


R分布式滞后非线性模型DLNM分析某城市空气污染与健康数据:多维度可视化优化滞后效应解读
全文链接:https://tecdat.cn/?p=42940
原文出处:拓端数据部落公众号
分析师:Yangfei Chen
作为环境健康领域的研究者,我们常面对这样的现实:当某城市连续一周PM10浓度偏高后,呼吸系统疾病就诊量在随后几天逐渐上升——这种“污染当下不显,影响滞后显现”的现象,正是公共卫生研究的核心难题。早在上世纪90年代,研究者就发现空气污染对健康的影响并非即时消散,而是存在滞后效应,且这种效应还可能随时间呈现非线性变化。比如,低温对心血管疾病的影响可能在3天后达到峰值,而PM10的危害可能持续一周以上。
为解开这种复杂关系,分布式滞后非线性模型(DLNM)应运而生。它既能捕捉暴露因素(如PM10)与健康结局(如死亡)的非线性关联,又能刻画这种关联随时间的滞后模式,逐渐成为环境流行病学的“利器”。
全文将从工具准备讲起,带大家用R语言的dlnm包一步步实现模型构建,再通过多种可视化方法解读结果——从整体效应曲线到三维曲面图,让抽象的滞后效应变得直观。无论你是刚接触数据分析的学生,还是需要解决实际问题的研究者,都能从中找到可用的方法。
专题项目文件(报告代码PPT)已分享在交流社群,阅读原文进群和500+行业人士共同交流和成长。
一、环境准备:从工具安装到镜像选择
当我们想探究空气污染如何在 days 后影响健康时,首先得搭好“工作台”。R语言作为数据分析的强大工具,搭配RStudio的可视化界面,能让整个分析过程更顺畅。
1.1 R与RStudio的安装技巧
安装R时,直接从官网下载常因服务器在国外而速度缓慢。我们可以选择国内的清华镜像站(https://mirrors.tuna.tsinghua.edu.cn/CRAN/),不仅下载快,还能避免因网络问题导致的安装失败。具体步骤可参考相关教程,但记住一个关键点:安装路径里别出现中文,否则可能出现奇怪的错误。
RStudio的安装更简单,直接用电脑自带的应用商店就行。安装完成后首次打开,它会让你选择关联的R版本,选刚装的64位版本就好。打开后,左边的console窗口就是我们写代码的地方,像个随时待命的助手。
二、核心工具与数据:包的导入与数据初探
有了工具,还得备好“材料”——分析用的包和数据。
2.1 关键包的安装与加载
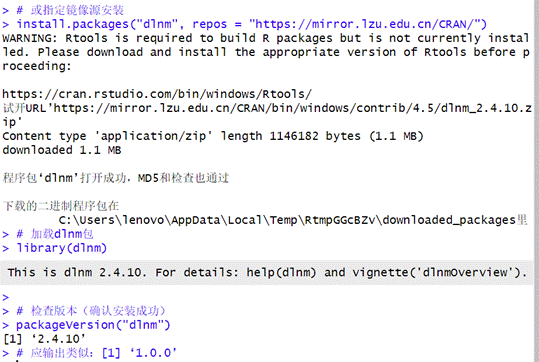
分布式滞后非线性模型的核心包是dlnm,它能帮我们构建暴露因素与滞后时间的交叉关系。另外,处理时间序列需要tsModel包,拟合平滑曲线需要splines包。安装dlnm时,在console里输入安装命令,看到类似下图的提示,就说明安装成功了。
每次打开RStudio,都要加载这些包才能用它们的功能,就像用工具前先把它们从抽屉里拿出来:
2.2 数据长什么样?
我们用的是某城市的空气污染与健康数据,包含日期、死亡数、PM10浓度、温度等信息。加载数据后,用head()函数看看前6行,能快速了解数据结构:
-
# 加载内置的某城市数据集
-
data(cityHealthData)
-
# 查看前6行数据
-
head(cityHealthData)
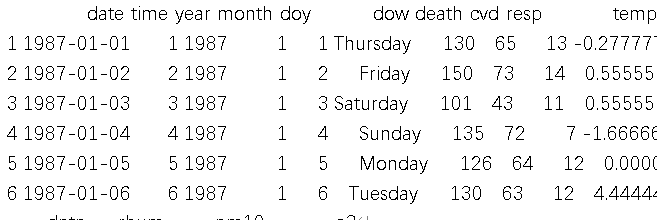
结果里,date是日期,death是每日死亡数,pm10是可吸入颗粒物浓度,temp是温度。从数据能看出,PM10浓度有时会出现NA(缺失值),这在实际数据中很常见,后续分析得注意处理。
三、DLNM建模:如何捕捉“滞后”的影响?
假设我们想知道PM10浓度从当天到第7天(滞后0-7天)对死亡数的影响,DLNM能帮我们把这种“随时间变化的关联”刻画出来。
3.1 构建交叉基矩阵
交叉基矩阵是DLNM的核心,它能同时处理PM10的非线性效应和滞后效应。我们让PM10的暴露-反应关系为线性(fun = “lin”),滞后模式用3个自由度的自然样条(df = 3)描述:
-
# 创建PM10滞后0-7天的交叉基矩阵
-
cb_pm <- crossbasis(cityHealthData$pm10,
-
lag = 7,
-
argvar = list(fun = "lin"),
-
arglag = list(fun = "ns", df = 3))
3.2 拟合模型:控制“干扰因素”
死亡数还可能受温度、时间趋势影响(比如冬天死亡数通常更高),所以建模时得把这些“干扰因素”加进去。我们用准泊松回归(quasipoisson),因为死亡数是计数数据:
-
# 生成时间序列变量
-
time_seq <- seq(nrow(cityHealthData))
-
# 拟合模型,控制温度和时间趋势
-
model <- glm(death ~ cb_pm + ns(temp, 3) + ns(time_seq, 8*14),
-
family = quasipoisson,
-
data = cityHealthData)
这里,ns(temp, 3)用3个自由度的样条函数处理温度的非线性影响,ns(time_seq, 8*14)则控制时间趋势(每年8个自由度,共14年)。
3.3 初步可视化:整体效应与等高线
模型建好后,我们可以预测不同PM10浓度下的相对风险(RR),并画图看看:
-
# 预测PM10浓度0-30μg/m³时的风险
-
pred <- crosspred(cb_pm, model, at = 0:30)
-
# 画整体效应图(累积滞后0-7天的总效应)
-
plot(pred, "overall", xlab = "PM10 (μg/m³)", ylab = "RR")
-
# 画等高线图(展示暴露水平和滞后时间的联合影响)
-
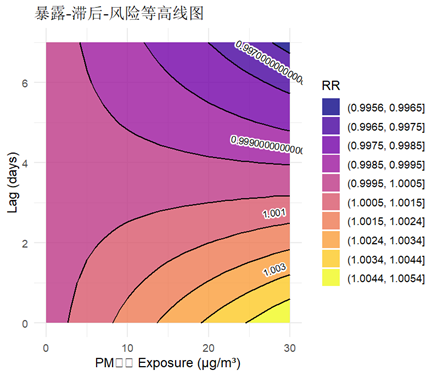
plot(pred, "contour", key.title = title("RR"))
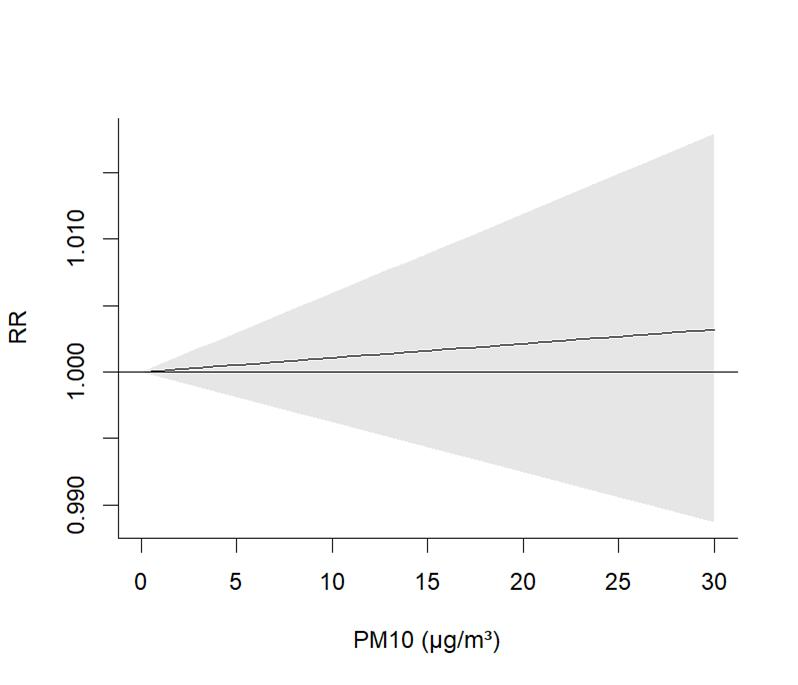
整体效应图显示,随着PM10浓度升高,RR值上升,说明PM10浓度越高,死亡风险越大。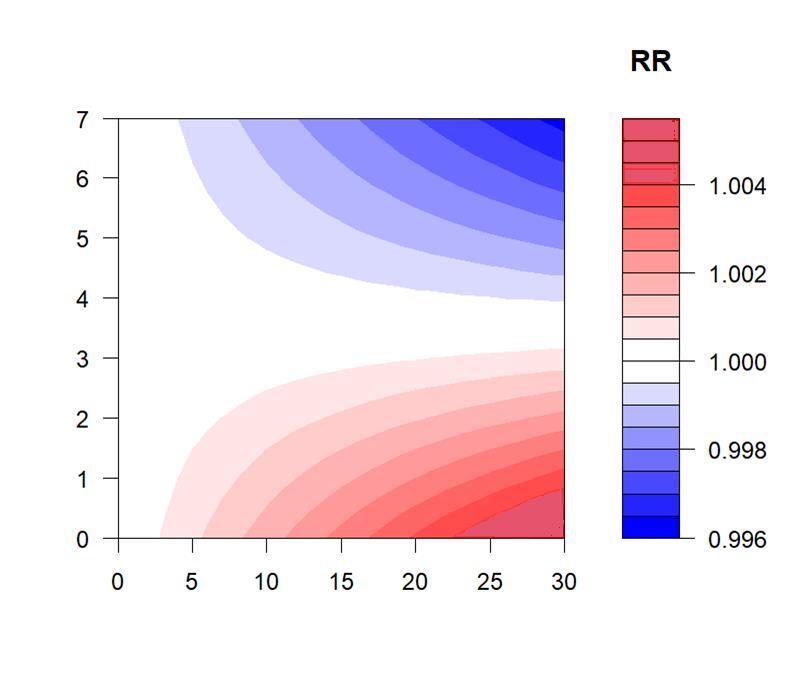
等高线图里,颜色越深表示RR越高,能看出在滞后2-3天左右,PM10的影响可能更明显。
四、多维度可视化:让滞后效应“看得见”
光看整体效应还不够,我们可以从更多角度解读,就像用不同镜头拍同一物体,看得更清楚。
4.1 三维曲面图:暴露、滞后与风险的“立体关系”
用plotly包画三维图,能直观看到PM10浓度、滞后时间和RR的关系:
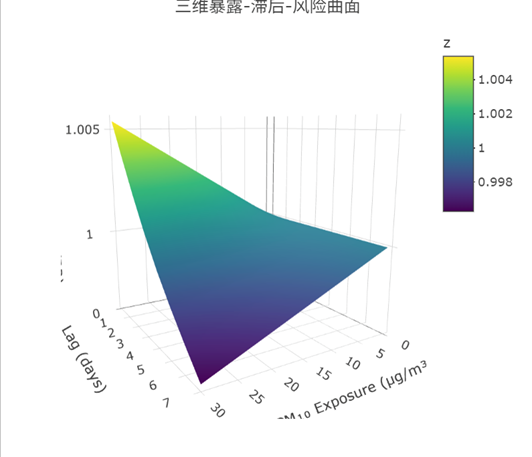
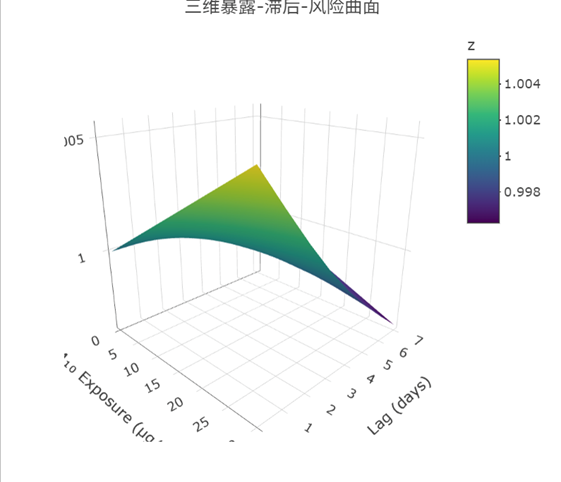
从图中能发现,滞后3天时,PM10浓度升高带来的RR上升更显著,这比单纯看数字更直观。
4.2 切片图:固定一个变量看变化
- 固定滞后时间看暴露影响:比如比较滞后0天、3天、7天的暴露-反应曲线:
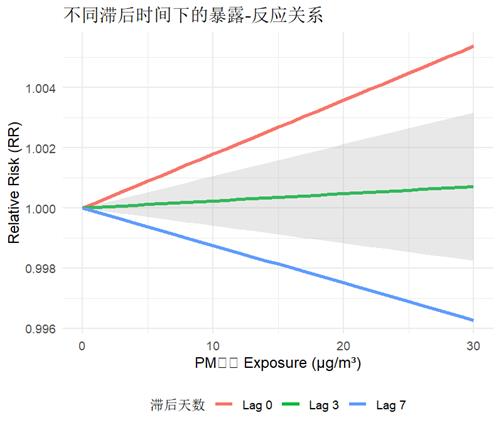
图中滞后3天的曲线斜率更大,说明此时PM10对死亡的影响更强。
- 固定暴露水平看滞后模式:比如看PM10浓度为10、20、30μg/m³时,滞后效应如何变化:
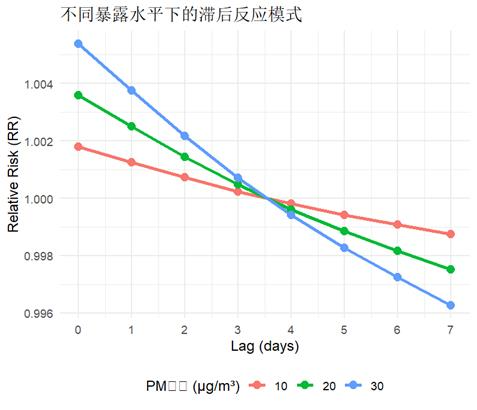
能看出浓度越高,滞后3天左右的RR峰值也越高。
4.3 累积效应曲线:总影响有多大?
把滞后0-7天的效应加起来,就是累积效应,能告诉我们PM10的总影响:
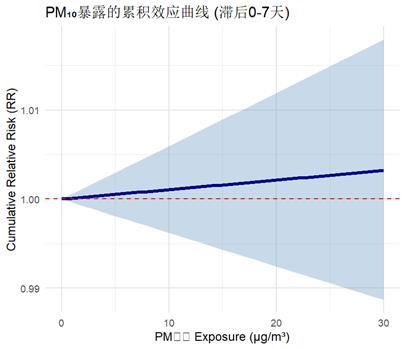
红色虚线以上的部分,说明PM10浓度升高会增加死亡风险。
五、数据导入进阶:怎么用好自己的CSV数据?
实际分析中,我们常需要用自己收集的数据(比如某城市的监测数据),这里分享两种导入CSV文件的方法。
5.1 用代码导入(适合有基础的用户)
用readr包的read_csv函数,能灵活处理中文和缺失值:
-
# 安装并加载readr包
-
install.packages("readr")
-
library(readr)
-
# 导入CSV文件
-
my_data <- read_csv(
-
"某城市数据.csv",
-
col_names = TRUE, # 第一行作为列名
-
na = c("", "NA", "无数据"), # 把空值、NA、无数据都视为缺失值
-
locale = locale(encoding = "UTF-8"), # 处理中文
-
skip = 1 # 跳过第一行(如果有多余标题)
-
)
5.2 用RStudio界面导入(适合初学者)
- 在RStudio右下角“Environment”面板点“Import Dataset”→“From Text (readr)…”
- 找到你的CSV文件,预览时检查:分隔符是不是逗号,首行是不是列名,编码选UTF-8(中文)
- 点“Import”,RStudio会自动生成代码,数据就导入成功了
结语
从工具准备到模型构建,再到用多种图表“拆解”滞后效应,我们一步步揭开了空气污染对健康影响的“时间密码”。DLNM的价值,就在于它能帮我们看清那些“看不见的延迟影响”——这不仅对学术研究重要,对制定空气污染防控政策也同样关键。比如,当我们知道PM10的滞后3天影响最大,就可以在污染高峰后3天加强医疗资源调配,减少健康损失。
希望这篇文章能让你对分布式滞后非线性模型有更清晰的认识,下次处理类似数据时,不妨试试用这些方法,或许会有新的发现。
关于分析师
在此对 Yangfei Chen 对本文所作的贡献表示诚挚感谢,她在武汉大学完成了通信工程专业的学习,专注深度学习与数据采集领域。擅长 Python、数据采集、深度学习。她在数据采集与深度学习应用方面拥有扎实的技术积累,尤其在利用 Python 进行数据获取与处理、构建深度学习模型解决实际问题等方面具备丰富经验,能够为相关项目提供专业的技术支持与分析思路。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号