节点运维新范式,原生节点助力企业全链路降本
背景
在云原生领域,Serverless 已然是大势所趋。相比 Serverful 模式(基于云服务器集群的K8s运维模式),Serverless 模式屏蔽了资源概念,大幅提升运维效率。用户无需介入底层运维:像操作系统的安全补丁升级这样的动作,判断升级时机 - 升级前置检查 - 无损分批升级全部都由平台自动闭环。但 Serverless 真的适合所有场景么?其实不然。
- Serveless 改变了运维习惯,例如集群出现业务故障时无法登录节点排查
- Serverless 业界实现无统一标准,对接复杂度高
- Serverless 对于客户的计费习惯、成本管理习惯、分账习惯也有很大的挑战
Serverless 和 Serverful 的完美平衡
我们一直在思考,有没有一种产品形态可以同时兼顾 Serverlful 和 Serverless 的优点呢?在长期的用户实践中,我们发现一个很有意思的现象:用户希望云厂商提供足够信息,帮助客户判断,但并不希望厂商替他们做决策,对“托管”这种概念表现出明显的排斥,因为“托管”似乎代表完全脱离了客户的控制。用户更期待一种类似管家的角色,够聪明,但是不越权。
因此,我们孵化出了一种节点运维新范式 - 原生节点:依然保留节点形态,但不越权。通过提供海量数据以及专家建议来辅助用户决策,通过声明式运维来高效执行用户的决策。同时,作为 FinOps 的领先布道者,我们也在原生节点中全面集成 Crane 项目的核心能力,并进行全面升级。针对有强烈降本诉求的行业,如泛互 / 教育 / 智能驾驶,以及在降本同时有强安全诉求的行业,如金融/政务,原生节点都提供了全面的解决方案(详见后文使用场景)。下图展示了原生节点的产品架构:

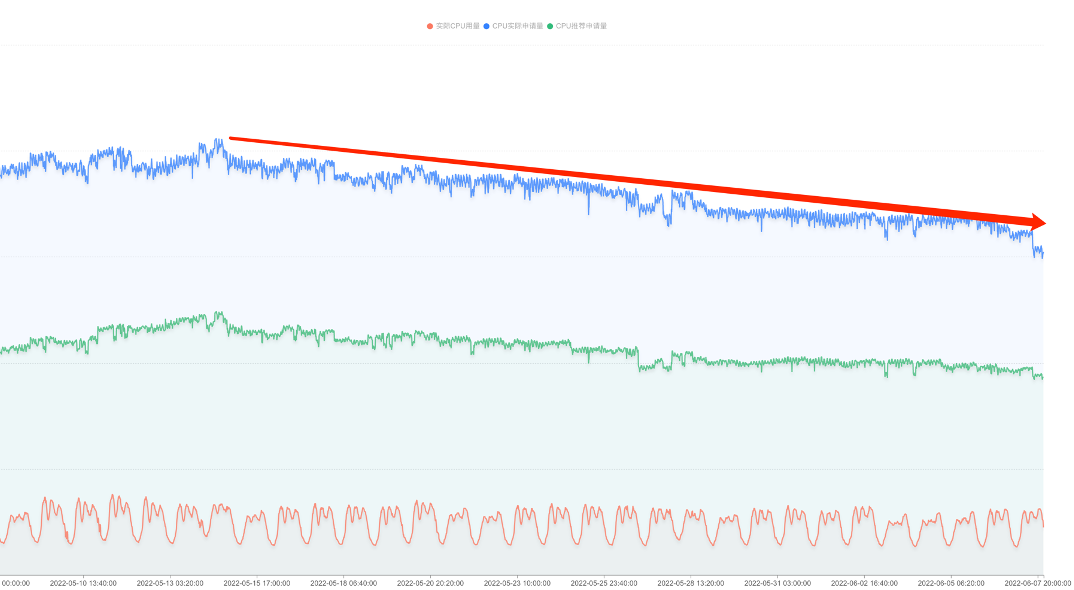
原生节点已支撑百万核 TKE 集群,为腾讯内部降本的坚实底座。在配合业务优化的同时,平台侧通过调度器的紧缩装箱策略以及集群内负载的再平衡,可以让业务 pod 集中到一部分计算节点,做资源的腾挪和下线,在一个月内实现了总 CPU 规模 40 万核的节省量,节省超过1000 万元。
节点运维新范式,像管理 pod 一样管理节点
传统模式的问题
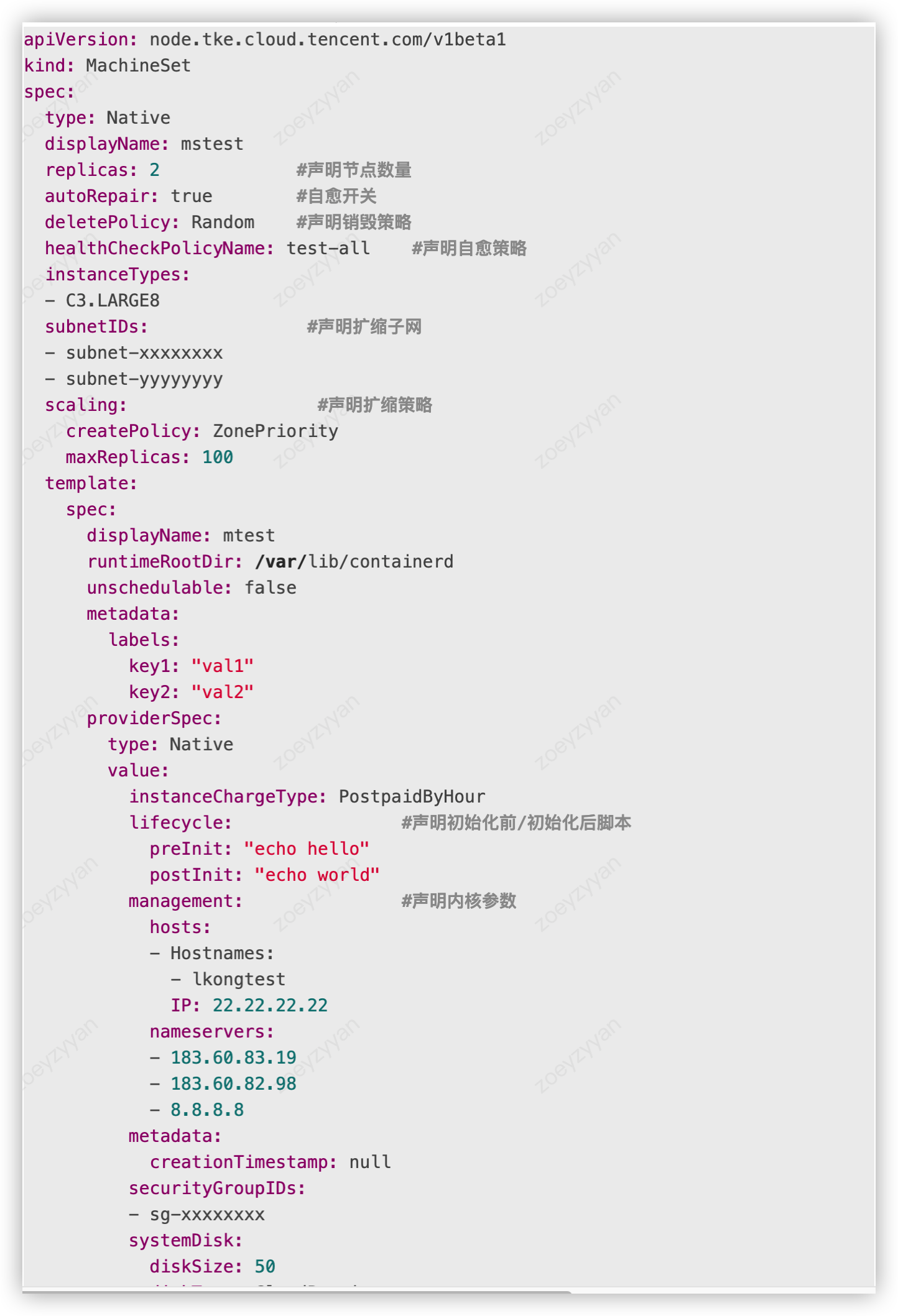
声明式运维是原生节点这种运维范式的核心特征,用户可以通过 yaml 管理节点,声明式提升资源利用率/提升运维效率。传统运维模式下,用户通过云 API 管理节点,往往会遇到:
- API 接口定义不规范
- 报错信息不同步
- 出现问题时需要手动重试
如果通过人肉或者脚本管理节点,比如进行内核版本的升级、系统组件的升级,又极易疏忽、难以复用、且缺乏有效的审计手段
声明式运维的优势

为了解决上述问题,原生节点借鉴 K8s 的管理理念:用户可以像声明 workload 规格、调度策略、运行参数等配置一样, 声明节点的内核版本、内核参数、运行的组件、利用率等配置,不用关心具体执行,让运维更便捷的同时更加精准和可靠:
- Machineset CRD 模版可以随意在任何集群使用,避免厂商绑定
- K8s 原生 reconcilel 机制让用户仅需关注操作结果
- 统一基础设置层的管理视图,符合云原生操作习惯
- 声明节点的资源利用率目标、资源调度策略等配置,从而让用户更方便的进行资源效能管理
原生节点产品能力
上一章节介绍了原生节点声明式运维的优势,这一节我们会详细介绍对应的产品能力,您也可以参考对应链接获取更多信息:
声明式提升资源利用率
-
云原生资产管理平台 :可视化大盘帮忙客户快速洞察成本走势、利用率波动、异常资源对象,提供节点视图 Node Map 和工作负载视图 Workload Map
-
request 智能推荐:根据业务历史画像分析,推荐合适的资源配置量,资源配置进入智能时代
-
pod 原地升降配:针对 pod 的 CPU、内存提供原地升降配能力,通过对 API Server 和 Kubelet 进行升级改造,支持在不重启 Pod 的情况下修改 CPU、内存的 request/limit 值,适用流量突发无损变配场景
-
节点规格放大:虚拟放大原生节点规格,让原生节点装箱率突破 100%,解决节点装满但用量很低的问题
-
调度时和运行时水位控制:提升高优业务稳定性和节点负载均衡
-
可抢占式 Job :从集群中已有资源进行抽取出闲置资源池, 提供可被抢占类型的离线业务使用,实现资源复用最大化
-
Qos Agent:利用腾讯自研的 RUE 内核,从 CPU、内存、网络、磁盘四大维度,十几个子能力全方位提供精细化的业务分级和资源隔离保障能力,充分提升敏感业务稳定性的同时,提升资源利用率
-
GPU 共享 qGPU:支持在多个容器间共享 GPU 卡并提供容器间显存、算力强隔离的能力,从而在更小粒度的使用 GPU 卡的基础上,保证业务安全, 提升 GPU 利用率
声明式提升运维效率
-
声明式管理节点自愈策略:基础设施的不稳定性、环境的不确定性经常会引发不同纬度的系统故障,故障自愈可帮助运维人员快速定位问题,并通过预置平台运维经验,针对不同检测项提供最小化的自愈动作
-
声明式管理节点生命周期:通过标准化的 K8s API 进行资源的增删改查, 无须学习任何社区类 IAC 工具, K8s 基础设施即代码
-
声明式管理节点预装组件及其配置:节点池维度保证参数一致性,提供参数使用说明和推荐值
-
声明式管理管理节点内核参数,配套容器场景优化内核, 兼顾基础设施不可变和用户客制化需求
-
自动升级:声明式管理节点版本,降低离散版本的稳定性风险
![]()
原生节点使用场景
提升资源利用率并进行节点裁撤
为了帮助您更好地理解如何在实际业务中用原生节点来节约资源成本,我们可以从节点裁撤这一最典型的优化举措切入,看看原生节点是如何全链路路攻克降本难题的:
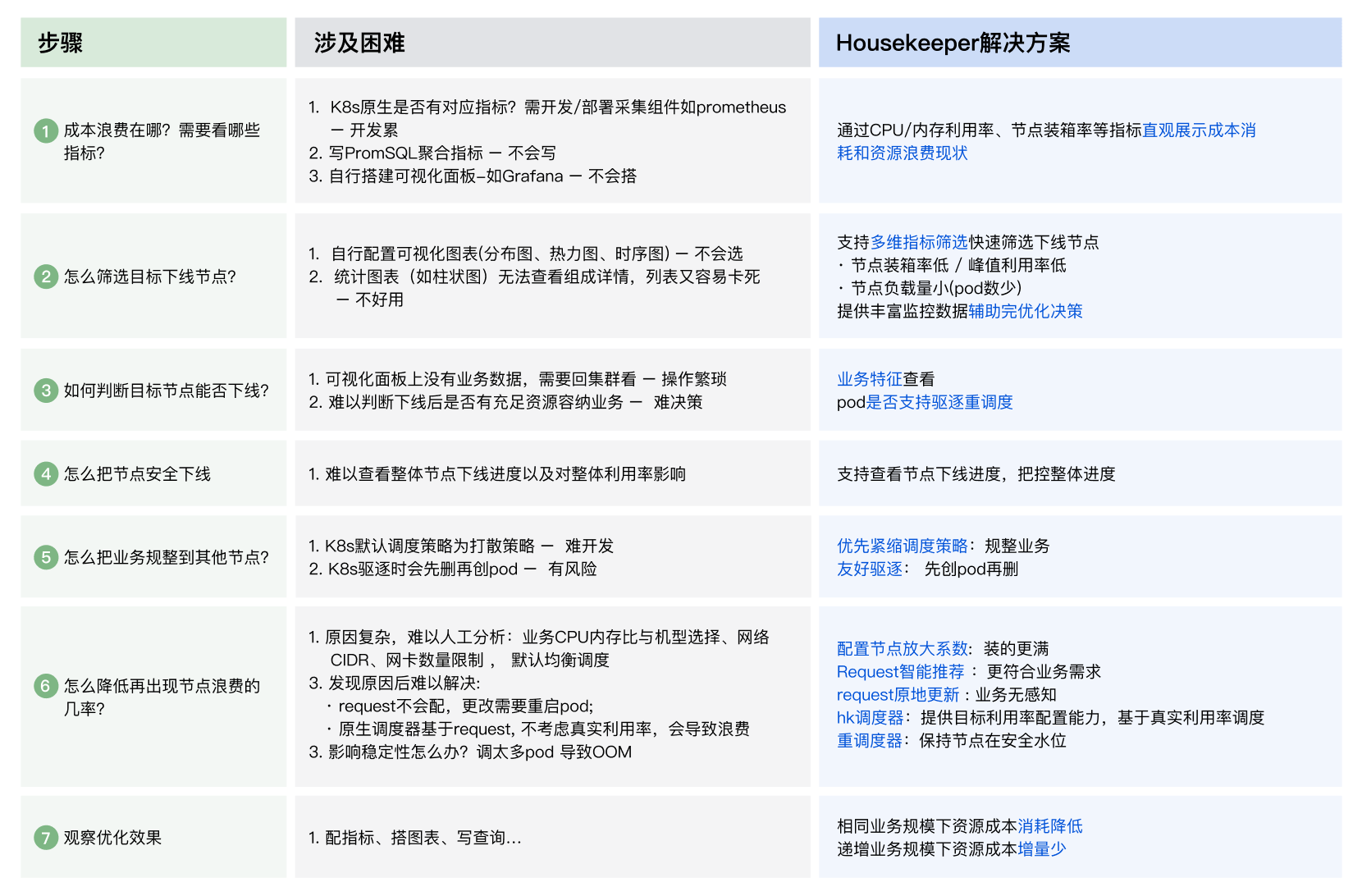
如何在降本的同时保持稳定
降本的前提是保障业务的稳定性,当节点上 pod 密度增加,pod 类型多样,客户必然会担心:
-
影响稳定性怎么办?调太多 pod 会不会负载太高把节点打挂
-
业务之间的资源抢占和竞争怎么处理?高优任务质量如何保障
原生节点也贴心的提供了解决方案:
-
水位线设置能力:保持节点在调度时和运行时都处于安全水位。针对运行时水位能力,原生节点在社区的基础之上增强了 descheduler 的能力:
- *支持按 workload 并行驱逐,在保证 workload 可用性的前提下,保证新的 pod 启动后,进行下一个 pod 的驱逐
- *支持按照事件进行驱动,不限制于以前只能定期轮训的模式
-
基于RUE内核的性能隔离能力,从 CPU、内存、磁盘、网络、调度等角度,全方位提升服务质量等级,为业务稳定降本增效保驾护航:
-
- CPU:绝对抢占,cpuburst,超线程隔离
-
- 内存:内存异步回收,全局水位分级,pagecache limit 等
-
-
网络:出入方向限速,带宽绝对抢占,端口白名单等
-
磁盘IO:磁盘 IOPS 限制,磁盘 BPS 限制等
提升运维效率
我们从 kubelet 组件/内核参数调参、节点排障、版本维护这三个场景来介绍原生节点是如何提升运维效率的:
自定义 kubelet 参数/内核参数
当客户想要自定义 kubelet 参数/内核参数时,会先准备一个初始化脚本或自定义镜像,并在脚本中修改 /etc/sysctl.conf 文件、kubelet、runtime 参数。如果之后要修改参数,客户可能会使用 agent 或者用开源工具,少部分集群中机器比较少的客户可能直接上机器修改。这种模式存在很多问题:
- 需要登陆机器或预写脚本
- 客户管理复杂度较高,不同业务底层机器对应修改的参数不一致,增加排障难度
- 要求运维同学对内核有丰富的修改经验
原生节点可以:
- 节点维度提供便捷操作入口“management”,支持声明式管理
- 提供统一的管理视图,参数可见且节点池维度保证参数一致性
- 提供参数使用说明和推荐值,用户可以自主决策
节点排障
客户节点故障后的排查链路通常是:业务发现问题 -- 拉通售后/一线/专项排查问题 -- 问题透传产研 -- 登陆用户节点查看日志 -- 分析故障分类 -- 根据经验解决:
节点故障分类繁杂,专业程度要求较高
流程长,涉及人员多
原生节点的故障自愈能力可以:
- 实时检测 + 自定义告警:缩短问题发现流程
- 扩大节点检测范围:覆盖 K8s、运行时、os 现网常见数十种故障方便快速定位
- 搭配组件重启能力缩短故障修复时间
版本维护
TKE 现网维护了数十种版本,不同 K8s\runtime\os 之间的版本相互耦合,导致排查问题的复杂度呈指数级上升。我们就曾遇到:客户发现业务访问节点存在超时现象,经过抓包、分析日志等长达一周的排障操作发现可能是由于内核版本不同,对应的 iptables 设置的默认值不一致导致。
但客户对于升级的态度慎之又慎,担心影响业务。原生节点就可以很好的破除这个困境:
- 统一底层基础设施:统一 os、运行时降低平台和用户侧对底层版本的关注度
- 提供自定义配置入口:如 kubelet 参数、内核参数、nameserver、Hosts 用户可通过统一入口声明式管控,兼顾定制化需求
应对流量突发,保障业务稳定性
传统场景下业务流量突发时,如果运维人员想要更改 pod 的 request/limit,往往是通过 yaml 手动更新,总是会遇到:
- 更新时间长,无法及时应对流量洪峰
- 用户修改 yaml,滚动更新,对业务可能有损,可能当前 pod 有流量
原生节点提供了动态修改 pod 资源参数的功能。当 pod 内存使用率逐渐升高,为避免触发 OOM(Out Of Memory)Killer,可以在不重启 pod 的前提下提高内存的 Limit,无损应对突发流量。
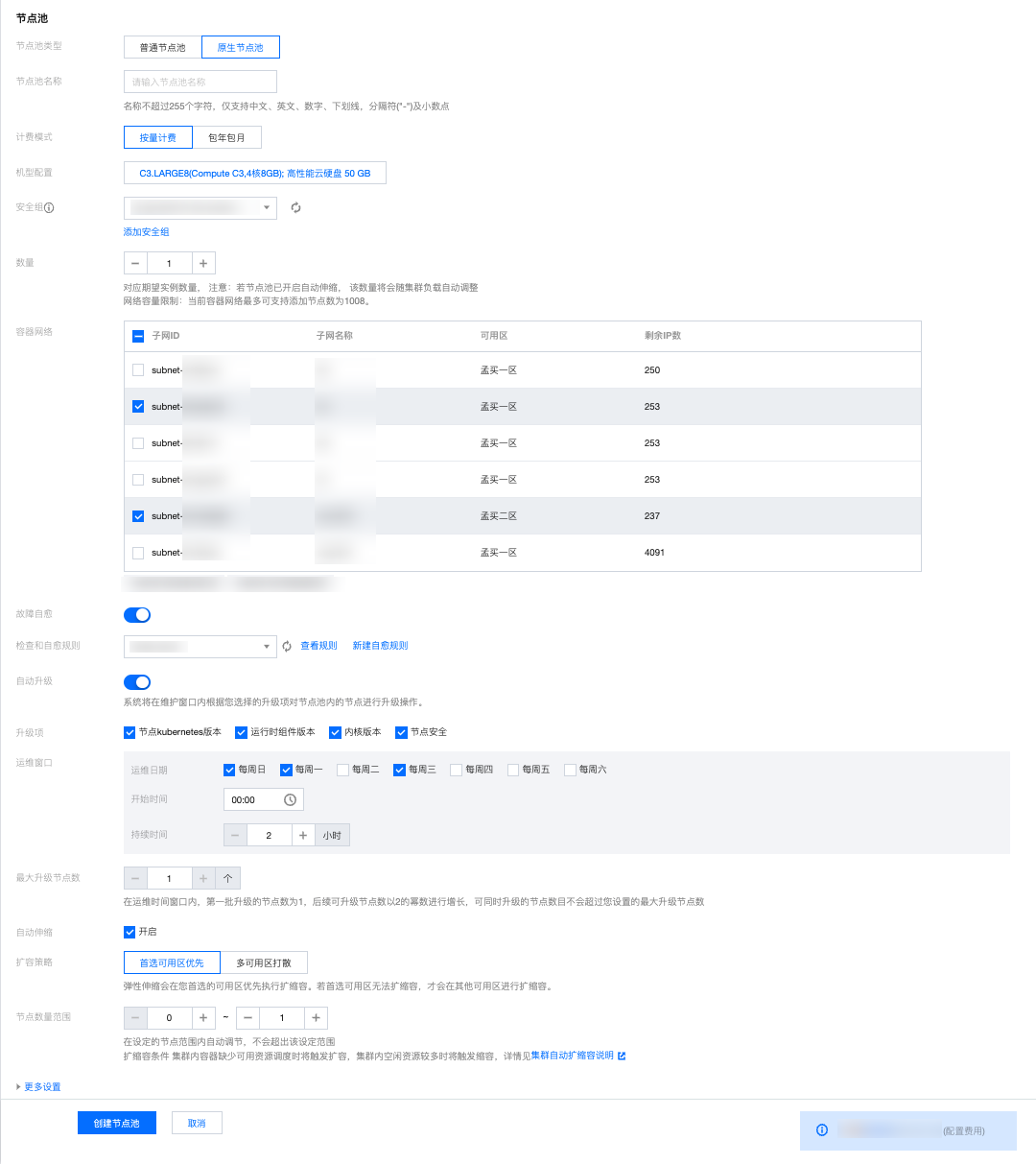
如何创建原生节点
进入集群详情页 > 选择左侧菜单栏中的节点管理 > 节点池 > 单击新建节点池,选择原生节点池并填写对应参数即可:
优惠活动
腾讯云原生
11.1-11.30大促活动持续进行中!
原生节点大额满减券等你领取!
扫描下方图片二维码进入会场抢优惠!

填写信息问券,还可申请测试专用代金券:https://wj.qq.com/s2/11233165/fa4c/
数量有限先到先得!
参考链接
云原生资产管理平台:
https://cloud.tencent.com/document/product/457/78329
request 智能推荐:
https://cloud.tencent.com/document/product/457/75471
pod原地升降配:
https://cloud.tencent.com/document/product/457/79697
节点规格放大:
https://mc.tencent.com/7m4G0ie8
调度时和运行时水位控制:
https://mc.tencent.com/G2nVeuPR
可抢占式 Job:
https://cloud.tencent.com/document/product/457/81751
GPU 共享 qGPU:
https://cloud.tencent.com/document/product/457/61448
声明式管理节点:
https://cloud.tencent.com/document/product/457/78649
【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号