
15.分配页之移除页(buffered_rmqueue详解)
如果内核找到适当的内存域,具有足够的空闲页可供分配,那么还有两件事情需要完成。首先它必须检查这些页是否是连续的(到目前为止,只知道有许多空闲页)。其次,必须按伙伴系统的方式从free_lists移除这些页,这可能需要分解并重排内存区。内核将该工作委托给前一节提到的buffered_rmqueue。图3-32给出了该函数必需的各个步骤。如果只分配一页,内核会进行优化,即分配阶为0的情形,20 = 1。该页不是从伙伴系统直接取得,而是取自per-CPU的页缓存(回想一下,可知该缓存提供了CPU本地的热页和冷页的列表,见1.NUMA模型及其基本数据结构
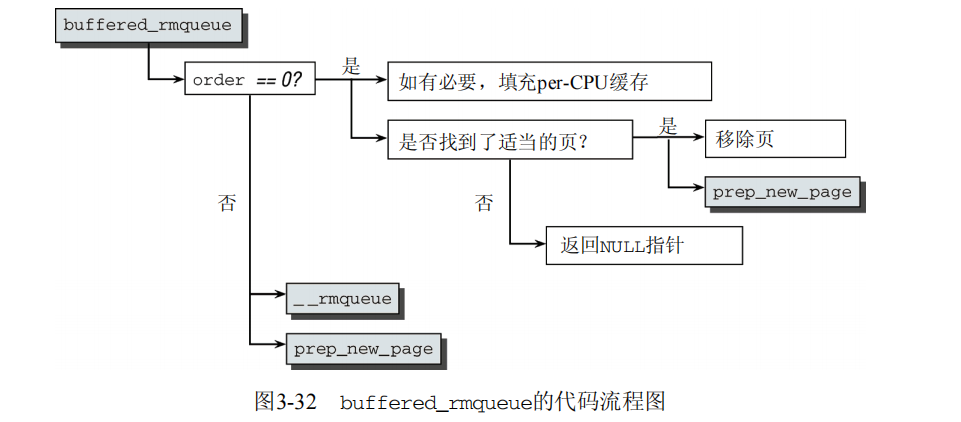
照例,首先需要设置一些变量:
mm/page_alloc.c static struct page *buffered_rmqueue(struct zone *zone, int order, gfp_t gfp_flags) { unsigned long flags; struct page *page; int cold = !!(gfp_flags & __GFP_COLD); int migratetype = allocflags_to_migratetype(gfp_flags);
如果分配标志设置了GFP_COLD,那么必须从per-CPU缓存取得冷页,前提是有的话。两个取反操作确保cold是0或1。根据分配标志确定迁移列表,也是必要的。先前介绍的函数allocflags_to_migratetype在这里就派上用场了,见11.伙伴系统(避免碎片及内存的迁移类型)。
在只请求一页时,内核试图借助于per-CPU缓存加速请求的处理。如果缓存为空,内核可借机检查缓存填充水平。
mm/page_alloc.c again: if (order == 0) { struct per_cpu_pages *pcp; page = NULL; pcp = &zone_pcp(zone, get_cpu())->pcp[cold]; if (!pcp->count) pcp->count = rmqueue_bulk(zone, 0,pcp->batch, &pcp->list); if (unlikely(!pcp->count)) goto failed; } ...
在针对当前处理器选择了适当的per-CPU列表(热页或冷页列表)之后,调用rmqueue_bulk重新填充缓存。在这里我不打算给出该函数的代码,因为它只是从通常的伙伴系统移除页,然后添加到缓存。但重要的是要注意,rmqueue_bulk将页的迁移类型存储在struct page的private成员中。在从缓存取得页时,该信息变得很重要:
mm/page_alloc.c /* 查找适当迁移类型的页 */ list_for_each_entry(page, &pcp->list, lru) if (page_private(page) == migratetype) break; /* 如有必要,向pcp列表分配更多页 */ if (unlikely(&page->lru == &pcp->list)) { pcp->count += rmqueue_bulk(zone, 0,pcp->batch, &pcp->list, migratetype); page = list_entry(pcp->list.next, struct page, lru); } list_del(&page->lru); pcp->count-- } else { page = __rmqueue(zone, order); if (!page) goto failed; } ...
内核会遍历per-CPU缓存中的所有页,检查是否有指定迁移类型的页可用。如果前一次调用中,用不同迁移类型的页重新填充了缓存,就可能找不到。如果无法找到适当的页,则向缓存添加一些符合当前要求迁移类型的页,然后从per-CPU列表移除一页,接下来进一步处理。
如果需要分配多页(由else分支处理),内核调用__rmqueue会从内存域的伙伴列表中选择适当的内存块。如有必要,该函数会自动分解大块内存,将未用的部分放回列表中(具体过程将在下文讲解)。切记,可能有这样的情况:内存域中有足够空闲页满足分配请求,但页不是连续的。在这种情况下,__rmqueue失败并返回NULL指针。
由于所有失败情形都跳转到标号failed处理,这可以确保内核到达当前点之后,page指向一系列有效的页。在返回指针之前,prep_new_page需要做一些准备工作,以便内核能够处理这些页(注意,如果所选择的页出了问题,则该函数返回正值。在这种情况下,分配将从头重新开始):
mm/page_alloc.c if (prep_new_page(page, order, gfp_flags)) goto again; return page; failed: ... return NULL; }
此外,根据页的标志,还需要作一些工作:
mm/page_alloc.c if (gfp_flags & __GFP_ZERO) prep_zero_page(page, order, gfp_flags); if (order && (gfp_flags & __GFP_COMP)) prep_compound_page(page, order); return 0; }
如果设置了__GFP_ZERO,prep_zero_page使用一个特定于体系结构的高效函数将页填充字节0。
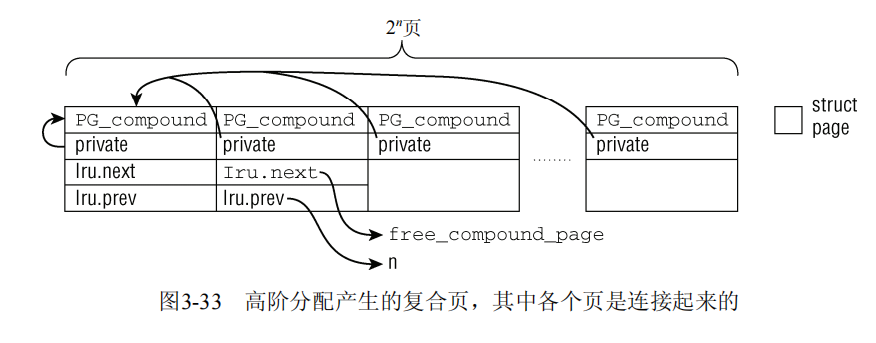
如果设置了__GFP_COMP并请求了多个页,内核必须将这些页组成复合页(compound page)。第一个页称作首页(head page),而所有其余各页称作尾页(tail page)。复合页的结构如图3-33所示。
复合页通过PG_compound标志位识别。组成复合页的所有页的page实例的private成员,包括首页在内,都指向首页。此外,内核需要存储一些信息,描述如何释放复合页。这包括一个释放页的函数,以及组成复合页的页数。第一个尾页的LRU链表元素因此被滥用:指向析构函数的指针保存在lru.next,而分配阶保存在lru.prev。请注意,lru成员无法用于这用途,因为如果将复合页连接到内核链表中,是需要该成员的。free_compound_pages用于该目的。本质上,在释放复合页时,该函数通过lru.prev确定页的分配阶,并依次释放各页。辅助函数prep_compound_page用于设置以上描述的结构。
__rmqueue辅助函数
内核使用了__rmqueue函数(前面讲过),该函数充当进入伙伴系统核心的看门人:
mm/page_alloc.c static struct page *__rmqueue(struct zone *zone, unsigned int order,int migratetype) { struct page *page; page = __rmqueue_smallest(zone, order, migratetype); if (unlikely(!page)) page = __rmqueue_fallback(zone, order, migratetype); return page; }
根据传递进来的分配阶、用于获取页的内存域、迁移类型,__rmqueue_smalles扫描页的列表,直至找到适当的连续内存块。在这样做的时候,可以按第1章的描述拆分伙伴。如果指定的迁移列表不能满足分配请求,则调用__rmqueue_fallback尝试其他的迁移列表,作为应急措施。
__rmqueue_smallest的实现不是很长。本质上,它由一个循环组成,按递增顺序遍历内存域的各个特定迁移类型的空闲页列表,直至找到合适的一项。
mm/page_alloc.c static struct page *__rmqueue_smallest(struct zone *zone, unsigned int order,int migratetype) { unsigned int current_order; struct free_area * area; struct page *page; /* 在首选的列表中找到适当大小的页 */ for (current_order = order; current_order < MAX_ORDER; ++current_order) { area = &(zone->free_area[current_order]); if (list_empty(&area->free_list[migratetype])) continue; page = list_entry(area->free_list[migratetype].next,struct page, lru); list_del(&page->lru); rmv_page_order(page); area->nr_free--; __mod_zone_page_state(zone, NR_FREE_PAGES, -(1UL << order)); expand(zone, page, order, current_order, area, migratetype); return page; } return NULL; }
搜索从指定分配阶对应的项开始。小的内存区无用,因为分配的页必须是连续的。我们知道给定分配阶的所有页又再分成对应于不同迁移类型的列表,在其中需要选择正确的一项。检查适当大小的内存块非常简单。如果检查的列表中有一个元素,那么它就是可用的,因为其中包含了所需数目的连续页。否则,内核将选择下一个更高分配阶,并进行类似的搜索。
在用list_del从链表移除一个内存块之后,要注意,必须将struct free_area的nr_free成员减1。还必须据此更新当前内存域的统计量,这可以通过使用__mod_zone_page_state实现。rmv_page_order是一个辅助函数,从页标志删除PG_buddy位,表示该页不再包含于伙伴系统中,并将struct page的private成员设置为0。
如果需要分配的内存块长度小于所选择的连续页范围,即如果因为没有更小的适当内存块可用,而从较高的分配阶分配了一块内存,那么该内存块必须按照伙伴系统的原理分裂成小的块。这是通过expand函数完成的。
mm/page_alloc.c static inline struct page *expand(struct zone *zone, struct page *page,int low, int high, struct free_area *area,int migratetype) { unsigned long size = 1 << high; while (high > low) { area--; high--; size >>= 1; list_add(&page[size].lru, &area->free_list[migratetype]); area->nr_free++; set_page_order(&page[size], high); } return page; }
伙伴系统只需要内存区第一个page实例,用作管理用途。内存区的长度可根据页所在的列表自动推导而得。
内核总是使用特定于迁移类型的free_area列表,在处理期间不会改变页的迁移类型。循环中各个步骤都调用了set_page_order辅助函数,对于回收到伙伴系统的内存区,该函数将第一个struct page实例的private标志设置为当前分配阶,并设置页的PG_buddy标志位。该标志表示内存块由伙伴系统管理。
如果在特定的迁移类型列表上没有连续内存区可用,则__rmqueue_smallest返回NULL指针。内核接下来根据备用次序,尝试使用其他迁移类型的列表满足分配请求。该任务委托给__rmqueue_fallback。迁移类型的备用次序在fallbacks数组定义(详见11.伙伴系统(避免碎片及内存的迁移类型))。首先,函数再一次遍历各个分配阶的列表:
mm/page_alloc.c static struct page *__rmqueue_fallback(struct zone *zone, int order,int start_migratetype) { struct free_area * area; int current_order; struct page *page; int migratetype, i; /* 在其他类型列表中找到最大可能的内存块 */ for (current_order = MAX_ORDER-1; current_order >= order;--current_order) { for (i = 0; i < MIGRATE_TYPES -1; i++) { migratetype = fallbacks[start_migratetype][i]; ...
但不只是相同的迁移类型,还要考虑备用列表中指定的不同迁移类型。请注意,该函数会按照分配阶从大到小遍历!这与通常的策略相反,内核的策略是,如果无法避免分配迁移类型不同的内存块,那么就分配一个尽可能大的内存块。如果优先选择更小的内存块,则会向其他列表引入碎片,因为不同迁移类型的内存块将会混合起来,这显然不是我们想要的。
特别列表MIGRATE_RESERVE包含了用于紧急分配的内存,需要特殊处理,我们将在下文讨论。如果当前考虑的迁移类型对应的空闲列表包含空闲内存块,则从该列表分配内存:
mm/page_alloc.c /* 如有必要,在后面处理MIGRATE_RESERVE */ if (migratetype == MIGRATE_RESERVE) continue; area = &(zone->free_area[current_order]); if (list_empty(&area->free_list[migratetype])) continue; page = list_entry(area->free_list[migratetype].next,struct page, lru); area->nr_free--;
我们知道,迁移列表是页迁移方法的基础,该方法用于使内存碎片保持在尽可能低的水平。较低的内存碎片水平,意味着即使在系统已经运行很长时间后,仍然有较大的连续内存块可以分配。较大内存块有多大的概念由全局变量pageblock_order给出,该变量定义了大内存块的分配阶。
如果需要分解来自其他迁移列表的空闲内存块,那么内核必须决定如何处理剩余的页。如果剩余部分也是一个比较大的内存块,那么将整个内存块都转到当前分配类型对应的迁移列表是有意义的,这样可以减少碎片。
如果是在分配可回收内存,那么内核在将空闲页从一个迁移列表移动到另一个时,会更加积极。此类分配经常猝发涌现,导致许多小的可回收内存块散布到所有的迁移列表,例如,在updatedb运行时就是这样。为避免此类情形,分配MIGRATE_RECLAIMABLE内存块时,剩余的页总是转移到可回收迁移列表。
内核对所述策略的实现如下:
mm/page_alloc.c /* * 如果分解一个大内存块,则将所有空闲页移动到优先选用的分配列表。 * 如果内核在备用列表中分配可回收内存块,则会更为积极地取得空闲页的所有权 * / if (unlikely(current_order >= (pageblock_order >> 1)) ||start_migratetype == MIGRATE_RECLAIMABLE) { unsigned long pages; pages = move_freepages_block(zone, page,start_migratetype); /* 如果大内存块超过一半是空闲的,则主张对整个大内存块的所有权 */ if (pages >= (1 << (pageblock_order-1))) set_pageblock_migratetype(page,start_migratetype); migratetype = start_migratetype; } ...
move_freepages试图将包含2 pageblock_order个页的整个内存块(包含当前将分配的内存块在内)转移到新的迁移列表。但只有空闲页(即设置了PG_buddy标志位的页)才会移动。此外,move_freepages还会考虑到内存域的边界,因此移动页的总数可能小于整个大内存块。但如果大内存块有超过二分之一的部分是空闲的,接下来set_pageblock_migratetype将修改整个大内存块的迁移类型(回忆前文可知,该函数总是处理具有pageblock_nr_pages页的大内存块)。
最后内核将内存块从列表移除,并使用expand将其中未用的部分还给伙伴系统。
mm/page_alloc.c /* 从空闲列表移除页 */ list_del(&page->lru); rmv_page_order(page); __mod_zone_page_state(zone, NR_FREE_PAGES,-(1UL << order)); ... expand(zone, page, order, current_order, area, migratetype); return page; } } ...
请注意,如果此前已经改变了迁移类型,那么expand将使用新的迁移类型。否则,剩余部分将放置到原来的迁移列表上。
最后,还需要考虑另一个场景:如果遍历了所有分配阶和所有迁移类型,仍然无法满足分配请求,那么该怎么办?在这种情况下,内核可以尝试从MIGRATE_RESERVE列表满足分配请求,这是最后的手段:
mm/page_alloc.c /* 使用MIGRATE_RESERVE,而不是分配失败 */ return __rmqueue_smallest(zone, order, MIGRATE_RESERVE); }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号