Hive
Hive
Hive官网:https://hive.apache.org/
简介
Hive是由Facebook开发,后来由Apache软件基金会开发,并作为进一步将它作为名义下Apache Hive为一个开源项目。Hive 没有专门的数据格式。 Hive 可以很好的工作在 Thrift 之上,控制分隔符,也允许用户指定数据格式。Hive不适用于在线事务处理。 它最适用于传统的数据仓库任务。
Hive是一个数据仓库基础工具在Hadoop中用来处理结构化数据。它架构在Hadoop之上,总归为大数据,并使得查询和分析方便。并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。
Hive 构建在基于静态批处理的Hadoop 之上,Hadoop 通常都有较高的延迟并且在作业提交和调度的时候需要大量的开销。因此,Hive 并不能够在大规模数据集上实现低延迟快速的查询,例如,Hive 在几百MB 的数据集上执行查询一般有分钟级的时间延迟。因此,
Hive 并不适合那些需要低延迟的应用,例如,联机事务处理(OLTP)。Hive 查询操作过程严格遵守Hadoop MapReduce 的作业执行模型,Hive 将用户的HiveQL 语句通过解释器转换为MapReduce 作业提交到Hadoop 集群上,Hadoop 监控作业执行过程,然后返回作业执行结果给用户。Hive 并非为联机事务处理而设计,Hive 并不提供实时的查询和基于行级的数据更新操作。Hive 的最佳使用场合是大数据集的批处理作业,例如,网络日志分析。
Hive vs 传统数据库
由于Hive采用了SQL的查询语言HQL,因此很容易将Hive理解为数据库。其实从结构上来看,Hive和数据库除了拥有类似的查询语言,再无类似之处。数据库可以用在Online的应用中,但是Hive是为数据仓库而设计的,清楚这一点,有助于从应用角度理解Hive的特性。Hive和数据库的比较如下表:
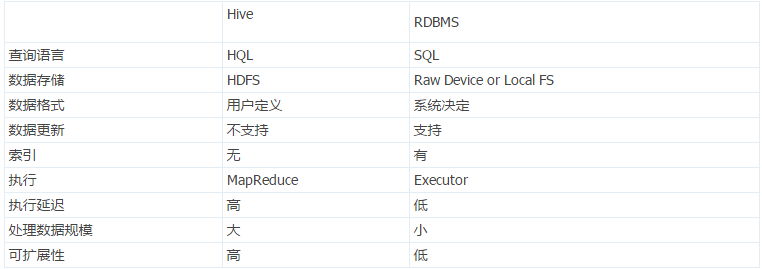
#从上如可以看到它们之间的差别。
- 查询语言。由于 SQL 被广泛的应用在数据仓库中,因此专门针对Hive的特性设计了类SQL的查询语言HQL。熟悉SQL开发的开发者可以很方便的使用Hive进行开发。
- 数据存储位置。Hive是建立在Hadoop之上的,所有Hive的数据都是存储在HDFS中的。而数据库则可以将数据保存在块设备或者本地文件系统中。
- 数据格式。Hive中没有定义专门的数据格式,数据格式可以由用户指定,用户定义数据格式需要指定三个属性:列分隔符(通常为空格、”\t”、”\x001″)、行分隔符(”\n”)以及读取文件数据的方法(Hive中默认有三个文件格式TextFile,SequenceFile以及RCFile)。由于在加载数据的过程中,不需要从用户数据格式到Hive定义的数据格式的转换,因此,
Hive在加载的过程中不会对数据本身进行任何修改,而只是将数据内容复制或者移动到相应的HDFS目录中。
而在数据库中,不同的数据库有不同的存储引擎,定义了自己的数据格式。所有数据都会按照一定的组织存储,因此,数据库加载数据的过程会比较耗时。 - 数据更新。由于Hive是针对数据仓库应用设计的,而数据仓库的内容是读多写少的。因此,Hive中不支持对数据的改写和添加,所有的数据都是在加载的时候中确定好的。而数据库中的数据通常是需要经常进行修改的,因此可以使用INSERT INTO ... VALUES添加数据,使用UPDATE ... SET修改数据。
- 索引。之前已经说过,Hive在加载数据的过程中不会对数据进行任何处理,甚至不会对数据进行扫描,因此也没有对数据中的某些Key建立索引。Hive要访问数据中满足条件的特定值时,需要暴力扫描整个数据,因此访问延迟较高。由于MapReduce的引入, Hive可以并行访问数据,因此即使没有索引,对于大数据量的访问,Hive仍然可以体现出优势。数据库中,通常会针对一个或者几个列建立索引,因此对于少量的特定条件的数据的访问,数据库可以有很高的效率,较低的延迟。由于数据的访问延迟较高,决定了Hive不适合在线数据查询。
- 执行。Hive中大多数查询的执行是通过Hadoop提供的MapReduce来实现的(类似select * from tbl的查询不需要MapReduce)。而数据库通常有自己的执行引擎。
- 执行延迟。之前提到,Hive在查询数据的时候,由于没有索引,需要扫描整个表,因此延迟较高。另外一个导致Hive执行延迟高的因素是MapReduce框架。由于MapReduce本身具有较高的延迟,因此在利用MapReduce执行Hive查询时,也会有较高的延迟。相对的,数据库的执行延迟较低。当然,这个低是有条件的,即数据规模较小,当数据规模大到超过数据库的处理能力的时候,Hive的并行计算显然能体现出优势。
- 可扩展性。由于Hive是建立在Hadoop之上的,因此Hive的可扩展性是和Hadoop的可扩展性是一致的。而数据库由于ACID语义的严格限制,扩展行非常有限。
- 数据规模。由于Hive建立在集群上并可以利用MapReduce进行并行计算,因此可以支持很大规模的数据;对应的,数据库可以支持的数据规模较小。
Hive的数据模型介绍:
官网介绍:https://cwiki.apache.org/confluence/display/Hive/Tutorial
创建表Bash
create external if not exists test_table (
key string
)
加载数据Bash
LOAD DATA INPATH 'filepath' OVERWRITE INTO TABLE test_table
查看数据Bash
select * from test_inner_table; select count(*) from test_table
删除表Bash
drop table test_table
Hive 新手常见问题
1.group by
2.alter table table_name add columns (column_1 string,column_2 int) # 增加字段只能表最后加
3.decimal # 未设置精度默认取整
4.null与"" # 不相等
