Python_文件的读写操作
python对文件的操作通过open()函数来实现,文件操作有两种模式:读、写
一、读
通过对open()函数的mode参数传入"r"值可打开文件,然后使用读的方法读取文件内容,一般有开就有关,所以还需要用close()方法关闭文件,避免产生内存溢出的问题。另外,若读取的文件不存在,则会抛错。
例:读取当前目录下的test.txt文件,该文件如下所示。
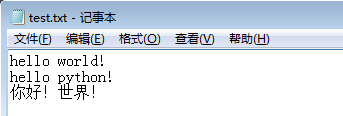
代码实现:
f = open("./test.txt", "r") print(f.read()) f.close()
执行结果:

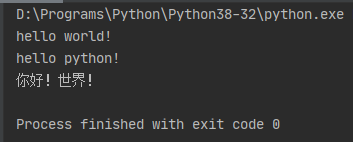
从上图看出,读取的内容,中文显示乱码 ,可以在读取文件时增加参数encoding=“utf-8”解决该问题
f = open("./test.txt", "r", encoding="utf-8") print(f.read()) f.close()
执行结果:
读的方法
上面例子中使用了read()方法读取文件,除此之外,还有readline()和readlines()这两种方法。下面依次讲解每种读法的不同之处。
read()
该方法是读文件最常用的方法,特点是,使用该方法默认情况下是将文件中的所有内容一次性全部读取出来,比如上面的示例,但是也可以读取指定字节的内容。
f = open("./test.txt", "r", encoding="utf-8") # 只读取前面5个字节 print(f.read(5)) f.close()
执行结果:
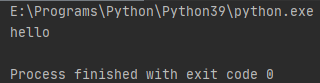
readline()
该方法是将文件内容一行一行读取,特点是,执行一次读取一行,如果要读取完文件,就要执行多次。
f = open("./test.txt", "r", encoding="utf-8") i = 1 while True: content = f.readline() if not content: break print(f"第{i}次读:{content}") i += 1 f.close()
执行结果:
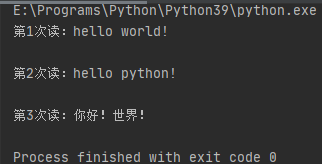
readlines()
该方法也是将文件内容一行一行读取,特点是,一次性读取所有内容,并将每行的数据保存在一个列表。
f = open("./test.txt", "r", encoding="utf-8") print(f.readlines()) f.close()
执行结果:

处理换行符\n
使用 readlines() 方法读取的内容会有换行符\n,极不方便我们对数据的处理。处理换行符的方法多种多样,下面介绍一种最简单的方法,使用字符串的内置方法 splitlines() ,该方法是将字符串以\n为分隔符进行切割。
t = "AAAA\nBBB\nCCC" print(t.splitlines()) f = open("./test.txt", "r", encoding="utf-8") print(f.read().splitlines()) f.close()
输出结果

综上,python读取文件的操作最常用的方法只需要记住read()方法就可以了。
二、写
与读方法类似,不同的是mode参数传入的值不同,需要传入“w”或”a“ 看到这里,有些读者可能会想,写为什么可传入两种写模式?因为读的操作只有一种场景,但写的场景却有覆盖写和追加写两种场景。
1、覆盖写:w
覆盖写的特点
- 会清空原文件内容
- 当文件不存在时,会新增文件
如下,写入‘你好,世界!’时,将原来的内容都清空。
f = open("test.txt", "w") f.write("你好,世界!") f.flush() f.close()
执行代码后的文件内容如下:

f.flush():有时我们用f.write()后,会发现没有写入文件,这是因为内容存在了缓冲区,需要等缓冲区满了之后,再把所有数据写入。此时可以用f.flush()强制把缓冲区里面的数据写到磁盘上。
2、追加写: a
追加模式a特点:
- 即在原内容末尾添加新内容
- 当文件不存在时,创建新文件
f = open("test.txt", "a") f.write("你好,python!") f.flush() f.close()
将‘你好,python’添加到原内容的末尾

除了以上r,w,a三种模式外,还有一种读写模式,在上面三种中模式中,任意一种模式后面增加+即为读写模式,读写模式很少用,仅供了解,下表为各种模式的总结:
| 读写模式 | 是否可读 | 是否可写 | 文件不存在时 |
| r | 是 | 否 | 报错 |
| r+ | 是 | 是,覆盖写 | 报错 |
| w | 否 | 是,覆盖写 | 创建新文件 |
| w+ | 是 | 是,覆盖写 | 创建新文件 |
| a | 否 | 是,追加写 | 创建新文件 |
| a+ | 是 | 是,追加写 | 创建新文件 |
三、文件指针
文件指针用来记录文件走到哪里。
文件指针是很重要的,我们看下面的例子中,read将test.txt的内容全部读了出来,readline则没有读出任何内容。原因是read读完之后,文件指针到了文件的末尾,此时readline接着从这个位置开始读,肯定是没内容的。因此有时需要调整文件指针的位置。
f = open("test.txt") print("read读的:", f.read()) # 已经读到最后一行 print("readline读的:", f.readline()) # 指针连着上一个操作,从最后一行读,所以没内容 f.close()
输出结果:
read读的: 你好,世界!
你好,pathon!
readline读的:
seek可以移动文件指针,移动后只是针对读,用追加模式写的时候,还是在末尾写。
另外,seek(num),这个num指的是字符,不是行。注:中文占两个字符!
在上面的代码中,加一句f.seek(0),即可将指针移到文件开头。这次,readline就可以从头开始读了。
f = open("test.txt") print("read读的:", f.read()) # 已经读到最后一行 f.seek(2) # 中文占两个字符,若输入1则会报错 print("readline读的:", f.readline()) # 指针连着上一个操作,从最后一行读,所以没内容 f.close()
输出结果:
read读的: 你好,世界!
你好,pathon!
readline读的: 好,世界!
四、使用with打开文件
with 语句是 Pyhton 提供的一种简化语法,通过 with 语句在编写代码时,会使代码变得更加简洁,不用再去关闭文件。
with open('test.txt', 'a', encoding="utf-8") as f: f.writelines('\n三体')
上面的代码等效于
f = open("./test.txt", "w+", encoding="utf-8") f.write("aaa") f.close()
五、文件修改
1、简单粗暴直接修改
最简单粗暴的修改文件,步骤是:
(1)打开文件,获取文件内容;
(2)对内容进行修改;
(3)清空原来文件的内容;
(4)把新的内容写进去。
这种方法很简单,下面看一个小例子----文件username里存放了姓名和密码,如下图格式。我们要在所有姓名前加上‘A班_’

因为'A班_'中含有中文,需要叫上encoding='utf-8',否则会出现乱码。


2、备份文件的方法
当文件很大时,刚刚的方法在一次性读取文件内容和写入新内容时,耗时长,占用磁盘空间也较大。
备份文件的方法是建立一个备份文件,读一点,改一点,写一点,具体步骤如下:
(1)打开2个文件,原文件a和备份文件b。如a.txt b.txt.bak
(2)删除a文件,将b文件名改为a文件名
例:将文件words里的“花”改成“flower”



 浙公网安备 33010602011771号
浙公网安备 33010602011771号