测开学习一阶段(2)编程思维训练---爬虫小案例
- 学习目的:散代码→面向过程→面向对象,学习各阶段的设计思路,实现步骤
- 1.基础版本
流程:
1.访问url
2.转换格式,抓取数据
3.格式化输出,保存到本地文件
import requests from lxml import etree url = 'http://www.51testing.com/html/90/category-catid-90.html' # 访问url rsp = requests.get(url) # 进行页面字符集转换 cod = rsp.apparent_encoding rsp.encoding = 'gbk' content = rsp.text # 将页面信息转为dom格式 doc = etree.HTML(content) # 查看返回结果 #print(content)
# 新建文件 file = open('data.txt','w') for j in range(2,5): print(j - 1) file.write(r'第{}页'.format(j-1)+'\n') # 提取数据 for i in range(1,11): ele = doc.xpath('/html/body/div[2]/div[3]/div[2]/div['+str(i)+']/div/p/text()')[0] print("第:{} 行--{}".format(i, ele)) # ele里面存在不可识别的字符,防止写入文件时报错,需要进行处理 new_ele = ''.join(ele.split()) file.write(r"第:{} 行{}".format(i, new_ele)+'\n'+'\n') # 获取第二页 url = 'http://www.51testing.com/html/90/category-catid-90-page-'+str(j)+'.html' rsp = requests.get(url) cod = rsp.apparent_encoding rsp.encoding = 'gbk' content = rsp.text doc = etree.HTML(content)
爬取效果:

- 2.面向过程封装设计
- 思路:独立模块,模块之间,整体
- 独立模块:输入,处理,输出
- 模块之间:返回值,传参
- 整体:模块间的调用顺序
- 思路:独立模块,模块之间,整体
- 版本优化操作
- 独立模块设计:
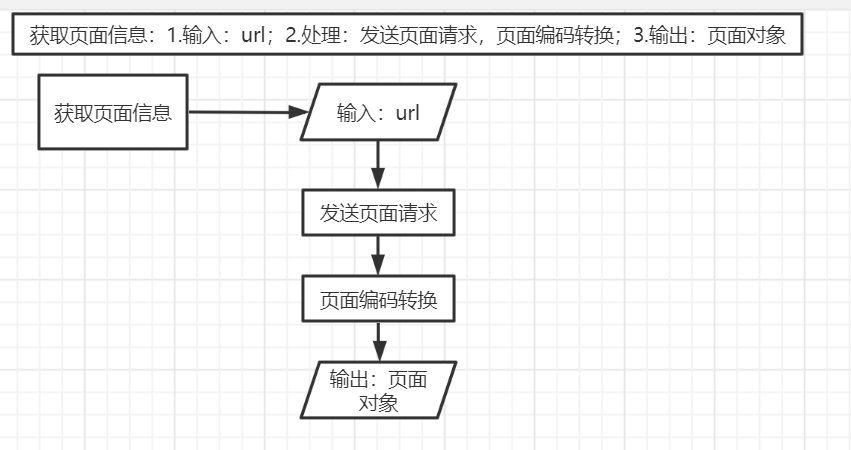
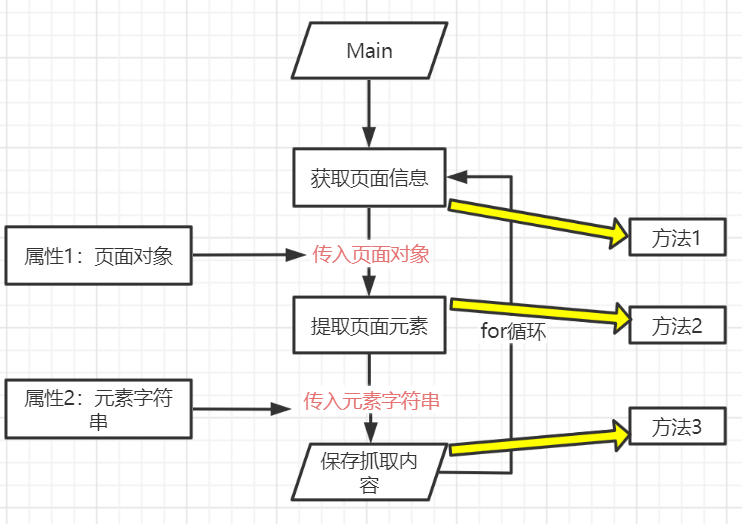
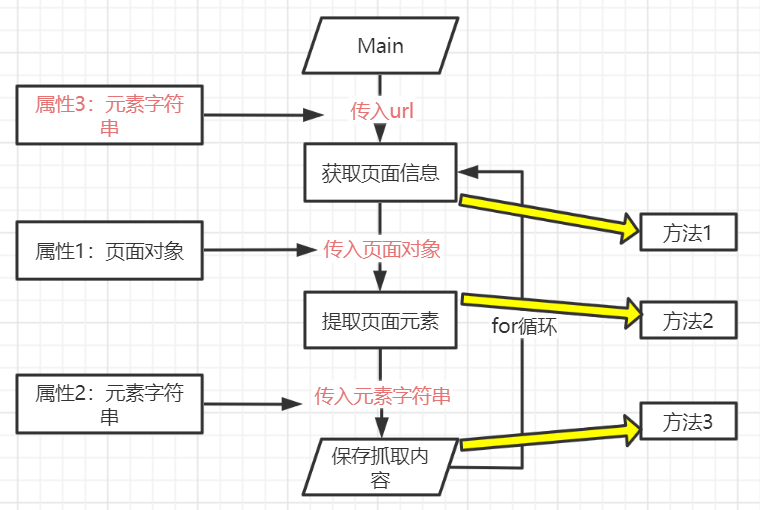
- 获取页面信息:1.输入:url;2.处理:发送页面请求,页面编码转换;3.输出:页面对象
- 提取页面元素:1.输入:页面对象;2.处理:转化为dom格式,通过xpath元素定位;3.输出:元素内容列表
- 保存抓取内容:1.输入:元素内容列表;2.处理:创建一个文件,写入元素内容,保存并关闭文件;3.输出:抓取文件
- 其他模块:待定...
- 分版本实践:
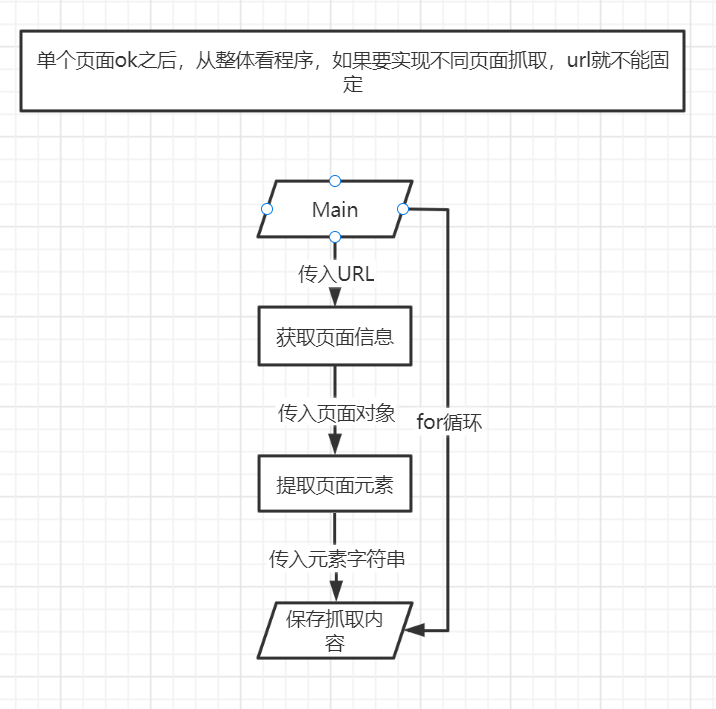
- v1.0单个页面抓取:传入固定url,提取一个页面元素,进行元素保存
- 流程图:
![]()
-
#********************************************** # 使用面向过程思想对爬虫代码进行封装 # V1.0:实现一个页面的元素抓取 # 一共设计3个方法 #********************************************* import requests from lxml import etree #******************获取页面信息****************** def get_page(): # 输入url url = 'http://www.51testing.com/html/90/category-catid-90.html' # 发送请求 rsp = requests.get(url) # 页面编码转化 cod = rsp.apparent_encoding rsp.encoding = 'gbk' # 输出:页面对象 #print(rsp.text) return rsp.text #******************提取页面元素****************** def get_element(content): # 输入:页面对象,传入get_page的返回值 # 定义列表,存储元素内容 #listcont = [] tmp = '' # 转化为dom格式 doc = etree.HTML(content) # 循环提取页面元素 for i in range(1,11): # 通过xpath元素定位 ele = doc.xpath('/html/body/div[2]/div[3]/div[2]/div['+str(i)+']/div/p/text()')[0] # ele里面存着不可识别的字符,防止写入文件时报错,需要进行处理 new_ele = ''.join(ele.split()) # 打印输出元素 #print("第:{} 行--{}".format(i, new_ele)) # 输出:元素内容列表 tmp = tmp+str(i)+new_ele+'\n'+'\n' #print(listcont) return tmp #******************保存抓取内容****************** def save_element(tmpcontent): # 1.输入:元素内容列表; # 创建一个文件, file = open('spider.txt', 'a') # 写入元素内容 file.write(tmpcontent) # 保存并关闭文件 file.close() if __name__ == '__main__': listc = [] content = get_page() listc = get_element(content) save_element(listc)
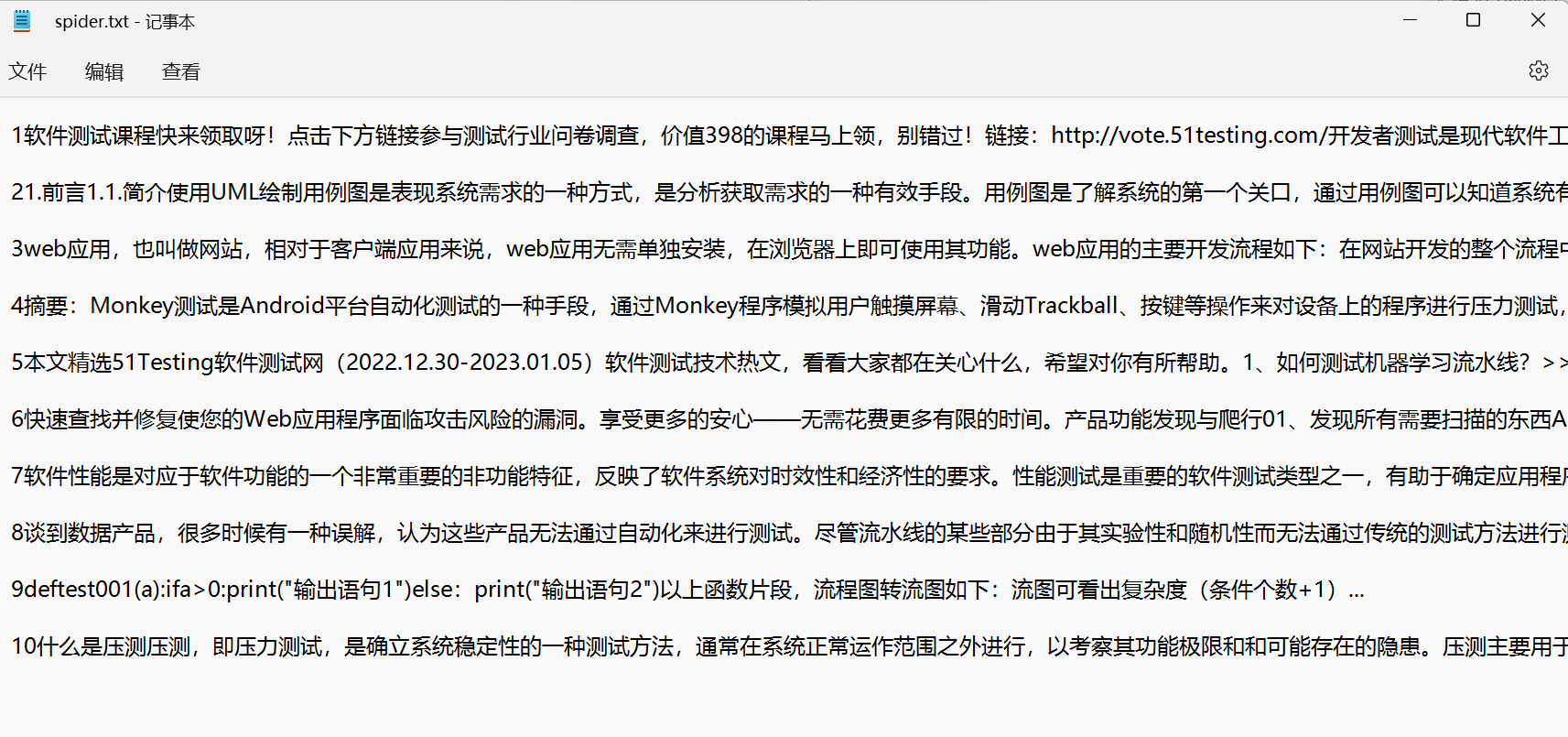
- 抓取效果
![]()
- v2.0多个页面抓取:由主程序传入url
- 流程图:
![]()
-
#******************获取页面信息****************** def get_page(url): # 发送请求 rsp = requests.get(url) # 页面编码转化 cod = rsp.apparent_encoding rsp.encoding = 'gbk' # 输出:页面对象 #print(rsp.text) return rsp.text #********************************************** # 中间代码不变........ if __name__ == '__main__': #url = 'http://www.51testing.com/html/90/category-catid-90.html' #url = 'http://www.51testing.com/html/90/category-catid-90-page-2.html' for i in range(1,6): # 如果首页 if i == 1: url = 'http://www.51testing.com/html/90/category-catid-90.html' else: url = 'http://www.51testing.com/html/90/category-catid-90-page-'+str(i)+'.html' content = get_page(url) strcont = get_element(content) save_element(strcont)
- 流程图:
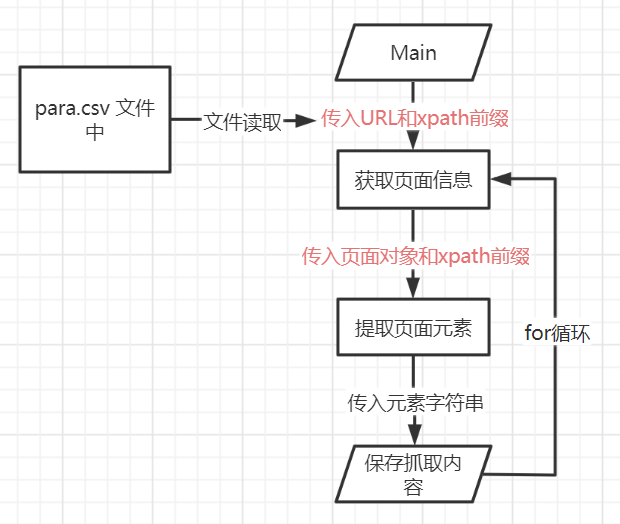
- v3.0灵活页面抓取
- 流程图:
![]()
- v1.0单个页面抓取:传入固定url,提取一个页面元素,进行元素保存
- 独立模块设计:
- 3.面向对象封装设计
- 思路:属性设计,方法设计,类设计
- 属性设计:方法之间传递参数
- 方法设计:与面向过程的方法直接对应
- 类设计:把属性和方法封装到类中
- 思路:属性设计,方法设计,类设计
- 版本优化操作
- 分版本实践:
- v1.0单个页面抓取:1.分析要设置的属性;2.保留之前的方法;3.把方法和属性封装到类中;
- 流程图:
![]()
-
代码:在面向过程v1.0版本上,新建了爬虫类,设置了两个属性 -
#********************************************** # 使用面向对象思想对爬虫代码进行封装 # V1.0:实现一个页面的元素抓取 # 一共设计3个方法,两个属性 #********************************************* import requests from lxml import etree # 定义爬虫类 class spider_v1(): #******************获取页面信息****************** def get_page(self): # 输入url url = 'http://www.51testing.com/html/90/category-catid-90.html' # 发送请求 rsp = requests.get(url) # 页面编码转化 cod = rsp.apparent_encoding rsp.encoding = 'gbk' # 输出:页面对象 # 设置属性1(在哪里产生就在哪里定义) self.content = rsp.text #print(self.content) #********************************************** #******************提取页面元素****************** def get_element(self): #原来面向过程接收content参数就不需要了,使用时,直接self.content # 输入:页面对象,传入get_page的返回值 # 定义列表,存储元素内容 #listcont = [] tmp = '' # 转化为dom格式 doc = etree.HTML(self.content) # 这里需要使用get_page产生的属性self.content # 循环提取页面元素 for i in range(1,11): # 通过xpath元素定位 ele = doc.xpath('/html/body/div[2]/div[3]/div[2]/div['+str(i)+']/div/p/text()')[0] # ele里面存着不可识别的字符,防止写入文件时报错,需要进行处理 new_ele = ''.join(ele.split()) # 打印输出元素 #print("第:{} 行--{}".format(i, new_ele)) # 输出:元素内容列表 tmp = tmp+str(i)+new_ele+'\n'+'\n' # 设置属性2 self.tmpcontent = tmp #print(self.tmpcontent) #******************保存抓取内容****************** def save_element(self): # 1.输入:元素内容列表; # 创建一个文件, file = open('spider.txt', 'a') # 写入元素内容 file.write("{}".format(self.tmpcontent)+'\n') # 保存并关闭文件 file.close() if __name__ == '__main__': # 实例化 obj = spider_v1() # 调用获取页面信息方法 obj.get_page() # 调用提取页面元素方法 obj.get_element() # 调用保存抓取内容方法 obj.save_element()
- v2.0单个页面抓取:需要设置属性3
- 流程图
![]()
-
代码: -
#********************************************** # 使用面对象程思想对爬虫代码进行封装 # V2.0:实现多个页面的元素抓取 # 一共设计3个方法,3个属性 #********************************************* import requests from lxml import etree # 定义爬虫类 class spider_v2(): # url在main中传入的,需要在类的初始化方法中设置 def __init__(self,i): if i == 1: self.url = 'http://www.51testing.com/html/90/category-catid-90.html' else: self.url = 'http://www.51testing.com/html/90/category-catid-90-page-'+str(i)+'.html' #******************获取页面信息****************** def get_page(self): # 发送请求 rsp = requests.get(self.url) # 页面编码转化 cod = rsp.apparent_encoding rsp.encoding = 'gbk' # 输出:页面对象 # 设置属性1(在哪里产生就在哪里定义) self.content = rsp.text print(self.content) #********************************************** #******************提取页面元素****************** def get_element(self): # 输入:页面对象,传入get_page的返回值 # 定义列表,存储元素内容 #listcont = [] tmp = '' # 转化为dom格式 doc = etree.HTML(self.content) # 循环提取页面元素 for i in range(1,11): # 通过xpath元素定位 ele = doc.xpath('/html/body/div[2]/div[3]/div[2]/div['+str(i)+']/div/p/text()')[0] # ele里面存着不可识别的字符,防止写入文件时报错,需要进行处理 new_ele = ''.join(ele.split()) # 打印输出元素 #print("第:{} 行--{}".format(i, new_ele)) # 输出:元素内容列表 tmp = tmp+str(i)+' '+new_ele+'\n'+'\n' # 设置属性2 self.tmpcontent = tmp print(self.tmpcontent) #******************保存抓取内容****************** def save_element(self): # 1.输入:元素内容列表; # 创建一个文件, file = open('spider.txt', 'a') # 写入元素内容 file.write(self.tmpcontent) # 保存并关闭文件 file.close() if __name__ == '__main__': for i in range(1,6): obj = spider_v2(i) obj.get_page() obj.get_element() obj.save_element()
- 分版本实践:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号