BUAA OO 2022 第一单元
hw1:
由于第一次作业并且没有适应java的面向对象编程的思想,所以感觉写出来的代码完全是面向过程式编程。
类图描述:
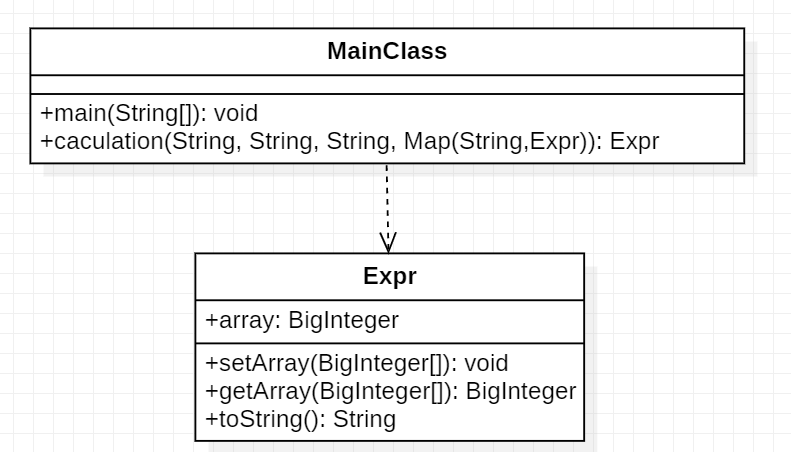
优缺点分析:
- 缺点:
- 内聚和耦合性并不是很强,MainClass不应该作为Exp的直接使用者。应该再实例化一个化简类,并且把
caculation这个计算的方法放到化简类里面。 - 它的缺点是没有面向对象易维护、易复用、易扩展。
- 内聚和耦合性并不是很强,MainClass不应该作为Exp的直接使用者。应该再实例化一个化简类,并且把
- 优点:
- 在性能方面比面向对象要高,但是因为类调用时需要实例化,其开销比较大,也比较消耗资源;
代码规模分析:
| Source File | Total Lines | Source Code Lines | Source Code Lines[%] | Comment Lines | Comment Lines[%] | Blank Lines | Blank Lines[%] |
|---|---|---|---|---|---|---|---|
| Main.java | 127 | 124 | 0.9763779527559056 | 0 | 0.0 | 3 | 0.023622047244094488 |
| Expr.java | 103 | 93 | 0.9029126213592233 | 2 | 0.019417475728155338 | 8 | 0.07766990291262135 |
方法复杂度分析:
| method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| Main.caculate(String, String, String, Map) | 23.0 | 1.0 | 10.0 | 14.0 |
| Main.main(String[]) | 16.0 | 1.0 | 9.0 | 9.0 |
| Expr.getArray() | 0.0 | 1.0 | 1.0 | 1.0 |
| Expr.Expr(BigInteger[]) | 1.0 | 1.0 | 2.0 | 2.0 |
| Expr.Expr(String, int) | 8.0 | 1.0 | 3.0 | 4.0 |
| Expr.setArray(BigInteger[]) | 0.0 | 1.0 | 1.0 | 1.0 |
| Expr.toString() | 24.0 | 5.0 | 13.0 | 14.0 |
| Total | 72.0 | 11.0 | 39.0 | 45.0 |
| Average | 10.285714285714286 | 1.5714285714285714 | 5.571428571428571 | 6.428571428571429 |
类复杂度分析:
| class | OCvag | OCmax | WMC |
|---|---|---|---|
| Main | 12.0 | 15.0 | 24.0 |
| Expr | 4.0 | 12.0 | 20.0 |
| Average | 6.285714285714286 | 13.5 | 22.0 |
-
仅有的两个类的OCvag都出现了爆红,可见面向过程的编程思想无论是代码量,还是类复杂度都较高。
-
内聚性和耦合性由于本次作业没有面向对象式编程,尤其是内聚性比较差。
第一次作业由于采用了预解析模式,并且没有面向对象编程的思想。在这里就不过多分析,将着重分析后面后面的两次作业,即采用递归下降法的架构设计以及类和方法的复杂度。
hw2:
由于在设计hw2时,我把expr作为了三角函数的属性,所以在hw3中,sin(expr)形式的输入便可很轻松的化简。并且因为parse函数有着天然嵌套层次,自定义函数的嵌套也很容易便可实现。
因此我的hw2和hw3的架构与代码内容基本一致,仅仅是对输出格式进行了细微的调整。因此,我将在hw3中进行进一步的分析,在这里便不进行多余的阐述。
hw3:
类图描述:
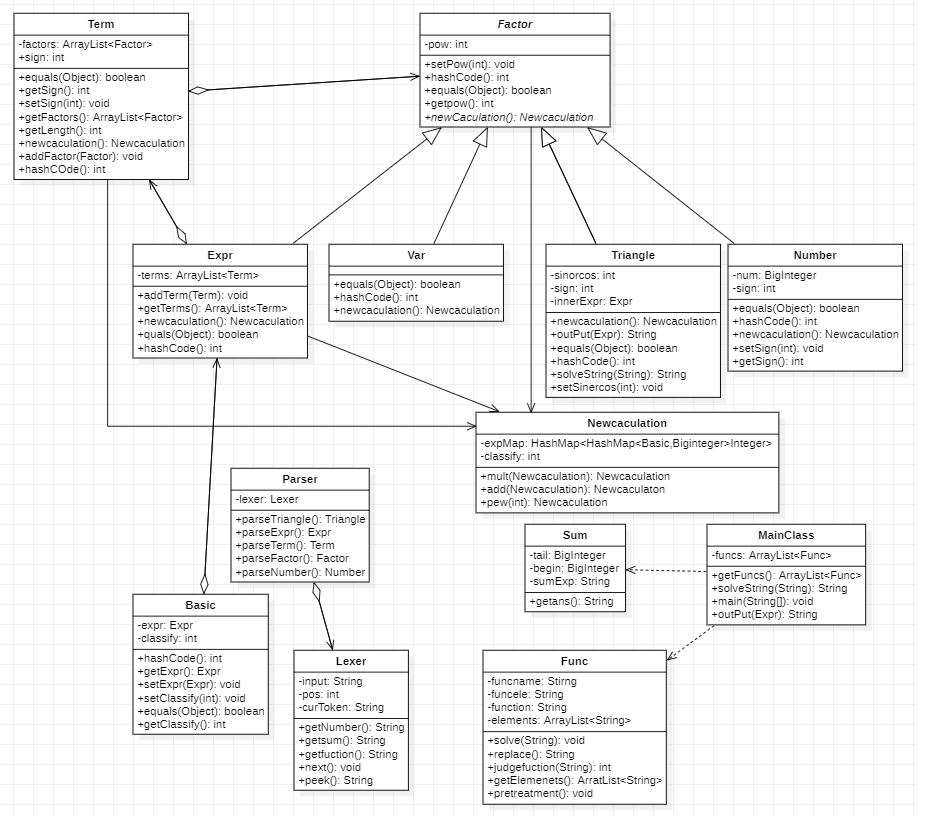
优缺点分析:
- 优点:
- 存储类的数据类型选取合适:重写各种类的
Hashcode和equals方法,使合并同类项较为简单。 - 选用
hashmap嵌套的数据结构,Newcaculation方法和output方法以及实现各种运算都可以放到一个类里面。 - 把
expr作为factor的属性之一,形成了天然的递归结构,在实现嵌套表达式因子的时候十分方便。并且传入的是最简形式的expr,这样就不用考虑嵌套形式内层的化简的,表达式树天然的递归层次可以帮助实现这一点。 - 在解析
Number类的时候,把Number作为第一层HashMap的value,这样就不用考虑常数项的同类型合并。
- 存储类的数据类型选取合适:重写各种类的
- 缺点:
- 在
MainClass类里面,插入了outPut函数以及getFuncs函数。在现在看来,这样的写法不够高内聚与低耦合,写起来十分不优雅,使MainClass类看上去有些臃肿。应该把他们放到相应的类里面。 - 没有把
sum类和function类作为因子,而作为一个单独的处理方法,我觉得这里还可以再优化一下,以降低代码的复杂度,提升代码的内聚性。
- 在
代码规模分析:
| Source File | Total Lines | Source Code Lines | Source Code Lines[%] | Comment Lines | Comment Lines[%] | Blank Lines | Blank Lines[%] |
|---|---|---|---|---|---|---|---|
| Basic.java | 49 | 37 | 0.7551020408163265 | 1 | 0.02040816326530612 | 11 | 0.22448979591836735 |
| Expr.java | 55 | 47 | 0.8545454545454545 | 0 | 0.0 | 8 | 0.14545454545454545 |
| Factor.java | 34 | 27 | 0.7941176470588235 | 0 | 0.0 | 7 | 0.20588235294117646 |
| Func.java | 101 | 85 | 0.8415841584158416 | 6 | 0.0594059405940594 | 10 | 0.09900990099009901 |
| Lexer.java | 83 | 76 | 0.9156626506024096 | 0 | 0.0 | 7 | 0.08433734939759036 |
| MainClass.java | 129 | 118 | 0.9147286821705426 | 2 | 0.015503875968992248 | 9 | 0.06976744186046512 |
| Newcaculation.java | 102 | 81 | 0.7941176470588235 | 9 | 0.08823529411764706 | 12 | 0.11764705882352941 |
| Number.java | 59 | 48 | 0.8135593220338984 | 1 | 0.01694915254237288 | 10 | 0.1694915254237288 |
| Parser.java | 161 | 147 | 0.9130434782608695 | 2 | 0.012422360248447204 | 12 | 0.07453416149068323 |
| Sum.java | 66 | 59 | 0.8939393939393939 | 3 | 0.045454545454545456 | 4 | 0.06060606060606061 |
| Term.java | 79 | 64 | 0.810126582278481 | 1 | 0.012658227848101266 | 14 | 0.17721518987341772 |
| Triangle.java | 172 | 158 | 0.9186046511627907 | 4 | 0.023255813953488372 | 10 | 0.05813953488372093 |
| Var.java | 47 | 39 | 0.8297872340425532 | 1 | 0.02127659574468085 | 7 | 0.14893617021276595 |
| Total: | 1137 | 986 | 0.8671943711521548 | 30 | 0.026385224274406333 | 121 | 0.10642040457343888 |
- 代码总行数并不算多。相对于hw2甚至变少。因为在hw3的时候只在hw2的基础上添加一个新的方法,便可以实现自定义函数的嵌套,并且对于hw2的冗余部分实现了一些合并与提取。没有涉及大规模的重构。
ExprFactor中的printCoef由于要判断项前系数省略,逻辑较为繁琐;Operation中的unpack由于要判断三角函数内因子的类型和状态判断是否可以拆包展开,逻辑较为繁琐;Parser中的parserFactor由于运用了工厂模式,需要判断因子的类型,逻辑较为繁琐;TriFactor中的toString由于承担了将sin(0), cos(0)化为常数的功能,逻辑较为复杂;- 相比之下,用于表达式解析的Parser类和Lexer类代码量较多,显得较为臃肿,而其他关于表达式架构存储的类规模较为均衡]
- 后续两次作业圈复杂度较高的情况也出现在
toString方法的分类讨论和运算器类需要处理多个Factor接口实现类的分类讨论中,就不一一分析。 - 由于
ExprFactor和Term承载了表达式化简的大部分功能,因此复杂度较高。Function则是由于代值时逻辑较为复杂,导致复杂度较高。
方法复杂度分析:
截取了部分爆红的方法进行分析。
| method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| expr.Term.hashCode() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Basic.Basic(int, Expr) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Basic.equals(Object) | 4.0 | 3.0 | 3.0 | 5.0 |
| expr.Basic.getClassify() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Basic.getExpr() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Basic.hashCode() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Basic.setClassify(int) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Basic.setExpr(Expr) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Expr.addTerm(Term) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Expr.equals(Object) | 4.0 | 4.0 | 2.0 | 5.0 |
| expr.Expr.Expr() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Expr.getTerms() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Expr.hashCode() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Expr.newcaculation() | 2.0 | 1.0 | 3.0 | 3.0 |
| expr.Factor.equals(Object) | 3.0 | 3.0 | 2.0 | 4.0 |
| expr.Factor.getPow() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Func.Func(String, String) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Func.getElements() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Func.judgefunction(String) | 2.0 | 2.0 | 1.0 | 2.0 |
| expr.Func.pretreatment() | 4.0 | 1.0 | 5.0 | 5.0 |
| expr.Func.replace() | 7.0 | 1.0 | 6.0 | 6.0 |
| expr.Func.solve(String) | 19.0 | 8.0 | 8.0 | 9.0 |
| expr.Newcaculation.add(Newcaculation, Newcaculation) | 4.0 | 1.0 | 3.0 | 3.0 |
| expr.Term.newcaculation() | 6.0 | 2.0 | 5.0 | 5.0 |
| expr.Term.setSign(int) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Term.Term() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Triangle.equals(Object) | 5.0 | 4.0 | 4.0 | 7.0 |
| expr.Triangle.hashCode() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Triangle.newcaculation() | 25.0 | 7.0 | 13.0 | 15.0 |
| expr.Triangle.setSinorcos(int) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Triangle.sovleString(String) | 2.0 | 1.0 | 4.0 | 4.0 |
| expr.Triangle.Triangle(Expr) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Var.equals(Object) | 4.0 | 4.0 | 2.0 | 5.0 |
| expr.Var.hashCode() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Var.newcaculation() | 3.0 | 1.0 | 3.0 | 3.0 |
| Lexer.getfunction() | 4.0 | 1.0 | 3.0 | 4.0 |
| Lexer.getNumber() | 2.0 | 1.0 | 3.0 | 3.0 |
| Lexer.getsum() | 4.0 | 1.0 | 3.0 | 4.0 |
| Lexer.Lexer(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Lexer.next() | 9.0 | 2.0 | 7.0 | 8.0 |
| Lexer.peek() | 0.0 | 1.0 | 1.0 | 1.0 |
| MainClass.getFuncs() | 0.0 | 1.0 | 1.0 | 1.0 |
| MainClass.main(String[]) | 1.0 | 1.0 | 2.0 | 2.0 |
| MainClass.outPut(Expr) | 58.0 | 4.0 | 20.0 | 22.0 |
| MainClass.setFuncs(ArrayList) | 0.0 | 1.0 | 1.0 | 1.0 |
| MainClass.sovleString(String) | 2.0 | 1.0 | 4.0 | 4.0 |
| Parser.outPut(Expr) | 58.0 | 4.0 | 20.0 | 22.0 |
| Parser.parseExpr() | 8.0 | 1.0 | 7.0 | 7.0 |
| Parser.parseFactor() | 26.0 | 10.0 | 19.0 | 19.0 |
| Parser.parseNumber() | 1.0 | 1.0 | 2.0 | 2.0 |
| Parser.Parser(Lexer) | 0.0 | 1.0 | 1.0 | 1.0 |
| Parser.parseTerm() | 1.0 | 1.0 | 2.0 | 2.0 |
| Parser.parseTriangle() | 4.0 | 1.0 | 3.0 | 4.0 |
| Parser.pre(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Parser.sovleString(String) | 2.0 | 1.0 | 4.0 | 4.0 |
| Average | 4.846153846153846 | 1.7307692307692308 | 3.230769230769231 | 3.6666666666666665 |
-
整体来看,用于表达式解析的
Parser类和MainClass类,以及Newcaculation类方法复杂度较高,显得较为臃肿,其他类的方法复杂度较为合理。 -
paser类中,调用了output函数,由于output函数没有使用递归的输出的方法,并且还有部分优化,所以这部分代码复杂度较高也是意料之中的。 -
MainClass类中,定义了output函数,现在想一下觉得这样的设计不是很合理,output函数应该放到每个表达式树里面,这样代码量可能会更少,复杂度也会下降。 -
在
Newcaculation类中,有着所有化简的add,mult,pow以及合并同类项还有化简的方法,通过阅读别人的代码发现,其实这些可以分散到不同的类中,这样debug和实现起来可能更加轻松一点。
类复杂度分析:
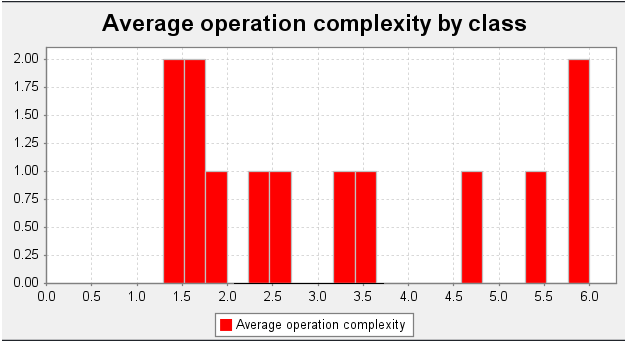
| class | OCvag | OCmax | WMC |
|---|---|---|---|
| expr.Basic | 1.2857142857142858 | 3.0 | 9.0 |
| expr.Expr | 1.8333333333333333 | 4.0 | 11.0 |
| expr.Factor | 1.5 | 3.0 | 6.0 |
| expr.Func | 3.5 | 8.0 | 21.0 |
| expr.Newcaculation | 2.25 | 6.0 | 18.0 |
| expr.Number | 1.6666666666666667 | 4.0 | 10.0 |
| expr.Sum | 6.0 | 8.0 | 12.0 |
| expr.Term | 1.6666666666666667 | 5.0 | 15.0 |
| expr.Triangle | 5.857142857142857 | 17.0 | 41.0 |
| expr.Var | 2.6666666666666665 | 4.0 | 8.0 |
| Lexer | 3.3333333333333335 | 8.0 | 20.0 |
| MainClass | 4.6 | 17.0 | 23.0 |
| Parser | 5.444444444444445 | 17.0 | 49.0 |
| Average | 3.1153846153846154 | 8.0 | 18.692307692307693 |
-
OCvag:Average operation complexity 平均操作复杂度OCmax:Maximum operation complexity 最大操作复杂度WMC:Weighted method complexity 加权方法复杂度 -
在这里,
expr.Triangle类的复杂度较高。这也是意料之中的,因为我在expr.Triangle里面调用了output函数,并且将输出的结果作为Triangle的属性。 -
同样,
Parser类中由于新添了parser.sum,parser.function,parser.Triangle等方法,使parser的类复杂度较高。
内聚性与耦合性分析:
-
整体来看,各个类的内聚性还是比较强的,比如:
Expr Factor Triangle Terms等类。各自封装了各自的方法和属性,互相之间形成了相互调用的关系,最终从底层回到上层,形成了递归的抽象层次,构建了一棵表达式树。 -
由于
Fuction和Sum类没有作为Factor的一种,导致这两个类无论是方法复杂度还是内聚性,耦合性都比较差。并且在MainClass里面实现了本该由Fuction类实现的方法,导致耦合度较高,内聚性较低,这是本次代码的一个缺陷。 -
对于上述
expr.Triangle问题的解决方法是可以在parser类中,把一个解析好的表达式传进来,这样会更加高内聚低耦合一些。
就不需要再把expr传入Triangle之后在再进行解析等操作了。
架构设计体验:
在做hw2时,设计了一个相对可拓展性较高的架构。并且在hw3时,依然可以使用。
- 对于每一种函数(常数、幂函数、三角函数、求和函数、自定义函数),分别建立类。
- 对于各种运算,
mult add pow将其封装在Caculation的方法类里面。 - 对于自定义函数,可以先将其
定义表达式展开,将展开后的结果进行解析并且进行化简。
于是我一共设计了 factor Trianglr expr Var Number function sum 作为基准类。
关键部分设计分享:
- 化简:
- 在化简的时候,主要解决的就是同类项的合并问题。我通过在乘法时判断内层HashMap的key值是否相同来进行合并,如果相同,则指数相加,否则将其作为Factor添加到ArrayList<Factors>里面作为新的一项。
- 对于嵌套的化简,我将expr作为每个Factor的属性,直接将化简后的expr传入到Factor里面,这样就形成了一种递归的层次,关于内层的化简就交给表达式树去处理。
- 在处理三角函数时,如果三角函数的
innerexpr有且仅有一个Term与一个Factor,就说明不需要加内层的括号。否则需要写成sin(())的形式。
- 嵌套自定义函数:
- 在处理嵌套自定义函数时,采用局部替换的方法,并且每次仅仅替换最外面一层,内层的自定义函数会自动以递归的方式进行解析。
- 关于多余的加减号与指数:
- 在
parseTerm与Parseexpr的如果遇到正负号,就调用setsign()函数,调整函数相应的符号。具体在计算式,就让外层HashMap的value乘上sign,来改变符号。 - 在解析完这个表达式后,判断后面是否有两个连续的*,如果有的话,读取指数,并调用
setpow()方法。在计算时,用Caculation类里面的power计算方法,这个计算方法仅需要调用我们在前面提到的乘法即可。
- 在
Bug分析:
hw1:
- 公测未发现bug。
- 互测由于在for循环中,将
i<=8写成了i<8,导致x**8的结果输出错误。
hw2:
- 公测中未发现bug。
- 互测中的bug主要存在与两个方面:
- 当Hashmap的key值是自定义类型的时候,一定要给这个自定义类型重写
hashcode和equals方法。我因为没写这个Number类的方法,导致sin(1)*sin(2)的输出结果会将二者当成一样的项合并起来,输出sin(1)**2 - 优化时的bug。笔者在优化sin(x)里面的符号时,在遇到偶次幂的时候也把符号提了出来,导致
sin(-1)**2的输出结果会是sin(1)**2。
- 当Hashmap的key值是自定义类型的时候,一定要给这个自定义类型重写
hw3:
- 公测中未发现bug。
- 互测中出现bug因为未考虑所有的边界情况。如果遇到
sin(0)**0的输入会导致输出错误。
对比:
- 产生bug的原因主要还是因为自己在课下的代码架构不够合理,对于java里面的hashcode和equals方法没并且未充分构造数据。可以看到,
Hack策略:
-
针对输入特殊格式进行测试。比如:空格与Tab,以及
+00 +001等特殊的输入情况进行Hack -
尝试“边界数据”,测试对方使用的数据类型是否合理。比如是否会超过
int的范围,long long类型是否真的符合作业要求。 -
结合自己debug的时候发现的bug进行hack,比如
sin(-1)**2与sin(sin(sin(-1)))等等 。 -
尝试阅读对方代码,尤其是遇到优化的部分,或者方法和复杂度较高,代码量较大的类时,需要整体性的分析,充分构造相应案例来进行hack。
-
结合上述几种情况,采用黑盒测试,随机轰炸。
心得体会:
- 这次作业真的难度算是比较高了,尤其是第一周,感觉跨度很大。每次想开始写代码总是有种力不从心,无从下手的感觉,于是第一周就反复在pre和作业中横跳(因为觉得pre没学好),最后周五晚上才开始写。多亏了两个室友和助教的支持与帮助,还有讨论区积极分享设计经验的同学门。CS的道路上一个人真的寸步难行......
- 对于面向对象有了进一步的理解。老师在课上反复强调,一定要改变过程式编程的思维。我的理解大概就是通过java的层次结构以及多态等机制。层次结构有数据抽象层次结构与行为抽象层次结构。比如这次作业就诠释了递归层次结构在面向对象编程里面的重要性。
- 仔细阅读指导书并且注重代码风格的要求。无论是现在的作业还是以后的工程项目,都需要先分析好需求,若没有耐心急于直接写代码可能会忽略掉一些关键细节甚至导致整个代码项目的重构。
- 好的架构相当重要,这里想起了gxp老师去年机组课上说的加速性回报。在面向对象编程的时候,一定要先有一个整体的架构框架,动手之前的思考往往决定着作业的质量与耗时。第三次本次作业因为在设计时考虑到了相对完整的架构而避开了重构。
- 最后,可变对象与不可变对象、各种设计模式、各种方法的重写,java多态机制的应用等等……依然需要后续练习中进一步体会才能有更深的理解。希望能在老师、助教和同学的帮助下更上一层楼。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号