获取 李四的语文成绩", df.loc["李四"].get("语文")) # 也可以在loc中同时传入行索引和列索引,注意行索引必须在前 print("使用loc方法索引方式获取 李四的语文成绩", df.loc["李四", "语文"])
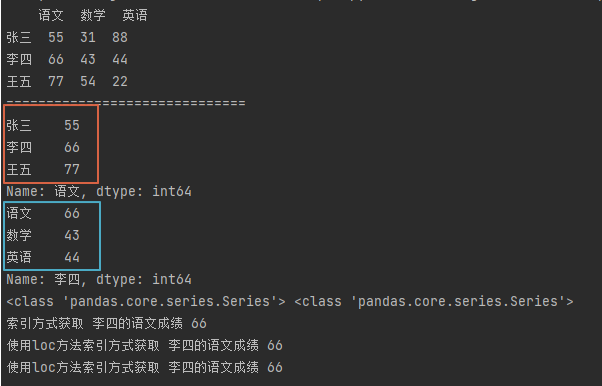
通过框选部分可以看出,可以根据数据维度,灵活选择获取值的方式
3.2.2 使用切片方式和iloc方法获取值
- 切片方式不能使用索引值,只能传切片值,所以切片后的数据类型仍为DataFrame,不能提取值,但可以用于对数据的分割处理
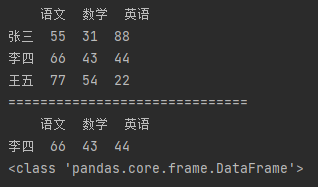
import pandas as pd # 指定数据索引 df_data = {"语文": [55, 66, 77], "数学": [31, 43, 54], "英语": [88, 44, 22]} df = pd.DataFrame(df_data, index=["张三", "李四", "王五"]) print(df) print("=" * 30) # 通过切片方式获取值。切片是以行索引的下标值进行切片 sr1 = df[1:2] # 获取李四所有成绩 print(sr1) print(type(sr1)) # 数据类型仍为DataFrame
iloc属性可以用切片方式对数据进行处理,也可以直接传入下标索引获取值
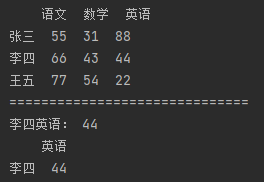
import pandas as pd # 指定数据索引 df_data = {"语文": [55, 66, 77], "数学": [31, 43, 54], "英语": [88, 44, 22]} df = pd.DataFrame(df_data, index=["张三", "李四", "王五"]) print(df) print("=" * 30) # 使用索引下标直接获取值 print("李四英语:", df.iloc[1, 2]) # 也可以使用切片方式处理值,返回值的类型为DataFrame print(df.iloc[1:2, 2:])
3.3 过滤DataFrame - 索引
上面介绍字典和loc取值方法如果传入列表值,返回的是DataFrame对象实例,通过这个特性,可以实现对DataFrame的过滤。
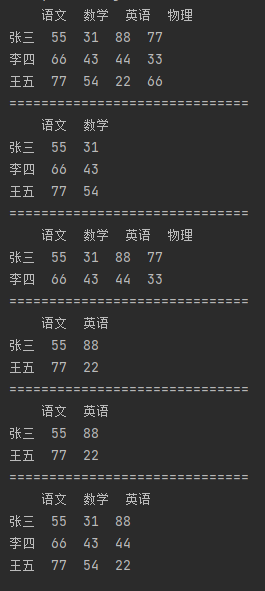
import pandas as pd # 指定数据索引 df_data = {"语文": [55, 66, 77], "数学": [31, 43, 54], "英语": [88, 44, 22], "物理": [77, 33, 66]} df = pd.DataFrame(df_data, index=["张三", "李四", "王五"]) print(df) print("=" * 30) # 提取表格中的语文、数学字段生成新的表格 new_df = df[["语文", "数学"]] print(new_df) print("=" * 30) # 提取表格中的张三、李四字段生成新的表格 new_df = df.loc[["张三", "李四"]] print(new_df) print("=" * 30) # 提取表格中张三、王五的语文和英语成绩,并生成新的表格 new_df = df.loc[["张三", "王五"], ["语文", "英语"]] print(new_df) print("=" * 30) # 上面的需求,也可以用相对笨拙的方式实现 new_df = df[["语文", "英语"]].loc[["张三", "王五"]] print(new_df) print("=" * 30) # 使用loc可以提取两个字段之间的全部信息 # 提取所有人的语文到英语之间的所有字段信息 new_df = df.loc[:, "语文":"英语"] print(new_df)
3.4 过滤DataFrame - 布尔值
布尔值过滤的原理是对某个条件进行布尔判断,返回一个布尔值的Series类型值,然后过滤出为True的数据
import pandas as pd # 指定数据索引。 df_data = {"语文": [55, 66, 77], "数学": [31, 43, 54], "英语": [88, 44, 22], "考试日期": ["2022-03-01", "2022-03-02", "2022-04-03"]} df = pd.DataFrame(df_data, index=["张三", "李四", "王五"]) print(df) print("=" * 30) # 对语文成绩大于60进行进行布尔判断 ret = df["语文"] > 60 print(ret) print(type(ret)) # 返回布尔值为True的全部信息 print(df[ret])
● 匹配等于指定字符串的行数据
import pandas as pd df_data = {"语文": [55, 66, 77], "数学": [31, 43, 54], "英语": [88, 44, 22], "考试日期": ["2022-03-01", "2022-03-02", "2022-04-03"]} df = pd.DataFrame(df_data, index=["张三", "李四", "王五"]) print(df) print("=" * 30) # 【过滤等于指定字符串的行(精确匹配)】 # 获取语文分数大于60的学生的全部分数 new_df = df[df["语文"] > 60] print(new_df) print("=" * 30) # 获取2022-03-01 和 2022-03-01 的考试结果 # 可用isin方法 new_df = df[df["考试日期"].isin(["2022-03-01", "2022-03-02"])] print(new_df) # 也可以用比较运算,但不建议 new_df = df[(df["考试日期"] == "2022-03-01") | (df["考试日期"] == "2022-03-02")] print(new_df)
● 匹配包含指定字符串的行数据
import pandas as pd df_data = {"语文": [55, 66, 77], "数学": [31, 43, 54], "英语": [88, 44, 22], "考试日期": ["2022-03-01", "2022-03-02", "2022-04-03"]} df = pd.DataFrame(df_data, index=["张三", "李四", "王五"]) print(df) print("=" * 30) # 【过滤包含指定字符串的行】 # 获取日期包含 04 的数据 new_df = df[df["考试日期"].str.contains("04")] print(new_df)
● 使用逻辑运算符 非(~)匹配不包含指定字符串的行数据
import pandas as pd df_data = {"语文": [55, 66, 77], "数学": [31, 43, 54], "英语": [88, 44, 22], "考试日期": ["2022-03-01", "2022-03-02", "2022-04-03"]} df = pd.DataFrame(df_data, index=["张三", "李四", "王五"]) print(df) print("=" * 30) # 【过滤不包含指定字符串的行】 # 获取日期不包含 ‘04’ 的行数据 new_df = df[~ df["考试日期"].str.contains("04")] print(new_df)
● 使用逻辑运算符 非(~)匹配不包含指定字符串的字段
过滤空字段
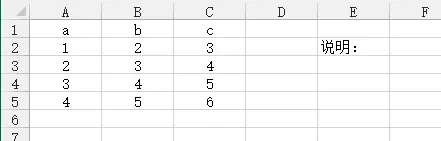
>>> import pandas as pd >>> data = pd.read_excel('a.xlsx') a b c Unnamed: 3 Unnamed: 4 0 1 2 3 NaN 说明: 1 2 3 4 NaN NaN 2 3 4 5 NaN NaN 3 4 5 6 NaN NaN >>> new_data = data.loc[:, ~data.columns.str.contains("Unnamed")] a b c 0 1 2 3 1 2 3 4 2 3 4 5 3 4 5 6
● 使用逻辑运算符 与(&)匹配多个条件的行数据
import pandas as pd df_data = {"语文": [55, 66, 77], "数学": [31, 43, 54], "英语": [88, 44, 22], "考试日期": ["2022-03-01", "2022-03-02", "2022-04-03"]} df = pd.DataFrame(df_data, index=["张三", "李四", "王五"]) print(df) print("=" * 30) # 【多条件并集过滤数据】 # 获取日期 不包含04 且包含01 的行数据 new_df = df[~ df["考试日期"].str.contains("04") & df["考试日期"].str.contains("01")] print(new_df)
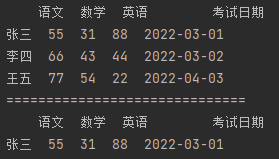
● 使用逻辑运算符 或(|)匹配多个条件的行数据
import pandas as pd df_data = {"语文": [55, 66, 77], "数学": [31, 43, 54], "英语": [88, 44, 22], "考试日期": ["2022-03-01", "2022-03-02", "2022-04-03"]} df = pd.DataFrame(df_data, index=["张三", "李四", "王五"]) print(df) print("=" * 30) # 【多条件并集过滤数据】 # 获取日期 包含04 或 包含01 的行数据 new_df = df[df["考试日期"].str.contains("04") | df["考试日期"].str.contains("01")] print(new_df)
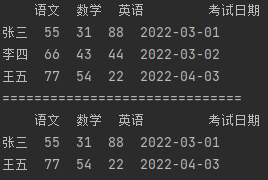
● 使用逻辑运算符 或(|)匹配多个条件的行数据
3.5 过滤DataFrame - filter()方法
参考 DataFrame常用属性和方法中 的filter方法
3.6 数据对齐
DataFrame对象在运算时,会从行索引与列索引两个维度进行数据对齐运算,都存在的列索引和行索引会进行运算,反之,会以NaN填充。
import pandas as pd df_data1 = {"语文": [55, 66], "数学": [31, 43], "英语": [88, 44]} df1 = pd.DataFrame(df_data1, index=["张三", "李四"]) df_data2 = {"语文": [22, 33], "数学": [55, 77], "英语": [88, 44], "化学": [31, 43]} df2 = pd.DataFrame(df_data2, index=["张三", "王五"]) df = df1 + df2 print(df)
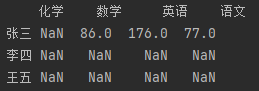
3.7 数据处理
- dropna(axis=0,where='any'...) 丢掉空值
- fillna(value) 将空值填充为value
- isnull() 判断是不是空
- notnull() 判断是不是非空
- round() 对数据进行四舍五入处理
- df[index] = value 将df数据中的index索引字段列或行全部修改为 value。
- df.loc[布尔值, 列索引] = value :将df的列索引字段中符合条件的的值修改为value
import pandas as pd df_data1 = {"语文": [55, 66], "数学": [31, 43], "英语": [88, 44]} df1 = pd.DataFrame(df_data1, index=["张三", "李四"]) df_data2 = {"语文": [22, 33], "数学": [55, 77], "英语": [88, 44], "化学": [31, 43]} df2 = pd.DataFrame(df_data2, index=["张三", "王五"]) df = df1 + df2 print(df) print("=" * 30) print(df.isnull()) print("=" * 30) print(df.notnull()) print("=" * 30) print(df.fillna(0)) print("=" * 30) print(df.loc[:, "数学":"语文"].dropna())
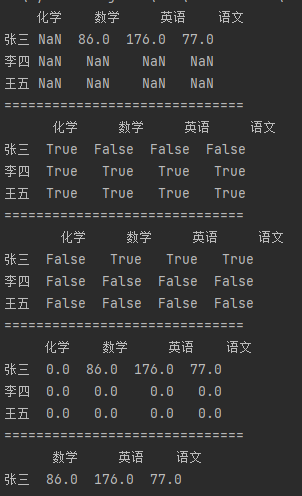
df.loc 修改指定数据
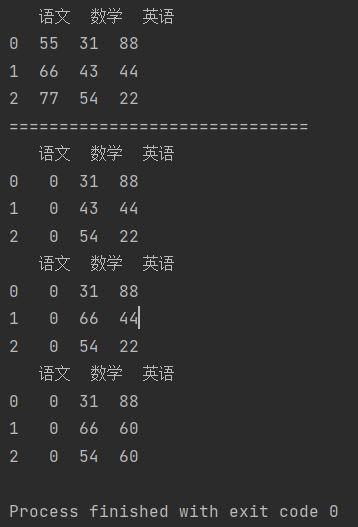
import pandas as pd # 【连接DataFrame 和 Series】 df_data = {"语文": [55, 66, 77], "数学": [31, 43, 54], "英语": [88, 44, 22]} df = pd.DataFrame(df_data) print(df) print("=" * 30) # 修改语文全部成绩为0 df["语文"] = 0 print(df) # 修改第2行的数学成绩 df.loc[1, "数学"] = 66 print(df) # 将英语成绩小于60的改为60 df.loc[df["英语"] < 60, "英语"] = 60 print(df)
四、数据合并
在实际的业务中,需要将多个文档、数据,可能是 Series 或 DataFrame 拼合在一起,进行大数据分析。Pandas 提供的各种功能轻而易举地进行这些工作。
数据的合并分为合并、连接等几种。最简单的是连接,连接相同字段把新的内容追加在后边。合并是把不同的列组合在一起形成多个列。
4.1 pd.contact()
pd.concat() 是专门用于数据连接合并的函数,它可以沿着行或者列进行操作,同时可以指定非合并轴的合并方式(合集、交集等)。
4.1.1 合并多个DataFrame
使用concat可以将两个拥有相同的列索引(与merge相反)的DataFrame合并成一个DataFrame
import pandas as pd df_data1 = {"语文": [55, 66, 77], "数学": [31, 43, 54], "英语": [88, 44, 22]} df1 = pd.DataFrame(df_data1, index=["张三", "李四", "王五"]) print(df1) print("=" * 30) df_data2 = {"语文": [55, 66], "数学": [31, 43], "英语": [88, 44]} df2 = pd.DataFrame(df_data2, index=["赵六", "孙七"]) print(df2) print("=" * 30) # 【连接两个DataFrame】 # 使用concat可以将两个拥有相同的列索引(即:科目所有)的DataFrame合并成一个 m_df = pd.concat([df1, df2]) print(m_df)
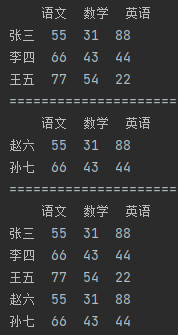
4.1.2 将多个Series合并成DataFrame
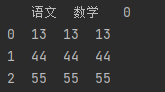
import pandas as pd # 【连接Series】 sr1 = pd.Series([13, 44, 55], name="语文") # name:给Series索引命名 sr2 = pd.Series([13, 44, 55], name="数学") sr3 = pd.Series([13, 44, 55]) # 不指定name值,列索引从0自增 # 连接多个Series,需要指定axis为1或 columns,否则数据错乱 m_df = pd.concat([sr1, sr2, sr3], axis="columns") print(m_df)
4.1.3 合并DataFrame和Series
可以像字典新增值一样将 Series 合并到 DataFrame中
import pandas as pd # 【连接DataFrame 和 Series】 df_data = {"语文": [55, 66, 77], "数学": [31, 43, 54], "英语": [88, 44, 22]} df = pd.DataFrame(df_data) print(df) print("=" * 30) # 也可以像添加字典值的方式将Series 合并到 DataFrame df["化学"] = pd.Series([32, 17, 55]) print(df)
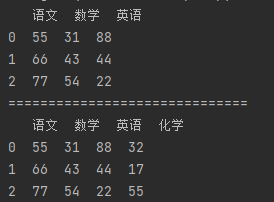
也可以使用concat方法
import pandas as pd # 【连接DataFrame 和 Series】 df_data = {"语文": [55, 66, 77], "数学": [31, 43, 54], "英语": [88, 44, 22]} df = pd.DataFrame(df_data) print(df) print("=" * 30) sr = pd.Series([13, 44, 55], name="物理") # name:给Series索引命名 # DataFrame 合并 Series 需要拥有相同的索引(如果DataFrame自定义了行索引,就无法进行合并),否则合并错乱 m_df = pd.concat([df, sr], axis="columns") print(m_df)
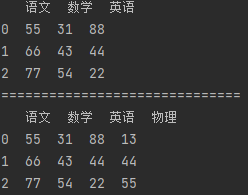
4.2 pd.merge()
Pandas 提供了 merge() 方法,具有全功能、高性能的内存连接操作,与 SQL 等关系数据库非常相似。
参数为:
- how:连接方式,默认为inner,可设为inner/outer/left/right
- on:根据某个字段进行连接,必须存在于两个DateFrame中(若未同时存在,则需要分别使用left_on 和 right_on 来设置)
- left_on:左连接,以DataFrame1中用作连接键的列
- right_on:右连接,以DataFrame2中用作连接键的列
- left_index:bool, default False,将DataFrame1行索引用作连接键
- right_index:bool, default False,将DataFrame2行索引用作连接键
- sort:根据连接键对合并后的数据进行排列,默认为True
- suffixes:对两个数据集中出现的重复列,新数据集中加上后缀 _x, _y 进行区别
4.2.1 索引作为连接键合并表格
通过索引连接两个DataFrame,left_index和right_index都需要指定为True,因为默认为inner连接方式,所以只会拼接索引交集的数据。
import pandas as pd # 【合并多个DataFrame】 df_data1 = {"语文": [55, 66, 77, 33], "数学": [31, 43, 54, 22], "英语": [88, 44, 22, 33]} df1 = pd.DataFrame(df_data1, index=["张三", "李四", "王五", "孙七"]) print(df1) print("=" * 30) df_data2 = {"物理": [55, 66, 12, 33], "化学": [31, 43, 88, 55]} df2 = pd.DataFrame(df_data2, index=["张三", "李四", "王五", "赵六"]) print(df2) print("=" * 30) # 索引作为连接键 m_df = pd.merge(df1, df2, left_index=True, right_index=True) print(m_df) # 这种方式等价于上面,后面不再另外介绍 m_df = df1.merge(df2, left_index=True, right_index=True) print(m_df)
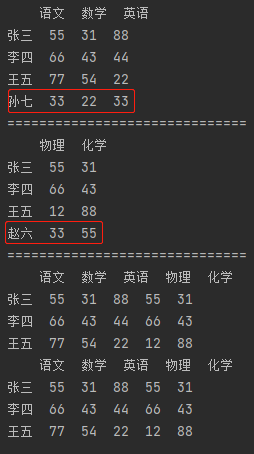
4.2.2 on 指定两个DataFrame中相同名称的字段进行连接
指定两个DataFrame中相同名称的字段进行连接,这个字段必须存在于两个DateFrame中。若字段有重复值,会多次匹配。
import pandas as pd # 【合并多个DataFrame】 df_data1 = {"姓名": ["张三", "李四", "王五", "孙七"], "语文": [55, 66, 77, 33], "数学": [31, 43, 54, 22], "英语": [88, 44, 22, 33]} df1 = pd.DataFrame(df_data1) print(df1) print("=" * 30) df_data2 = {"姓名": ["张三", "李四", "王五", "赵六"], "物理": [55, 66, 12, 33], "化学": [31, 43, 88, 55]} df2 = pd.DataFrame(df_data2) print(df2) print("=" * 30) # on参数指定两个DataFrame同时存在的列索引作为连接键 m_df = pd.merge(df1, df2, on="姓名") print(m_df)
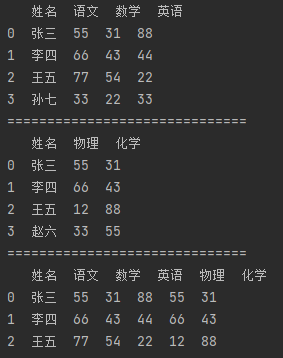
4.2.3 left连接和right连接
左连接是以左边的DataFrame作为连接对象,右边的DataFrame存在相同的数据则拼接,不存在则以NaN占位。
右连接与左连接相反。
import pandas as pd # 【合并多个DataFrame】 df_data1 = {"姓名": ["张三", "李四", "王五", "孙七"], "语文": [55, 66, 77, 33], "数学": [31, 43, 54, 22], "英语": [88, 44, 22, 33]} df1 = pd.DataFrame(df_data1) print(df1) print("=" * 30) df_data2 = {"姓名": ["张三", "李四", "王五", "赵六"], "物理": [55, 66, 12, 33], "化学": [31, 43, 88, 55]} df2 = pd.DataFrame(df_data2) print(df2) print("=" * 30) # 左连接 m_df = pd.merge(df1, df2, on="姓名", how="left") print(m_df)
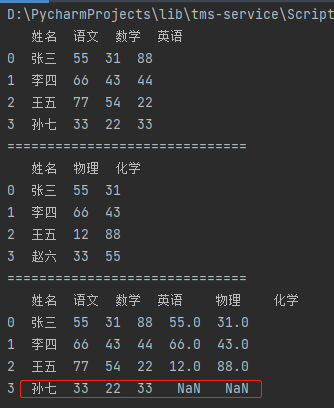
4.2.4 inner连接和outer连接
inner连接会将两个DataFrame的连接键相交部分的数据进行合并
outer连接会将两个DataFrame的连接键进行全合并,不存在的以NaN占位
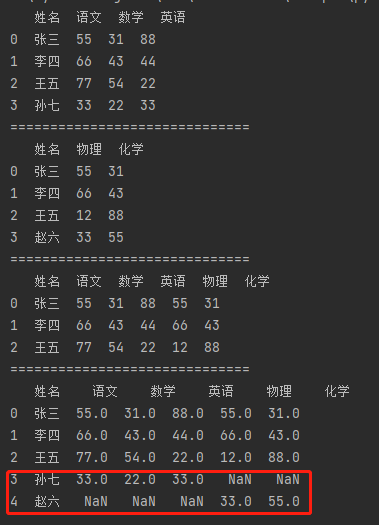
import pandas as pd # 【合并多个DataFrame】 df_data1 = {"姓名": ["张三", "李四", "王五", "孙七"], "语文": [55, 66, 77, 33], "数学": [31, 43, 54, 22], "英语": [88, 44, 22, 33]} df1 = pd.DataFrame(df_data1) print(df1) print("=" * 30) df_data2 = {"姓名": ["张三", "李四", "王五", "赵六"], "物理": [55, 66, 12, 33], "化学": [31, 43, 88, 55]} df2 = pd.DataFrame(df_data2) print(df2) print("=" * 30) # 内连接 m_df = pd.merge(df1, df2, on="姓名", how="inner") print(m_df) print("=" * 30) # 外连接 m_df = pd.merge(df1, df2, on="姓名", how="outer") print(m_df)
append 和 join 效果差不多,可参考 https://www.gairuo.com/p/pandas-append
五、DataFrame常用属性和方法
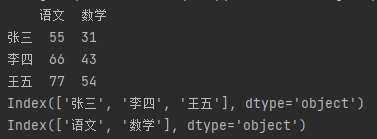
● index 和 columns
- index:获取行索引
- columns:获取列索引
import pandas as pd # 指定数据索引。 df_data = {"语文": [55, 66, 77], "数学": [31, 43, 54]} df = pd.DataFrame(df_data, index=["张三", "李四", "王五"]) print(df) # 获取行索引 print(df.index) # 获取列索引 print(df.columns)
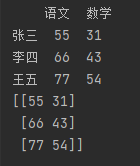
● values 获取值数组
import pandas as pd # 指定数据索引。 df_data = {"语文": [55, 66, 77], "数学": [31, 43, 54]} df = pd.DataFrame(df_data, index=["张三", "李四", "王五"]) print(df) # 获取值数组 print(df.values)
● shape 获取行数和列数
import pandas as pd # 指定数据索引。 df_data = {"语文": [55, 66, 77], "数学": [31, 43, 54]} df = pd.DataFrame(df_data, index=["张三", "李四", "王五"]) print(df) # 获取行数和列数 print(df.shape)
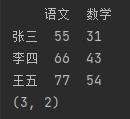
● describe() 获取快速统计
import pandas as pd # 指定数据索引。 df_data = {"语文": [55, 66, 77], "数学": [31, 43, 54]} df = pd.DataFrame(df_data, index=["张三", "李四", "王五"]) print(df) # 获取快速统计 print(df.describe())
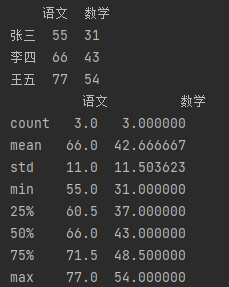
● rename() 修改索引名称
import pandas as pd # 指定数据索引。 df_data = {"语文": [55, 66, 77], "数学": [31, 43, 54]} df = pd.DataFrame(df_data, index=["张三", "李四", "王五"]) print(df) # 修改索引名称 df = df.rename(index={"李四": "李四改"}, columns={"语文": "语文改", "数学": "数学改"}) print(df)

● filter() 根据索引标签对数据框行或列查询子集
需要注意的是,此方法不会对数据帧的数据内容进行过滤,仅应用于按标签筛选
import pandas as pd # 指定数据索引。 df_data = {"语文": [55, 66, 77], "数学": [31, 43, 54], "英语": [22, 33, 44], "物理": [22, 66, 33]} df = pd.DataFrame(df_data, index=["张三", "李四", "王五"]) print(df) # 根据索引标签精准过滤 print(df.filter(items=["语文", "数学"])) # 默认过滤列索引,通过指定 axis 参数的值为 index可修改过滤维度为行索引 print(df.filter(items=["张三", "王五"], axis="index")) # 可通过like 或 regex参数进行模糊匹配索引 print(df.filter(like="语")) print(df.filter(regex="语")) # regex参数还可输入正则 print(df.filter(regex=".语"))
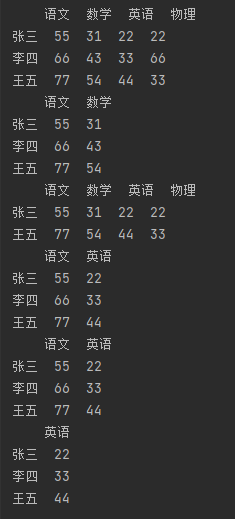
● groupby() 分组统计
df.groupby() 方法可以按指定字段对 DataFrame 进行分组,生成一个分组器对象,然后再把这个对象的各个字段按一定的聚合方法输出。
参数说明:
- by,分组字段,可以是列名/series/字典/函数,常用为列名
- axis,指定切分方向,默认为0,表示沿着行切分
- as_index,是否将分组列名作为输出的索引,默认为True;当设置为False时相当于加了reset_index功能
- sort,与SQL中groupby操作会默认执行排序一致,该groupby也可通过sort参数指定是否对输出结果按索引排序
df.groupby('team').describe() # 描述性统计 df.groupby('team').sum() # 求和 df.groupby('team').count() # 每组数量,不包括缺失值 df.groupby('team').max() # 求最大值 df.groupby('team').min() # 求最小值 df.groupby('team').size() # 分组数量 df.groupby('team').mean() # 平均值 df.groupby('team').median() # 中位数 df.groupby('team').std() # 标准差 df.groupby('team').var() # 方差
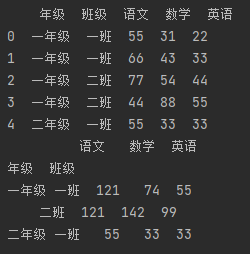
多层级分组
by参数可传入list类型,用于多层级分组
import pandas as pd df_data = { "年级": ["一年级", "一年级", "一年级", "一年级", "二年级"], "班级": ["一班", "一班", "二班", "二班", "一班"], "语文": [55, 66, 77, 44, 55], "数学": [31, 43, 54, 88, 33], "英语": [22, 33, 44, 55, 33], } df = pd.DataFrame(df_data) print(df) # 需求:求每个年级、每个班级的各科的总和 print(df.groupby(["年级", "班级"]).sum())
六、excel文件读取与导出
假如在test.xlsx文件中有如下两个sheet页
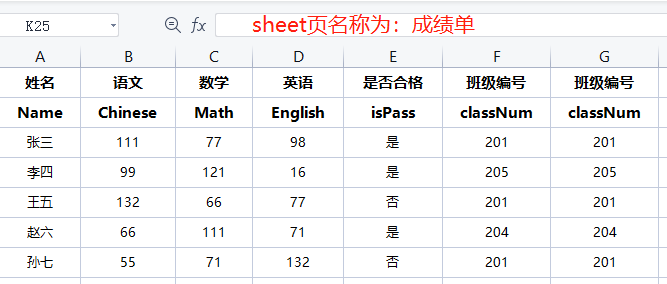
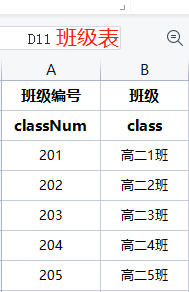
● 读取文件
使用 pd.read_excel(excel文件) 方法读取文件,默认读取第1个sheet页,可以使用sheet_name参数指定读取的sheet页。
文件读取成功后,会将首行作为列索引,可以使用 header参数指定开始解析的行,从0开始。
当sheet页存在多个相同名称字段时,df会给重复的索引自动添加尾缀 “,数字”
import pandas as pd # sheet_name:excel的sheet页名称 # header:开始解析的行数,从0开始 df_cjd = pd.read_excel("test.xlsx", sheet_name="成绩单", header=1) print(df_cjd)
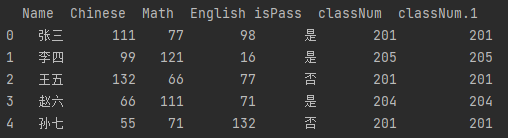
● 导出文件
import pandas as pd df_data = {"语文": [55, 66, 77], "数学": [31, 43, 54], "英语": [22, 33, 44], "物理": [22, 66, 33]} df = pd.DataFrame(df_data, index=["张三", "李四", "王五"]) # 将DataFrame数据导出为excel文件 # ./test/demo.xlsx 指定导出的路径为 ./test/ 导出名称为 demo.xlsx 注:路径必须存在,否则报错 # sheet_name指定导出sheet的名称,默认为Sheet1 # index 导出的内容是否包含行索引,默认True export_path = './test/demo.xlsx' with pd.ExcelWriter(export_path) as writer: df.to_excel(writer, sheet_name='demo_sheet', index=False)
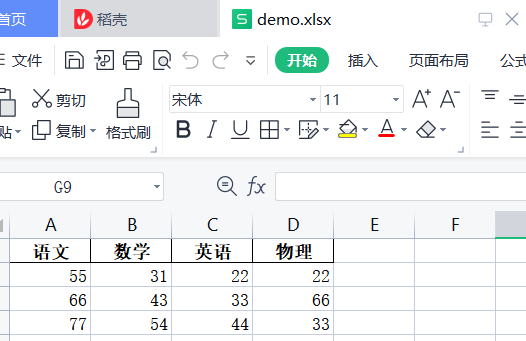
● 联表
将上面两个表以classNum进行联表。
import pandas as pd df_cjd = pd.read_excel("test.xlsx", sheet_name="成绩单", header=1) df_bjb = pd.read_excel("test.xlsx", sheet_name="班级表", header=1) df = pd.merge(df_cjd, df_bjb, how="left", on="classNum") print(df)
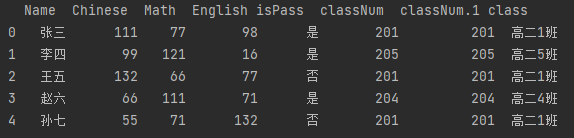
● 根据条件过滤数据
import pandas as pd df_cjd = pd.read_excel("test.xlsx", sheet_name="成绩单", header=1) df_bjb = pd.read_excel("test.xlsx", sheet_name="班级表", header=1) df = pd.merge(df_cjd, df_bjb, on="classNum") # 提取 isPass 值为'是'的行 df_pass = df[df["isPass"].isin(["是"])] print(df_pass)

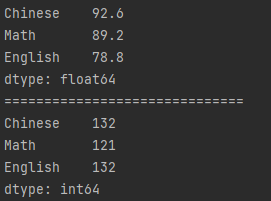
● 列维度:计算每科的平均值和最大值
import pandas as pd df_cjd = pd.read_excel("test.xlsx", sheet_name="成绩单", header=1) df_bjb = pd.read_excel("test.xlsx", sheet_name="班级表", header=1) df = pd.merge(df_cjd, df_bjb, how="left", on="classNum")[["Chinese", "Math", "English"]] # 列维度 df_avg = df.mean(numeric_only=True) df_max = df.max(numeric_only=True) print(df_avg) print("=" * 30) print(df_max)
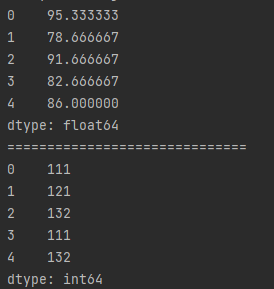
● 行维度:计算每人的平均值和最大值
import pandas as pd df_cjd = pd.read_excel("test.xlsx", sheet_name="成绩单", header=1) df_bjb = pd.read_excel("test.xlsx", sheet_name="班级表", header=1) df = pd.merge(df_cjd, df_bjb, how="left", on="classNum")[["Chinese", "Math", "English"]] # 行维度 df_avg = df.mean(numeric_only=True, axis=1) df_max = df.max(numeric_only=True, axis="columns") print(df_avg) print("=" * 30) print(df_max)
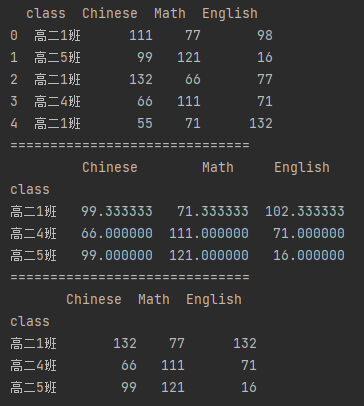
● 分组维度:计算每个班每科的平均值和最大值
import pandas as pd df_cjd = pd.read_excel("test.xlsx", sheet_name="成绩单", header=1) df_bjb = pd.read_excel("test.xlsx", sheet_name="班级表", header=1) df = pd.merge(df_cjd, df_bjb, how="left", on="classNum")[["class", "Chinese", "Math", "English"]] print(df) print("=" * 30) # 分组 df_group_avg = df.groupby("class").mean(numeric_only=True) df_group_max = df.groupby("class").max(numeric_only=True) print(df_group_avg) print("=" * 30) print(df_group_max)
七、设置数据显示格式
常用的参数项如下:
| 参数 | 说明 |
|---|---|
| display.max_rows | 最大显示行数,超过该值用省略号代替,为None时显示所有行。 |
| display.max_columns | 最大显示列数,超过该值用省略号代替,为None时显示所有列。 |
| display.expand_frame_repr | 输出数据宽度超过设置宽度时,表示是否对其要折叠,False不折叠,True要折叠。 |
| display.max_colwidth | 单列数据宽度,以字符个数计算,超过时用省略号表示。 |
| display.precision | 设置输出数据的小数点位数。 |
| display.width | 数据显示区域的宽度,以总字符数计算。 |
| display.show_dimensions | 当数据量大需要以truncate(带引号的省略方式)显示时,该参数表示是否在最后显示数据的维数,默认 True 显示,False 不显示。 |
设置方式
import pandas # 当列非常多的时候,pandas会自作进行自动换行,可以通过以下设定来设置不换行 pandas.set_option('display.width', 1000)
八、简单封装
import pandas as pd from testdrglib.helper.helper import handle_round class PdLib: @classmethod def handle_data_frame(cls, data_frame, columns=None, renames=None): """ :param data_frame:需要处理的DataFrame数据 :param columns:指定读取sheet的字段,默认全部。类型为list :param renames:修改sheet字段的名称,类型为dict,key为sheet字段名称,value为新名称 """ # 过滤空字段 data_frame = data_frame.loc[:, ~ data_frame.columns.str.contains("Unnamed")] # 获取指定字段数据 if columns: data_frame = data_frame[list(columns)] # 重命名字段 if renames: data_frame = data_frame.rename(columns=renames) return data_frame @classmethod def merge(cls, data_frames, left_on=None, right_on=None, left_index=False, right_index=False): m_df = None for df in data_frames: if m_df is None: m_df = df continue m_df = pd.merge( m_df, df, left_on=left_on, right_on=right_on, left_index=left_index, right_index=right_index, how="left" ) return m_df @classmethod def get_col_name(cls, data_frame): """获取列名""" return data_frame.columns @classmethod def get_col_data(cls, data_frame, column_name): """获取某列值, :param data_frame:pandas的DataFrame格式数据 :param column_name 列名。比如 drg_code """ return data_frame.get(column_name) @classmethod def query_col_is_list(cls, data_frame, col, value): """查询某列值为xxx的数据 (查询列表为A,值为abc的所有值) :param data_frame:pandas的DataFrame格式数据 :param col: 列名 :param value: value值 """ return data_frame[data_frame[col] == value] @classmethod def query_col_contain(cls, data_frame, col, value): """查询某列值包含xxx的数据 :param data_frame:pandas的DataFrame格式数据 :param col: 列名 :param value: value值 """ # 当输入值为None时,获取字段中的空值 if value is None: return data_frame[data_frame[col].isnull()] if isinstance(value, (float, int)): return data_frame[data_frame[col] == value] return data_frame[data_frame[col].str.contains(value)] @classmethod def query_col_not_contain(cls, data_frame, col, value): """查询某列值不包含xxx的数据 :param data_frame:pandas的DataFrame格式数据 :param col: 列名 :param value: value值 """ # 当输入值为None时,获取字段中的非空值 if value is None: return data_frame[data_frame[col].notnull()] return data_frame[~ data_frame[col].str.contains(value)] @classmethod def format_data(cls, data_frame, key_col, data_type="dict"): """将数据转化为字段格式的数据 :param data_frame:pandas的DataFrame格式数据 :param key_col: 列值,转为key :param data_type: str {'dict', 'list', 'series', 'split', 'records', 'index'} :return: { 1: {'Course': 'BBA', 'Age': 16, 'Name': 'Jay'}, 4: {'Course': 'BSc', 'Age': 18, 'Name': 'Mark'} ... } """ return data_frame.set_index(key_col).T.to_dict(data_type) @classmethod def df_format_dict(cls, data_frame, key_col=None, value_col=None, round_num=None): """将df数据的某个字段以行索引为key,指定其中一个字段为value,转化为字典格式的数据 :param data_frame:pandas的DataFrame格式数据 :param key_col: 转为key的列值,若为None,则为行索引 :param value_col: 转为value的列值,若为None,则为行索引 :param round_num: 对value的多少位进行四舍五入,若为None,则不进行四舍五入 """ k = data_frame.index if key_col is not None: k = data_frame[key_col] v = data_frame.index if value_col is not None: v = data_frame[value_col] if round_num is not None: v = [handle_round(i, round_num) for i in v] return dict(zip(k, v)) @classmethod def sr_format_dict(cls, series_data, round_num=None): """将sr数据的行索引为key,值为value,转化为字典格式的数据 :param series_data:pandas的Series格式数据 :param round_num: 对value的多少位进行四舍五入,若为None,则不进行四舍五入 """ k = series_data.index v = list(series_data) if round_num is not None: v = [handle_round(i, round_num) for i in v] return dict(zip(k, v)) @classmethod def df_format_two_field_to_dict(cls, data_frame, col_key, col_value): """将df数据中的2个字段转化为字典格式的数据 :param data_frame:data_frame数据源 :param col_key: df数据中的某个字段作为key :param col_value: df数据中的某个字段作为value """ sr_keys = data_frame[col_key] sr_values = data_frame[col_value] return dict(zip(sr_keys, sr_values))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号