kafka介绍和使用
1 Kafka简介
Kafka是最初由Linkedin公司开发,它是一个分布式、可分区、多副本,基于zookeeper协调的分布式日志系统;常见可以用于web/nginx日志、访问日志,消息服务等等。Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。主要应用场景是:日志收集系统和消息系统。
Kafka是一个分布式消息队列。具有高性能、持久化、多副本备份、横向扩展能力。生产者往队列里写消息,消费者从队列里取消息进行业务逻辑。Kafka就是一种发布-订阅模式。将消息保存在磁盘中,以顺序读写方式访问磁盘,避免随机读写导致性能瓶颈。
-
消息(Message)
是指在应用之间传送的数据,消息可以非常简单,比如只包含文本字符串,也可以更复杂,可能包含嵌入对象。 -
消息队列(Message Queue)
一种应用间的通信方式,消息发送后可以立即返回,通过消息系统来确保信息的可靠传递,消息发布者只管把消息发布到MQ中而不管谁来取,消息使用者只管从MQ中取消息而不管谁发布的,这样发布者和使用者都不用知道对方的存在。
2 Kafka特性
-
高吞吐、低延迟kafka 最大的特点就是收发消息非常快,kafka 每秒可以处理几十万条消息,它的最低延迟只有几毫秒。 -
高伸缩性每个主题(topic) 包含多个分区(partition),主题中的分区可以分布在不同的主机(broker)中。 -
持久性、可靠性Kafka 能够允许数据的持久化存储,消息被持久化到磁盘,并支持数据备份防止数据丢失。 -
容错性允许集群中的节点失败,某个节点宕机,Kafka 集群能够正常工作。 -
高并发支持数千个客户端同时读写。
3 Kafka集群架构
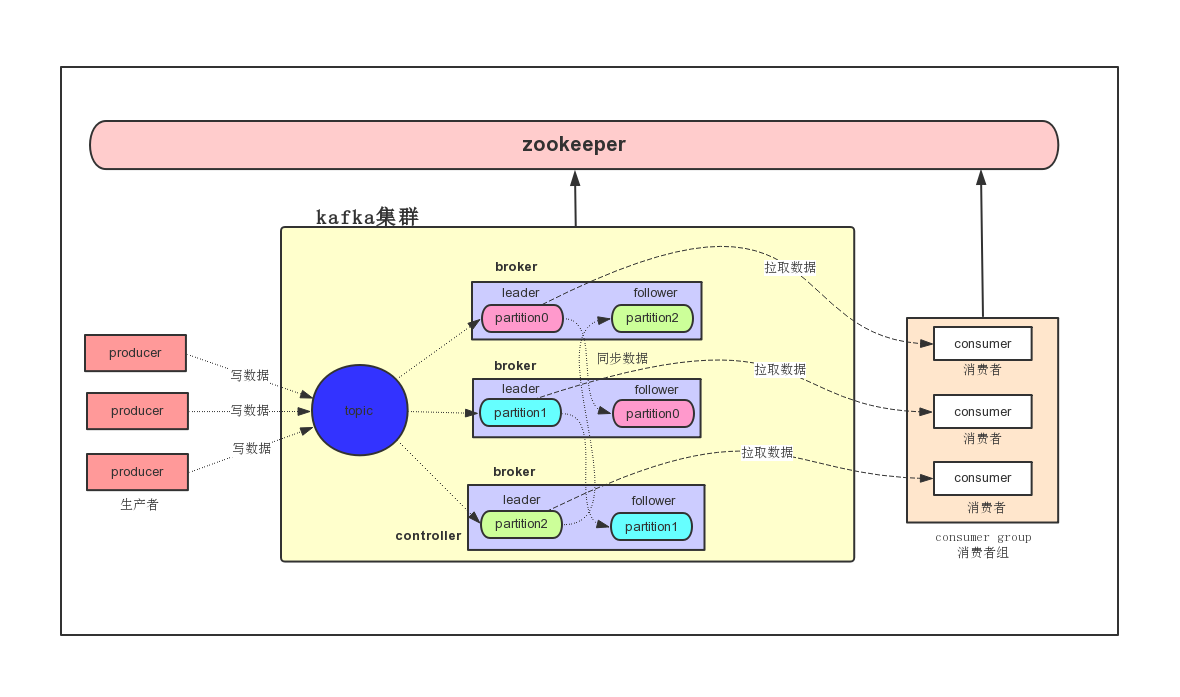
-
producer
消息生产者,发布消息到Kafka集群的终端或服务。 -
broker
Kafka集群中包含的服务器,一个borker就表示kafka集群中的一个节点。
-
topic
每条发布到Kafka集群的消息属于的类别,即Kafka是面向 topic 的。 更通俗的说Topic就像一个消息队列,生产者可以向其写入消息,消费者可以从中读取消息,一个Topic支持多个生产者或消费者同时订阅它,所以其扩展性很好。 -
partition
每个 topic 包含一个或多个partition。Kafka分配的单位是partition。 -
replica
partition的副本,保障 partition 的高可用。 -
consumer
从Kafka集群中消费消息的终端或服务。 -
consumer group
每个 consumer 都属于一个 consumer group,每条消息只能被 consumer group 中的一个 Consumer 消费,但可以被多个 consumer group 消费。 -
leader
每个partition有多个副本,其中有且仅有一个作为Leader,Leader是当前负责数据的读写的partition。 producer 和 consumer 只跟 leader 交互。 -
follower
Follower跟随Leader,所有写请求都通过Leader路由,数据变更会广播给所有Follower,Follower与Leader保持数据同步。如果Leader失效,则从Follower中选举出一个新的Leader。 -
controller
知道大家有没有思考过一个问题,就是Kafka集群中某个broker宕机之后,是谁负责感知到他的宕机,以及负责进行Leader Partition的选举? 如果你在Kafka集群里新加入了一些机器,此时谁来负责把集群里的数据进行负载均衡的迁移? 包括你的Kafka集群的各种元数据,比如说每台机器上有哪些partition,谁是leader,谁是follower,是谁来管理的? 如果你要删除一个topic,那么背后的各种partition如何删除,是谁来控制? 还有就是比如Kafka集群扩容加入一个新的broker,是谁负责监听这个broker的加入? 如果某个broker崩溃了,是谁负责监听这个broker崩溃? 这里就需要一个Kafka集群的总控组件,Controller。他负责管理整个Kafka集群范围内的各种东西。 -
zookeeper
(1)Kafka 通过 zookeeper 来存储集群的meta元数据信息。 (2)一旦controller所在broker宕机了,此时临时节点消失,集群里其他broker会一直监听这个临时节点,发现临时节点消失了,就争抢再次创建临时节点,
保证有一台新的broker会成为controller角色。
* offset
* 偏移量
消费者在对应分区上已经消费的消息数(位置),offset保存的地方跟kafka版本有一定的关系。
kafka0.8 版本之前offset保存在zookeeper上。
kafka0.8 版本之后offset保存在kafka集群上。
它是把消费者消费topic的位置通过kafka集群内部有一个默认的topic,名称叫 __consumer_offsets,它默认有50个分区。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号