x86_64 Linux 运行时栈的字节对齐
前言
C语言的过程调用机制(即函数调用)的一个关键特性是使用了栈数据结构提供的后进先出的内存管理原则,其实大多数编程语言都是如此。每一个函数的栈空间被称为栈帧,一个栈帧上包含了保存的寄存器、分配给局部变量的空间以及传递给被调用函数的参数等等。一个基本的栈结构如下图所示:

过程调用的参数是通过栈来传递的,并且分配的局部变量也在栈上,那么对于不同字节长度的参数或变量,是如何在栈上为它们分配空间的?这里所涉及的就是我们要探讨的字节对齐。
本文示例所用到的环境如下:
- Ubuntu 18.04 x86_64
- gcc 7.4.0
数据对齐
许多计算机系统对基本数据类型的合法地址做了一些限制,要求某种类型对象所在的地址必须是某个值K的倍数,K的具体如下图所示。
| K | 类型 |
|---|---|
| 1 | char |
| 2 | short |
| 4 | int, float |
| 8 | long,double,char* |
这种对齐限制简化了处理器和内存系统之间接口的硬件设计。举个实际的例子:比如我们在内存中读取一个8字节长度的变量,如果这个变量所在的地址是8的倍数,那么就可以通过一次内存操作完成该变量的读取。倘若这个变量所在的地址并不是8的倍数,可能就需要执行两次内存读取,因为该变量被放在两个8字节的内存块中了。
无论数据是否对齐,x86_64硬件都能正常工作,但是却会降低系统的性能,所以编译器在编译时一般会为对程序实施数据对齐。
栈的字节对齐
栈的字节对齐,实际是指栈顶指针必须是16字节的整数倍。栈对齐使得在尽可能少的内存访问周期内读取数据,不对齐堆栈指针可能导致严重的性能下降。
上文我们说,即使数据没有对齐,我们的程序也是可以执行的,只是效率有点低而已,但是某些型号的Intel和AMD处理器,在执行某些实现多媒体操作的SSE指令时,如果数据没有对齐,将无法正确执行。这些指令对16字节内存进行操作,在SSE单元和内存之间传送数据的指令要求内存地址必须是16的倍数。
因此,任何针对x86_64处理器的编译器和运行时系统都必须保证, 它们分配内存将来可能会被SSE指令使用,所以必须是16字节对齐的,这也就形成了一种标准:
- 任何内存分配函数(
alloca,malloc,calloc或realloc)生成的块的起始地址都必须是16的倍数。 - 大多数函数的栈帧的边界都必须是16字节的倍数。
如上,在运行时栈中,不仅传递的参数和局部变量要满足字节对齐,我们的栈指针(rsp)也必须是16的倍数。
三个示例
我们用三个实际的例子来看一看为了实现数据对齐和栈字节对齐,栈空间的分配具体是怎样的。
下面是CSAPP上的一个示例程序。
void proc(long a1, long *a1p,
int a2, int *a2p,
short a3, short *a3p,
char a4, char *a4p) {
*a1p += a1;
*a2p += a2;
*a3p += a3;
*a4p += a4;
}
long call_proc()
{
long x1 = 1; int x2 = 2;
short x3 = 3; char x4 = 4;
proc(x1, &x1, x2, &x2, x3, &x3, x4, x4);
return (x1+x2)*(x3+x4);
}
使用如下命令进行编译和反编译:
$ gcc -Og -fno-stack-protector -c call_proc.c
$ objdump -d call_proc.o
其中-fno-stack-protector参数指示编译器不添加栈保护机制
生成的汇编代码如下,这里我们仅看call_proc()中的栈空间分配
0000000000000015 <call_proc>:
15: 48 83 ec 10 sub $0x10,%rsp
19: 48 c7 44 24 08 01 00 movq $0x1,0x8(%rsp)
20: 00 00
22: c7 44 24 04 02 00 00 movl $0x2,0x4(%rsp)
29: 00
2a: 66 c7 44 24 02 03 00 movw $0x3,0x2(%rsp)
31: c6 44 24 01 04 movb $0x4,0x1(%rsp)
36: 48 8d 4c 24 04 lea 0x4(%rsp),%rcx
3b: 48 8d 74 24 08 lea 0x8(%rsp),%rsi
40: 48 8d 44 24 01 lea 0x1(%rsp),%rax
45: 50 push %rax
46: 6a 04 pushq $0x4
48: 4c 8d 4c 24 12 lea 0x12(%rsp),%r9
4d: 41 b8 03 00 00 00 mov $0x3,%r8d
53: ba 02 00 00 00 mov $0x2,%edx
58: bf 01 00 00 00 mov $0x1,%edi
5d: e8 00 00 00 00 callq 62 <call_proc+0x4d>
...
15行(冒号前面的十六进制数,其实这些数字是指令的字节偏移,姑且就这样叫吧)中先将%rsp减去0x10,为4个局部变量共分配了16个字节的空间,并且在45和46行,程序将%rax和$0x4入栈,联系该函数的C语言程序和汇编程序中的具体操作,不难知,栈上的具体空间分配如下图所示:
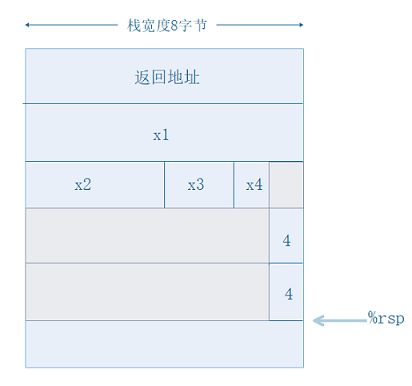
图中,为了使栈字节对齐,4单独占用了一个8字节的空间,并且栈中的每一个类型的变量,都符合数据对齐的要求。
如果我们的参数8占用的字节数减少,会不会减少栈空间的占用呢?我们将上面的C语言程序的稍微改一改,如下:
void proc(long a1, long *a1p,
int a2, int *a2p,
short a3, short *a3p,
char a4, char a5) { // char *a4p改为了char a5
*a1p += a1;
*a2p += a2;
*a3p += a3;
a5 += a4;
}
long call_proc()
{
long x1 = 1; int x2 = 2;
short x3 = 3; char x4 = 4;
proc(x1, &x1, x2, &x2, x3, &x3, x4, x4); // 相应的改变了最后一个参数
return (x1+x2)*(x3+x4);
}
call_proc()的汇编如下:
000000000000000a <call_proc>:
a: 48 83 ec 10 sub $0x10,%rsp
e: 48 c7 44 24 08 01 00 movq $0x1,0x8(%rsp)
15: 00 00
17: c7 44 24 04 02 00 00 movl $0x2,0x4(%rsp)
1e: 00
1f: 66 c7 44 24 02 03 00 movw $0x3,0x2(%rsp)
26: 48 8d 4c 24 04 lea 0x4(%rsp),%rcx
2b: 48 8d 74 24 08 lea 0x8(%rsp),%rsi
30: 6a 04 pushq $0x4
32: 6a 04 pushq $0x4
34: 4c 8d 4c 24 12 lea 0x12(%rsp),%r9
39: 41 b8 03 00 00 00 mov $0x3,%r8d
3f: ba 02 00 00 00 mov $0x2,%edx
44: bf 01 00 00 00 mov $0x1,%edi
49: e8 00 00 00 00 callq 4e <call_proc+0x44>
...
对照程序,栈的空间结构编程的如下如所示:

我们发现,栈空间的占用并没有减少,为了能够达到栈字节对齐的目的,参数8和参数7各占一个8字节的空间,该过程调用浪费了1 + 7 + 7 = 15字节的空间。但为了兼容性和效率,这是值得的。
我们再看另一个程序,当我们在栈中分配字符串时又是怎样的呢?
void function(int a, int b, int c) {
char buffer1[5];
char buffer2[10];
strcpy(buffer2, buffer1);
}
int main() {
function(1,2,3);
return 0;
}
使用gcc -fno-stack-protector -o foo foo.c和objdump -d foo进行编译和反编译后,function()的汇编代码如下:
000000000000064a <function>:
64a: 55 push %rbp
64b: 48 89 e5 mov %rsp,%rbp
64e: 48 83 ec 20 sub $0x20,%rsp
652: 89 7d ec mov %edi,-0x14(%rbp)
655: 89 75 e8 mov %esi,-0x18(%rbp)
658: 89 55 e4 mov %edx,-0x1c(%rbp)
65b: 48 8d 55 fb lea -0x5(%rbp),%rdx
65f: 48 8d 45 f1 lea -0xf(%rbp),%rax
663: 48 89 d6 mov %rdx,%rsi
666: 48 89 c7 mov %rax,%rdi
669: e8 b2 fe ff ff callq 520 <strcpy@plt>
66e: 90 nop
66f: c9 leaveq
670: c3 retq
该过程共在栈上分配了32个字节的空间,其中包括两个字符串的空间和三个函数的参数的空间,这里需要提一下的是,尽管再x64下,函数的前6个参数直接用寄存器进行传递,但是有时候程序需要用到参数的地址,这个时候程序就不得不在栈上为参数分配内存并将参数拷贝到内存上,来满足程序对参数地址的操作。
联系程序,该过程的栈结构如下:
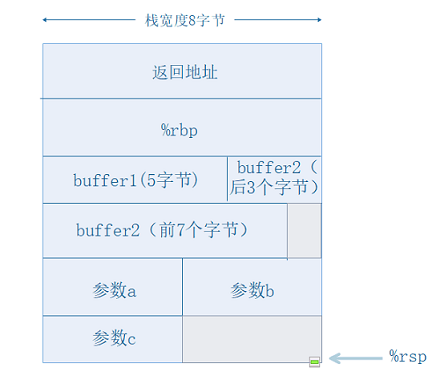
图中,因为char类型的地址可以从任意地址开始(地址为1的倍数),所以buffer1和buffer2是连续分配的,而三个int型变量则被分配在了两个单独的8字节空间中。
小结
以上,我们看到,为了满足数据对齐和栈字节对齐的要求,或者说规范,编译器不惜牺牲了部分内存,这使得程序提高了兼容性,也提高了程序的性能。
完
参考:
- 《深入理解计算机系统》
- C函数调用过程解析(x86-64)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号