5.内存映射
C标准库提供了mmap函数建立映射。在内核一端,提供了两个系统调用mmap和mmap2。两个函数的参数相同。
asmlinkage unsigned long sys_mmap{2}(unsigned long addr, unsigned long len,unsigned long prot, unsigned long flags,unsigned long fd, unsigned long off)
这两个调用都会在用户虚拟地址空间中的pos位置,建立一个长度为len的映射,其访问权限通过prot定义。flags是一个标志集,用于设置一些参数。相关的文件通过其文件描述符fd标识。
mmap和mmap2之间的差别在于偏移量的语义(off)。在这两个调用中,它都表示映射在文件中开始的位置。对于mmap,位置的单位是字节,而mmap2使用的单位则是页(PAGE_SIZE)。可使用munmap系统调用删除映射。因为不需要文件偏移量,因此不需要munmap2系统调用,只需提供映射的虚拟地址。
创建映射
mmap和mmap2的调用语法在上文已经介绍,这里简要地列出可以设置的最重要的标志。
MAP_FIXED指定除了给定地址之外,不能将其他地址用于映射。如果没有设置该标志,内核可以在受阻时随意改变目标地址。例如,在目标地址已经存在一个映射的情况(否则,现存的映射将被覆盖)。
如果一个对象(通常是文件)在几个进程之间共享时,则必须使用MAP_SHARED。
MAP_PRIVATE创建一个与数据源分离的私有映射,对映射区域的写入操作不影响文件中的数据。
MAP_ANONYMOUS创建与任何数据源都不相关的匿名映射,fd和off参数被忽略。此类映射可用于为应用程序分配类似malloc所用的内存。
为简明起见,下文只讨论sys_mmap2(sys_mmap在大多数其他体系结构上的行为是类似的:最终都会到达下文讨论的do_mmap_pgoff函数)。该函数用作mmap2系统调用的入口,其实现立即将工作委托给do_mmap2。内核在其中提供文件描述符找到file实例,以及所处理文件的所有特征数据。剩余的工作委托给do_mmap_pgoff。
do_mmap_pgoff是一个体系结构无关的函数,定义在mm/mmap.c。图4-12给出了相关的代码流程图。
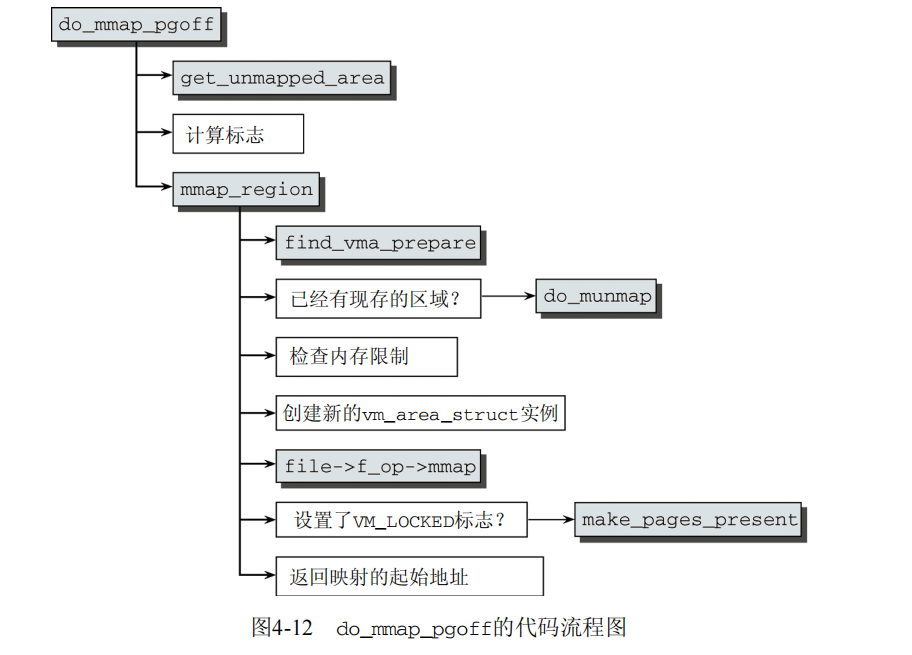
do_mmap_pgoff现在已经分成两个部分。一个部分需要彻底检查用户应用程序传递的参数,第二个部分需要考虑大量特殊情况和微妙之处。由于后一部分对于从一般意义上理解所涉及的机制没什么价值,我们只考察具有代表性的标准情况:用MAP_SHARED映射普通文件。另外,为避免使描述过于冗长,代码流程图也进行了相应删减。
首先调用4.对区域的操作描述的get_unmapped_area函数,在虚拟地址空间中找到一个适当的区域用于映射。我们知道,应用程序可以对映射指定固定地址、建议一个地址或由内核选择地址。
calc_vm_prot_bits和calc_vm_flag_bits将系统调用中指定的标志和访问权限常数合并到一个共同的标志集中,在后续的操作中比较易于处理(MAP_和PROT_标志转换为前缀VM_的标志)。
mm/mmap.c vm_flags = calc_vm_prot_bits(prot) | calc_vm_flag_bits(flags) | mm->def_flags | VM_MAYREAD | VM_MAYWRITE | VM_MAYEXEC;
最有趣的是,内核在从当前运行进程的mm_struct实例获得def_flags之后,又将其包含到标志集中。def_flags的值为0或VM_LOCK。前者不会改变结果标志集,而VM_LOCK意味着随后映射的页无法换出。为设置def_flags的值,进程必须发出mlockall系统调用,使用上述机制防止所有未来的映射被换出,即使在创建时没有显式指定VM_LOCK标志,也是如此。
在检查过参数并设置好所有需要的标志之后,剩余的工作委托给mmap_region。其中调用了我们在4.对区域的操作已经熟悉的find_vma_prepare函数,来查找前一个和后一个区域的vm_area_struct实例,以及红黑树中结点对应的数据。
![]()
如果在指定的映射位置已经存在一个映射,则通过do_munmap删除它(将在下一节描述)。
如果没有设置MAP_NORESERVE标志或内核参数sysctl_overcommit_memory设置为OVERCOMMIT_NEVER(即,不允许过量使用),则调用②vm_enough_memory。该函数选择是否分配操作所需的内存。如果它选择不分配,则系统调用结束,返回-ENOMEM。
注:sysctl_overcommit_memory可以借助于/proc/sys/vm/overcommit_memory设置。当前有3个过量使用选项。1允许应用程序分配与所要数量同样多的内存,即使超出系统地址空间所允许的限制。0意味着应用启发式过量使用,可用页的数目是通过计算页缓存、交换区和未使用页帧的总数而得到,且允许分配少量页的请求。2表示严格模式,称之为严格过量使用,其中允许分配的页数如下计算:
allowed = (totalram_pages -hugetlb) * sysctl_overcommit_ratio / 100;
allowed += total_swap_pages;
这里sysctl_overcommit_ratio是一个可配置的内核参数,通常设置为50。如果已使用页的总数超出所述计算结果,则内核拒绝继续分配内存。对于每个进程可以创建的映射,还有一个最大数目的限制。
在内核分配了所需的内存之后,会执行下列步骤。
(1) 分配并初始化一个新的vm_area_struct实例,并插入到进程的链表/树数据结构中。
(2) 用特定于文件的函数file->f_op->mmap创建映射。大多数文件系统将generic_file_mmap用于该目的。它所作的所有工作,就是将映射的vm_ops成员设置为generic_file_vm_ops。vma->vm_ops = &generic_file_vm_ops;
(2的目的即初始化vm->ops的falult成员,使之指向filemap_fault函数。filemap_fault借助于潜在文件系统的底层例程取得所需数据,并读取到物理内存,这些对应用程序是透明的。换句话说,映射数据不是在建立映射时立即读入内存,只有实际需要相应数据时才进行读取。)
如果设置了VM_LOCKED,或者通过系统调用的标志参数显式传递进来,或者通过mlockall机制隐式设置,内核都会调用make_pages_present依次扫描映射中各页,对每一页触发缺页异常以便读入其数据。当然,这意味着失去了延迟读取带来的性能提高,但内核可以确保在映射建立后所涉及的页总是在物理内存中。毕竟VM_LOCKED标志用来防止从内存换出页,因此这些页必须先读进来。
删除映射
从虚拟地址空间删除现存映射,必须使用munmap系统调用,它需要两个参数:解除映射区域的起始地址和长度。sys_munmap是该系统调用的入口。它按惯例将其工作委托给定义在mm_mmap.c中的do_munmap函数(进一步的实现信息在相关的代码流程图中给出,如图4-13)。

内核首先必须调用find_vma_prev,以找到解除映射区域的vm_area_struct实例。该函数的操作方式与4.对区域的操作讨论的find_vma完全相同,但它不仅会找到与地址匹配的vm_area_struct实例,还会返回指向前一个区域的指针。
如果解除映射区域的起始地址与find_vma_prev找到的区域起始地址不同,则只解除部分映射,而不是整个映射区域。在内核这样做之前,首先必须将现存的映射划分为几个部分。映射的前一部分不需要解除映射,首先通过split_vma分裂出来。如果解除映射的部分区域的末端与原区域末端并不重合,那么原区域后部仍然有一部分未解除映射,因此需要对这部分也重复上述的处理过程。
内核接下来调用detach_vmas_to_be_unmapped,列出所有需要解除映射的区域。由于解除映射操作可能涉及地址空间中的任何区域,很可能影响连续几个区域。内核可能拆分这一系列区域中首尾两端的区域,以确保只影响到完整的区域。(因为参数addr+长度len可能横跨连续的好几个vm_area_struct)
detach_vmas_to_be_unmapped会遍历vm_area_struct实例的线性表,直至要解除映射的地址范围已经全部涵盖在内。该结构的vm_next成员在此处滥用,用于将解除映射的区域彼此连接起来。该函数还将mmap缓存设置为NULL,使之无效。
最后还有两个步骤。首先调用unmap_region从页表删除与映射相关的所有项。完成后,内核还必须确保将相关的项从TLB移除或使之无效。其次,用remove_vma_list释放vm_area_struct实例占用的空间,完成从内核中删除映射的工作。
反向映射
物理内存页和该页所属进程(或更精确地说,所有使用该页的进程的对应页表项)之间的联系仍然未建立,在换出页时,刚好需要该关联。以便更新所有涉及的进程。因为页已经换出,必须在页表中标明。上文讨论的所有映射操作都只涉及虚拟内存页,因此不需要(也无法)建立反向映射。
数据结构
内核使用了简洁的数据结构,以最小化逆向映射的管理开销。page结构包含了一个用于实现逆向映射的成员。
mm.h struct page { .... atomic_t _mapcount; /* 内存管理子系统中映射的页表项计数,用于表示页是否 * 已经映射,还用于限制逆向映射搜索。 */ ... };
_mapcount表明共享该页的位置的数目。计数器的初始值为1。在页插入到逆向映射数据结构时,计数器赋值为0。页每次增加一个使用者时,计数器加1。这使得内核能够快速检查在所有者之外该页有多少使用者。
显然这没有多少帮助,因为逆向映射的目的在于:给定page实例,找到所有映射了该物理内存页的位置。因此,还有两个其他的数据结构需要发挥作用。
(1) 优先查找树中嵌入了属于非匿名映射的每个区域。
(2) 指向内存中同一页的匿名区域的链表。关于匿名区域的详细解释,可见这篇
用于建立这两个数据结构的成员集成在vm_area_struct中,即shared联合以及anon_vma_node和anon_vma。
mm.h struct vm_area_struct { ... /* *对于有地址空间和后备存储器的区域来说,shared连接到address_space->i_mmap优先树, *或连接到悬挂在优先树结点之外、类似的一组虚拟内存区域的链表, *或连接到address_space->i_mmap_nonlinear链表中的虚拟内存区域。 */ union { struct { struct list_head list; void *parent; /* 与prio_tree_node的parent成员在内存中位于同一位置 */ struct vm_area_struct *head; } vm_set; struct raw_prio_tree_node prio_tree_node; } shared; /* *在文件的某一页经过写时复制之后,文件的MAP_PRIVATE虚拟内存区域可能同时在i_mmap *树和anon_vma链表中。MAP_SHARED虚拟内存区域只能在i_mmap树中。匿名的 *MAP_PRIVATE、栈或brk虚拟内存区域(file指针为NULL)只能处于anon_vma链表中。 */ struct list_head anon_vma_node; /* 对该成员的访问通过anon_vma->lock串行化 */ struct anon_vma *anon_vma; /* 对该成员的访问通过page_table_lock串行化 */ ... }
内核在实现逆向映射时采用的技巧是,不直接保存页和相关的使用者之间的关联,而只保存页和页所在区域之间的关联。包含该页的所有其他区域(进而所有的使用者)都可以通过刚才提到的数据结构找到。
建立逆向映射
在创建逆向映射时,有必要区分两个备选项:匿名页和基于文件映射的页。这是可以理解的,因为用于管理这两种选项的数据结构不同。
1. 匿名页
将匿名页插入到逆向映射数据结构中有两种方法。对新的匿名页必须调用page_add_new_anon_rmap。已经有引用计数的页,则使用page_add_anon_rmap。这两个函数之间唯一的差别是,前者将映射计数器page->_mapcount设置为0(提示:新初始化的页_mapcount的初始值为-1),后者将计数器加1。这两个函数都并入__page_set_anon_rmap。
mm/rmap.c void __page_set_anon_rmap(struct page *page, struct vm_area_struct *vma, unsigned long address) { struct anon_vma *anon_vma = vma->anon_vma; anon_vma = (void *) anon_vma + PAGE_MAPPING_ANON; page->mapping = (struct address_space *) anon_vma; page->index = linear_page_index(vma, address); }
anon_vma表头的地址在加上PAGE_MAPPING_ANON之后,保存到page实例的mapping成员中。 这使得内核可以通过检查最低位来区分匿名页和普通映射的页:如果为0(没有设置PAGE_MAPPING_ANON),则为普通映射;如果为1(PAGE_MAPPING_ANON置位),则为匿名页。回忆前文可知,该技巧之所以有效,是因为由于对齐,address_space实例总是对齐到sizeof(long)。
2. 基于文件映射的页
此类型的页非常简单,代码片段如下所示:
mm/rmap.c void page_add_file_rmap(struct page *page) { if (atomic_inc_and_test(&page->_mapcount)) __inc_zone_page_state(page, NR_FILE_MAPPED); }
基本上,所需要的只是对_mapcount变量加1(原子操作)并更新各内存域的统计量。
使用逆向映射
page_referenced是一个重要的函数,很好地使用了逆向映射方案所涉及的数据结构。它统计了最近活跃地使用(即访问)了某个共享页的进程的数目。
该函数相当于一个多路复用器,对匿名页调用page_referenced_anon,而对基于文件映射的页调用page_referenced_file。分别调用的两个函数,其目的都是确定有多少地方在使用一个页,但由于底层数据结构的不同,二者采用了不同的方法。
我们首先察看处理匿名页的函数。我们首先需要调用page_lock_anon_vma辅助函数,找到引用了某个特定page实例的区域的列表(按前一节的讨论,从数据结构中读取相关信息)。
<mm/rmap.c> static struct anon_vma *page_lock_anon_vma(struct page *page) { struct anon_vma *anon_vma = NULL; unsigned long anon_mapping; anon_mapping = (unsigned long) page->mapping; if (!(anon_mapping & PAGE_MAPPING_ANON)) goto out; if (!page_mapped(page)) goto out; anon_vma = (struct anon_vma *) (anon_mapping -PAGE_MAPPING_ANON); return anon_vma; }
上述代码首先使用我们现在已经熟悉的技巧(指针的最低位必须置位),判断page->mapping指针实际上是否指向一个anon_vma实例。在确认之后,page_mapped检查该页是否已经映射(page->_mapcount必须大于等于0)。倘若如此,该函数返回一个指向与该页关联的anon_vma实例的指针。
page_referenced_anon对该信息的用法如下:
mm/rmap.c static int page_referenced_anon(struct page *page) { unsigned int mapcount; struct anon_vma *anon_vma; struct vm_area_struct *vma; int referenced = 0; anon_vma = page_lock_anon_vma(page); if (!anon_vma) return referenced; mapcount = page_mapcount(page); list_for_each_entry(vma, &anon_vma->head, anon_vma_node) { referenced += page_referenced_one(page, vma, &mapcount); if (!mapcount) break; } return referenced; }
在找到匹配的 anon_vma 实例之后,内核遍历链表中的所有区域,分别调用 page_referenced_one,计算使用该页的次数。对所有区域调用page_referenced_one的结果需要累加起来,最后返回。
page_referenced_one分为两个步骤执行其任务。
(1) 找到指向该页的页表项。这样做是可行的,因为page_referenced_one的参数不仅包括page实例,还有相关的vm_area_struct。虚拟地址空间中映射该页的可以根据后者确定。
(2) 检查页表项是否设置了_PAGE_ACCESSED标志位,然后清除该标志位。每次访问该页时,硬件会设置该标志(如果特定体系结构有需要,内核也会提供额外的支持)。如果设置了该标志位,则引用计数器加1;否则不变。因此经常使用的页引用计数较高,而很少使用的页则刚好相反。因此内核根据引用计数,立即就能判断某一页是否重要。(对每个映射了该页的区域,page_referenced_one都自动地将mapcount计数器减1。)
在检查基于文件映射的页的引用次数时,采用的方法类似。内核调用vm_prio_tree_foreach遍历优先树中所存储区域包含相关页的所有结点。与前述情况相同,仍然对每一个区域调用了page_referenced_one汇总所有引用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号