
模块与包
模块与包
一、模块的介绍
- 在Python中,一个.py文件就是一个模块
- 一般讲的模块有三个来源:
- Python解释器自带的,可以直接拿来使用
- 第三方的:有别人编写并开元出来,使用时需要下载
- 自己写的简单的模块
- 将程序模块化会使得程序的组织结构清晰,维护起来更加方便。
- 比起直接开发一个完整的程序,单独开发一个小的模块也会更加简单,并且程序中的模块与电脑中的零部件稍微不同的是:程序中的模块可以被重复使用。
二、模块的使用
[1]直接导入
- 使用import语句
import py文件名/模块名
(1)导入模块后会有哪些变化
- 进入模块内,加载模块内的名称空间
- 回到自己的文件中,继续向下执行自己的名称空间
- 之后就可以使用模块和原来的名称空间内的变量函数等
(2)import导入模块方式
-
可以用import导入多个模块
- 多行import语句进行导入
import module_1 import module_2 import module_3- 也可以在一行导入,不同模块使用逗号隔开。
import module_1, module_2, module_3 -
第一种方法更加规范,方便。
-
第一种方法更容易区分不同模块,并且模块的导入有着一定的顺序:
- Python自带模块
- 第三方模块
- 自定义模块
[2]详细导入
from...import...语句
from 模块位置 import 模块名
# from ... import ... 与 import ...最大的区别就是通过from声明过的位置引用时就不需要再次加上位置
# 如在同一文件夹下创建了一个名为module.py的文件,将其作为一个模块,在其中定义了如下变量
name = "Xanadu"
password = "521"
def add(x, y):
return x + y
#在次文件夹内再次创建主文件,并在其中导入module模块,使用其中变量及函数:
import module
#使用import语句时,要引用模块内变量方法等,需要带上前缀module.
print(module.name) # Xanadu
from module import name, password, add
#使用from ... import ... 语句就只要在导入时声明一次,之后在使用就不需要加前缀
print(name) # Xanadu
print(password) # 521
print(add(1, 2)) # 3
#也可以使用*来导入所有module中的变量,函数等
from module import *
print(name) # Xanadu
print(password) # 521
print(add(1, 2)) # 3
- 但是需要强调的一点是:
- 只能在模块最顶层使用
*的方式导入,在函数内则非法(无法在函数内使用*导入) - 并且
*的方式会带来一种副作用- 即我们无法搞清楚究竟从源文件中导入了哪些名字到当前位置
- 这极有可能与当前位置的名字产生冲突。
- 模块的编写者可以在自己的文件中定义
__all__变量用来控制*代表的意思
- 只能在模块最顶层使用
[3]模块重命名
from ... import ... as ...语句
# 不仅可以在当前位置为导入的模块起一个别名还可以为导入的一个名字起别名
import module as mod
print(mod.name) # Xanadu
from module import password as pwd
print(pwd) # 521
- 通常在被导入的名字过长时采用起别名的方式来精简代码
- 另外为被导入的名字起别名可以很好地避免与当前名字发生冲突
- 还有很重要的一点就是:
- 可以保持调用方式的一致性
- 例如
- 我们有两个模块json和pickle同时实现了load方法
- 作用是从一个打开的文件中解析出结构化的数据
- 但解析的格式不同
- 可以用下述代码有选择性地加载不同的模块
- 我们有两个模块json和pickle同时实现了load方法
[4]循环导入问题
- 循环导入问题指的是在一个模块加载/导入的过程中导入另外一个模块
- 而在另外一个模块中又返回来导入第一个模块中的名字
- 由于第一个模块尚未加载完毕
- 所以引用失败、抛出异常
- 究其根源就是在python中
- 同一个模块只会在第一次导入时执行其内部代码
- 再次导入该模块时
- 即便是该模块尚未完全加载完毕也不会去重复执行内部代码
(1)循环导入所引发的问题演示
- m1.py
print('正在导入m1')
from m2 import y
x='m1'
- m2.py
print('正在导入m2')
from m1 import x
y='m2'
- run.py
import m1
1.演示一
- 执行run.py会抛出异常
正在导入m1
正在导入m2
Traceback (most recent call last):
File "/Users/linhaifeng/PycharmProjects/pro01/1 aaaa练习目录/aa.py", line 1, in <module>
import m1
File "/Users/linhaifeng/PycharmProjects/pro01/1 aaaa练习目录/m1.py", line 2, in <module>
from m2 import y
File "/Users/linhaifeng/PycharmProjects/pro01/1 aaaa练习目录/m2.py", line 2, in <module>
from m1 import x
ImportError: cannot import name 'x'
- 分析
- 先执行run.py--->执行import m1
- 开始导入m1并运行其内部代码--->打印内容"正在导入m1"
- --->执行from m2 import y 开始导入m2并运行其内部代码--->打印内容“正在导入m2”
- --->执行from m1 import x,由于m1已经被导入过了,所以不会重新导入,所以直接去m1中拿x
- 然而x此时并没有存在于m1中,所以报错
2.演示二
- 执行文件不等于导入文件,比如执行m1.py不等于导入了m
直接执行m1.py抛出异常
正在导入m1
正在导入m2
正在导入m1
Traceback (most recent call last):
File "/Users/linhaifeng/PycharmProjects/pro01/1 aaaa练习目录/m1.py", line 2, in <module>
from m2 import y
File "/Users/linhaifeng/PycharmProjects/pro01/1 aaaa练习目录/m2.py", line 2, in <module>
from m1 import x
File "/Users/linhaifeng/PycharmProjects/pro01/1 aaaa练习目录/m1.py", line 2, in <module>
from m2 import y
ImportError: cannot import name 'y'
- 分析
- 执行m1.py,打印“正在导入m1”,
- 执行from m2 import y
- 导入m2进而执行m2.py内部代码
- --->打印"正在导入m2"
- 执行from m1 import x
- 此时m1是第一次被导入
- 执行m1.py并不等于导入了m1
- 于是开始导入m1并执行其内部代码
- --->打印"正在导入m1"
- 执行from m1 import y
- 由于m1已经被导入过了
- 所以无需继续导入而直接问m2要y
- 然而y此时并没有存在于m2中所以报错
(2)循环引入产生的问题的解决方案
1.方案一
- 导入语句放到最后,保证在导入时,所有名字都已经加载过
- m1.py
print('正在导入m1')
x='m1'
from m2 import y
- m2.py
print('正在导入m2')
y='m2'
from m1 import x
- run.py
import m1
print(m1.x)
print(m1.y)
2.方案二
- 导入语句放到函数中,只有在调用函数时才会执行其内部代码
- m1.py
print('正在导入m1')
def f1():
from m2 import y
print(x,y)
x = 'm1'
- m2.py
print('正在导入m2')
def f2():
from m1 import x
print(x,y)
y = 'm2'
- run.py
import m1
m1.f1()
注意:循环导入问题大多数情况是因为程序设计失误导致,上述解决方案也只是在烂设计之上的无奈之举,在我们的程序中应该尽量避免出现循环/嵌套导入,如果多个模块确实都需要共享某些数据,可以将共享的数据集中存放到某一个地方,然后进行导入
三、搜索模块的路径与优先级
[1]模块的分类
-
模块其实分为四个通用类别,分别是:
- 1、使用纯Python代码编写的py文件
- 2、包含一系列模块的包
- 3、使用C编写并链接到Python解释器中的内置模块
- 4、使用C或C++编译的扩展模块
-
在导入一个模块时
- 如果该模块已加载到内存中,则直接引用
- 否则会优先查找内置模块
- 然后按照从左到右的顺序依次检索
sys.path中定义的路径
- 然后按照从左到右的顺序依次检索
- 直到找模块对应的文件为止
- 否则抛出异常。
[2]查看模块的搜索路径
sys.path也被称为模块的搜索路径,它是一个列表类型
import sys
print(sys.path)
r'''
['D:\\project\\python',
'D:\\app\\Pycharm\\PyCharm 2023.2.1\\plugins\\python\\helpers\\pycharm_display',
'D:\\app\\python\\3.10\\python310.zip',
'D:\\app\\python\\3.10\\DLLs',
'D:\\app\\python\\3.10\\lib',
'D:\\app\\python\\3.10',
'D:\\app\\python\\3.10\\lib\\site-packages',
'D:\\app\\Pycharm\\PyCharm 2023.2.1\\plugins\\python\\helpers\\pycharm_matplotlib_backend']
'''
-
列表中的每个元素都可以当做一个目录来看,其中的压缩包(.zip等)Python也支持从其中导入模块
-
sys.path中的第一个路径通常为空,代表执行文件所在的路径,所以在被导入模块与执行文件在同一目录下时肯定是可以正常导入的 -
当要导入的模块和执行文件不在同一个文件夹时,我们一般将执行文件所在的路径也加入
sys.path中,这样导入的模块不管在哪都可以被找到然后导入 -
当我开发一个模块时,可以在文件末尾基于
__name__在不同应用场景下值的不同来控制文件执行不同的逻辑
# module.py
...
if __name__ == '__main__':
# 被当做脚本执行时运行的代码
module.py
else:
# 被当做模块导入时运行的代码
module.py
[3]模块编写规范
- 我们在编写py文件时
- 需要时刻提醒自己
- 该文件既是给自己用的
- 也有可能会被其他人使用
- 因而代码的可读性与易维护性显得十分重要
- 为此我们在编写一个模块时最好按照统一的规范去编写
- 需要时刻提醒自己
四、包
[1]什么是包
- 包是一个模块的集合,它可以将多个模块的功能组合到一起。
- 包可以按照其功能和作用进行分类,方便用户查找和使用。
- 包是在Python标准库中定义的一种特殊类型的模块,可以通过import语句来引入和使用。
- Python的包分为标准库包和第三方库包。
- 标准库包是Python内置的包,包含了一些基本的模块和函数,如os、sys、random等;
- 第三方库包是第三方开发的包,通常提供了更加丰富和高级的功能。
[2]包的结构
- 包是Python程序中用于组织模块的一种方式。包是一个包含模块的目录,同时还可以包含其他子包。
- 要创建一个包,我们只需要在目录中创建一个名为
__init__.py的文件即可。 - 包路径下必须存在
__init__.py文件。
[3]创建包
- 如果使用Pycharm进行解释器,直接创建包会自带
__init__.py文件 - 也可以创建文件夹之后,再手动创建
__init__.py文件 - 这里创建一个mine包,包中创建一个计算机的model结构如下:
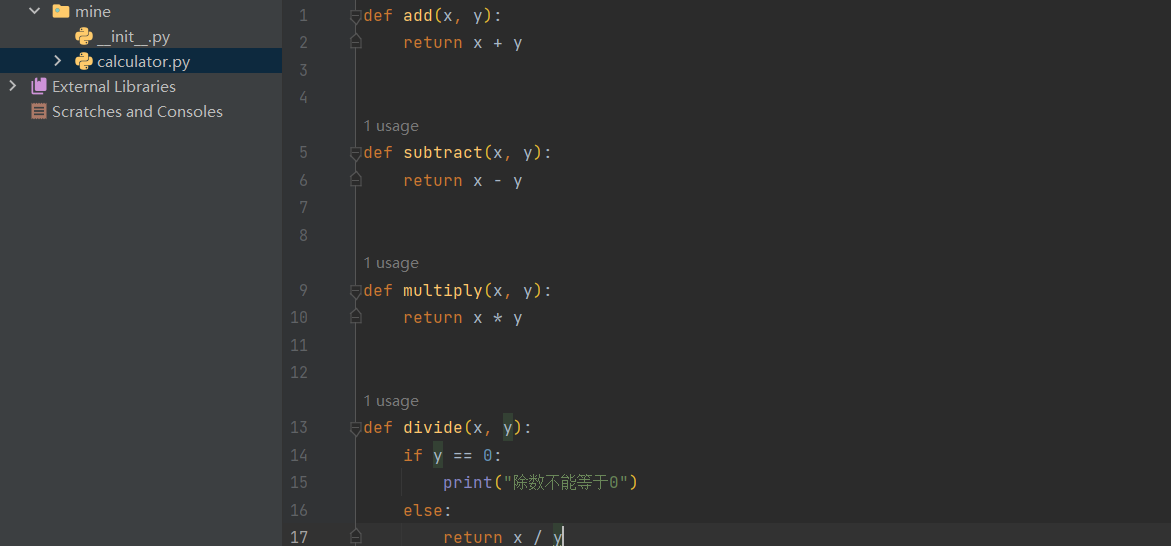
- calculator.py
def add(x, y):
return x + y
def subtract(x, y):
return x - y
def multiply(x, y):
return x * y
def divide(x, y):
if y == 0:
print("除数不能等于0")
else:
return x / y
[4]使用包
- 包的使用和模块的使用类似
(1)直接使用
- 语法
import 包名.包名.模块名
- 使用
import mine.calculator
print(mine.calculator.add(1, 2)) # 3
- 缺点:直接使用import 导入使用,会有很长的前缀
(2)详细使用
-
语法
- 先在包的文件夹内的
__init__.py文件里“注册”其他文件里的函数方法
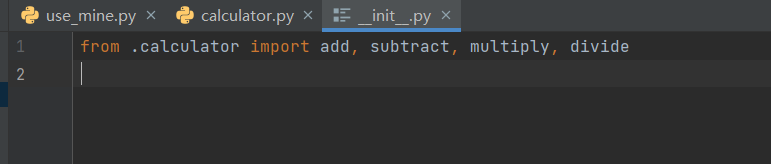
- 之后使用from...import...来导入模块方法,再使用时就不需要带着长长的前缀了
from mine import add, divide, multiply, subtract print(add(10, 2)) # 12 print(divide(10, 2)) # 5.0 print(multiply(10, 2)) # 20 print(subtract(10, 2)) # 8 - 先在包的文件夹内的
五、相对路径和绝对路径
- 在Python中,路径分为相对路径和绝对路径。
[1]相对路径
- 相对路径是相对于当前工作目录或当前脚本文件所在目录的路径。
- 使用相对路径时,你指定的路径是相对于执行脚本的当前工作目录的。
#当前目录如下D:\project\python\mine\mine\calculator.py
#那么当前相对路径就可以是mine\calculator.py
[2]绝对路径
- 绝对路径是文件或目录在文件系统中的完整路径,不依赖于当前工作目录。
- 使用绝对路径时,你指定的路径是从文件系统的根目录开始的。
#绝对路径一般从盘符开始
#当前的绝对路径就是D:\project\python\mine\mine\calculator.py

 浙公网安备 33010602011771号
浙公网安备 33010602011771号