

Hadoop 学习之路之YARN原理
一,前言
Hadoop 2.0由三个子系统组成,分别是HDFS、YARN和MapReduce,其中,YARN是一个崭新的资源管理系统,而MapReduce则只是运行在YARN上的一个应用,如果把YARN看成一个云操作系统,那么MapReduce可认为是运行在这个操作系统上的App。
二,产生背景
YARN的出现主要是为了解决MapReduce1带来的一些问题,为了解决这些问题而开发出来的,有那些问题呢?如下:
1)JobTracker单点故障问题;如果Hadoop集群的JobTracker挂掉,则整个分布式集群都不能使用了。
2)JobTracker不但进行全局的资源管理同时也要对整个作业进行度,承受的访问压力大,影响系统的扩展性。
3)不支持MapReduce之外的计算框架,比如Storm、Spark、Flink等。
4)集群的资源利用率低。
三,YARN的工作原理
随着数据规模的膨胀,大家已经不满足于仅仅能在Hadoop集群上运行MapReduce程序,更希望能够有一套合理的管理机制来控制整个集群的资源调度,于是Yarn平台应运而生。先来看看Yarn平台的基本架构:

在Yarn的结构中,把原来JobTracker管的事儿(资源管理、任务调度)拆开了,资源调度让ResourceManager干,任务调度让 ApplicationMaster管,这样的好处就是能够让各个模块各司其职,专一干一件事,就好比一个大领导每天如果不专心管理管队,老跑去敲代码, 最后这个团队必然存在问题。言归正传,既然要了解Yarn的架构,在这里有必要先解释一下上图的各部件。
2.1 Container
容器(Container)这个东西是Yarn对资源做的一层抽象。就像我们平时开发过程中,经常需要对底层一些东西进行封装,只提供给上层一个调用接口一样,Yarn对资源的管理也是用到了这种思想。
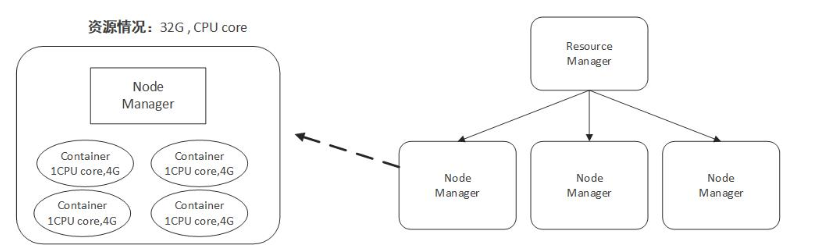
如上所示,Yarn将CPU核数,内存这些计算资源都封装成为一个个的容器(Container)。需要注意两点:
- 容器由NodeManager启动和管理,并被它所监控。
- 容器被ResourceManager进行调度。
- Container由ApplicationMaster向ResourceManager申请的,由ResouceManager中的资源调度器异步分配给ApplicationMaster;
- Container的运行是由ApplicationMaster向资源所在的NodeManager发起的,Container运行时需提供内部执行的 任务命令(可以使任何命令,比如java、Python、C++进程启动命令均可)以及该命令执行所需的环境变量和外部资源(比如词典文件、可执行文件、 jar包等)。
另外,一个应用程序所需的Container分为两大类,如下:
(1) 运行ApplicationMaster的Container:这是由ResourceManager(向内部的资源调度器)申请和启动的,用户提交应用程序时,可指定唯一的ApplicationMaster所需的资源;
(2) 运行各类任务的Container:这是由ApplicationMaster向ResourceManager申请的,并由ApplicationMaster与NodeManager通信以启动之。
以上两类Container可能在任意节点上,它们的位置通常而言是随机的,即ApplicationMaster可能与它管理的任务运行在一个节点上。
2.2 Yarn的三个主要组件
再看最上面的图,我们能直观发现的两个主要的组件是ResourceManager和NodeManager,但其实还有一个ApplicationMaster在图中没有直观显示(其实就是图中的App Mstr,图里用了简写)。三个组件构成了Yarn的全景,这三个组件的主要工作是什么,Yarn 框架又是如何让他们相互配合的呢,我们分别来看这三个组件。
ResourceManager
我们先来说说上图中最中央的那个ResourceManager(RM)。从名字上我们就能知道这个组件是负责资源管理的,在运行过程中,整个系统有且只有一个RM,系统的资源正是由RM来负责调度管理的。RM包含了两个主要的组件:定时调用器(Scheduler)以及应用管理器(ApplicationManager),我们分别来看看它们的主要工作。
-
定时调度器(Scheduler):从本质上来说,定时调度器就是一种策略,或者说一种算法。当Client提交一个任务的时候,它会根据所需要的资源以及当前集群的资源状况进行分配。注意,它只负责向应用程序分配资源,并不做监控以及应用程序的状态跟踪。
-
应用管理器(ApplicationManager):同样,听名字就能大概知道它是干嘛的。应用管理器就是负责管理Client用户提交的应用。上面不是说到定时调度器(Scheduler)不对用户提交的程序监控嘛,其实啊,监控应用的工作正是由应用管理器(ApplicationManager)完成的。
主要事件如下:
(1) NODE_REMOVED:事件NODE_REMOVED表示集群中被移除一个计算节点(可能是节点故障或者管理员主动移除),资源调度器收到该事件时需要从可分配资源总量中移除相应的资源量。
(2) NODE_ADDED:事件NODE_ADDED表示集群中增加了一个计算节点,资源调度器收到该事件时需要将新增的资源量添加到可分配资源总量中。
(3) APPLICATION_ADDED: 事件APPLICATION_ADDED 表示ResourceManager收到一个新的Application。通常而言,资源管理器需要为每个application维护一个独立的数据结 构,以便于统一管理和资源分配。资源管理器需将该Application添加到相应的数据结构中。
(4) APPLICATION_REMOVED:事件APPLICATION_REMOVED表示一个Application运行结束(可能成功或者失败),资源管理器需将该Application从相应的数据结构中清除。
(5) CONTAINER_EXPIRED:当资源调度器将一个container分配给某个ApplicationMaster后,如果该ApplicationMaster在一定时间间隔内没有使用该container,则资源调度器会对该container进行再分配。
(6) NODE_UPDATE:NodeManager 通过心跳机制向ResourceManager汇报各个container运行情况,会触发一个NODE_UDDATE事件,由于此时可能有新的 container得到释放,因此该事件会触发资源分配,也就是说,该事件是6个事件中最重要的事件,它会触发资源调度器最核心的资源分配机制。
OK,明白了资源管理器ResourceManager,那么应用程序如何申请资源,用完如何释放?这就是ApplicationMaster的责任了。
ApplicationMaster
每当Client(用户)提交一个Application(应用程序)时候,就会新建一个ApplicationMaster。由这个ApplicationMaster去与ResourceManager申请容器资源,获得资源后会将要运行的程序发送到容器上启动,然后进行分布算。
这里可能有些难以理解,为什么是把运行程序发送到容器上去运行?如果以传统的思路来看,是程序运行着不动,然后数据进进出出不停流转。但当数据量大的时候就没法这么玩了,因为海量数据移动成本太大,时间太长。但是中国有一句老话山不过来,我就过去。大数据分布式计算就是这种思想,既然大数据难以移动,那我就把容易移动的应用程序发布到各个节点进行计算呗,这就是大数据分布式计算的思路。
作用:
与RM的调度器通讯,协商管理资源分配。
与NM合作,在合适的容器中运行对应的task,并监控这些task执行。
如果container出现故障,AM会重新向调度器申请资源。
计算应用程序所需的资源量,并转化成调度器可识别的协议。
AM出现故障后,ASM会重启它,而由AM自己从之前保存的应用程序执行状态中恢复应用程序。
NodeManager
相比起上面两个组件的掌控全局,NodeManager就显得比较细微了。NodeManager是ResourceManager在每台机器的上代理,主要工作是负责容器的管理,并监控他们的资源使用情况(cpu,内存,磁盘及网络等),并且它会定期向ResourceManager/Scheduler提供这些资源使用报告,再由ResourceManager决定对节点的资源进行何种操作(分配,回收等)
作用总结:
为应用程序启动容器,同时确保申请的容器使用的资源不会超过节点上的总资源。
为task构建容器环境,包括二进制可执行文件,jars等。
为所在的节点提供了一个管理本地存储资源的简单服务,应用程序可以继续使用本地存储资源即使他没有从RM那申请。比如:MapReduce可以使用该服务程序存储map task的中间输出结果。
一个NodeManager上面可以运行多个Container,Container之间的资源互相隔离,类似于虚拟机的多个系统一样,各 自使用自己分配的资源。NodeManager会启动一个监控进行用来对运行在它上面的Container进行监控,当某个Container占用的资源 超过约定的阈值后,NodeManager就会将其杀死。
注意:Yarn中有且仅有一个ResourceManager在运行,HA的不算在内。而ApplicationMaster没提交一个任务都会创建一个。二nodeManager有多个。
四,提交一个Application到Yarn的流程
流程图一:
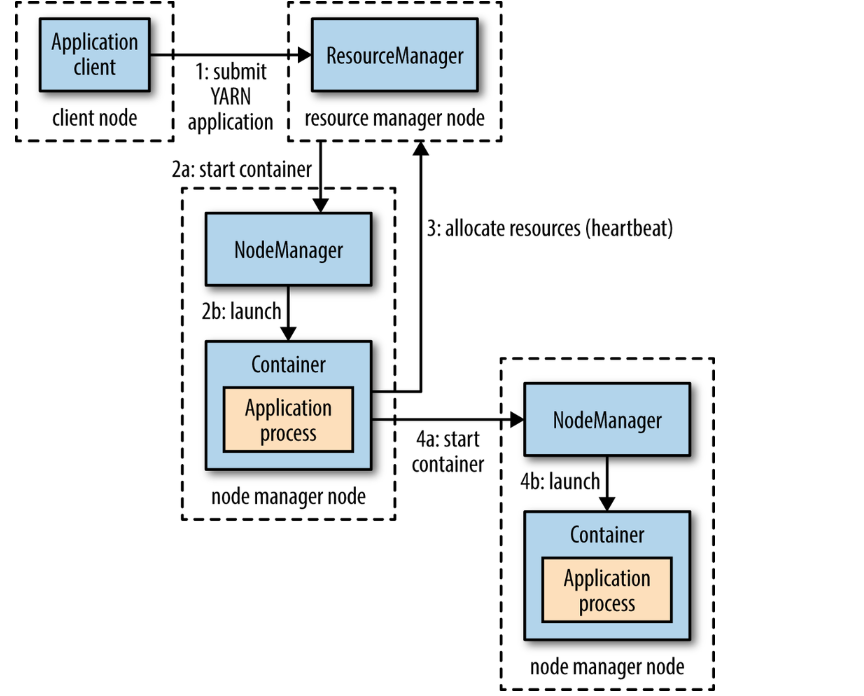
我对上面的流程图进行了一个简化,如下图
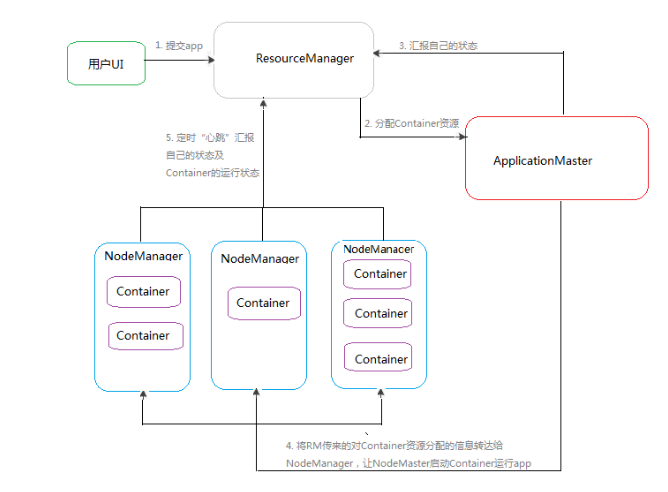
这张图简单地标明了提交一个程序所经历的流程,接下来我们来具体说说每一步的过程。
-
Client向Yarn提交Application,这里我们假设是一个MapReduce作业。
-
ResourceManager向NodeManager通信,为该Application分配第一个容器。并在这个容器中运行这个应用程序对应的ApplicationMaster。
-
ApplicationMaster启动以后,对作业(也就是Application)进行拆分,拆分task出来,这些task可以运行在一个或多个容器中。然后向ResourceManager申请要运行程序的容器,并定时向ResourceManager发送心跳。
-
申请到容器后,ApplicationMaster会去和容器对应的NodeManager通信,而后将作业分发到对应的NodeManager中的容器去运行,这里会将拆分后的MapReduce进行分发,对应容器中运行的可能是Map任务,也可能是Reduce任务。
-
容器中运行的任务会向ApplicationMaster发送心跳,汇报自身情况。当程序运行完成后,ApplicationMaster再向ResourceManager注销并释放容器资源。
以上就是一个作业的大体运行流程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号