



拓端数据tecdat|R语言代写向量自回归模型(VAR)及其实现
原文链接 http://tecdat.cn/?p=6916
澳大利亚在2008 - 2009年全球金融危机期间发生了这种情况。澳大利亚政府发布了一揽子刺激计划,其中包括2008年12月的现金支付,恰逢圣诞节支出。因此,零售商报告销售强劲,经济受到刺激。因此,收入增加了。
VAR面临的批评是他们是理论上的; 也就是说,它们不是建立在一些经济学理论的基础上,这些理论强加了方程式的理论结构。假设每个变量都影响系统中的每个其他变量,这使得估计系数的直接解释变得困难。尽管如此,VAR在几种情况下都很有用:
- 预测相关变量的集合,不需要明确的解释;
- 测试一个变量是否有助于预测另一个变量(格兰杰因果关系检验的基础);
- 脉冲响应分析,其中分析了一个变量对另一个变量的突然但暂时的变化的响应;
- 预测误差方差分解,其中每个变量的预测方差的比例归因于其他变量的影响。
示例:用于预测美国消费的VAR模型
VARselect(uschange[,1:2], lag.max=8,
type="const")[["selection"]]
#> AIC(n) HQ(n) SC(n) FPE(n)
#> 5 1 1 5
R输出显示由vars包中可用的每个信息标准选择的滞后长度。由AIC选择的VAR(5)与BIC选择的VAR(1)之间存在很大差异。因此,我们首先拟合由BIC选择的VAR(1)。
var1 <- VAR(uschange[,1:2], p=1, type="const")
serial.test(var1, lags.pt=10, type="PT.asymptotic")
var2 <- VAR(uschange[,1:2], p=2, type="const")
serial.test(var2, lags.pt=10, type="PT.asymptotic")
与单变量ARIMA方法类似,我们使用Portmanteau测试24测试残差是不相关的。VAR(1)和VAR(2)都具有一些残余序列相关性,因此我们拟合VAR(3)。
var3 <- VAR(uschange[,1:2], p=3, type="const")
serial.test(var3, lags.pt=10, type="PT.asymptotic")
#>
#> Portmanteau Test (asymptotic)
#>
#> data: Residuals of VAR object var3
#> Chi-squared = 34, df = 28, p-value = 0.2
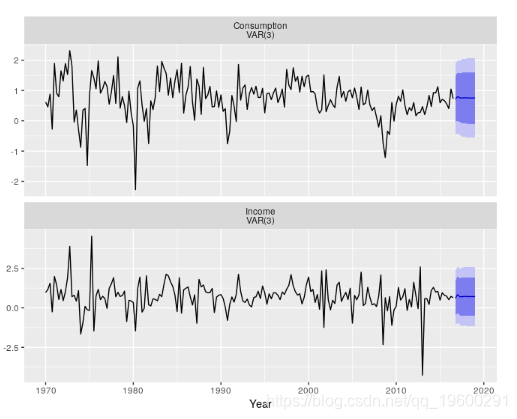
该模型的残差通过了串联相关的测试。VAR(3)生成的预测如图所示。
forecast(var3) %>%
autoplot() + xlab("Year")
![]()
相关推荐:
| 标题 |
|---|
| 使用R语言随机波动模型SV处理时间序列中的随机波动率 (2020-04-15 14:49) |
| R语言用WinBUGS 软件对学术能力测验(SAT)建立分层模型 (2020-04-14 16:27) |
| R语言使用随机技术差分进化算法优化的Nelson-Siegel-Svensson模型 (2020-04-12 18:52) |
| 已迁离北京外来人口的数据画像 (2020-04-11 20:55) |
| R语言用神经网络改进Nelson-Siegel模型拟合收益率曲线分析 (2020-04-10 15:51) |
| 用R语言用Nelson Siegel和线性插值模型对债券价格和收益率建模 (2020-04-06 11:16) |
| R语言LME4混合效应模型研究教师的受欢迎程度 (2020-03-27 15:18) |
| R语言Black Scholes和Cox-Ross-Rubinstein期权定价模型案例 (2020-03-25 14:36) |
| R语言中的Nelson-Siegel模型在汇率预测的应用 (2020-03-25 14:07) |
| R语言中的block Gibbs吉布斯采样贝叶斯多元线性回归 (2020-03-06 16:20) |
如果您有任何疑问,请在下面发表评论。
▍关注我们
【大数据部落】第三方数据服务提供商,提供全面的统计分析与数据挖掘咨询服务,为客户定制个性化的数据解决方案与行业报告等。
▍咨询链接:http://y0.cn/teradat
▍联系邮箱:3025393450@qq.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号