
温故知新,.Net Core利用UserAgent+rDNS双解析方案,正确识别并反爬虫/反垃圾邮件
背景
一般有价值的并保有数据的网站或接口很容易被爬虫,爬虫会占用大量的流量资源,接下来我们参考历史经验,探索如何在.Net Core中利用UserAgent+rDNS双解析方案来正确识别并且反爬虫。

新建网络爬虫识别项目
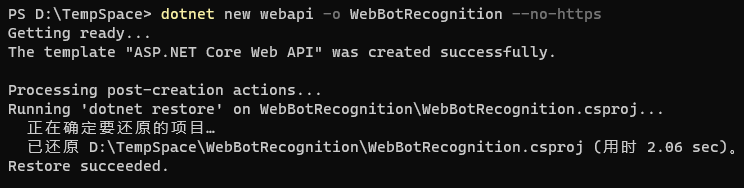
在终端命令行中,基于DotNet-Cli的new命令新建名为WebBotRecognition的webapi项目,并且不需要https,它将自动创建一个net5.0的网络接口项目。
dotnet new webapi -o WebBotRecognition --no-https
cd WebBotRecognition
切换到项目目录
code .
用Visual Studio Code来打开当前目录。

于是,我们便完成一个演示项目创建。
执行命令,先运行起来。
dotnet watch run
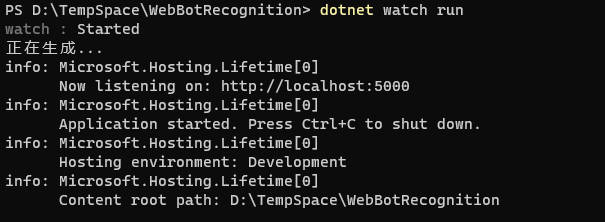
基于DotNet-Cli的run命令把项目中的模板示例先运行起来,确保一切正常,这里携带watch参数来确保后面热更新。
好了,接下来,我们删掉自带的Controller那些东西。
尝试解析请求来源的User Agent
User Agent中文名为用户代理,简称UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。
在.Net Core中我们可以基于UAParser组件包来实现对User Agent字符串的识别和解析。
安装UAParser
dotnet add package UAParser
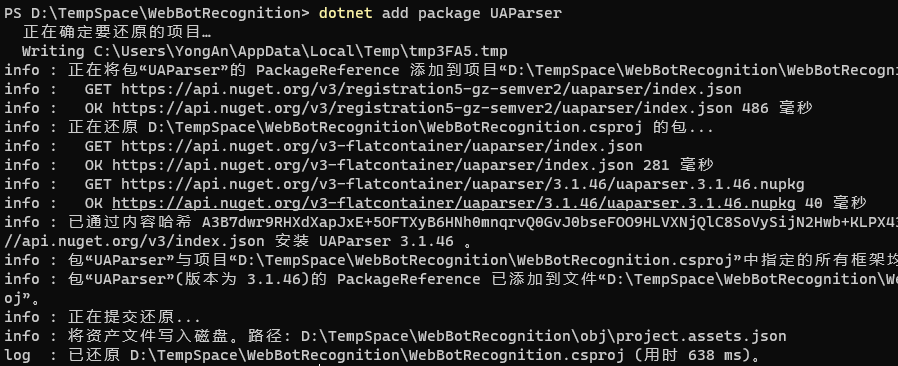
基于DotNet-Cli的add package命令在当前项目中安装并添加UAParser组件。
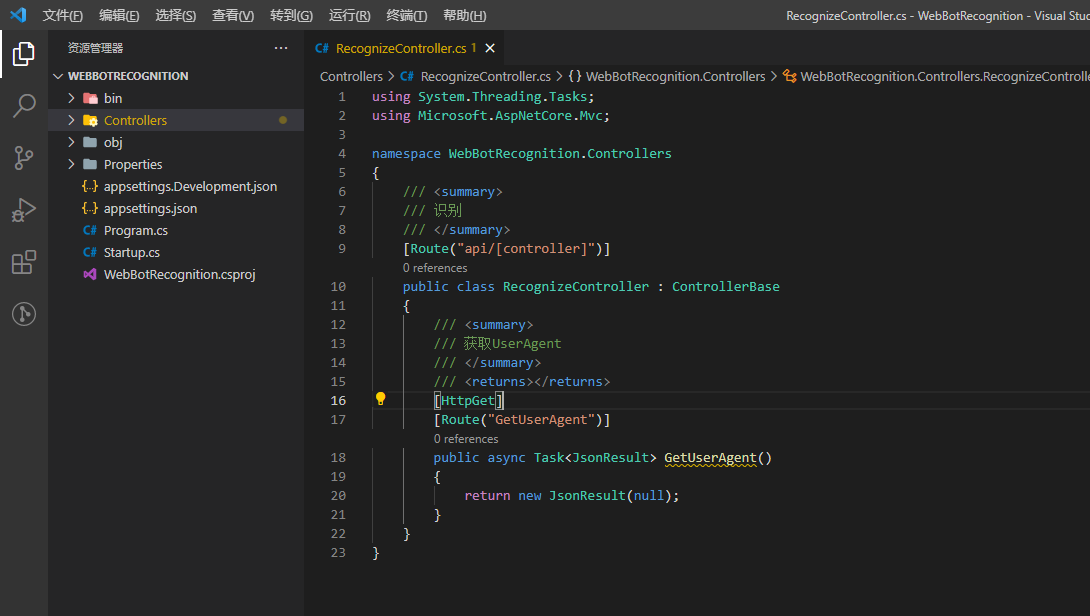
新建识别接口测试
在项目的Controllers目录下新建名为RecognizeController的控制器,继承自MVC中的ControllerBase,并且设置好路由地址和新建一个名为GetUserAgent的方法。
using System.Threading.Tasks;
using Microsoft.AspNetCore.Mvc;
namespace WebBotRecognition.Controllers
{
/// <summary>
/// 识别
/// </summary>
[Route("api/[controller]")]
public class RecognizeController : ControllerBase
{
/// <summary>
/// 获取UserAgent
/// </summary>
/// <returns></returns>
[HttpGet]
[Route("GetUserAgent")]
public async Task<JsonResult> GetUserAgent()
{
return new JsonResult(null);
}
}
}
利用UAParser组件来解析来源User Agent
/// <summary>
/// 获取UserAgent
/// </summary>
/// <returns></returns>
[HttpGet]
[Route("GetUserAgent")]
public async Task<JsonResult> GetUserAgent()
{
// 定义解析结果信息对象
ClientInfo clientInfo = null;
// 尝试从头部里面获取User-Agent字符串
if(Request.Headers.TryGetValue("User-Agent", out var requestUserAgent) && !string.IsNullOrEmpty(requestUserAgent))
{
// 获取UaParser实例
var uaParser = Parser.GetDefault();
// 解析User-Agent字符串
clientInfo = uaParser.Parse(requestUserAgent);
}
return new JsonResult(clientInfo);
}
这里我们可以从Request.Headers里面通过TryGetValue的方式相对安全的读取到User Agent字符串。
先获取一个UaParser实例,然后基于它直接解析RequestUserAgent即可。
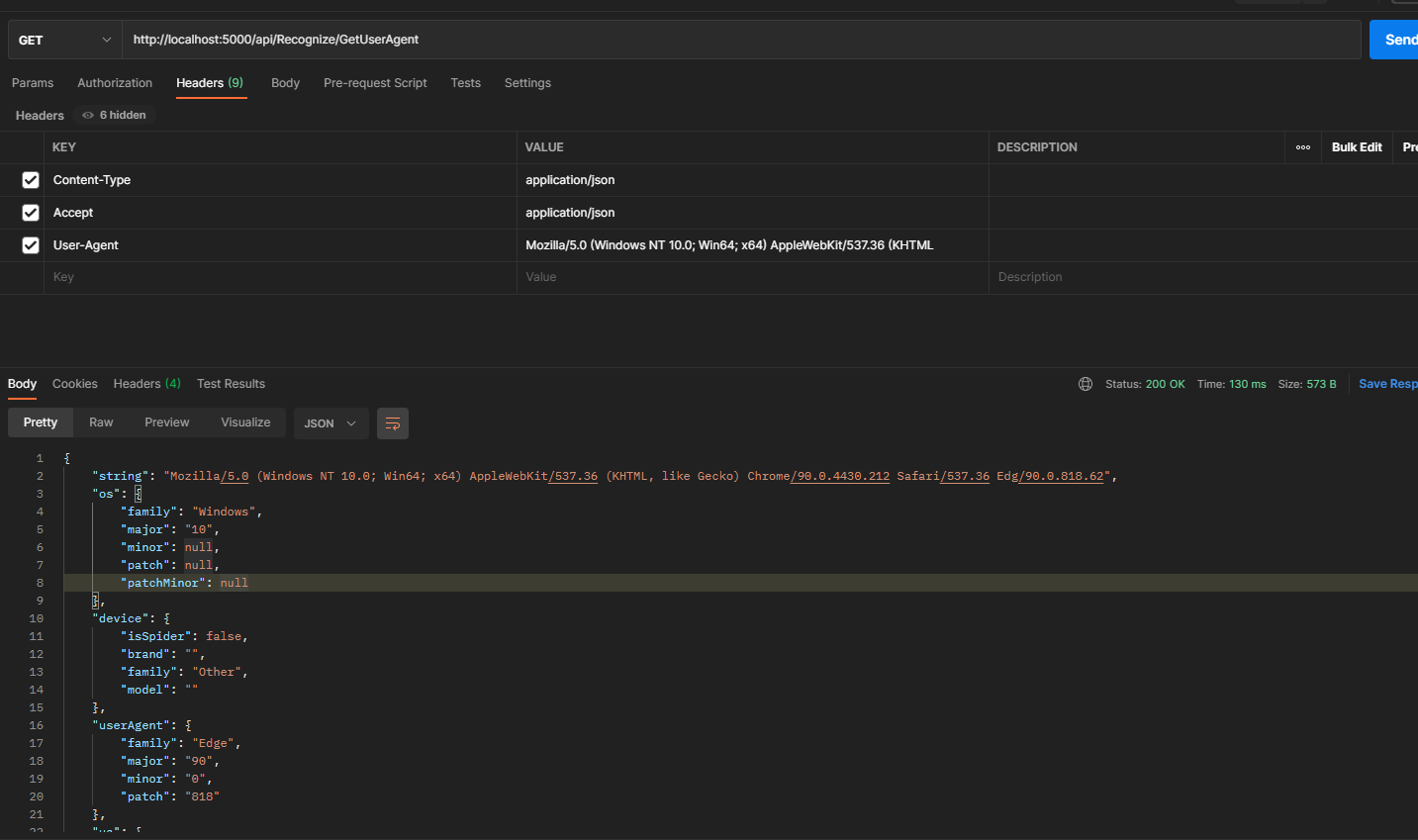
我们通过PostMan调用来看看返回结果。
Content-Type:application/json
Accept:application/json
User-Agent:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36 Edg/90.0.818.62
{
"string": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36 Edg/90.0.818.62",
"os": {
"family": "Windows",
"major": "10",
"minor": null,
"patch": null,
"patchMinor": null
},
"device": {
"isSpider": false,
"brand": "",
"family": "Other",
"model": ""
},
"userAgent": {
"family": "Edge",
"major": "90",
"minor": "0",
"patch": "818"
},
"ua": {
"family": "Edge",
"major": "90",
"minor": "0",
"patch": "818"
}
}
结果很清晰,如果我们需要进一步通过结果去判断,就可以按这个结构来了。
我们多看几组。
Content-Type:application/json
Accept:application/json
User-Agent:Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0
{
"string": "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0",
"os": {
"family": "Windows",
"major": "7",
"minor": null,
"patch": null,
"patchMinor": null
},
"device": {
"isSpider": false,
"brand": "",
"family": "Other",
"model": ""
},
"userAgent": {
"family": "IE",
"major": "9",
"minor": "0",
"patch": null
},
"ua": {
"family": "IE",
"major": "9",
"minor": "0",
"patch": null
}
}
Content-Type:application/json
Accept:application/json
User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.1
{
"string": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.1",
"os": {
"family": "Mac OS X",
"major": "10",
"minor": "7",
"patch": "0",
"patchMinor": null
},
"device": {
"isSpider": false,
"brand": "Apple",
"family": "Mac",
"model": "Mac"
},
"userAgent": {
"family": "Chrome",
"major": "17",
"minor": "0",
"patch": "963"
},
"ua": {
"family": "Chrome",
"major": "17",
"minor": "0",
"patch": "963"
}
}
尝试解析请求来源的Ip及反查域名
通常常规的搜索引擎的爬虫机器在爬取你的网站的时候,是有固定爬虫ip的,我们反爬虫,其实不想误伤他们,毕竟有些网站还是需要依赖SEO来提高曝光率的,但是伪装成主流搜索引擎爬虫的User-Agent的成本极低,那么我们能进一步判断和区分呢?
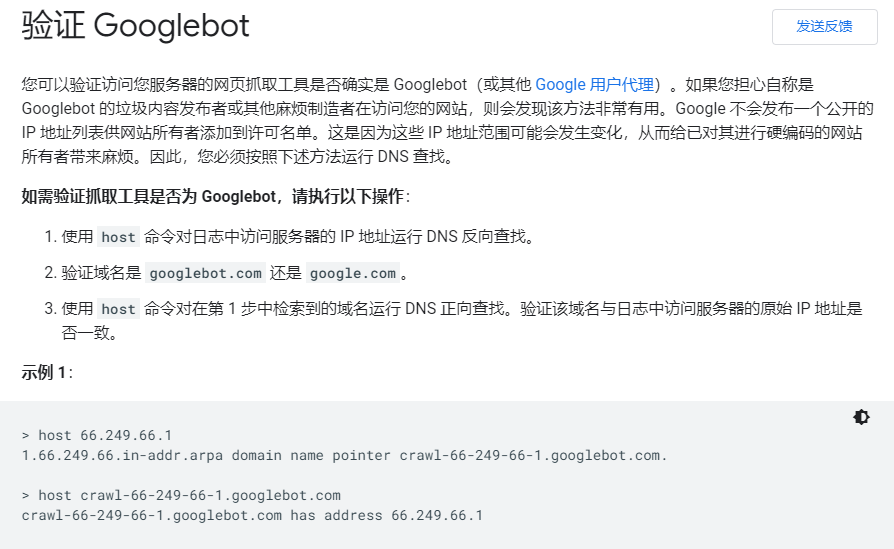
这里,我们可以用到一个叫rDNS的机制,大型的搜索引擎提供商,比如谷歌、百度以及微软均会有固定的IP地址作为爬虫的IP,并且会将这些IP做rDNS解析。可以通过查询某个IP的rDNS解析记录,来判断这个IP到底是不是真的来自谷歌或者百度。
反向DNS(rDNS或RDNS)是从IP地址查找域名的域名服务(DNS)。 常规的DNS请求将解析给定域名的IP地址; 因此名称为“ reverse”。反向DNS也称为反向DNS查找和反向DNS。
反向DNS请求通常用于过滤垃圾邮件。 垃圾邮件发送者可以使用所需的任何域名轻松地设置发送电子邮件地址,包括银行或受信任组织等合法域名。
接收电子邮件服务器可以通过使用反向DNS请求检查发送IP地址来验证传入消息。 如果电子邮件是合法的,则rDNS解析器应与电子邮件地址的域匹配。 这种技术的缺点是某些合法的邮件服务器末端没有正确的rDNS记录设置才能正确响应,因为在许多情况下,它们的ISP必须设置这些记录。

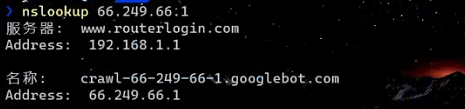
以Google的爬虫ip(66.249.66.1)为例,我们可以通过nslookup命令来反溯其域名。
尝试在NetCore中获取真实来源Ip
据说(暂时只是看网上说)在.Net Core中如果要获取真实来源Ip,默认是不行的,但是可以基于一个官方的Microsoft.AspNetCore.HttpOverrides包来实现,接下来我们安装下这个包。
https://www.nuget.org/packages/Microsoft.AspNetCore.HttpOverrides/
dotnet add package Microsoft.AspNetCore.HttpOverrides
然后在项目的Startup.cs文件的ConfigureServices方法中添加ForwardedHeadersOptions的配置支持。
public void ConfigureServices(IServiceCollection services)
{
// 添加Forwarded Headers Middleware配置
services.Configure<ForwardedHeadersOptions>(options =>
{
options.ForwardedHeaders = ForwardedHeaders.XForwardedFor | ForwardedHeaders.XForwardedProto;
options.KnownNetworks.Clear();
options.KnownProxies.Clear();
});
services.AddControllers();
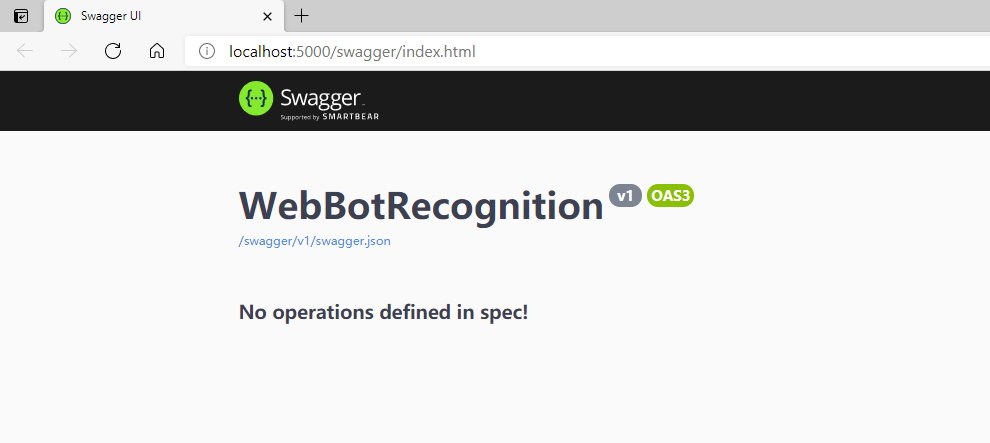
services.AddSwaggerGen(c =>
{
c.SwaggerDoc("v1", new OpenApiInfo { Title = "WebBotRecognition", Version = "v1" });
});
}
并且在Startup.cs文件的Configure方法中启用ForwardedHeaders中间件。
public void Configure(IApplicationBuilder app, IWebHostEnvironment env)
{
if (env.IsDevelopment())
{
app.UseDeveloperExceptionPage();
app.UseSwagger();
app.UseSwaggerUI(c => c.SwaggerEndpoint("/swagger/v1/swagger.json", "WebBotRecognition v1"));
}
// Forwarded Headers Middleware
app.UseForwardedHeaders();
...
}
接下来,我们就可以获取到来源真实IP地址了。
/// <summary>
/// 获取真实客户端来源Ip
/// </summary>
/// <returns></returns>
[HttpGet]
[Route("GetRealClientIpAddress")]
public async Task<JsonResult> GetRealClientIpAddress()
{
// 通过Connection的RemoteIpAddress获取IPV4的IP地址
var requestIp = Request.HttpContext.Connection.RemoteIpAddress?.MapToIPv4().ToString();
return new JsonResult(requestIp);
}
通过真实来源Ip反向查找爬虫域名
前面我们已经拿到了真实的请求IP,然后我们可以借助.Net中的DNS类来反向解析Ip地址来模拟实现nslookup命令的效果。
/// <summary>
/// 获取rDNS反向域名
/// </summary>
/// <returns></returns>
[HttpGet]
[Route("GetrDnsHostName")]
public async Task<JsonResult> GetrDnsHostName(string requestIp)
{
if(string.IsNullOrEmpty(requestIp))
{
// 通过Connection的RemoteIpAddress获取IPV4的IP地址
requestIp = Request.HttpContext.Connection.RemoteIpAddress?.MapToIPv4().ToString();
}
IPHostEntry iPHostEntry;
try
{
// 根据真实请求Ip反向解析请求Ip的域名
iPHostEntry = await Dns.GetHostEntryAsync(requestIp);
}
catch
{
iPHostEntry = null;
}
// 获取请求的域名地址
var requestHostName = iPHostEntry?.HostName;
return new JsonResult(requestHostName);
}

通过requestIp我们可以传入指定Ip,这里我们用GoogleBot的Ip做个实验,发现就能反向查找得到*.googlebot.com这样的域名。
这里注意,如果Ip反向查找不出来,会抛异常,我们要通过try-catch来稳住这个情况。
结合User-Agent和rDNS技术来判断真实的爬虫
我们可以通过UaParser来解析是否为爬虫的User Agent,同时辅助使用是否为爬虫的来源Ip来判断,这样就比较稳妥。
Content-Type:application/json
Accept:application/json
User-Agent:Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
requestIp=66.249.66.1
/// <summary>
/// 是否来自真实的爬虫机器人
/// </summary>
/// <returns></returns>
[HttpGet]
[Route("IsRealSpiderBot")]
public async Task<bool> IsRealSpiderBot(string requestIp)
{
// 定义解析结果信息对象
ClientInfo clientInfo = null;
// 尝试从头部里面获取User-Agent字符串
if(Request.Headers.TryGetValue("User-Agent", out var requestUserAgent) && !string.IsNullOrEmpty(requestUserAgent))
{
// 获取UaParser实例
var uaParser = Parser.GetDefault();
// 解析User-Agent字符串
clientInfo = uaParser.Parse(requestUserAgent);
}
if(string.IsNullOrEmpty(requestIp))
{
// 通过Connection的RemoteIpAddress获取IPV4的IP地址
requestIp = Request.HttpContext.Connection.RemoteIpAddress?.MapToIPv4().ToString();
}
IPHostEntry iPHostEntry;
try
{
// 根据真实请求Ip反向解析请求Ip的域名
iPHostEntry = await Dns.GetHostEntryAsync(requestIp);
}
catch
{
iPHostEntry = null;
}
// 获取请求的域名地址
var requestHostName = iPHostEntry?.HostName;
// 当反向解析域名不为空且UserAgent解析结果为爬虫时,才真正为爬虫机器人
var isRealSpiderBot = !string.IsNullOrEmpty(requestHostName) && (clientInfo?.Device?.IsSpider ?? false);
return isRealSpiderBot;
}
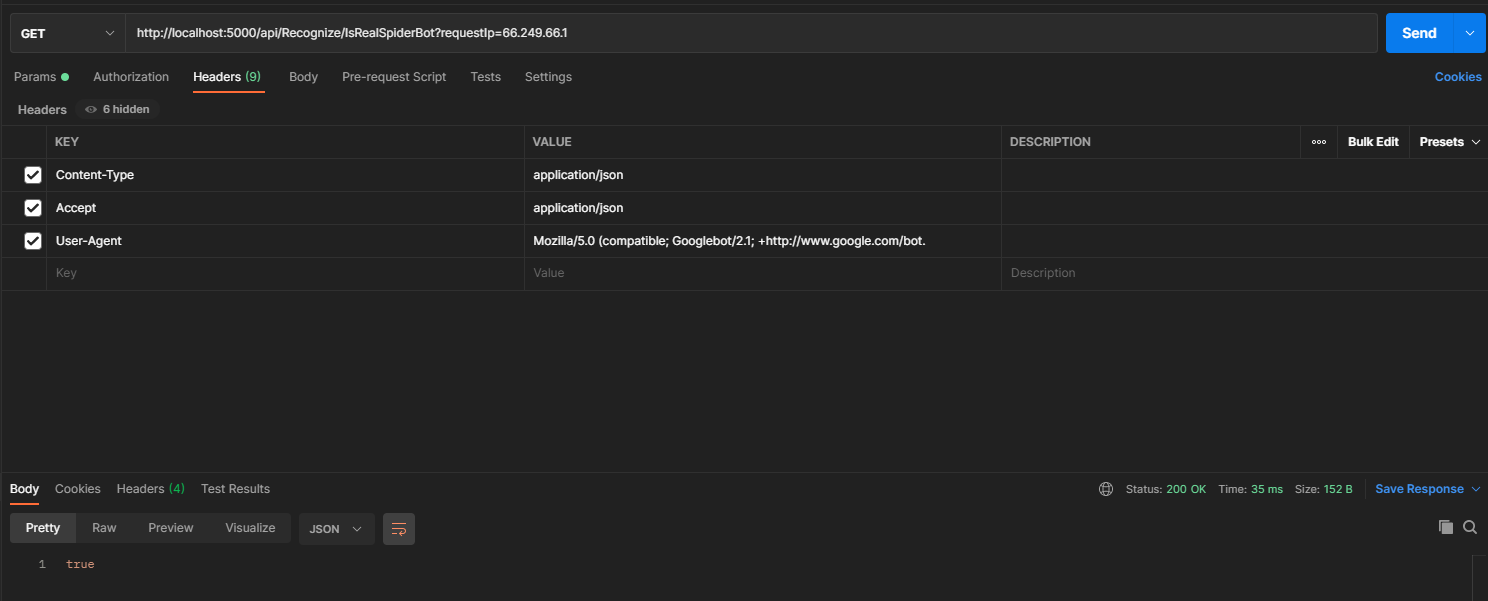
这里我们还是以Google Bot的ip为例,调用下,结果符合预期。
常见的搜索引擎爬虫的User Agent
1. GoogleBot
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
2. Bingbot
Mozilla/5.0 (compatible; Bingbot/2.0; +http://www.bing.com/bingbot.htm)
3. Slurp Bot
Mozilla/5.0 (compatible; Yahoo! Slurp; http://help.yahoo.com/help/us/ysearch/slurp)
4. DuckDuckBot
DuckDuckBot/1.0; (+http://duckduckgo.com/duckduckbot.html)
5. Baiduspider
Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)
6. Yandex Bot
Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots)
7. Sogou Spider
Sogou Pic Spider/3.0( http://www.sogou.com/docs/help/webmasters.htm#07)
Sogou head spider/3.0( http://www.sogou.com/docs/help/webmasters.htm#07)
Sogou web spider/4.0(+http://www.sogou.com/docs/help/webmasters.htm#07)
Sogou Orion spider/3.0( http://www.sogou.com/docs/help/webmasters.htm#07)
Sogou-Test-Spider/4.0 (compatible; MSIE 5.5; Windows 98)
8. Exabot
Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Exabot-Thumbnails)
Mozilla/5.0 (compatible; Exabot/3.0; +http://www.exabot.com/go/robot)
9. Facebook external hit
facebot
facebookexternalhit/1.0 (+http://www.facebook.com/externalhit_uatext.php)
facebookexternalhit/1.1 (+http://www.facebook.com/externalhit_uatext.php)
10. Alexa crawler
ia_archiver (+http://www.alexa.com/site/help/webmasters; crawler@alexa.com)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号