


Python丁香医生平台医生与患者评论数据分析:LightGBM、LDA主题模型、因果推断、聚类、PSM| 附代码数据
全文链接:https://tecdat.cn/?p=44099
原文出处:拓端数据部落公众号
分析师:Jiasen Chen

随着在线医疗行业从 “流量红利” 转向 “质量竞争”,平台如何通过数据挖掘优化医患匹配、提升服务质量,成为突破增长瓶颈的关键。作为数据科学团队,我们曾为多家医疗平台提供数据分析咨询服务,本文内容正改编自此前为在线医疗头部平台设计的用户生态优化项目 —— 通过对丁香医生平台的医生信息与患者评论数据深度分析,解决 “如何识别高价值医生”“患者核心诉求是什么”“服务行为是否真能提升满意度” 等核心业务问题。
本次分析以 Python 为核心工具栈,串联数据采集、清洗、探索性分析(EDA)、机器学习建模与因果推断全流程:先用 K-Means 聚类勾勒医生群体画像,再借 LDA 主题模型挖掘患者隐性诉求,随后通过 LightGBM、多元回归等监督学习量化评分、定价、流量的驱动因素,最后用倾向性评分匹配(PSM)验证服务行为对满意度的因果效应。整个过程既解决实际业务痛点,也为数据科学初学者提供 “从业务到模型” 的完整思路。
本文内容源自过往项目技术沉淀与已通过实际业务校验,该项目完整代码与数据已分享至交流社群。阅读原文进群,可与 600 + 行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路,帮大家既懂 怎么做,也懂 为什么这么做;遇代码运行问题,更能享 24 小时调试支持。此外,我们针对学生群体推出 “应急修复服务”,24 小时响应 “代码运行异常” 求助,比自行调试效率提升 40%,真正实现 “买代码不如买明白”,同时保证高人工创作比例,解决 “代码能运行但怕查重、怕漏洞” 的痛点。
流程图
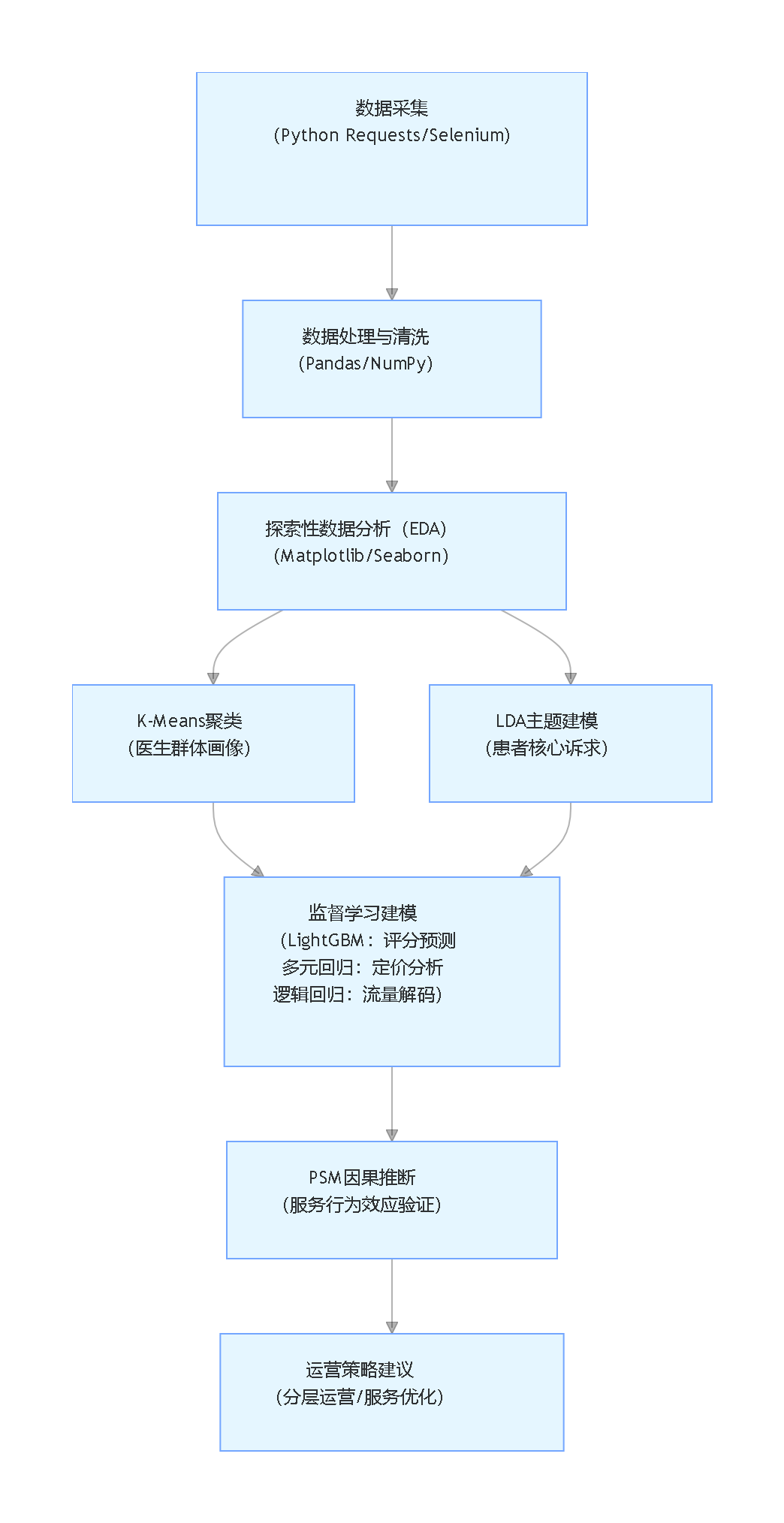
一、 项目概述
1.1 项目背景
随着互联网技术的深度渗透,在线医疗服务已成为现代医疗体系的重要组成部分,深刻地改变了传统的医患交互模式。丁香医生作为国内领先的在线健康服务平台,已汇聚了海量的医生专业信息与患者反馈数据。这些高维度、大规模的数据不仅是平台的核心数字资产,更蕴含着优化服务质量、实现精准医患匹配、提升运营效率的巨大潜力。因此,本项目旨在应用大数据分析技术,对丁香医生平台的公开数据进行系统性的采集、处理与深度挖掘,以探索其内在规律,并提炼出具有商业价值和现实意义的洞见。
1.2 项目目标
为系统性地发掘丁香医生平台数据的价值,本项目设定了以下四个核心研究目标:
- 医生群体结构分析与画像构建: 运用非监督学习算法(K-Means聚类)对医生群体进行数据驱动的分层,识别并描绘具有不同特征的医生群体画像,从而深入理解平台医生生态的构成与多样性。
- 患者核心需求与体验洞察: 利用自然语言处理技术(LDA主题模型)对患者评论文本进行深度挖掘,提炼患者的核心关切、情感诉求及就医体验的关键维度,为服务质量的针对性提升提供依据。
- 关键成功因素的量化识别: 综合运用探索性数据分析(EDA)与多种监督学习模型,量化分析影响医生服务定价、患者满意度及平台流量分配等关键结果变量的核心驱动因素,并评估其相对重要性。
- 数据驱动的战略建议提炼: 基于上述分析结果,为平台在运营策略、产品优化、医生激励机制及精准营销等方面,提供具备实证基础和可操作性的战略与战术建议。
1.3 技术栈
本项目综合运用了以下技术栈:
- 数据采集:Python (Requests, Selenium)
- 数据处理:Pandas, NumPy, re
- 数据可视化:Matplotlib, Seaborn
- 机器学习:Scikit-learn (KMeans, PCA, RandomForestClassifier), LightGBM
- 自然语言处理:Jieba, pyLDAvis
二、 数据获取与处理
2.1 数据工程流水线设计
本项目构建了一套完整的数据工程流水线,从元数据采集到最终的结构化数据输出,流程清晰,自动化程度高。
整个流程主要分为四个阶段:
- 准备工作:采集所有科室列表及其ID,为后续爬取奠定基础。
- 数据采集:利用并发爬虫,高效获取每位医生的详细信息与全量评论。
- 数据存储:将原始数据以JSON格式分层级、分文件存储,便于管理和追溯。
- 数据处理:通过解析脚本,将分散的JSON数据清洗、整合,输出为可供分析的CSV宽表。
2.2 核心功能模块实现
系统的核心功能由一系列Python脚本实现,各脚本职责明确、相互协作:
- 科室爬虫.py
功能:采集所有科室的名称和链接,作为数据采集的入口。 - 医生id爬虫.py
功能:根据科室ID,分页抓取各科室下的所有医生列表信息。 - 并发爬虫.py
功能:核心数据采集脚本,使用多线程并发抓取每位医生的详细个人信息和全量患者评论。 - alldoctor.py
功能:将分散的医生基本信息JSON文件,解析并整合成一个总的医生特征宽表CSV。 - 评论汇总.py
功能:将分散的医生评论JSON文件,按科室进行汇总,为文本分析做准备。 - 辅助与测试脚本
功能:包含单爬虫、单文件解析等脚本,用于调试和验证核心逻辑。
部分数据如下:

2.3 数据清洗与特征工程
在获得原始数据后,我们进行了系统的数据清洗和特征工程,以提升数据质量,并为后续建模做准备。主要步骤包括:
- 缺失值处理:对关键数值型特征(如consult_price)中的缺失值,基于业务理解采用零值或中位数进行填充;对描述性文本的缺失,则填充为空字符串。
- 数据转换:将非结构化的响应时间文本(如“xx分钟”、“xx小时”)统一转换为数值型的“分钟”单位。
- 地理特征衍生:从location_name字段中提取出city(城市)、city_tier(城市等级)、is_municipality(是否直辖市)等结构化特征。
- 标签特征工程:对specialty_tags(专业标签)进行频率分析,提取高频标签作为独热编码特征;从hospital_info_tag中提取出hosp_type_百强医院、hosp_type_三甲医院等关键二值特征。
- 文本特征二值化:将practice_experience(实践经历)和academic_experience(学术经历)等文本描述,转换为表示“有/无”的二值特征。
2.4 字段表
|
字段名 |
数据类型 |
中文含义 |
|
doctor_id |
int64 |
医生唯一标识符 |
|
nickname |
object |
医生昵称 |
|
gender |
int64 |
性别 |
|
title |
object |
职称 |
|
title_id |
int64 |
职称ID |
|
specialty_tags |
object |
专业标签 |
|
specialty_tags_type |
object |
标签类型 |
|
total_comment |
int64 |
总评论数 |
|
practice_experience |
object |
执业经历 |
|
academic_experience |
object |
学术经历 |
|
professional_profile |
object |
专业简介 |
|
hospital_id |
int64 |
医院ID |
|
hospital_name |
object |
医院名称 |
|
department_id |
int64 |
科室ID |
|
department_name |
object |
科室名称 |
|
location_name |
object |
所在地名称 |
|
location |
int64 |
详细地址 |
|
hospital_info_tag |
object |
医院标签 |
|
hospital_info_type |
object |
医院类型 |
|
years_experience |
int64 |
从业年限 |
|
expert |
int64 |
是否专家 |
|
certified_expert |
int64 |
是否认证专家 |
|
self_desc |
object |
自我描述 |
|
send_word |
object |
医生寄语 |
|
reply_count |
int64 |
回复患者数 |
|
patient_count |
int64 |
患者总数 |
|
received_count |
int64 |
接诊量 |
|
star_sum |
int64 |
星级评分总和 |
|
follower_count |
int64 |
粉丝数 |
|
average_rating |
float64 |
平均评分 |
|
avg_response_time |
object |
平均响应时间(分钟) |
|
prescription_count |
int64 |
处方数量 |
|
consult_price |
float64 |
图文咨询价格 |
|
phone_price |
float64 |
电话咨询价格 |
|
video_price |
float64 |
视频咨询价格 |
|
new_user_price |
float64 |
新用户价格 |
|
hot_counsel_tags |
object |
热门咨询标签 |
|
comment_tags |
object |
评论标签 |
|
department |
object |
科室大类 |
|
anonymous_name |
object |
匿名用户名称 |
|
rating |
int64 |
评分(星级) |
|
comment_time |
object |
评论时间 |
|
comment_content |
object |
评论内容 |
|
labels |
object |
评论标签 |
|
has_replies |
int64 |
是否有回复(1有/0无) |
|
comment_length |
int64 |
评论长度(字数) |
|
is_positive |
int64 |
是否积极评价(1是/0否) |
三、 探索性数据分析 (EDA)
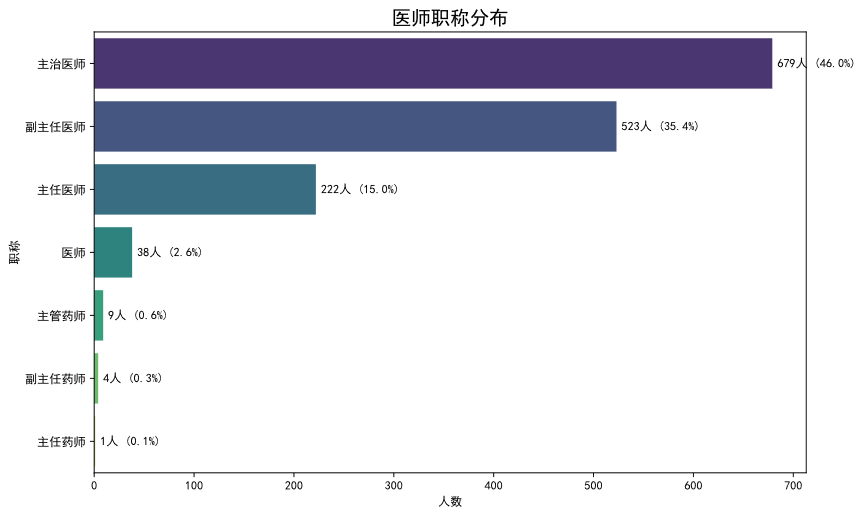
通过对核心字段的描述性统计分析,我们勾勒出丁香医生平台医生的整体画像,其主要特征如下:
3.1平台医生整体特征分析
- 高职称构成主体: 平台医生以主治医师 (46.0%) 和副主任医师 (35.4%) 为绝对主力,二者合计占比超过80%,表明平台医生群体具备扎实的专业水准和临床经验。
- 顶级医院背景显著: 90.0% 的医生来自三甲医院,93.1% 的医生所在医院为医保定点机构。这反映了平台在医生准入上具有较高门槛,其核心医生资源高度集中于国内优质医疗机构。
- 资深专业能力突出: 超过半数(53.6%)的医生从业年限超过10年;近四成(37.5%)拥有医学博士学位;超过八成(81.6%)具备在线处方权。这些数据共同印证了平台医生群体的资深性与专业性。
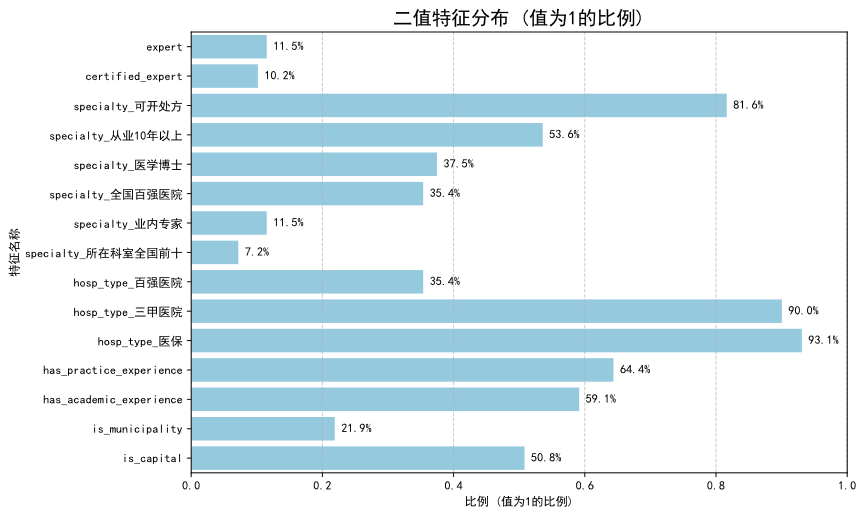
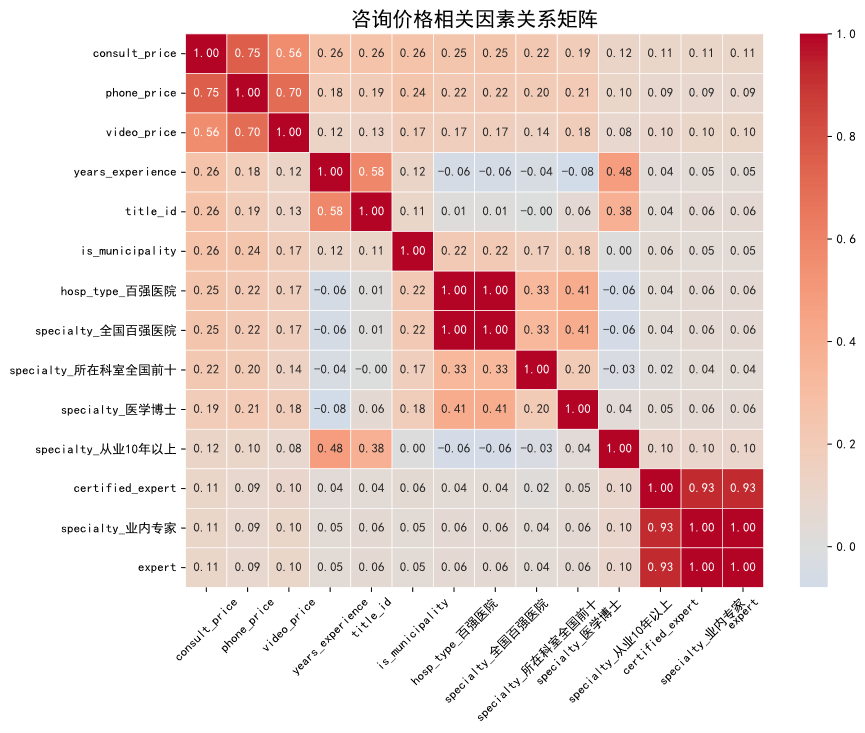
3.2 核心发现与业务洞察
洞察一:探索性分析的核心洞察
分析显示,医生的从业经验与职称等级存在高达0.58的强正相关性。同时,这两者均与服务价格显著正相关。这表明平台的定价体系在很大程度上遵循了传统医疗领域“论资排辈”的价值逻辑,资历是医生服务价值的核心体现。
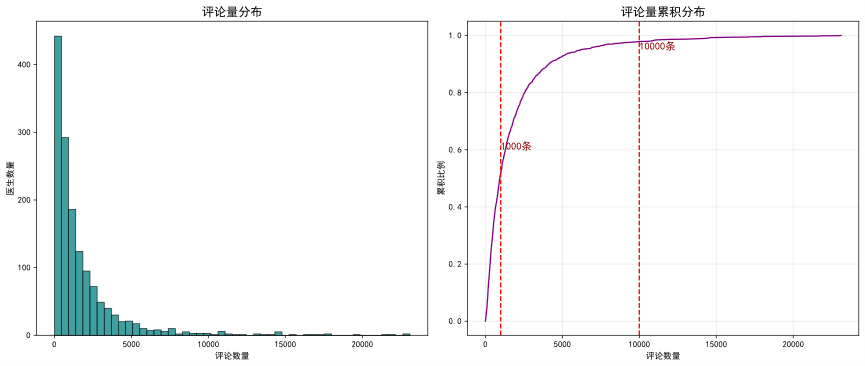
洞察二:平台流量分布呈现显著的“马太效应”
服务量相关指标,如total_comment(总评论数)和patient_count(服务患者数),均呈现严重的长尾分布。少数头部医生占据了平台绝大部分的患者与流量资源,而超过半数的医生服务量相对较小。这揭示了平台生态中流量高度集中的现状。
相关文章

CNN-LSTM、GRU、XGBoost、LightGBM风电健康诊断、故障与中国银行股票预测应用实例
原文链接:https://tecdat.cn/?p=41907
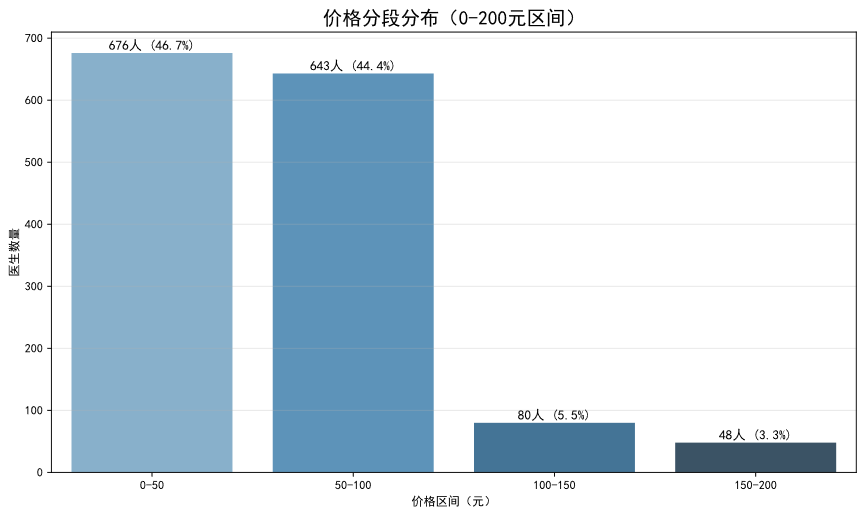
洞察三:价格敏感带清晰,200元是重要心理价位。
绝大多数在线图文咨询服务的定价集中在50至150元人民币区间。服务定价超过200元的医生占比仅为2.0%,表明高价位服务在当前市场环境下仍属小众,平台的主流用户对价格较为敏感。
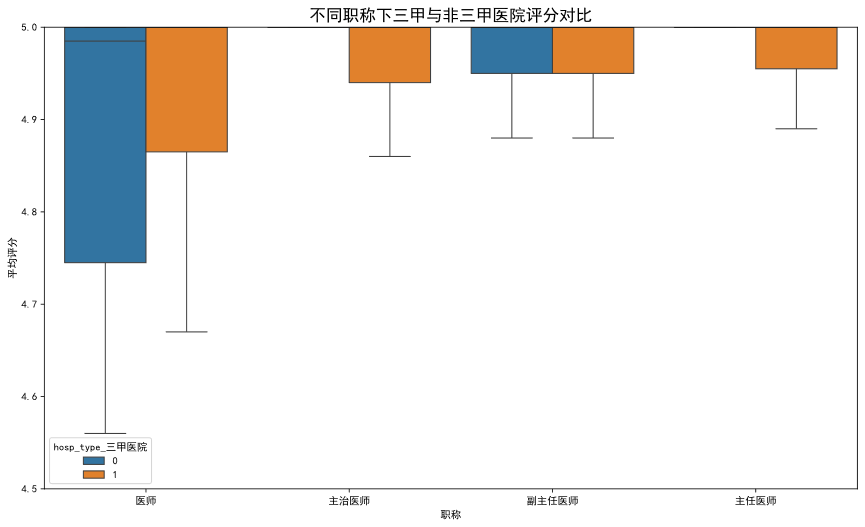
洞察四:“三甲”光环并非患者满意度的绝对保证
尽管三甲医院的医生在数量上占绝对优势(90%),但在核心的患者满意度指标average_rating上,非三甲医院医生的平均表现与三甲医生并无统计学上的显著差异(p=0.13),甚至略高。这初步表明,医院的“金字招牌”并不能完全等同于线上的服务体验质量。
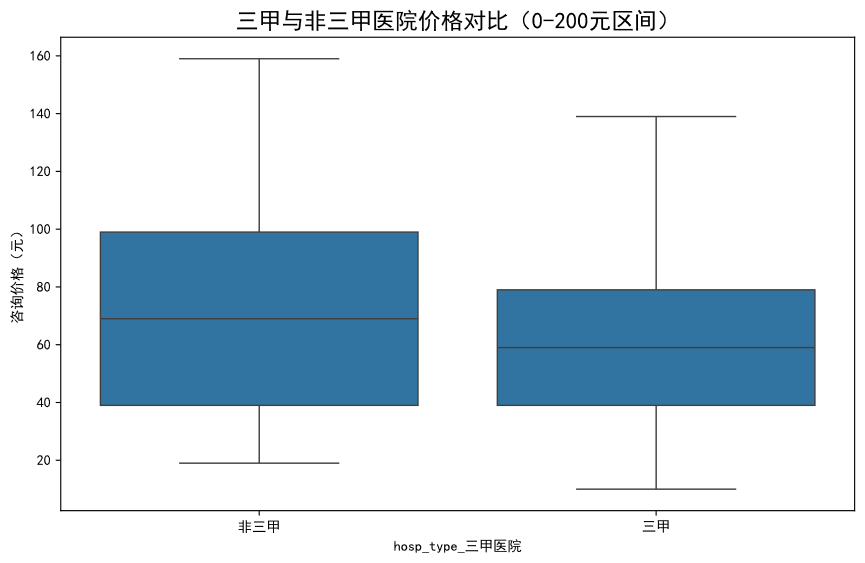
洞察五:用户选择行为呈现“声誉导向”与“性价比导向”的分化
交叉分析显示,平台流量最大的医生群体组合是“三甲医院背景且无医保资质”,而平均服务价格最低的群体组合是“非三甲医院背景且有医保资质”。这暗示平台可能存在两类主流用户:一类是追求顶尖医疗资源、对价格不敏感的“声誉优先型”用户;另一类则是寻求基础医疗保障、对价格敏感的“性价比优先型”用户。
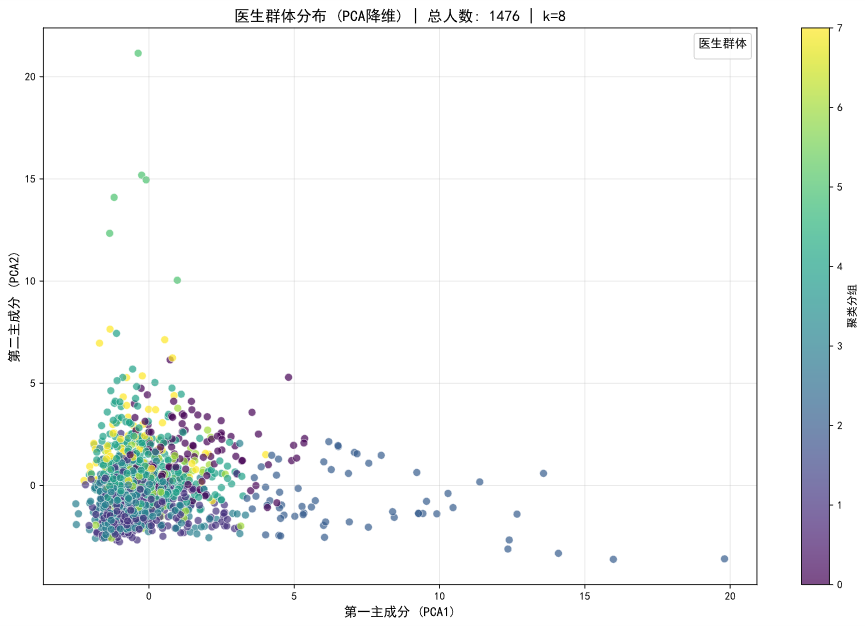
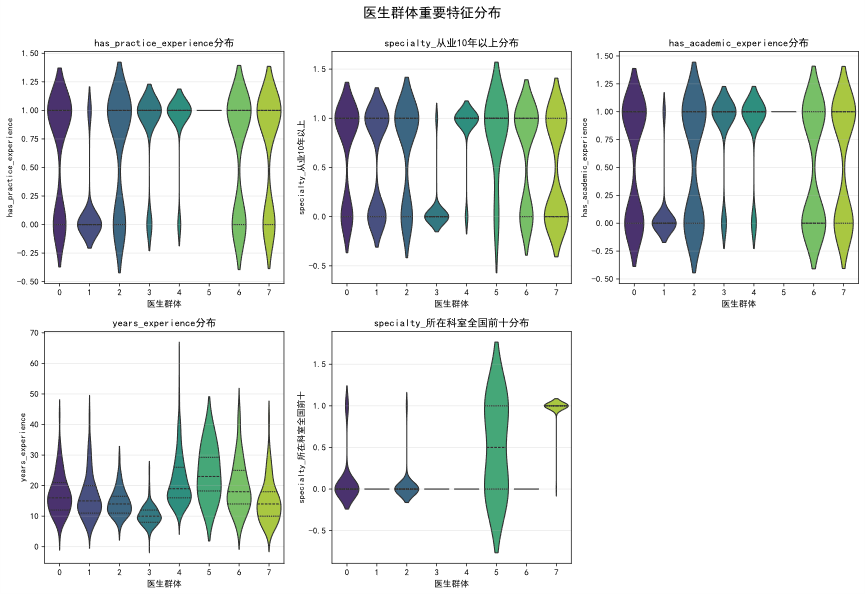
群体 5: 顶尖科室精英领袖 - 规模极小 (0.4%),拥有最高的平均从业年限(24年),在临床与学术两方面均有卓越建树,且半数任职于全国顶尖科室,代表了行业金字塔的顶端力量
群体 7: 顶尖科室核心专家 - 该群体几乎全部(99%)在全国排名前十的顶尖科室工作,平均拥有约15年经验,是国内顶级医疗机构的中坚骨干。
群体 4: 资深学术临床型领军人物 - 具备非常资深的从业经验(平均21.6年),在临床和学术领域均表现出极高的活跃度,是大型医院的学科带头人。
群体 3: 学术临床双修型中坚力量 - 作为平台规模最大的群体(26.8%),平均拥有约10年经验,是正在崛起的“青壮派”。他们在临床实践与学术研究上双线发展,代表了行业的未来潜力。
群体 6: 经验丰富的临床实干家- 拥有近20年的丰富从业经验,其职业路径更侧重于临床实践,是解决复杂临床问题的资深专家。。
群体 0 & 2: 均衡发展型医师 - 两个稳健的中坚群体,从业经验在14-17年之间,在临床与学术领域均有涉猎,但活跃度不及“双栖中坚力量”。
群体 1: 资深非一线/转型专家 - 一个庞大且特殊的群体(23.0%),虽拥有16年的资深履历,但其当前的临床和学术活跃度指标极低。这可能表明该群体成员已部分转向管理、公共卫生或相关产业领域。
4.1.3 结论与应用价值
K-Means聚类分析不仅验证了平台医生群体的内在异质性,更重要的是,它超越了单一维度的标签,识别出了具有不同职业发展路径的医生群体。例如,“双栖发展型”、“临床实践型”与“转型期专家”等画像,为平台实施人才分层运营提供了清晰的目标客群。平台可据此进行精准的资源匹配、内容合作邀约及个性化的职业发展支持。
4.2 LDA主题建模:洞察患者核心诉求
4.2.1 方法与目标
针对平台积累的海量非结构化评论文本,本研究采用潜在狄利克雷分配(Latent Dirichlet Allocation, LDA)主题建模技术。通过对分词、去停用词等预处理后的文本进行建模,旨在自动地从大规模语料中发现患者在评价医生服务时所共同关注的潜在主题结构。
4.2.2 结果与发现
通过对33个科室的评论数据进行建模与分析,我们成功提炼出四大跨科室的共性主题,这些主题共同构成了患者评价体系的核心框架
主题一:专业素养与服务态度 (Professionalism and Service Attitude)
- 核心词: “耐心”、“专业”、“详细”、“细致”、“感谢”
- 解读: 这是所有科室中最为普适和高频的主题,构成了患者满意度的基石。它表明患者不仅关注诊疗的专业性,同样高度重视医生的沟通方式和人文关怀。
主题二:情绪价值与心理慰藉 (Emotional Value and Reassurance)
- 核心词: “焦虑”、“放心”、“缓解”、“消除”、“担心”
- 解读: 此主题凸显了医生在提供情绪支持方面的关键作用。有效安抚患者及其家属的负面情绪,是医生服务价值的重要体现,尤其在精神心理科、肿瘤科等领域至关重要。
主题三:具体病症与诊疗过程 (Specific Symptoms and Diagnosis Process)
- 核心词: (高度科室相关)如儿科的“宝宝/孩子”,口腔科的“牙齿”,妇产科的“怀孕/月经”等。
- 解读: 该主题直接反映了不同科室患者群体的具体诊疗需求与关注焦点,具有高度的场景化特征。
主题四:治疗方案与后续指导 (Treatment Plans and Follow-up Guidance)
- 核心词: “情况”、“用药”、“观察”、“建议”、“效果”
- 解读: 患者非常关注医生对其病情的诊断结论、用药指导的清晰度以及后续康复或观察的明确建议,这关系到诊疗方案的执行与效果。
4.2.3 结论与价值
LDA主题分析深刻揭示,患者对在线医生的评价是一个多维度的综合考量,其不仅看重医生的“硬技能”(专业知识与诊疗水平),也同样倚重其“软技能”(沟通技巧、共情能力与情绪价值的提供)。这一核心发现为平台提供了明确的价值提升方向:
- 赋能医生培训: 可针对性地开发沟通技巧、医患关系处理等培训课程,提升医生的“软技能”。
- 优化产品设计: 可在医患沟通界面中,嵌入智能化的安抚性话术模板或病情解释辅助工具。
- 驱动内容营销: 可围绕各科室的高频病症主题,策划系列化的科普文章或短视频,精准满足用户的知识需求。
五、 监督学习:医生评分的关键驱动因素识别
5.1 研究目标
本章旨在通过构建一个高精度的机器学习模型,对医生的平均评分(average_rating)进行预测。其核心目标并非仅为预测本身,而是通过对模型的解释,识别并量化影响医生评分的关键驱动因素,从而为平台提升整体服务质量和患者满意度提供数据洞察。
5.2 建模方法与流程
本研究遵循标准的机器学习建模流程:
- 数据准备与特征工程: 该步骤与2.3节所述一致,包括数据清洗、缺失值处理、以及多维度特征的衍生与构建。
- 模型选择: 选用LightGBM模型。这是一种基于梯度提升决策树(GBDT)的高性能算法,以其高精度、高效率及对大规模表格数据的出色处理能力而著称。
- 模型训练与验证: 采用5折交叉验证(5-Fold Cross-Validation)策略。该方法将数据集随机划分为五个互斥的子集,轮流使用其中四份作为训练集,一份作为验证集。通过五轮训练和验证,可以获得对模型泛化能力的稳健评估,有效避免了单次数据集划分可能带来的偶然性。
5.3 模型性能评估
通过5折交叉验证,模型展现出卓越且稳定的预测性能:
- 核心指标:平均均方根误差(RMSE)为0.2709。在1至5分的评分体系中,这意味着模型的平均预测误差仅为0.27分,达到了较高的预测精度。
- 稳定性:RMSE的标准差仅为0.0253,表明模型在不同数据子集上的表现一致,具备良好的泛化能力
- 误差分析:模型的预测误差(残差)近似服从正态分布,且95%的预测误差落在[-0.56, 0.49]的紧凑区间内,证明模型不存在显著的系统性偏差。
相关视频
视频讲解:CatBoost、梯度提升 (XGBoost、LightGBM)心理健康数据
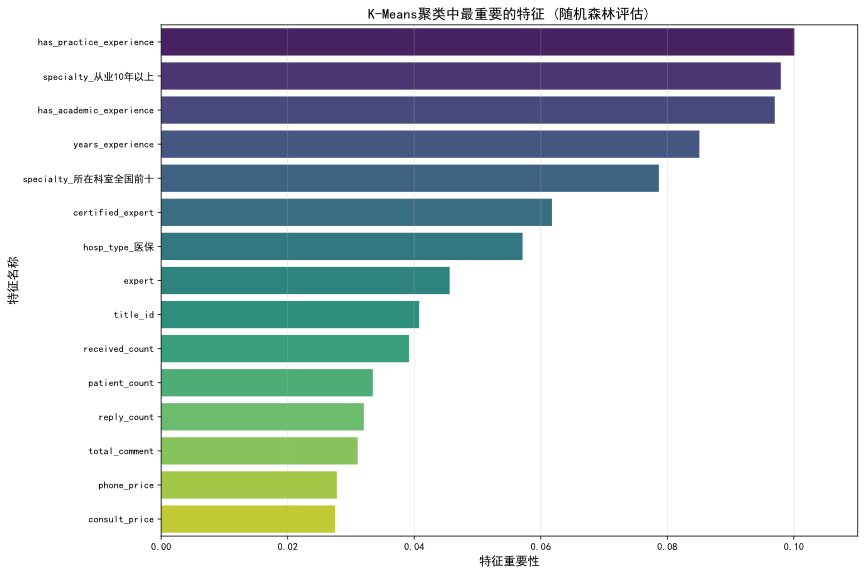
5.4 核心驱动因素分析 (特征重要性)
通过分析LightGBM模型的特征重要性,我们识别出影响医生评分的关键因素,并将其归纳为三个梯队:
第一梯队:服务体量与社会认同(核心驱动力)
star_sum (获赞总数) 和 received_count (接诊量) 等指标占据了重要性的顶端。这表明,医生的服务广度(服务了多少人)和获得的显性认可(收到了
多少赞),是其高评分的最直接体现。这揭示了一个强烈的正向反馈循环:高服务量带来高曝光和更多评价机会,而优质服务则沉淀为高赞誉,进一步巩固其高评分。
第二梯队:服务效率与专业资历(关键影响因素)
response_minutes (响应时长) 的重要性高居前列,印证了患者对于服务即时性的高度敏感。此外,years_experience (从业年限) 和 title_id (职称) 等代表医生专业深度的资历指标,也是影响评分的重要因素
第三梯队:服务价格与专业标签
服务价格、是否具备处方权以及其他专业背景标签,虽然对评分亦有影响,但其重要性次于直接反映服务过程和结果的动态指标
5.5 结论与价值
该预测模型深刻地揭示出,医生的评分并非由其静态背景(如医院、学历)单方面决定,而是由其在平台上的动态服务行为(服务体量、响应速度)和不断累积的社会认同(获赞数、评论数)共同塑造。
基于此,该模型的价值不仅在于预测新入驻医生的潜力评分,更重要的是为平台运营提供了明确的指导:
- 打破“马太效应”壁垒: 通过流量扶持等手段,给予有潜力但服务量尚小的“腰部”医生更多曝光机会,帮助其启动声誉积累的正向循环。
- 激励高效服务行为: 建立激励机制,对保持快速响应的医生给予奖励,将服务效率作为平台的核心考核指标之一。
- 引导正向互动: 优化产品设计,通过更便捷的点赞、感谢功能,鼓励用户更积极地表达其正面反馈,从而加速优质医生声誉的积累。
六、多元回归分析: 探究医生服务定价的稳健驱动因素
6.1研究目标与方法论
本章旨在通过多元线性回归模型,量化识别影响丁香医生平台图文咨询服务(consult_price)定价的关键因素。为确保模型结论的稳健性(Robustness)和可解释性(Interpretability),我们采用了严谨的建模策略:
1. 多重共线性诊断与处理:
- 首先,构建了一个包含所有潜在自变量的“全特征模型”。通过计算方差膨胀因子(VIF),我们诊断出该模型存在严重的多重共线性问题,这意味着部分自变量间高度相关,会导致回归系数的估计不稳定且难以解释。
- 为解决此问题,我们采用迭代剔除法,逐步移除VIF值最高的变量,直至所有剩余变量的VIF值均在可接受范围内。
2. 最终模型构建与评估:
基于剔除共线性后的变量集,我们构建了最终的优化回归模型。本报告的所有结论均基于此稳健模型。
模型评估:
- 整体显著性: F检验的P值(Prob (F-statistic))为 4.08e-72,远小于0.01,表明模型整体在统计上高度显著。
- 解释力度: 调整后R²(Adj. R-squared)为 0.236。这意味着模型筛选出的这组自变量能够联合解释医生服务价格中23.6%的变异,对于复杂的社会经济现象而言,这是一个具有实际意义的解释水平。
- 模型稳健性: 优化后模型的条件数(Condition No.)大幅降低,表明多重共线性问题已得到有效缓解,回归系数的估计更为稳定可靠。
6.2 核心发现:服务定价的决定因素
优化后的回归模型揭示了一套清晰且符合商业逻辑的定价体系。下述所有结论均在统计上显著(p < 0.05)。
发现一:稀缺性品牌资产是定价的“核心引擎”
- specialty_所在科室全国前十 (系数: +27.88, P<0.001): 此为模型中最强的正向影响因素。拥有“全国顶尖科室”这一稀缺品牌背书,可为医生带来近28元的显著价格溢价。
- is_municipality (直辖市,系数: +24.78, P<0.001): 地理位置的品牌效应同样显著。来自直辖市的医生,其平均定价高出近25元,反映了核心城市所带来的资源集中与品牌价值。
- hosp_type_百强医院 (系数: +22.31, P<0.001): “百强医院”的身份认证是第三大溢价因素,平均可带来22元的价格提升。
- 解读: 平台服务的最高定价能力,并非源于宽泛的标签,而是由顶尖专科声誉、核心地理位置、顶级医院品牌这三大稀缺性资产共同驱动
发现二:职称体系的相对价值被精准量化
模型以“主任医师”为参照基准,清晰地量化了不同职称等级间的价格差异:
- 职称_副主任医师 (系数: -13.34, P=0.002)
- 职称_主治医师 (系数: -32.55, P<0.001)
- 职称_医师 (系数: -41.67, P<0.001)
- 职称_主管药师 (系数: -67.43, P<0.001): 与医师群体相比,药师群体的基础定价显著偏低,符合其不同的服务范畴。
解读: 结果呈现出清晰的等级阶梯效应。相较于主任医师,职称每降低一个等级,其基础定价相应减少。特别地,药师群体的服务定价显著低于医师群体,这符合两者在服务范畴上的差异。
发现三:经验价值恒定,但医保与部分服务量指标呈负相关
- years_experience (从业年限,系数: +1.06, P<0.001): 经验的价值得到稳健验证,每增加一年从业经验,平均可带来约1元的价格提升,是定价体系的“压舱石”。
- hosp_type_医保 (系数: -12.24, P<0.001):支持医保的医生,其平均定价反而显著偏低。这可能源于医保服务更倾向于普惠性的基础医疗,而高价服务则多为市场化的自费项目。
- patient_count (患者总数,系数: -0.0023, P=0.003):在控制了口碑等因素后,服务患者数量越多的医生,其平均价格越低,这可能反映了部分医生采取“薄利多销”的运营策略以获取更大流量。
发现四:可沉淀的口碑是服务量的唯一增值项
- total_comment (总评论数,系数: +0.0058, P<0.001):在所有与服务量相关的指标中,总评论数是唯一对价格有显著正向影响的因素。这表明,相比于接诊量、服务人数等纯粹的“数量”指标,能够沉淀为公开评论的“口碑”,才是能直接转化为价格优势的宝贵数字资产。
6.3 结论与商业启示
本章通过构建一个稳健的多元回归模型,为丁香医生的服务定价策略绘制了一幅清晰的图景:
- 定价策略的金字塔模型:
塔尖由稀缺性品牌(顶尖科室/城市/医院)决定核心溢价;塔身由职称与经验构建价格阶梯;塔基则由医保属性与市场策略(口碑积累 vs. 薄利多销)进行调节。
- 可行的商业洞察:
- 精准营销:营销资源应向具备“塔尖”特征的医生倾斜,并大力宣传其稀缺性标签以支撑其高定价。
- 分层运营:识别并区分“专家型”(高口碑、高定价)与“流量型”(高服务量、低定价)医生,提供差异化的运营支持。
- 价值沟通:向平台医生清晰地传递一个信息:持续积累从业经验和患者口碑,是能够在平台上稳定实现价值增长的核心路径。
七、逻辑回归:高流量医生成功模式的解码与画像分析7.1 研究目标与升维分析策略
为深入探究平台“马太效应”背后的驱动机制,本章旨在通过逻辑回归模型,解码影响医生获取高流量(定义为平台接诊量排名前20%)的关键因素。我们采用了创新的升维分析策略:
第一层:识别普适性成功法则。
首先,构建一个基础逻辑回归模型,识别出适用于所有医生的、影响流量获取的普适性关键特征(如评分、价格、响应速度等)。
第二层:探究群体成功的差异化路径。
随后,将第四章K-Means聚类得出的八类医生画像作为虚拟变量引入模型。此举旨在进行一次升维分析,探究在控制了所有个体特征之后,医生所属的“群体画像”本身,是否对其流量获取能力具有独立的、显著的影响。
7.2 模型性能:精准识别高潜力医生
我们最终构建的逻辑回归模型表现出色。其AUC(ROC曲线下面积)值高达0.84,远超0.5的随机水平,表明模型拥有强大的区分能力,能有效识别出具备高流量潜力的医生。同时,模型通过了VIF检验与L2正则化处理,确保了结论的稳健性。
7.3 核心发现(一):高流量的普适性“成功法则”
模型首先揭示了所有医生在流量竞争中都需遵循的共性规律:
维度一:质量为王——解决问题的核心能力
- average_rating(平均评分):口碑是流量转化的基石,高评分显著提升获取高流量的概率。
- prescription_count(处方数):作为解决患者实际问题的直接体现,是预测高流量的最强正向因子。
维度二:定价有道——“冰与火”的服务模式
- consult_price(图文咨询价格):价格越低,越易获得高流量,验证了“性价比”是吸引基础流量的有效策略。
- phone_price&video_price(电话/视频价格):与图文咨询相反,更高价格的实时咨询服务与高流量正相关,这可能是头部医生进行价值变现的标志。
维度三:体验至上——不可或缺的服务细节
- response_minutes (响应时长):响应越慢,获得高流量的概率越低,证明了快速响应是在线服务的生命线。
维度四:品牌加持——“光环效应”的价值
- hosp_type_三甲医院、specialty_全国百强医院等知名医院背景,以及is_municipality (核心城市) 的地理位置,都为医生带来了显著的天然流量优势。
7.4 核心洞察(二):不同医生画像在流量竞争中的差异化表现
在控制了上述所有个体特征后,引入“医生画像”变量,得到了本次分析最深刻的洞察:
1. 流量获取的冠军画像——“均衡发展型医师”(画像2):
这是最关键的发现。在流量获取上最具潜力的,并非履历最顶尖的“精英领袖”,而是这批拥有14-17年经验、在临床与学术上均衡发展的中坚力量(优势比OR ≈ 1.72)。他们正处于知识、经验和精力的“黄金结合点”,既有足够的资历赢得患者信任,又有充足的精力投入线上服务,是平台生态中“性价比”与“可靠性”的最佳平衡。
2. 流量获取的潜力画像——“经验丰富的临床实践专家”(画像6):
这类拥有近20年经验的纯粹临床专家,其深厚的实战能力同样受到线上患者青睐(OR ≈ 1.13),代表了以极致临床实用性取胜的成功路径。
3. 面临流量挑战的画像:
- “学术临床双栖中坚力量”(画像3): 作为平台规模最大的“青壮派”(约10年经验),他们在当前流量竞争中反而处于劣势(OR ≈ 0.74)。这可能是因为其资历尚不及更资深的医生,同时双线发展可能分散了其线上服务的精力。
- “资深非一线/转型期专家”(画像1): 此类专家因其较低的临床活跃度,在以解决临床问题为核心的问诊平台上,自然不具备流量优势(OR ≈ 0.77)。
7.5结论与升维商业建议
本次分析通过结合监督与非监督学习,成功地从“特征”和“画像”两个维度解码了高流量医生的成功模式。
- 重新定义“平台明星”:平台的“流量引擎”并非传统意义上履历最顶尖的专家,而是以“均衡发展型医师”为代表的,在经验、精力、专业性、服务意愿等多个维度上达到最佳平衡点的中坚力量
- 给平台的升维运营策略——“因材施教”:
- 对画像2(均衡发展型)群体:应作为核心合作伙伴,进行重点流量扶持和资源倾斜,助其成长为平台的“超级头部”。
- 对画像3(双修型中坚力量)群体:应提供时间管理、线上运营等赋能工具与培训,助其将线下潜力高效转化为线上优势。
- 对画像6(临床实干家)群体:应在营销上突出其丰富的“临床实战经验”,形成差异化竞争优势。
- 对画像1(转型专家)群体:可探索非问诊类的合作模式,如付费科普、课程讲座等,实现其经验价值的多元化变现。。
- 构建多元化医生生态:平台不应只追求单一维度的“顶尖”,而应认识到不同画像医生的独特价值,通过差异化的运营策略,构建一个多元、健康、可持续发展的医生生态金字塔。
八、因果推断分析——服务行为对患者满意度的净效应评估
8.1 研究问题的深入:从“相关”到“因果”
在前面的章节中,我们通过探索性分析和相关性模型,初步观察到医生的服务行为(如响应速度)与患者评价之间存在关联。然而,这种关联是否等同于因果关系?即,究竟是“优秀的医生倾向于提供好服务”,还是“好服务本身造就了患者满意”?这是一个困扰平台运营的核心问题。
为回答这一问题,本章将分析层次从相关性探索提升至因果效应评估。我们旨在通过严谨的因果推断方法,剥离所有与医生背景相关的混淆因素,从而精准地量化“高水平服务行为”本身对“患者深度满意度”的净因果效应(Net Causal Effect)。
8.2 研究设计:基于倾向性评分匹配的准实验
为有效解决“选择性偏误”(即背景优秀的医生可能更倾向于提供高质量服务)这一核心挑战,本研究采用了倾向性评分匹配(Propensity Score Matching, PSM)方法。该方法旨在通过统计学手段,模拟一场“随机对照实验(RCT)”,其核心设计如下:
1. 定义处理组与对照组:
- 处理变量 (Treatment): “高水平服务行为”,操作化定义为响应时间低于样本中位数(18分钟)。提供高水平服务的医生构成处理组 (T=1)。
- 对照组 (Control): 其余提供常规服务的医生构成对照组 (T=0)。
2. 定义结果变量与混淆变量:
- 结果变量 (Outcome): “患者深度满意度”,操作化定义为更能体现超预期体验的 received_count(患者感谢数)。
- 混淆变量 (Covariates): 纳入所有可能同时影响“服务行为”和“患者满意度”的医生背景特征,如 title_id(职称)、years_experience(资历)、consult_price(价格)、以及关键的 hosp_type_三甲医院 等。
3. 匹配过程:
- 计算倾向性得分: 首先,使用逻辑回归模型,基于所有混淆变量,预测每位医生属于“处理组”的概率。这个概率即为“倾向性得分”,它综合了医生所有的背景信息。
- 实施1:1匹配: 随后,为处理组中的每一位医生,在对照组中寻找一位倾向性得分最接近的“虚拟双胞胎”。
- 构建准实验环境: 匹配完成后,我们得到了两组医生:他们在所有可观测的背景特征上(如职称、资历、是否三甲等)已无统计学差异,唯一的系统性区别仅在于一组提供了高水平服务,而另一组没有。这使得后续的比较具备了因果推断的基础。
8.3分析结果:效应的量化与显著性检验
发现一:协变量平衡性显著改善,为因果推断奠定基础
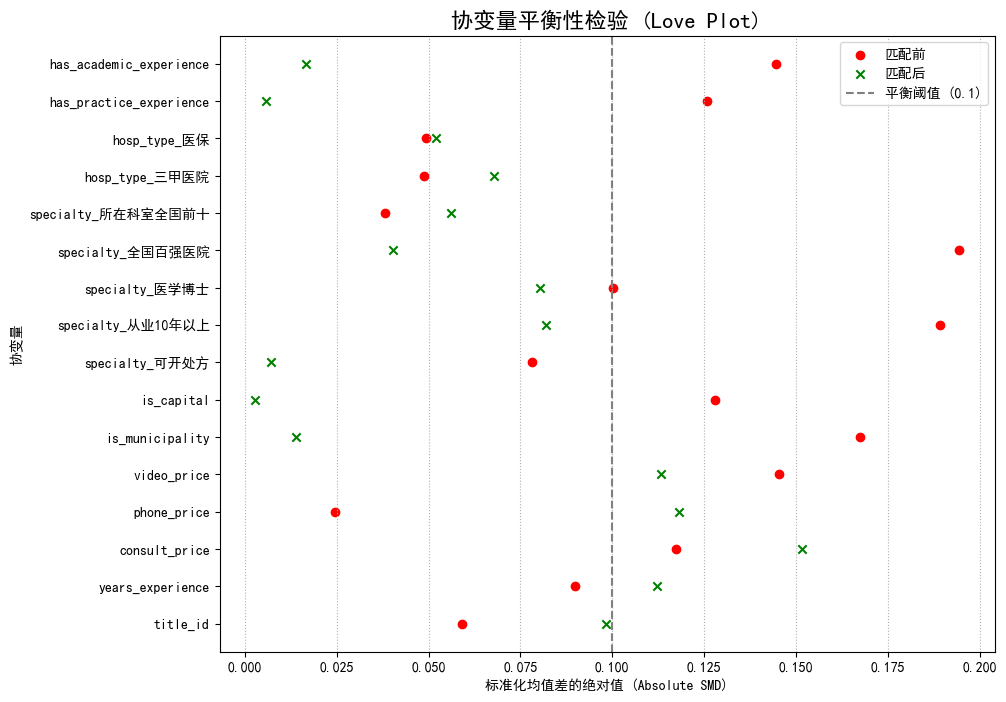
上图的平衡性检验结果(Love Plot)展示了倾向性评分匹配(PSM)在改善组间可比性方面的显著效果。
- 匹配前(红点):处理组与对照组在多数背景变量上存在巨大差异,例如has_practice_experience、specialty_从业10年以上等变量的标准化均值差(SMD)均远超0.1,表明直接比较是存在严重偏误的。
- 匹配后(绿叉):我们可以观察到,几乎所有变量的SMD值都显著地向0点靠近,大部分已落入0.1的平衡阈值以内。例如,has_practice_experience的巨大差异几乎被完全消除。这表明PSM方法成功地、大幅度地减少了由可观测的背景特征所带来的混淆偏误。
我们同样注意到,少数变量如hosp_type_医保和video_price在匹配后的SMD值虽然有所降低,但仍略高于0.1的严格阈值。这在真实世界数据的PSM分析中是常见现象,它提示我们匹配可能未能完全消除所有可观测变量的差异。然而,核心在于PSM已经将整体的组间差异从一个非常不平衡的状态,改善到了一个高度近似平衡的状态。这为我们进行下一步的因果效应评估,提供了一个远比原始数据更公平、更可靠的比较基础。
发现二: “高水平服务”的因果效应巨大且高度显著,结论稳健
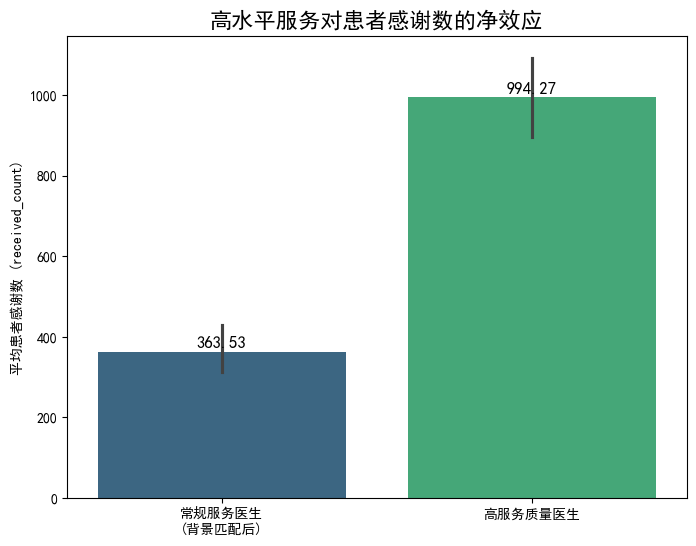 在经过PSM平衡处理后的两组医生中进行比较,结果揭示了服务行为的巨大影响力:
在经过PSM平衡处理后的两组医生中进行比较,结果揭示了服务行为的巨大影响力:
- 高服务质量组的平均患者感谢数为 994.27。
- 常规服务组的平均患者感谢数仅为 363.53。
由此计算出,高水平服务行为对患者感谢数的平均处理效应(ATT)高达 +630.74。这一效应不仅在数值上是巨大的,在统计上也极度显著(配对T检验 p-value < 0.0001)。
结论的稳健性讨论: 考虑到匹配后仍存在微小的残余不平衡,一个自然的问题是:这个巨大的效应是否会被这些微小差异所解释?答案是否定的。我们观察到的效应量(差异为630.74)是基础值(363.53)的1.7倍之多。如此巨大的效应差异,远远超过了由hosp_type_医保等变量的微小不平衡所可能带来的影响。换言之,即使考虑到这些残余偏误,它们也完全不足以推翻“服务行为是主导因素”这一核心结论。因此,我们可以满怀信心地认为,本研究的结论是稳健的(robust)。
8.4 结论与战略建议
核心结论:服务为王。 本研究通过严谨的、并经过审慎评估的因果推断分析,证实了驱动在线医疗平台患者深度满意度的根本引擎,是医生可培养、可激励的服务行为,而非其固有的身份标签。即便在考虑了匹配过程中的微小不完美后,服务行为带来的巨大积极效应依然是压倒性的和不容置疑的。
基于此结论,我们为平台提出以下三点战略建议:
1. 战略层面:重塑价值导向,从“争夺名医”到“培育优服”
- 目标: 将平台的品牌核心价值,从“我们拥有最多三甲名医”转变为“在我们的平台,您能获得最优质、最及时的医疗服务”。
- 行动:在市场宣传和品牌故事中,更多地突出平台对服务质量的保障体系,以及那些因卓越服务而备受赞誉的医生案例,无论其医院背景如何。
2. 算法与产品优化:让优质服务被看见、被奖励
- 目标: 使平台的流量分配机制成为优质服务的“放大器”。
- 行动:在推荐与搜索算法中,显著提升“响应速度”、“回复率”、“患者感谢数”等动态服务指标的权重。同时,创建并推广如“响应之星”、“服务标兵”等行为标签,使其在用户端的感知价值不亚于传统的“三甲”标签。
3. 生态建设与医生赋能:从“少数精英”到“全员优质”
- 目标: 激励并帮助平台上的每一位医生,尤其是潜力巨大的非三甲医生,提升其在线服务能力。
- 行动:设计与服务质量指标(如感谢数、响应达标率)强相关的激励体系(如流量券、现金奖励)。同时,开发赋能工具(如智能沟通模板、线上培训课程),帮助医生更高效地提供高质量服务,最终形成“平台赋能 -> 医生提效 -> 患者满意 -> 平台增长”的良性循环
九、 项目总结与展望
9.1 总体结论:构建多维度的平台生态认知
本项目通过一个系统化的数据科学流程,从数据采集与处理、多模型探索性分析,到最终的因果推断,对丁香医生平台的生态系统进行了全面而深入的剖析。研究成果不仅验证了传统认知,更揭示了许多深层次、反直觉的规律。
本研究的核心结论可归纳为一个三维度的综合模型,即一个成功的在线医生,是其“静态禀赋”(Static Endowment)、“动态行为”(Dynamic Behaviors)和“累积声誉”(Accumulated Reputation)三者相互作用、共同塑造的结果。
- 静态禀含: 以医生的职称、从业年限、医院背景(如是否三甲、百强)及地理位置为代表。这些是医生进入平台时的固有资产,共同构成了其价值基石和初始品牌认知,并在服务定价和流量的初始获取中扮演着重要角色。
- 动态行为: 以响应速度、服务价格策略(图文vs电话/视频)、是否开具处方等为代表。这些是医生在平台上的可干预、可优化的运营行为。因果分析强有力地证明,这些动态行为,特别是服务效率,是决定患者深度满意度的根本驱动力。
- 累积声誉: 以平均评分、总评论数、患者感谢数等为代表。这是医生通过其静态禀赋和动态行为,在平台上逐步积累的社会资本。监督学习模型明确指出,累积声誉反过来成为预测其未来评分和流量的最强指标,形成了一个关键的正向或负向反馈循环。
9.2 核心洞察与业务价值
本项目的系列分析,从不同角度相互印证,共同为丁香医生平台提供了具备高度可行性的商业洞察:
- 医生分层运营的画像依据:通过K-Means聚类识别出的八类医生画像,为平台提供了超越“职称”、“科室”等传统标签的多维度人才地图。结合逻辑回归的发现,平台可对“均衡发展型医师”(画像2)等高潜力群体进行精准扶持,对“转型专家”(画像1)等群体探索非问诊类合作,实现精细化、差异化的医生运营策略。
- 服务质量提升的关键抓手:LDA主题模型揭示了患者对“服务品质”与“情绪安抚”的核心诉求。评分预测模型和因果分析则进一步量化了“响应速度”和“服务互动”的极端重要性。这些发现为平台赋能医生培训、优化产品功能(如智能沟通助手)提供了明确的方向。
- 定价与流量分配的优化罗盘:多元回归模型清晰地解构了定价的“金字塔模型”,即由稀缺性品牌(顶尖科室/城市)、等级定位(职称/经验)和市场策略(医保/口碑)共同决定。逻辑回归则揭示了平台的流量密码。二者结合,为平台动态调整价格策略、优化流量分配算法、构建健康的“专家型”与“流量型”医生共存生态提供了坚实的数据基础。
- 战略方向的根本性启示:本项目最具价值的结论来自于因果分析——“服务为王,而非出身”。它明确指出,平台的长期核心竞争力,应建立在激励和培育全体医生的优质服务行为之上,而非过度依赖少数的精英身份标签。这为平台从“资源依赖型”向“服务驱动型”增长模式转型提供了战略指引。
9.3 项目创新性与未来展望
本项目的创新性体现在其分析框架的整合性与递进性。研究并非孤立地应用各类模型,而是将非监督学习(画像构建)、监督学习(因素量化)与因果推断(效应评估)有机地串联起来,形成了一个相互验证、层层深入的分析闭环。特别是将聚类画像作为特征引入监督学习模型,以及从相关性分析最终走向因果推断,体现了高阶的数据分析思维。
展望未来,本研究可在以下方向进一步深化:
- 高级因果推断应用:除PSM外,可尝试使用双重差分法(DID)或工具变量法(IV),探究平台某项运营活动(如上线新功能、进行价格补贴)对医生行为和患者满意度的真实因果效应,为运营决策提供更精准的ROI评估。
- 自然语言处理的深度融合:将LDA主题分布、情感得分等NLP特征作为变量,融入回归或分类模型中。这有望更精确地捕捉患者评论中的“软信息”,进一步提升医生评分预测或流量预测模型的精度。
- 动态时序与生命周期分析:构建基于时间的动态模型,分析医生各项指标(如服务量、评分、价格)随时间演变的轨迹。通过时序分析,可以构建医生生命周期模型,实现对医生潜力的早期预测、对流失风险的提前预警,从而进行更具前瞻性的平台管理。
综上所述,本项目不仅完成了既定研究目标,更通过严谨的分析为丁香医生平台提供了兼具战略高度与战术可行性的数据驱动决策支持,充分展现了大数据技术在赋能现代医疗健康服务领域的巨大潜力。
关于分析师

在此对 Jiasen Chen 对本文所作的贡献表示诚挚感谢,他在南京大学完成了工业工程专业的相关学业,专注深度学习、数理金融与数据采集分析领域。擅长 R 语言、Python、C++,同时在数据采集分析与深度学习应用方面具备扎实的技术能力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号