

HTTP概述
浏览器、服务器和相关的应用程序都是通过HTTP相互通信的。HTTP是现代全球因特网中使用的公共语言
HTTP(超文本传输协议)是一个基于请求与响应模式的,无状态的,应用层的
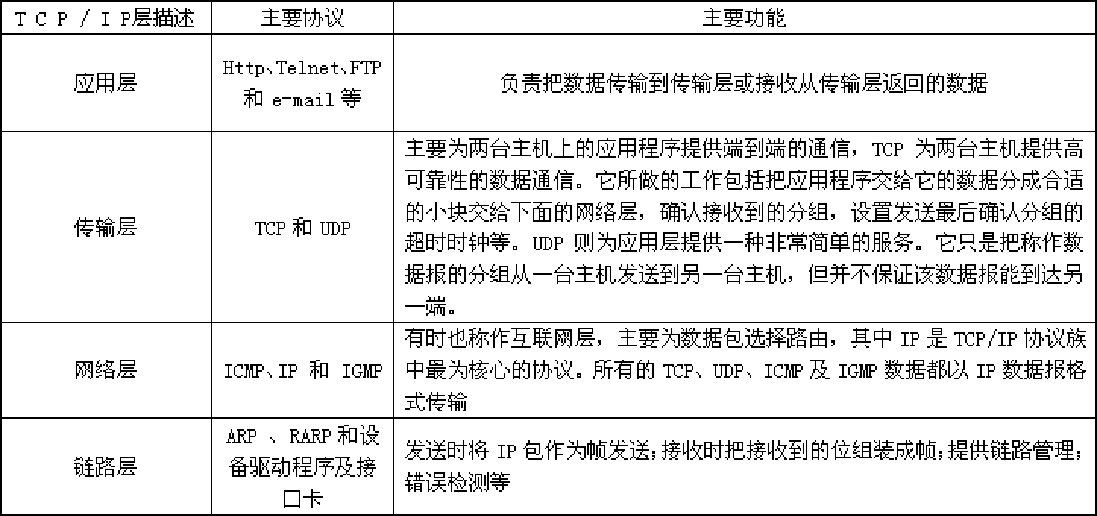
数据资源都是存储在服务器上的,客户端发出请求,服务器会提供数据,客户端向服务器发送HTTP请求,服务器会在HTTP响应中回送所请求的数据
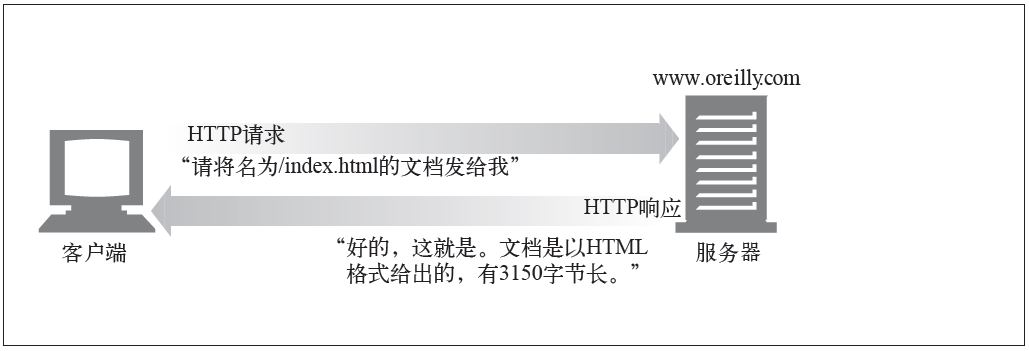
客户端向服务端发起请求后,服务端响应你的请求:
a.答应你的请求
b.拒绝你的请求
c.没有响应
无状态是没有记忆功能,无存储功能,每一个请求都是单独的
URL:统一资源定位符(URL)用于描述一台特定服务器上某资源的特定位置,其明确地说明如何从一个精确固定的位置获取资源
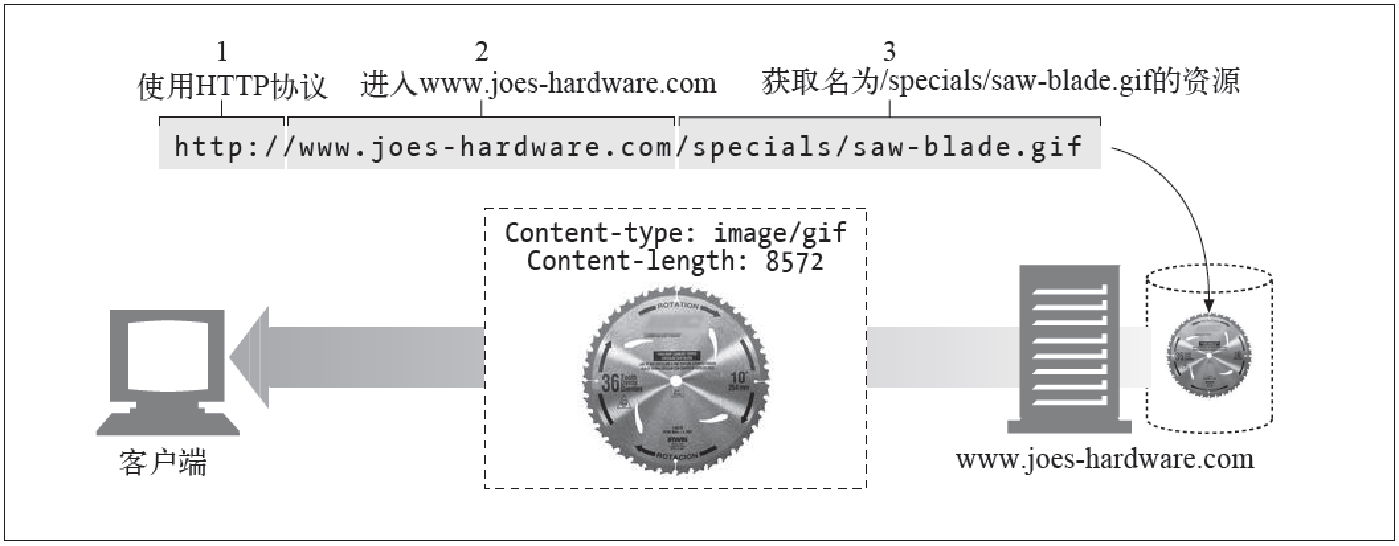
大部分URL都遵循一种标准格式,这种格式包含三个部分:
- URL的第一部分被称为方案,说明了访问资源所使用的协议类型,这部分通常就是HTTP协议(http://)
- 第二部分给出了服务器的因特网地址,比如:www.baidu.com
- 其余部分指定了服务器上的某个资源,比如:/specialssaw-blade.gif
请求方法:HTTP支持几种不同的请求命令,这些命令被称为HTTP方法。
每条HTTP请求报文都包含一个方法,这个方法会告诉服务器要执行什么动作,比如:获取一个Web页面、运行一个网关程序、删除一个文件等
下面是五种常见的HTTP方法:
- GET:请求指定的页面信息,并返回实体主体
- POST:向指定资源提交数据进行处理请求。例如:提交表单或者上传文件。数据被包含在请求体中。POST请求可能会导致新的资源的建立或已有资源的修改
- PUT:从客户端向服务器传送的数据,取代指定的文档的内容
- DELETE:请求服务器删除指定页面
- HEAD:类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头
状态码:每条HTTP响应报文返回时都会携带一个状态码。状态码是一个三位数字的代码,告知客户端请求是否成功,或者是否需要采取其它工作。
伴随着每个数字状态码,HTTP还会发送一条解释性的“原因短语”文本。包含文本短语主要是为了进行描述,所有的处理过程使用的都是数字码
状态码的5种类别:
- 1xx:指示信息 – 表示请求已接收,继续处理
- 2xx:成功 – 表示请求已被成功接收、理解、接受
- 3xx:重定向 – 要完成请求必须进行更进一步的操作
- 4xx:客户端错误 – 请求有语法错误或请求无法实现
- 5xx:服务器错误 – 服务器未能实现合法的请求
常见状态码:
-
200 OK // 客户端请求成功
-
400 BadRequest // 客户端请求有语法错误,不能被服务器所理解
-
401 Unauthorized // 请求未经授权,这个状态码必须和www-Authenticate报头域一起使用
-
403 Forbidden // 服务器收到请求,但是拒绝提供服务
-
404 NotFound // 请求资源不存在,或输入了错误的URL
-
500 InternalServerError // 服务器发生不可预期的错误
-
503 ServerUnavailable // 服务器当前不能处理客户端的请求,一段时间后可能恢复正常
HTTP报文:HTTP报文是由一行行的简单字符串组成的,HTTP报文都是纯文本,不是二进制代码
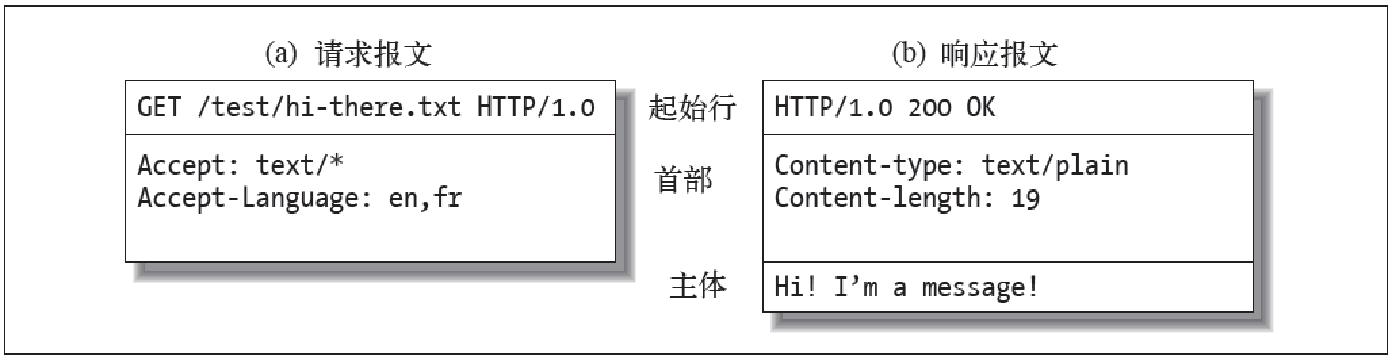
从客户端发往服务器的HTTP报文称为请求报文。从服务器发往客户端的报文称为响应报文,此外没有其它类型的HTTP报文
HTTP报文包括如下三部分:
- 起始行:报文的第一行就是起始行,在请求报文中用来说明要做些什么,在响应报文中说明出现了什么情况。
- 首部字段:起始行后面有0个或多个首部字段,每个首部字段都包含一个名字和一个值,为了便于解析,两者之间用冒号:来分隔。首部以一个空行结束,添加一个首部字段和添加新行一样简单。
- 主体:空行之后就是可选的报文主体了,其中包含了所有类型的数据。请求主体中包括了要发送给Web服务器的数据;响应主体中装载了要返回给客户端的数据。起始行和首部都是文本形式且都是结构化的,而主体则不同,主体中可以包含任意的二进制数据。比如:图片、视频、音轨、软件程序,也可以包含文本。
URL语法
大部分URL都遵循一种标准格式,这种格式包含三个部分:
-
URL的第一部分是方案,说明了访问资源所使用的协议类型,告知客户端怎样访问资源。这部分通常就是HTTP协议(http://)
-
URL的第二部分指的是服务器的位置,告知客户端资源位于何处。比如:www.baidu.com
-
URL的第三部分是资源路径,路径说明了请求的是服务器上哪个特定的本地资源。比如:/specialssaw/index-fall.html
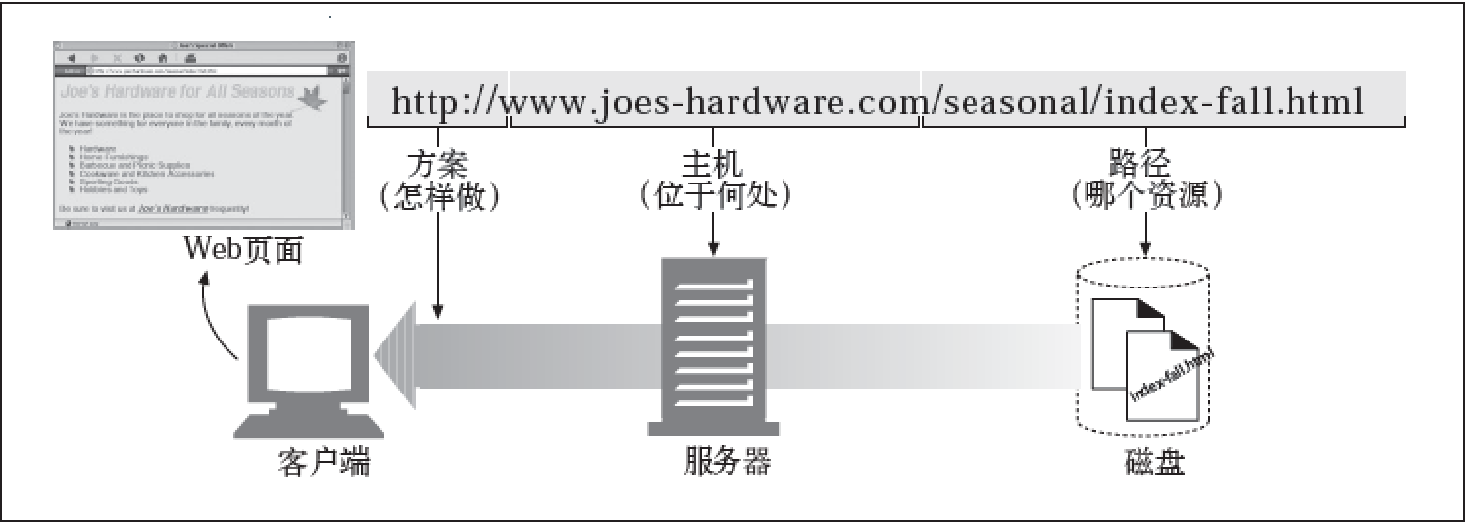
URL提供了一种统一的资源命名方式。大多数URL都是同样的结构
大多数URL语法都建立在这个由9部分构成的通用格式上:<scheme>://<user>:<password>@<host>:<port>/<path>;<params>?<query>#<frag>

方案——使用什么协议
方案实际上是规定如何访问指定资源的主要标识符,它会告诉负责解析URL 的应用程序应该使用什么协议
方案组件必须以一个字母符号开始,由第一个“:”符号将其与URL 的其余部分分隔开来
主机与端口
主机组件表示了因特网上能够访问资源的宿主机器
端口组件标识了服务器正在监听的网络端口。对下层使用了TCP协议的HTTP 来说,默认端口号为80;HTTPS默认端口号为443
用户名和密码
很多服务器都要求输入用户名和密码才会允许用户访问数据
路径
URL 的路径组件说明了资源位于服务器的什么地方。路径通常很像一个分级的文件系统路径
路径是服务器定位资源时所需的信息。可以用字符“/”将HTTP URL的路径组件划分成一些路径段。每个路径段都有自己的参数组件
参数
为了向应用程序提供它们所需的输入参数,以便正确的与服务器进行交互,URL中参数组件就是URL中的名值对列表,由字符”;”将其与URL的其余部分(以及各名值对)分隔开
查询字符串
URL问号(?)右边的内容被称为查询组件。URL 的查询组件和标识网关资源的URL 路径组件一起被发送给网关资源。基本上可以将网关当作访问其他应用程序的访问点
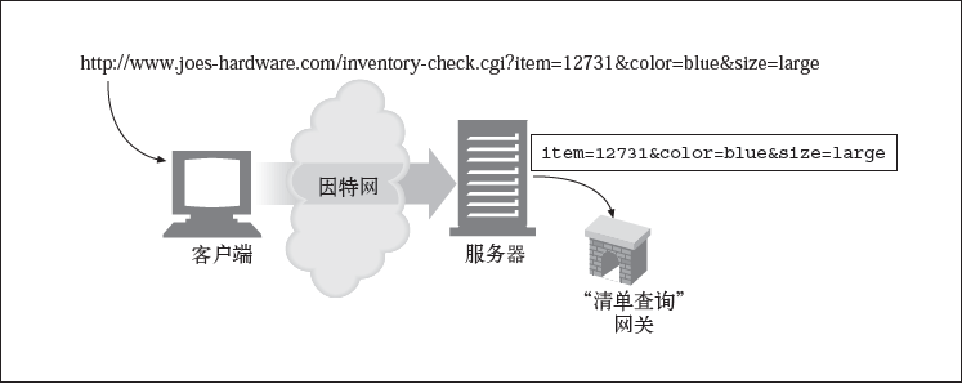
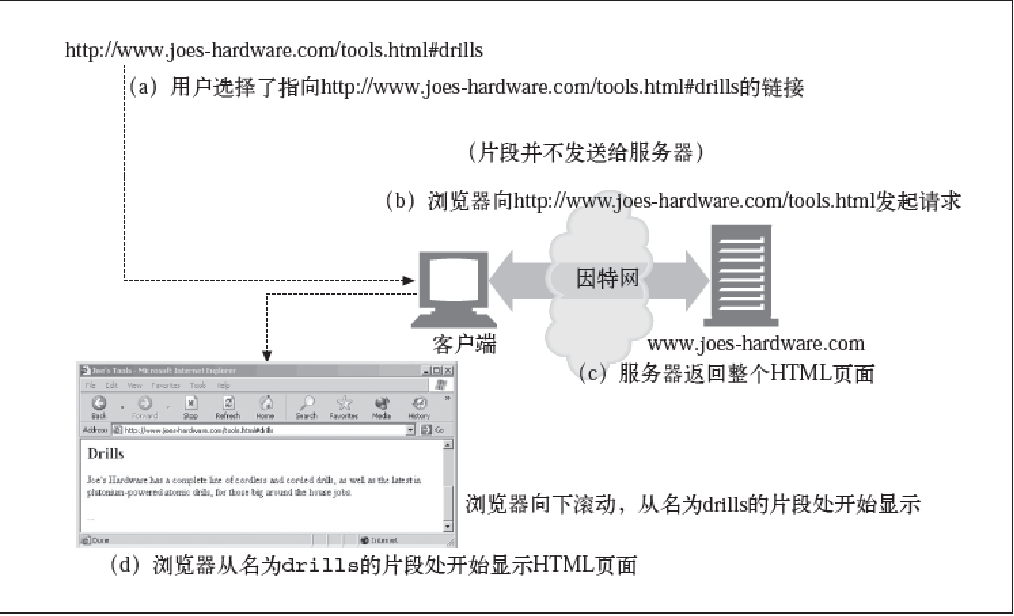
片段
为了引用部分资源或资源的一个片段,URL支持使用片段组件来表示一个资源内部的片段。比如:URL可以指向HTML文档中一个特定的图片或小节
url详解:https://www.baidu.com/sdf/view/cvaxb?f=8&rsv_bp=1&tn=baidu&wd=%E5%A4%A9%E6%B0%94&oq=params&rsv_pq=ec2127830013cd62
-
http/https:协议类型
-
host:主机地址或域名(192.168.x.xx:8080;www.xxx.com;localhost:8080)
-
port:端口号(默认端口是80,可以省略)
-
path:请求的路径(host之后,问号?之前)
-
?:问号是分隔符号
-
参数:name = value
-
&:多个参数用&隔开
HTTP报文
什么是HTTP报文?
用于HTTP协议交互的信息被称为HTTP报文
客户端向服务端发起请求的HTTP报文,叫做请求报文,服务端向客户端返回的HTTP报文,叫做响应报文。也就是说,所有的HTTP报文都可以分为两类:请求报文和响应报文
请求和响应报文的基本报文结构相同
HTTP报文本身是多行数据构成的字符串文本
如果将HTTP比作因特网的信使,那么HTTP报文就是它用来搬东西的包裹
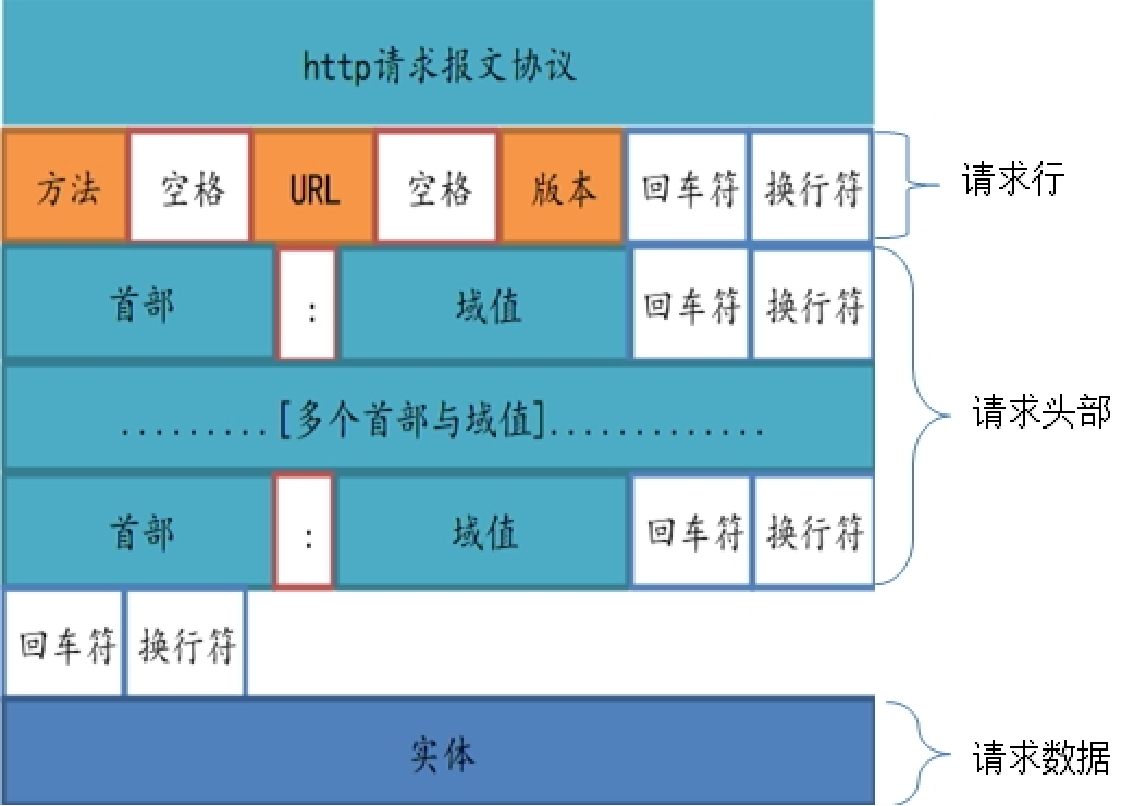
报文的组成部分
起始行
所有的HTTP报文都以一个起始行作为开始。请求报文的起始行说明了要做些什么。响应报文的起始行说明发生了什么
-
请求行:请求报文的起始行,称为请求行,包含了一个方法,一个请求URL,和H一个TTP版本
-
响应行:响应报文的起始行,称为响应行,包含了响应报文使用的HTTP版本,数字状态码,以及描述操作状态的文本形式的原因短语
方法和状态码
方法是用来告诉服务器做什么事情
状态码则用来攻速客户端,发生了什么事情
原因短语
原因短语是响应起始行中的最后一个组件,它为状态码提供了文本形式的解释
原因短语和状态码是成对出现的。原因短语是状态码的可读版本
版本号
版本号会以HTTP/x.x的形式出现在请求和响应报文的起始行中。使用版本号的目的是为使用HTTP的应用程序提供一种线索,以便相互了解对方的能力和报文格式
首部
HTTP首部字段向请求和响应报文中添加了一些附加信息。本质上来说,它们只是一些名/值对的列表
请求首部
- Connection:定义C/S之间关于请求/响应的有关选项对于http/1.0, Connection: keep-alive
- Cache-Control: 缓存指示
- Content-Encoding:支持的编码
- Content-Language:支持的自然语言
- Content-Length:文本长度
- Content-Location:资源所在位置
- Content-Range:在整个资源中此实体表示的字节范围
- Content-Type:主体的对象类型
- Host: 请求的主机名和端口号,虚拟主机环境下用于不同的虚拟主机
- Referer:指明了请求当前资源的原始资源的URL
- User-Agent: 用户代理,使用什么工具发出的请求
- Accept: 指明服务器能发送的媒体类型
- Accept-Charset: 支持使用的字符集
- Accept-Encoding: 支持使用的编码方式
- Accept-Language: 支持使用语言
- Expect: 告诉服务器能够发送来哪些媒体类型
- Authorization: 客户端提交给服务端的认证数据,如帐号和密码;Token
- Cookie: 客户端发送给服务器端身份标识
响应首部
-
Date标头:消息产生的时间
-
Age标头:(从最初创建开始)响应持续时间
-
Server标头: 向客户端标明服务器程序名称和版本
-
ETage标头:不透明验证者
-
Location标头:URL备用的位置
-
Content-Length标头:实体的长度
-
Content-Tyep标头:实体的媒体类型
-
Accept-Ranges: 对当前资源来讲,服务器所能够接受的范围类型
-
Vary: 首部列表,服务器会根据列表中的内容挑选出最适合的版本发送给客户端
-
Set-Cookie: 服务器端在某客户端第一次请求时发给令牌
-
WWW-Authentication: 质询,即要求客户提供帐号和密码
HTTP请求报文
HTTP响应报文
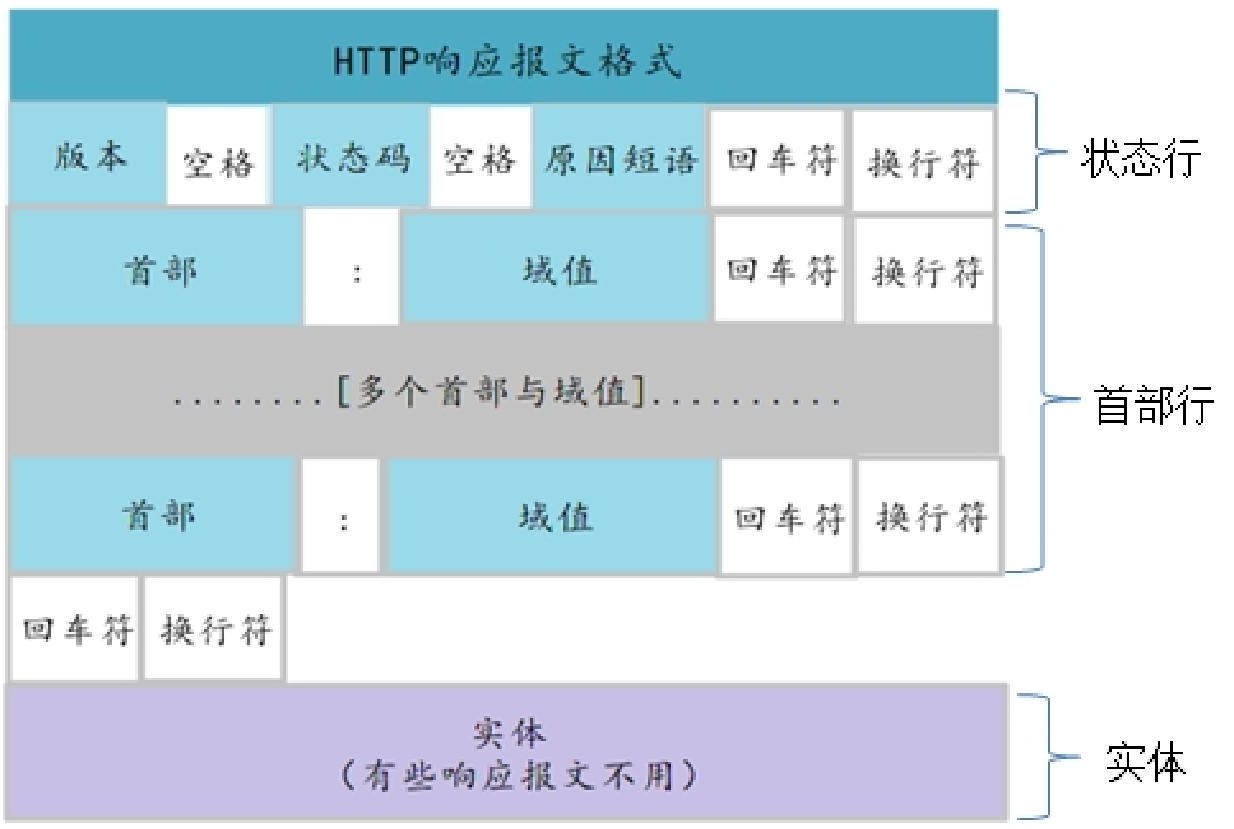
实体的主体部分
HTTP报文的第三部分是可选的实体主体部分。实体的主体是HTTP报文的负荷。就是HTTP要传输的内容
实体包含了客户端请求的对象。Content-Length标头及Content-Type标头用于计算实体的位置、数据类型和数据长度。当服务器接收到客户端的请求报文后,对HTTP请求报文进行解析,并将客户端的请求的对象取出打包,通过HTTP响应报文将数据传回给客户端,如果出现错误则返回包含对应错误的错误代码和错误原因的HTTP响应报文
Post的body
Post的body常见的数据类型有四种,但并不是只有四种:
-
Content-Type:application/json {“key1”:”value1”,”key2”:”value2”}
-
Content-Type:application/x-www-form-urlencoded name1=value1&name2=value2&name3=value3
-
Content-Type:multipart/form-data 这一种是表单格式的,上传图片,上传附件的时候会遇到
-
Content-Type:text/xml <!--?xml version=“1.0”?--> <methodcall> < methodname>examples.getStateName </ methodname>
Get与Post请求
- get方法:只有请求行和请求头,body肯定为空。get的请求参数都在请求行里
- post方法:多一个body部分,当然body也可以为空。post的请求参数可以放在请求行里,也可放在body里
Cookie 与 Session
很多接口都有关联,一个登录接口,其它接口都依赖于登录,当登录之后才能访问页面
HTTP是无状态的,每一个请求都是独立的,需要用到cookies进行关联,登录之后客户端会存cookies,cookies里面存了登录信息,下一个请求就会带着cookies去请求,这样服务器就会识别到已经登录成功了,这就是cookies
Cookies和Session的区别
Cookies是存在客户端的,相当于文本格式,存在客户端就是一个文件。Cookies信息就写人到文件里面去了
Session主要用于服务端,是服务端给的一个标志,一串数字或一串字母之类的,它是服务端用于校验的,Session有有效期
Cookies有如下特点:
-
保存在客户端,存储在本地
-
是否加密存储是由服务端决定,不过由于存储在本地,很难保证数据不被非法访问,并不怎么安全,所以cookies中不宜保存敏感信息,如密码等
-
哪些信息需要保存,作为cookies保存在客户端本地,保存多长时间,一般是由服务端决定的。所以HTTP协议中通过服务器返回的响应报文头中,有一个set-Cookie域,来指示客户端在本地保存cookie信息
-
cookies保存在客户端本地的目的是为了下次访问网站的时候,可以直接取出来上送服务器,所以HTTP协议中通过客户端发送给服务器的请求报文头中,有一个cookies域专门用于存放这个信息,以便客户端将cookies信息发送给服务端
Session:
-
Session,中文一般翻译为“会话”
-
也是一种管理用户状态和信息的机制
-
与cookies将数据保存在客户端本地不同的是,session的数据保存在服务端,一般放在服务器的内存里
-
客户端和服务端通过一个SessionID来进行沟通,为了防止不同的客户端之间出现冲突和重复,这个SessionID一般是一个较长的随机字符串(32或者48个字节)
什么是登录态,票据和token
当用户在app中输入账号和密码登录后,服务端(也就是后台)会进行验证,看看账号和密码是否匹配,如果匹配,就登录成功。用户后续在app中操作的时候,就不需要再输入密码了,直接操作即可。
这里有个问题,如果有人恶意用别人的账号伪造发请求呢?岂不是代替别人进行一些操作了?
后台不能让用户每次操作都携带密码,怎么办呢?实际上,用户登录成功后,后台会生成一个特定的信息(可以理解为一个字符串),这个字符串就是一个令牌,是一种身份和状态的标志。用户进行一些操作的时候,客户端不需要携带密码,而是携带这个令牌就行了,后台验证这个令牌信息,从而来确定接收到的请求是否是用户自己真正的请求
可见,令牌是一种身份,是一种登录成功的状态,这个令牌其实就是token,在很多场合,也可以叫票据。所以, 你可以认为,票据==token
那登录态是什么意思呢?登录态有两个含义:
- 指登录的状态。比如大家经常会看到提示登录态已经失效,登录态应过期,意思就是说,现在是退出的状态, 而非登录的状态
- 指票据,或者说是token。后端的同学可能会说:app传过来的登录态过期了啊。所以,这里的登录态是指登录态信息,说白了,就是指票据,也就是token
当用户登录成功后,进行一系列操作时,除了需要携带登录态票据/token外,对应操作的请求外,还需要携带登录账号吗?其实可带可不带,带了也没用,服务端是不能信任这个账号的,因为谁都可以伪造。那后台怎么知道是哪个账号发的呢?很简单,在进行登录态票据/token校验的时候,能从登录态票据/token中解出用户账号。所以,通常的方式是:app端携带账号、登录态票据/token以及操作的请求,后台只能相信于从登录态票据/token校验中获取的账号, 而不能直接相信app给的账号
为什么能从登录态票据/token中解出账号信息呢?很显然,在后台肯定是有绑定关系的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号