多路复用
IO多路复用
阻塞 IO
服务端为了处理客户端的连接和请求的数据,写了如下代码。
listenfd = socket(); // 打开一个网络通信端口
bind(listenfd); // 绑定
listen(listenfd); // 监听
while(1) {
connfd = accept(listenfd); // 阻塞建立连接
int n = read(connfd, buf); // 阻塞读数据
doSomeThing(buf); // 利用读到的数据做些什么
close(connfd); // 关闭连接,循环等待下一个连接
}
这段代码会执行得磕磕绊绊,就像这样。

可以看到,服务端的线程阻塞在了两个地方,一个是 accept 函数,一个是 read 函数。
如果再把 read 函数的细节展开,我们会发现其阻塞在了两个阶段。
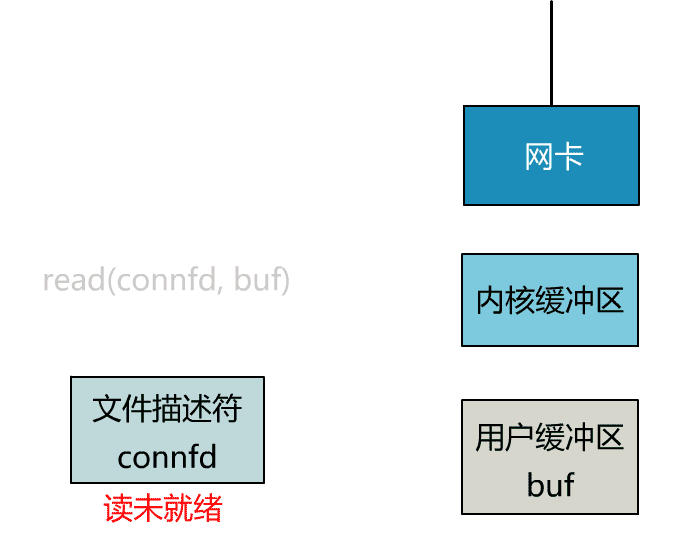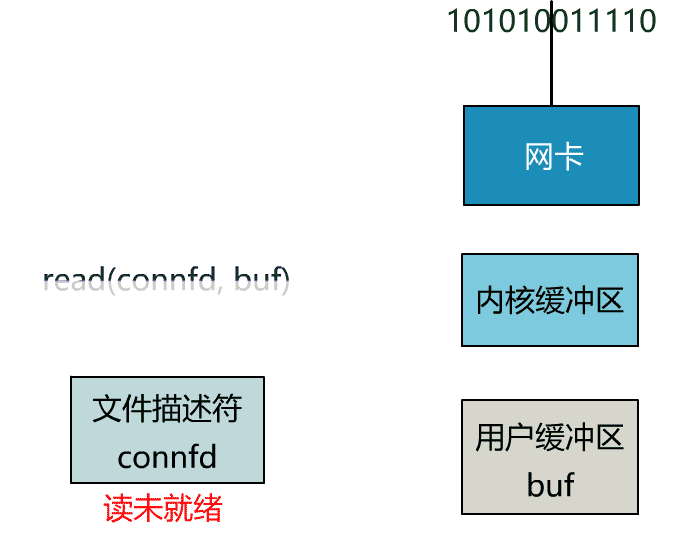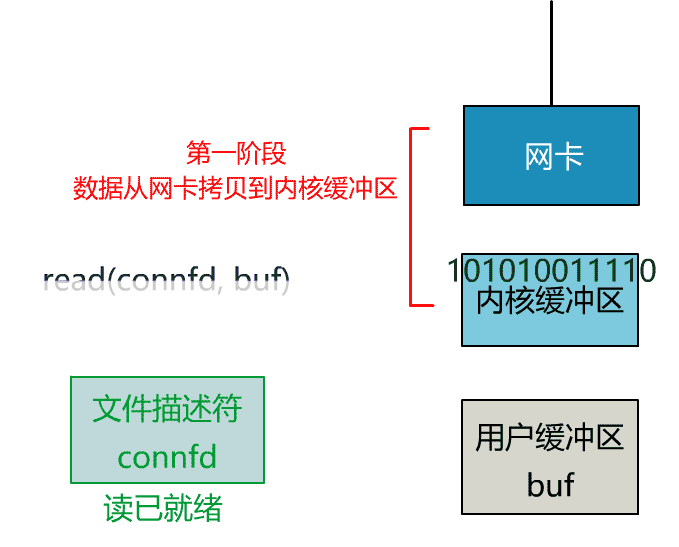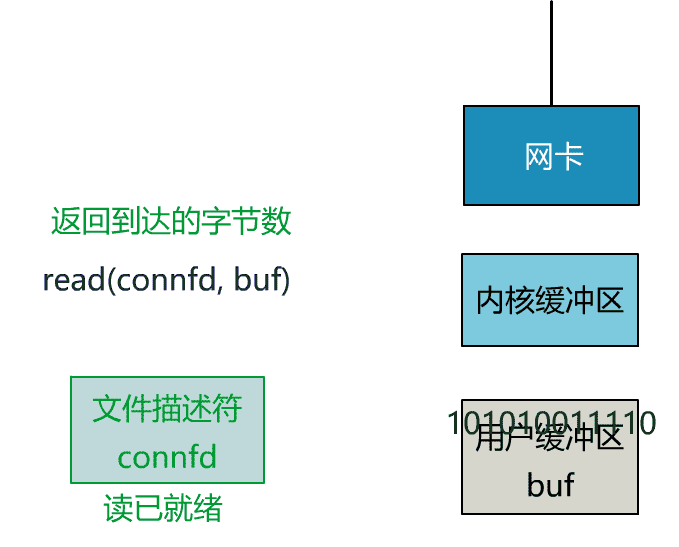
这就是传统的阻塞 IO。
整体流程如下图。
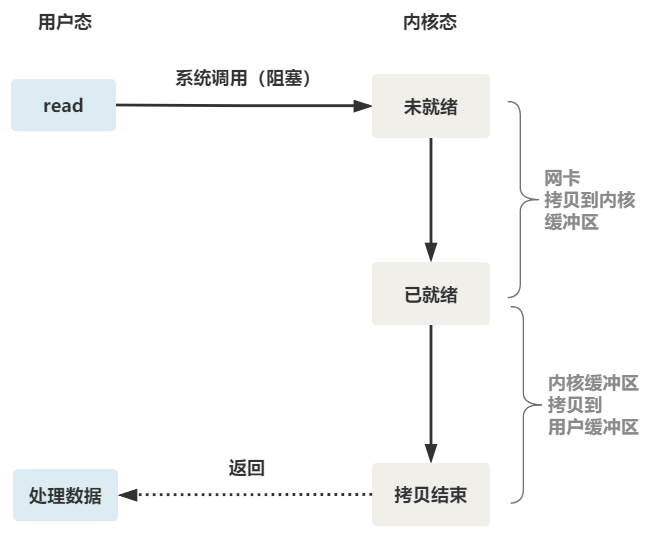
所以,如果这个连接的客户端一直不发数据,那么服务端线程将会一直阻塞在 read 函数上不返回,也无法接受其他客户端连接。
这肯定是不行的。
非阻塞 IO
为了解决上面的问题,其关键在于改造这个 read 函数。
有一种聪明的办法是,每次都创建一个新的进程或线程,去调用 read 函数,并做业务处理。
while(1) {
connfd = accept(listenfd); // 阻塞建立连接
pthread_create(doWork); // 创建一个新的线程
}
void doWork() {
int n = read(connfd, buf); // 阻塞读数据
doSomeThing(buf); // 利用读到的数据做些什么
close(connfd); // 关闭连接,循环等待下一个连接
}
这样,当给一个客户端建立好连接后,就可以立刻等待新的客户端连接,而不用阻塞在原客户端的 read 请求上。

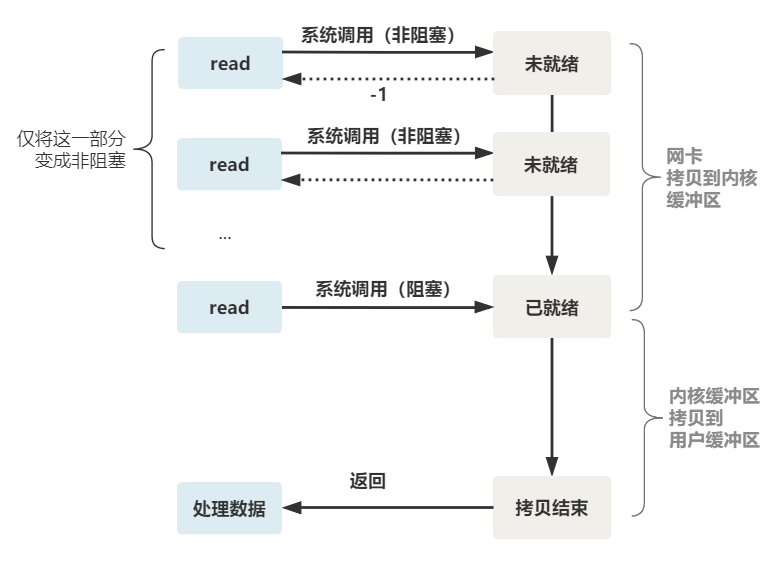
不过,这不叫非阻塞 IO,只不过用了多线程的手段使得主线程没有卡在 read 函数上不往下走罢了。操作系统为我们提供的 read 函数仍然是阻塞的。
所以真正的非阻塞 IO,不能是通过我们用户层的小把戏,而是要恳请操作系统为我们提供一个非阻塞的 read 函数。
这个 read 函数的效果是,如果没有数据到达时(到达网卡并拷贝到了内核缓冲区),立刻返回一个错误值(-1),而不是阻塞地等待。
操作系统提供了这样的功能,只需要在调用 read 前,将文件描述符设置为非阻塞即可。
fcntl(connfd, F_SETFL, O_NONBLOCK);
int n = read(connfd, buffer) != SUCCESS);
这样,就需要用户线程循环调用 read,直到返回值不为 -1,再开始处理业务。
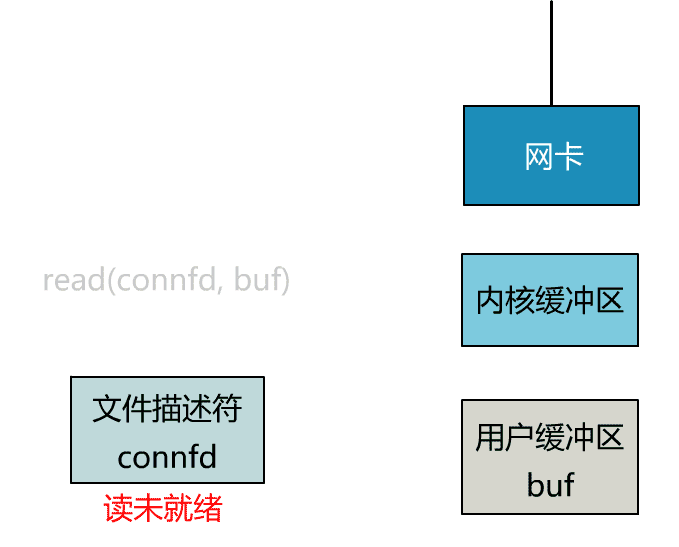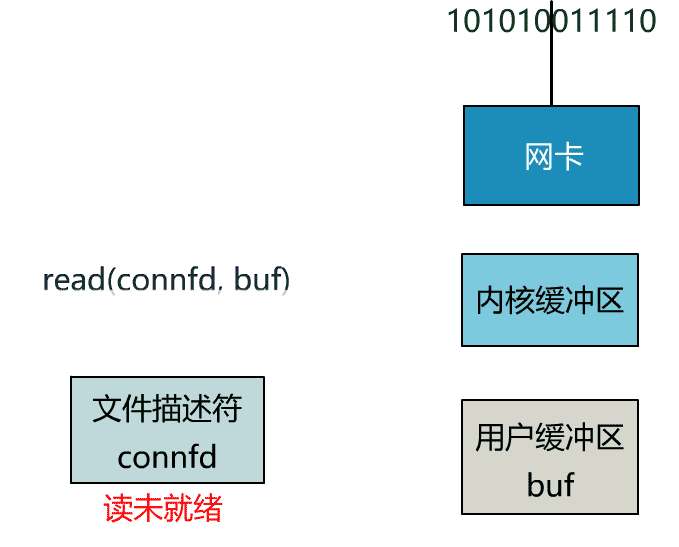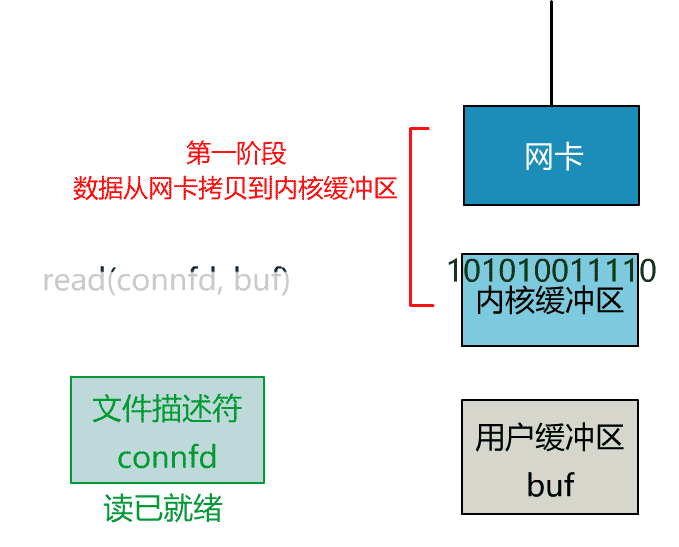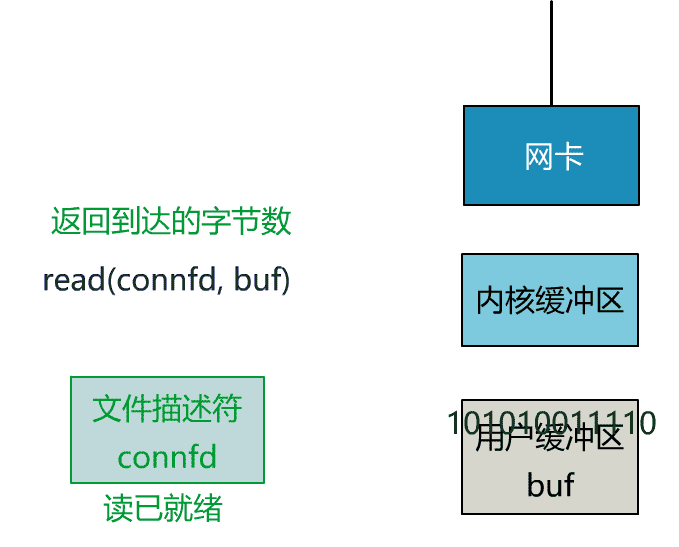
这里我们注意到一个细节。
非阻塞的 read,指的是在数据到达前,即数据还未到达网卡,或者到达网卡但还没有拷贝到内核缓冲区之前,这个阶段是非阻塞的。
当数据已到达内核缓冲区,此时调用 read 函数仍然是阻塞的,需要等待数据从内核缓冲区拷贝到用户缓冲区,才能返回。
整体流程如下图
IO 多路复用
为每个客户端创建一个线程,服务器端的线程资源很容易被耗光。
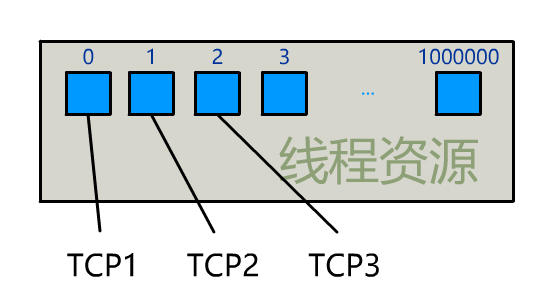
当然还有个聪明的办法,我们可以每 accept 一个客户端连接后,将这个文件描述符(connfd)放到一个数组里。
fdlist.add(connfd);
然后弄一个新的线程去不断遍历这个数组,调用每一个元素的非阻塞 read 方法。
while(1) {
for(fd <-- fdlist) {
if(read(fd) != -1) {
doSomeThing();
}
}
}
这样,我们就成功用一个线程处理了多个客户端连接。
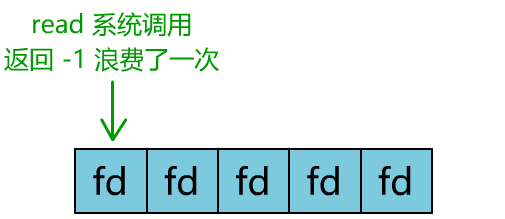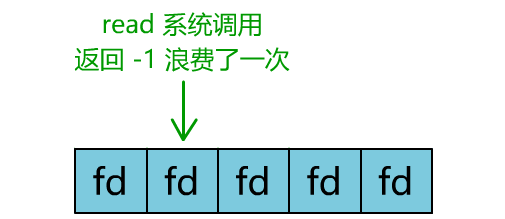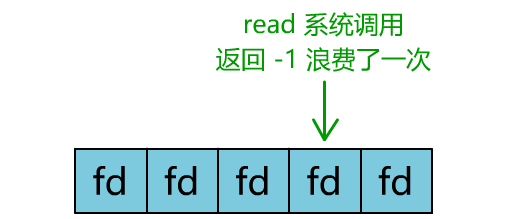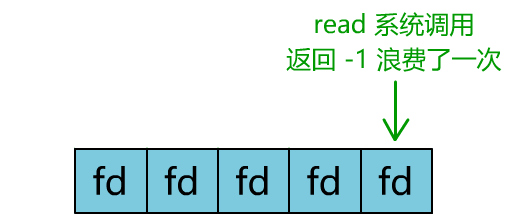
你是不是觉得这有些多路复用的意思?
但这和我们用多线程去将阻塞 IO 改造成看起来是非阻塞 IO 一样,这种遍历方式也只是我们用户自己想出的小把戏,每次遍历遇到 read 返回 -1 时仍然是一次浪费资源的系统调用。
在 while 循环里做系统调用,就好比你做分布式项目时在 while 里做 rpc 请求一样,是不划算的。
所以,还是得恳请操作系统老大,提供给我们一个有这样效果的函数,我们将一批文件描述符通过一次系统调用传给内核,由内核层去遍历,才能真正解决这个问题。
select
select 是操作系统提供的系统调用函数,通过它,我们可以把一个文件描述符的数组发给操作系统, 让操作系统去遍历,确定哪个文件描述符可以读写, 然后告诉我们去处理:
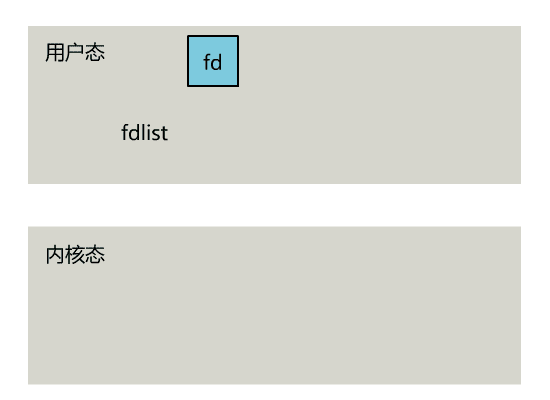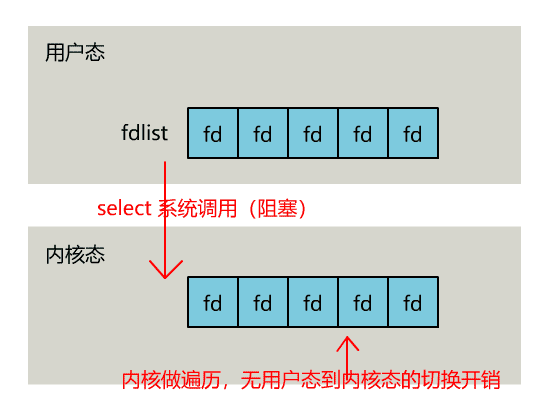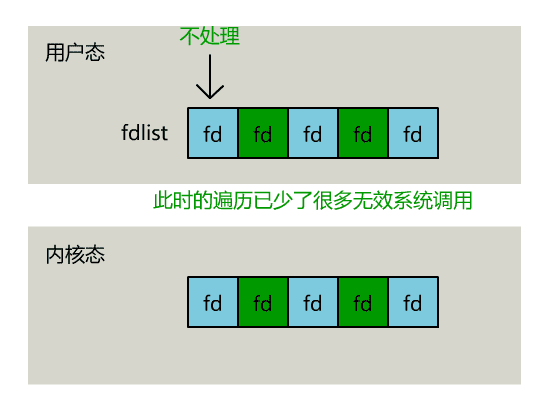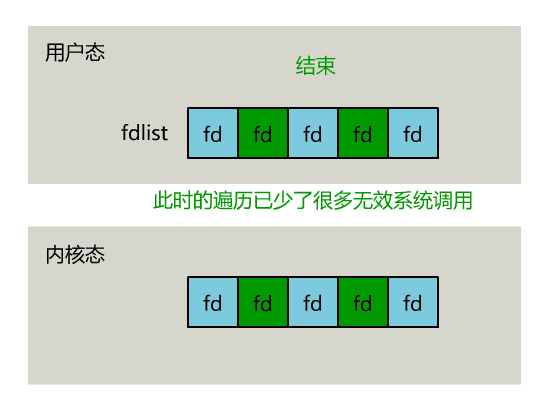
select系统调用的函数定义如下。
int select(
int nfds,
fd_set *readfds,
fd_set *writefds,
fd_set *exceptfds,
struct timeval *timeout);
// nfds:监控的文件描述符集里最大文件描述符加1
// readfds:监控有读数据到达文件描述符集合,传入传出参数
// writefds:监控写数据到达文件描述符集合,传入传出参数
// exceptfds:监控异常发生达文件描述符集合, 传入传出参数
// timeout:定时阻塞监控时间,3种情况
// 1.NULL,永远等下去
// 2.设置timeval,等待固定时间
// 3.设置timeval里时间均为0,检查描述字后立即返回,轮询
服务端代码,这样来写。
首先一个线程不断接受客户端连接,并把 socket 文件描述符放到一个 list 里。
while(1) {
connfd = accept(listenfd);
fcntl(connfd, F_SETFL, O_NONBLOCK);
fdlist.add(connfd);
}
然后,另一个线程不再自己遍历,而是调用 select,将这批文件描述符 list 交给操作系统去遍历。
while(1) {
// 把一堆文件描述符 list 传给 select 函数
// 有已就绪的文件描述符就返回,nready 表示有多少个就绪的
nready = select(list);
...
}
不过,当 select 函数返回后,用户依然需要遍历刚刚提交给操作系统的 list。
只不过,操作系统会将准备就绪的文件描述符做上标识,用户层将不会再有无意义的系统调用开销。
while(1) {
nready = select(list);
// 用户层依然要遍历,只不过少了很多无效的系统调用
for(fd <-- fdlist) {
if(fd != -1) {
// 只读已就绪的文件描述符
read(fd, buf);
// 总共只有 nready 个已就绪描述符,不用过多遍历
if(--nready == 0) break;
}
}
}
正如刚刚的动图中所描述的,其直观效果如下。(同一个动图消耗了你两次流量,气不气?)
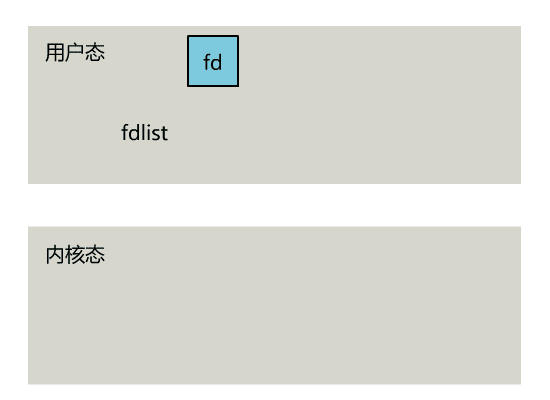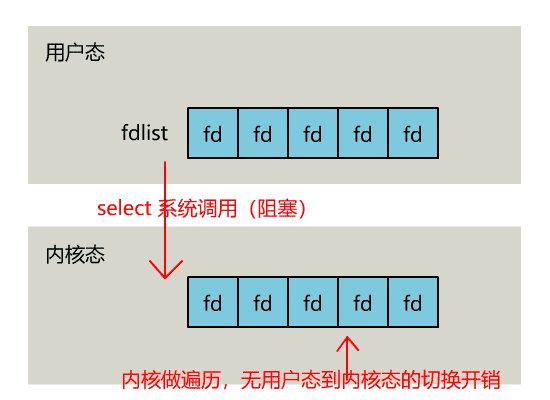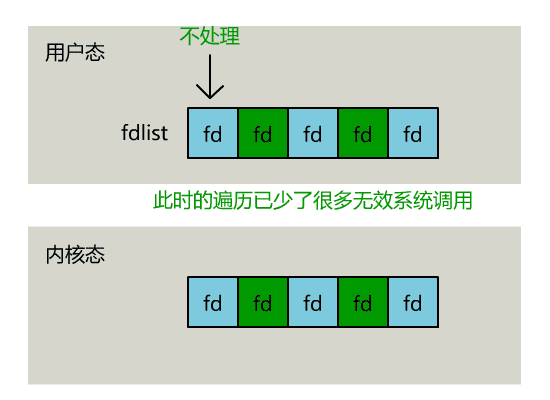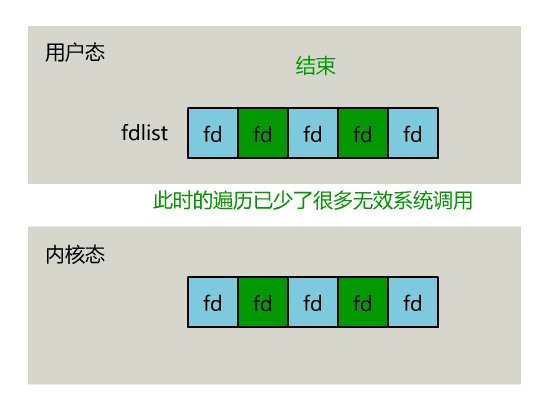
可以看出几个细节:
-
select 调用需要传入 fd 数组,需要拷贝一份到内核,高并发场景下这样的拷贝消耗的资源是惊人的。(可优化为不复制)
-
select 在内核层仍然是通过遍历的方式检查文件描述符的就绪状态,是个同步过程,只不过无系统调用切换上下文的开销。(内核层可优化为异步事件通知)
-
select 仅仅返回可读文件描述符的个数,具体哪个可读还是要用户自己遍历。(可优化为只返回给用户就绪的文件描述符,无需用户做无效的遍历)
整个 select 的流程图如下。
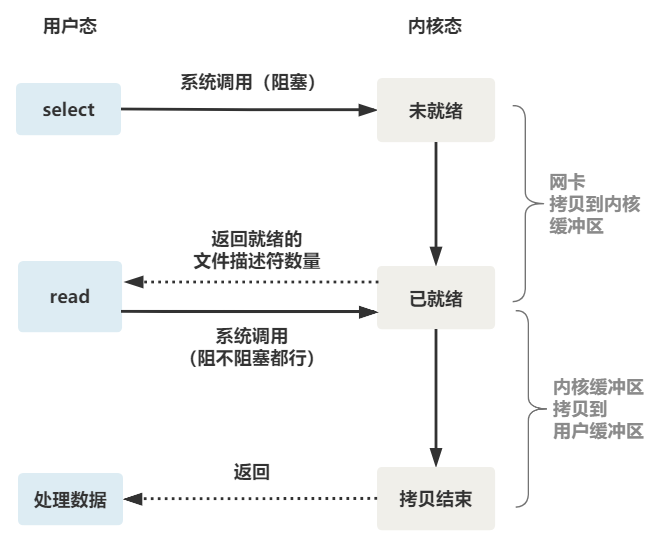
可以看到,这种方式,既做到了一个线程处理多个客户端连接(文件描述符),又减少了系统调用的开销(多个文件描述符只有一次 select 的系统调用 + n 次就绪状态的文件描述符的 read 系统调用)。
poll
poll 也是操作系统提供的系统调用函数。
int poll(struct pollfd *fds, nfds_tnfds, int timeout);
struct pollfd {
intfd; /*文件描述符*/
shortevents; /*监控的事件*/
shortrevents; /*监控事件中满足条件返回的事件*/
};
它和 select 的主要区别就是,去掉了 select 只能监听 1024 个文件描述符的限制。
epoll
epoll 是最终的大 boss,它解决了 select 和 poll 的一些问题。
还记得上面说的 select 的三个细节么?
-
select 调用需要传入 fd 数组,需要拷贝一份到内核,高并发场景下这样的拷贝消耗的资源是惊人的。(可优化为不复制)
-
select 在内核层仍然是通过遍历的方式检查文件描述符的就绪状态,是个同步过程,只不过无系统调用切换上下文的开销。(内核层可优化为异步事件通知)
-
select 仅仅返回可读文件描述符的个数,具体哪个可读还是要用户自己遍历。(可优化为只返回给用户就绪的文件描述符,无需用户做无效的遍历)
所以 epoll 主要就是针对这三点进行了改进。
-
内核中保存一份文件描述符集合,无需用户每次都重新传入,只需告诉内核修改的部分即可。
-
内核不再通过轮询的方式找到就绪的文件描述符,而是通过异步 IO 事件唤醒。
-
内核仅会将有 IO 事件的文件描述符返回给用户,用户也无需遍历整个文件描述符集合。
具体,操作系统提供了这三个函数。
第一步,创建一个 epoll 句柄
int epoll_create(int size);
第二步,向内核添加、修改或删除要监控的文件描述符。
int epoll_ctl(
int epfd, int op, int fd, struct epoll_event *event);
第三步,类似发起了 select() 调用
int epoll_wait(
int epfd, struct epoll_event *events, int max events, int timeout);
使用起来,其内部原理就像如下一般丝滑。

如果你想继续深入了解 epoll 的底层原理,推荐阅读飞哥的《图解 | 深入揭秘 epoll 是如何实现 IO 多路复用的!》,从 linux 源码级别,一行一行非常硬核地解读 epoll 的实现原理,且配有大量方便理解的图片,非常适合源码控的小伙伴阅读。
python select
server
# coding: utf-8
import select
import socket
import Queue
from time import sleep
# Create a TCP/IP
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server.setblocking(False)
# Bind the socket to the port
server_address = ('localhost', 8090)
print ('starting up on %s port %s' % server_address)
server.bind(server_address)
# Listen for incoming connections
server.listen(5)
# Sockets from which we expect to read
inputs = [server]
# Sockets to which we expect to write
# 处理要发送的消息
outputs = []
# Outgoing message queues (socket: Queue)
message_queues = {}
while inputs:
# Wait for at least one of the sockets to be ready for processing
print ('waiting for the next event')
# 开始select 监听, 对input_list 中的服务器端server 进行监听
# 一旦调用socket的send, recv函数,将会再次调用此模块
readable, writable, exceptional = select.select(inputs, outputs, inputs)
# Handle inputs
# 循环判断是否有客户端连接进来, 当有客户端连接进来时select 将触发
for s in readable:
# 判断当前触发的是不是服务端对象, 当触发的对象是服务端对象时,说明有新客户端连接进来了
# 表示有新用户来连接
if s is server:
# A "readable" socket is ready to accept a connection
connection, client_address = s.accept()
print ('connection from', client_address)
# this is connection not server
connection.setblocking(0)
# 将客户端对象也加入到监听的列表中, 当客户端发送消息时 select 将触发
inputs.append(connection)
# Give the connection a queue for data we want to send
# 为连接的客户端单独创建一个消息队列,用来保存客户端发送的消息
message_queues[connection] = Queue.Queue()
else:
# 有老用户发消息, 处理接受
# 由于客户端连接进来时服务端接收客户端连接请求,将客户端加入到了监听列表中(input_list), 客户端发送消息将触发
# 所以判断是否是客户端对象触发
data = s.recv(1024)
# 客户端未断开
if data != '':
# A readable client socket has data
print ('received "%s" from %s' % (data, s.getpeername()))
# 将收到的消息放入到相对应的socket客户端的消息队列中
message_queues[s].put(data)
# Add output channel for response
# 将需要进行回复操作socket放到output 列表中, 让select监听
if s not in outputs:
outputs.append(s)
else:
# 客户端断开了连接, 将客户端的监听从input列表中移除
# Interpret empty result as closed connection
print ('closing', client_address)
# Stop listening for input on the connection
if s in outputs:
outputs.remove(s)
inputs.remove(s)
s.close()
# Remove message queue
# 移除对应socket客户端对象的消息队列
del message_queues[s]
# Handle outputs
# 如果现在没有客户端请求, 也没有客户端发送消息时, 开始对发送消息列表进行处理, 是否需要发送消息
# 存储哪个客户端发送过消息
for s in writable:
try:
# 如果消息队列中有消息,从消息队列中获取要发送的消息
message_queue = message_queues.get(s)
send_data = ''
if message_queue is not None:
send_data = message_queue.get_nowait()
else:
# 客户端连接断开了
print "has closed "
except Queue.Empty:
# 客户端连接断开了
print "%s" % (s.getpeername())
outputs.remove(s)
else:
# print "sending %s to %s " % (send_data, s.getpeername)
# print "send something"
if message_queue is not None:
s.send(send_data)
else:
print "has closed "
# del message_queues[s]
# writable.remove(s)
# print "Client %s disconnected" % (client_address)
# # Handle "exceptional conditions"
# 处理异常的情况
for s in exceptional:
print ('exception condition on', s.getpeername())
# Stop listening for input on the connection
inputs.remove(s)
if s in outputs:
outputs.remove(s)
s.close()
# Remove message queue
del message_queues[s]
sleep(1)
client
# coding: utf-8
import socket
messages = ['This is the message ', 'It will be sent ', 'in parts ', ]
server_address = ('localhost', 8090)
# Create aTCP/IP socket
socks = [socket.socket(socket.AF_INET, socket.SOCK_STREAM), socket.socket(socket.AF_INET, socket.SOCK_STREAM), ]
# Connect thesocket to the port where the server is listening
print ('connecting to %s port %s' % server_address)
# 连接到服务器
for s in socks:
s.connect(server_address)
for index, message in enumerate(messages):
# Send messages on both sockets
for s in socks:
print ('%s: sending "%s"' % (s.getsockname(), message + str(index)))
s.send(bytes(message + str(index)).decode('utf-8'))
# Read responses on both sockets
for s in socks:
data = s.recv(1024)
print ('%s: received "%s"' % (s.getsockname(), data))
if data != "":
print ('closingsocket', s.getsockname())
s.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号