


OO第三单元总结
OO第三单元总结
JML基础语法
JML(Java Modeling Language)是用于对Java程序进行规格化设计的一种表示语言。
我理解的JML最大的特点在于它的逻辑严格的规格描述。因为用自然语言来描述一个方法是用来干什么,这是非常模糊而且不清楚的,使用JML以后,我们只需要通过阅读JML就能知道方法要干什么,而不用再去花费时间阅读方法的代码,这样可以使得大型工程的分工合作更加便捷。
表达式
原子表达式
- \result表达式:表示一个非void方法的执行所获得的返回值
- \old(expr)表达式:用来表示一个表达式expr在相应方法执行前的取值。注意在任何情况下都应该使用\old把关心的表达式整体括起来。这里注意\old(v.size())和\old(v).size()的巨大区别!
- \not assigned(x,y,...)表达式:用来表示括号中的变量是否在方法执行过程中被赋值。如果没有被赋值,返回为true,否则返回false
- \not modified(x,y,...)表达式:与上面的\not assigned类似。限制括号中的变量在方法执行期间的取值未发生变化
- \nonnullelememts(container)表达式:表示container对象中存储的对象不会有null
- \type(type)表达式:返回类型type对应的类型(Class)
- \typeof(expr)表达式:返回expr对应的准确类型,注意与\type的区别
量化表达式
- \forall:表示对于给定范围内的元素,每个元素都满足相应的约束
- \exist:表示对于给定范围内的元素。存在某个元素满足相应的约束
- \sum:返回给定范围内的表达式的和
- \product:返回给定范围内的表达式的连乘结果
- \max:返回给定范围内的表达式的最大值
- \min:返回给定范围内的表达式的最小值
- \num_of:返回给定制定变量中满足相应条件的取值个数
操作符
- 子类型关系操作符:E1<:E2
- 等价关系操作符:<==> && <=!=> 同 == && !=,唯一区别是<==>优先级比==高
- 推理操作符:b_expr1==>b_expr2
- 变量引用操作符:\nothing只是一个空集,\everything指示一个全集
方法规格
- 前置条件:前置条件通过requires字句来表示:
requires P;前置条件要求调用者确保调用时满足相应的前置条件。如果不满足前置条件,方法执行结果不可预测。所以我们在代码的正常行为规格中必须要考虑前置条件的影响!!!(该if判断就要if) - 后置条件:
ensures P;方法实现者必须确保方法执行满足谓词P - 副作用范围限定:assignable, modifiable
- public normal_behavior && public exceptional_behavior,注意同一个方法的正常功能前置条件和异常功能前置条件一定不重叠。
- signals子句强调在对象状态满足某个条件时会抛出符合相应类型的异常;而signals_only则不强调对象状态条件,强调满足前置条件时抛出相应的异常。
类型规格
类型规格指针对JAVA中程序中定义的数据类型所设计的限制规则,这要设计两类,不变式(invariant)限制和约束(constraints)限制。
- 不变式invariant:不变式是要求在所有可见状态下都必须满足的特性,可见状态简言之就是除了方法正在执行的状态。分为静态不变式和实例不变式。
- 状态变化约束constraint:对前序可见状态和当前可见状态的关系进行约束,即在方法执行的过程中进行约束,例如constraint counter == \old(counter)+1
应用工具链情况
这单元我用了Junit,JunitNG,openJML三个工具链进行测试,以下具体叙述
部署SMT Solver
介绍
SMT是⼀款基于数理逻辑的⽤于⾃动化验证函数正确性的⼯具,其⽀持多平台的SMT解释器(SMT Solver),其中应⽤最⼴泛的平台之⼀是微软所研发的 z3。
类型检查(Parsing and Type-checking)
OpenJML最基本的功能就是对JML注释的完整性进行检查。检查包括经典的类型检查、变量可见性与可写性等。这里的检查是对JML语法的基础检查
Person.java没问题
Group.java
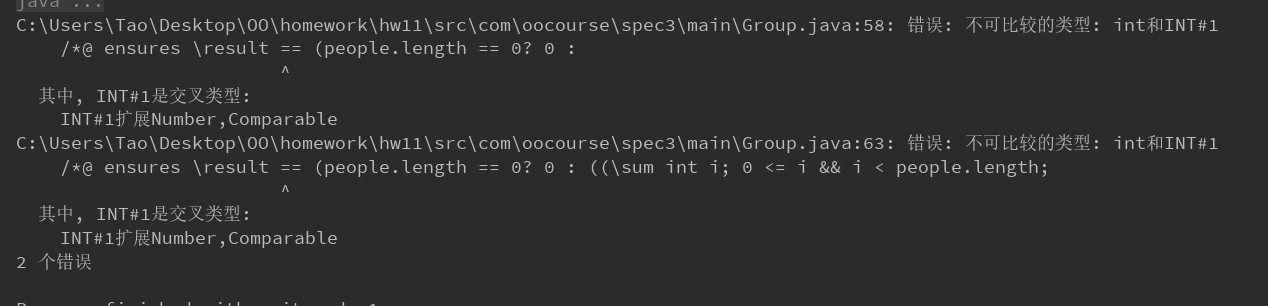
NetWork.java

从结果来看是说比较的类型不一样,我觉得是由于这个工具不支持三目运算符所导致的
静态检查(Extended Static Checking)
与类型检查的结果保持一样,说明类的实现表面上没有问题
运行时检查(Runtime Assertion Checking)
MyGroup.java
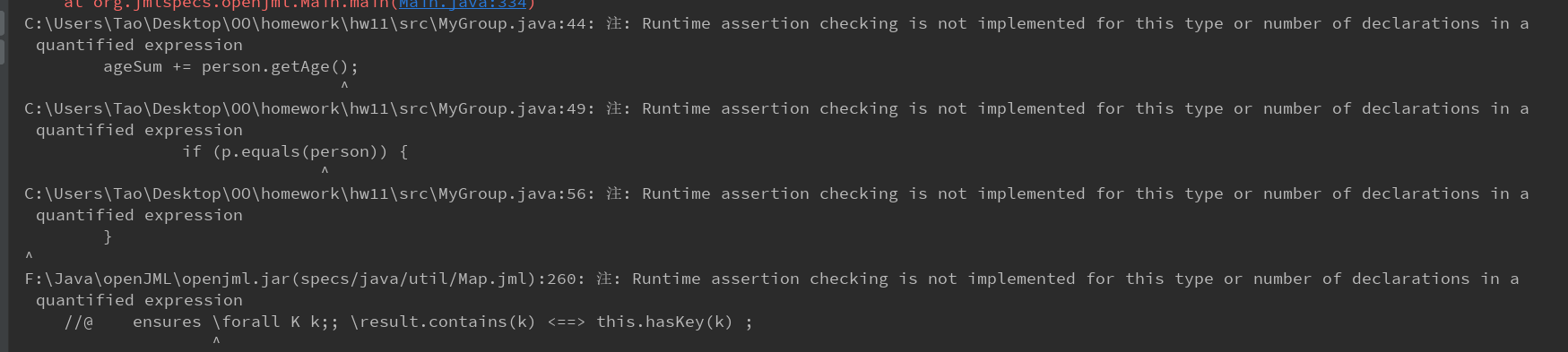
MyNetwork.java
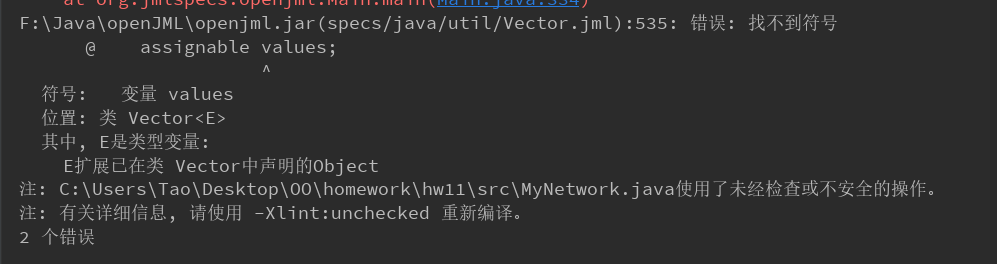
运行时检查的报错我看不太懂,以我的理解来说是好像这个工具不支持某些运行时的检查
部署JMLUnitNG
依次输入下面5条指令
java -jar jmlunitng.jar test/Person.java`
javac -cp jmlunitng.jar test/*.java
java -jar openjml.jar -rac test/Person.java
javac -cp jmlunitng.jar test/Person_JML_Test.java
java -cp jmlunitng.jar test.Group_JML_Test
得到Person.java的结果
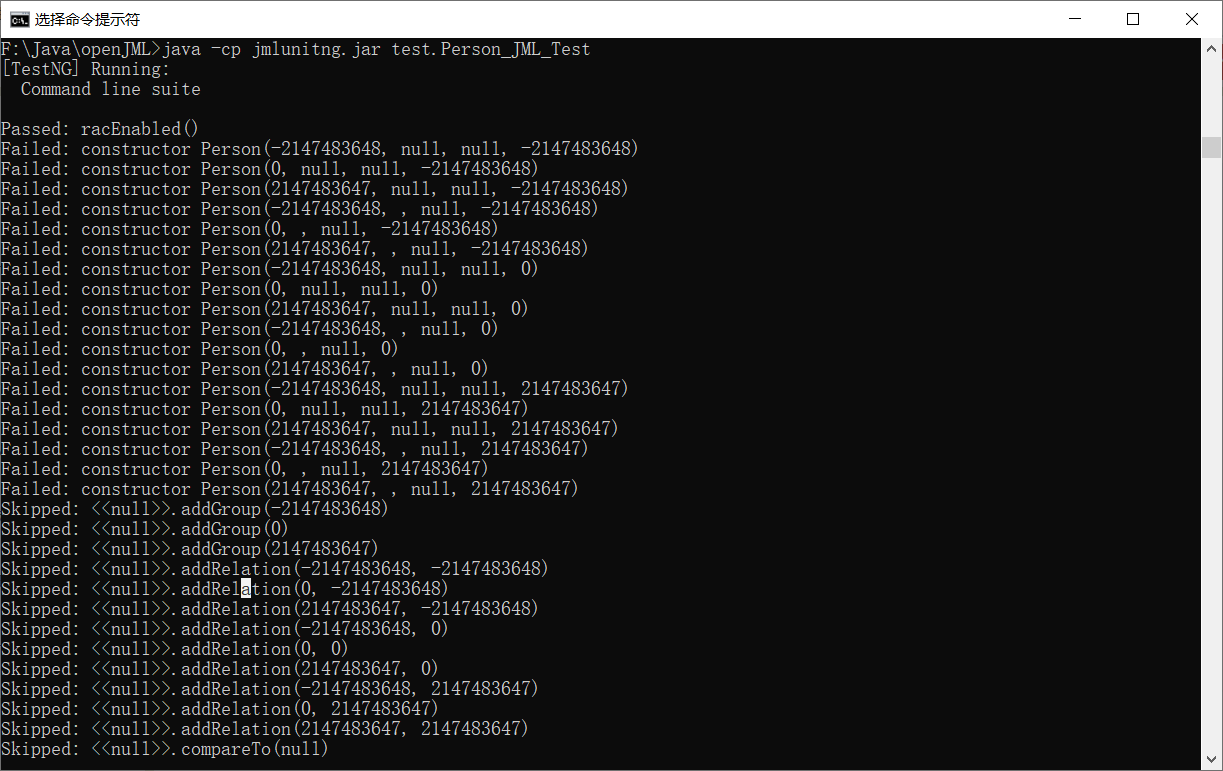
同理可以得到Group.java的结果

可以看到检测出来的问题基本都是算数溢出或者是null的一些问题
所以从JMLUnitNG⽣成的测试样例来看,⼤多测试的都是边界数据。因此JMLUnitNG可以作为⼀个提醒程序员考虑数据边界的辅助测试⼯具,但是程序正确性的保证,还是需要JUnit进⾏单元测试以及考虑⾃动或⼿动构造更多的测试样例。从现实来看这些测试样例的错误其实都是被runner会处理的,也就是说,我们需要做到的是用户输出带来的错误会由我们进行处理并且反馈给用户,只有这样程序才能越来越健壮。
梳理架构设计
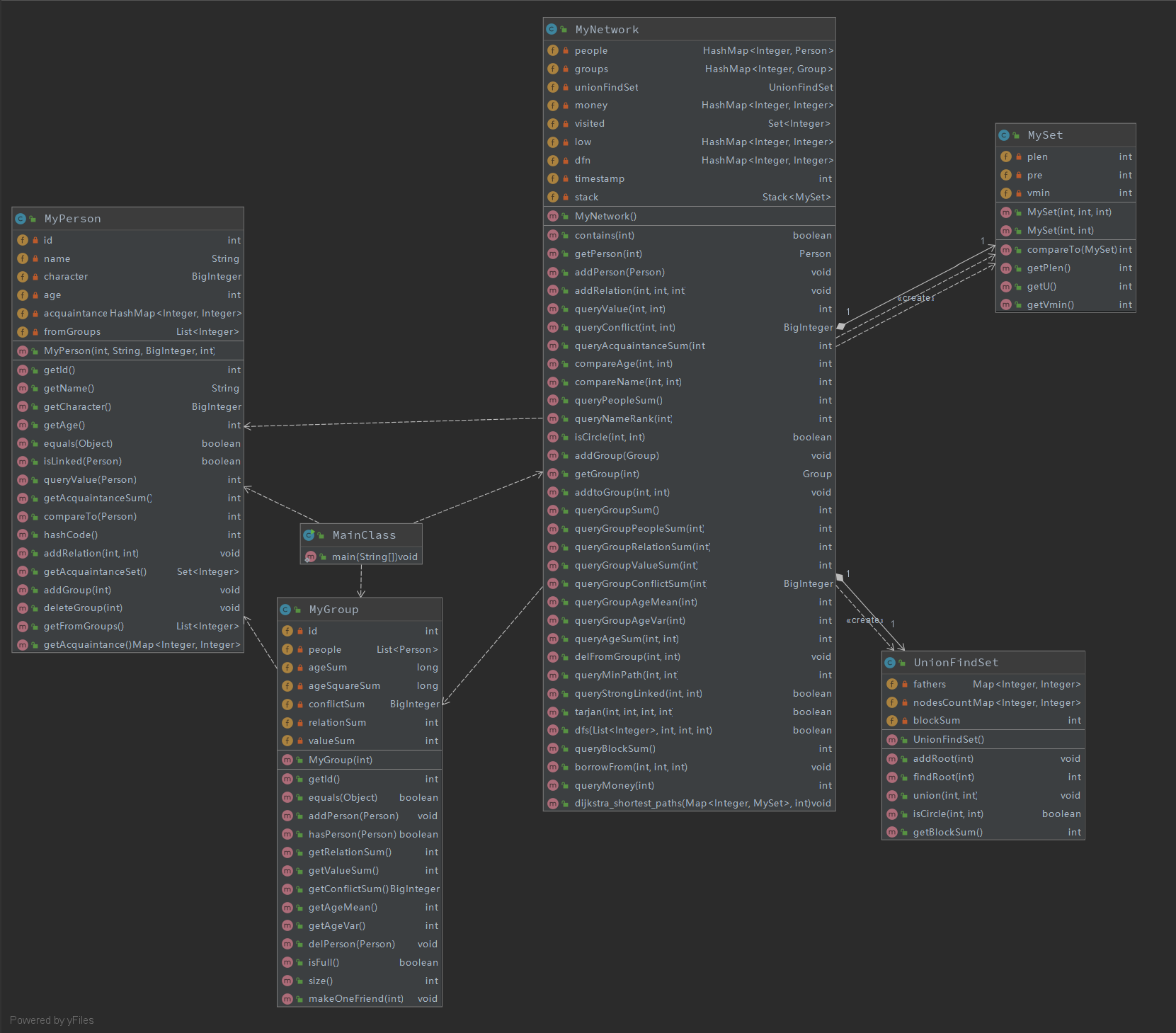
由于三次作业迭代开发,这里仅放第三次作业的UML图
第三次作业 UML 图
复杂度分析

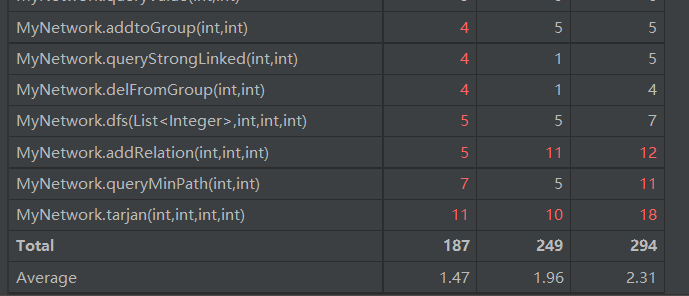
这里我列出了所有标红的方法,这些方法的复杂度都有些高,这些都是由于算法的复杂度偏高所导致的,解决的方法是把一个方法分成多个方法,这样可以降低复杂度。
我的模型架构设计主要是根据JML规格来进行设计。这三次作业的图由addRelation的规格可以很容易看出来是无向图,因此以下所有的图都指的是无向图。
类的设计
因为有三个接口,所以也设计了相对应的三个类:Myperson.java,MyGroup.java,MyNetwork.java,然后根据我的算法设计,由于isCircle需要用到并查集算法,于是我又设计了一个类交UnionFindSet,由于在Dijkstra算法中需要存三元组,于是我也相对应设计了MySet类
属性的设计
由于要存所有的人,而且还要方便的根据人的id来找人,因此存储这种映射关系的最佳容器绝对是HashMap,没有之一,使用HashMap来查找可以做到O(1)。就是所有有着映射关系的都可以存成一个HashMap是绝对不亏的一种方法。
方法的设计
-
isCircle:这个方法主要判断两个人之间存不存在通路。这个方法我在HW9的时候是直接采用BFS宽度优先搜索来实现的,但是由于在HW10指令数加到了30000条,我担心会超时,于是改成了并查集算法。并查集的思路在于每次往图里新加人的时候,创建一个新的树,并把这个人作为树根。在加边的时候,先找到这两个节点所在树的树根,然后让一个树的树根是另外一个树的树根的子节点。为了让树更加扁,在遍历找根节点的时候,让节点的父亲是节点的爷爷,然后再让小的树是大的树的树根的子节点。以上都是用HashMap存储节点和它的父节点来实现的。在判断是不是连通的时候,只需要判断这两个节点是不是在一棵树上就可以,即找他们的树根是不是同一个。这样一套操作下来基本上可以实现查找是O(1)的。
-
queryBlockSum:这个方法的含义是找连通集的数目。这个方法其实也有两种算法。一种是BFS遍历所有的节点,这个方法的复杂度是O(n)。另外一种方法还是并查集,维护一个总的连通集的数目。只需要在加人的时候让连通集的数目加1,在addRelation的时候,如果这两个人不在一棵树上,让连通集的数目减1,这样最后的复杂度也是O(1)。所以总结来说,如果不用删除边,那么并查集绝对是最好的方法,没有之一
-
queryMinPath:这个方法的含义是找两个节点之间的最短路径。最短路径通常都有两种算法,一种是求解单源最短路径Dijkstra算法,复杂度为O(n2),一种是求解多源最短路径的Floyd算法,复杂度为O(n3)。由于这个题只需要求解一个点到另外一个点的最短路径,因此选择Dijkstra算法
-
queryStrongLinked:这个方法的含义是求解两个点之间是不是双连通的。注意这里的命名是非常有歧义的,根据方法字面的含义是求是否强连通,但是JML规格很明显地指出来是求两个点之间是否有两条不一样的路径,这两条路径只有起点和终点相同。所以这告诉我们不能只从方法的字面含义去理解方法,要真正地读懂JML才是最关键的。简单来说就是求解这两个点是不是在一个点双连通分量里面。初始一想可能觉得很简单,用两次bfs,第二次的时候去掉第一次时遍历到的顶点不就行了吗,但这样做是错误的!!有明显的反例,这告诉我们不要想当然。这个方法基本上来说有两种算法,第一种是做n次bfs遍历,每次都去掉一个点,看是不是连通的,如果n次下来都是连通的,那么就是点双连通的,因为说明对这两个点之间所有的路径来说,没有必须经过的点,所以这两个点之间一定是点双连通的。复杂度简单分析可知是O(V*(V+E)),略高,但是考虑到只有20条qsl指令来说,应该可以接受。第二种方法就是大名鼎鼎的,也是我采用的tarjan算法。这个厉害的人在图领域发明了无数非常强的算法,令我非常钦佩。这个算法可以做到只用一遍DFS遍历就可以求出所有的点双连通分量。以下是对tarjan算法的简要介绍和分析:
- 搜索树:dfs遍历得到的一棵树
- dfn:时间戳,代表dfs时遍历的先后顺序
- low:追溯值,代表一个点可以不经过父节点所能到达的最早的点的时间戳。基于此定义,我们知道这个值实际上定义为下列节点时间戳的最小值:
- x的子树中的节点
- 通过一条不在搜索树上的边,能够达到搜索树上的那个节点
这个算法的原理在于遍历可以找到点u,u存在子节点v,当low(v)大于等于dfn(u)时,u为割点。因为此时代表着v必须经过u才能到达上面的点,说明u是割点。而在遍历的过程中把边存到栈里面,在找到割点的时候弹栈,一直弹到(u,v)出来,这些边上的点构成了一个边双连通分量。
纵观整个三次作业,会发现三次作业都是无向图,而且都只能加边,不能去边,而且边的权值都只能是正的,这些限定条件事实上是降低了我们编写代码的难度。或许在不远的将来,我们就会遇到这些更加困难的需求吧。
作业bug分析
第一次作业
第一次作业未出现bug,我也没有找到互测屋中成员bug
第二次作业
第二次作业出现了一个愚蠢的bug,就是(int)-3.5我认为是-4,但实际上是-3,这个bug出现在getAgeVar中,这个bug的原因是我又再一次想当然了,而且也没有做好充足的测试所导致的。互测中着重测试了未优化Group的各种参数查询的bug,采用大量的queryGroup***来hack。
第三次作业
第三次作业中我有一个愚蠢的bug,就是当Arraylist中存的是Integer时,arraylist的remove方法是重载了两种参数,第一种是根究index,即下标,第二种是remove一个元素。这个时候我用Arraylist的remove方法就直接参数里用的数字,导致被当成下标去remove,报出IndexOutOfBounds,解决方案有两种,第一种是remove(Integer.valueof(int a)),第二种是remove(new Integer(int a)),这两种方法都可以解决问题。互测中着重去测试qsl,qmp,qbs三个方法的复杂度。
规格撰写和体会
-
经历了这一单元的学习,我发现规格真的是很有用的一个东西,很多大型程序的设计真的离不开规格,我对规格的理解就是写程序的人和用程序的人之间的纽带。好的规格有助于很好的扩展性,代码的可维护性,可读性。
-
所以写程序前先写规格,做好规格化的设计很重要。毕竟有可能算法大家都一样,但是规格的设计确是每个人都不一样的,这从第一二单元的作业可以很好的看出来。
-
规格的好处不仅于此,形式化的设计可以形式化的来进行验证。例如openjml和JMLUnitNG等工具链的完善和形成使得规格化设计如虎添翼。
-
这单元我学会了JML规格的相关语法知识,以及JML相关工具链的用法,以及各种大师们的算法,可谓是受益匪浅。希望下个单元能够继续加油!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号