

作业一
当当图书爬取实验
作业内容
-
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法; Scrapy+Xpath+MySQL数据库存储技术路线爬取当当网站图书数据
-
关键词:学生自由选择
实验步骤
1.首先创建我们的scrapy项目
scrapy startproject dangdang
2.然后我们再进入创建好的项目之下,创建爬虫
scrapy genspider dangdang_spiders
items:
class DangdangItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() title = scrapy.Field() author = scrapy.Field() date = scrapy.Field() publisher = scrapy.Field() detail = scrapy.Field() price = scrapy.Field() pass
dangdang_spiders获取网页数据部分:
dammit = UnicodeDammit(response.body,["utf-8","gbk"]) data = dammit.unicode_markup selector=scrapy.Selector(text=data) lis=selector.xpath("//li['@ddt-pit'][starts-with(@class,'line')]") for li in lis: title=li.xpath("./a[position()=1]/@title").extract_first() price=li.xpath("./p[@class='price']/span[@class='search_now_price']/text()").extract_first() author=li.xpath("./p[@class='search_book_author']/span[position()=1]/a/@title").extract_first() date=li.xpath("./p[@class='search_book_author']/span[position()=last()-1]/text()").extract_first() publisher=li.xpath("./p[@class='search_book_author']/span[position()=last()]/a/@title").extract_first() detail = li.xpath("./p[@class='detail']/text()").extract_first() item=DangdangItem() item["title"]=title.strip()if title else"" item["author"] = author.strip() if author else "" item["date"] = date.strip()[1:] if date else "" item["publisher"] = publisher.strip() if publisher else "" item["price"] = price.strip() if price else "" item["detail"] = detail.strip() if detail else ""
编写pipelines,包含着Mysql数据库的接入,在向数据库插入信息时,我们需要先创建表,因为代码部分没有创建表的部分:
import pymysql class DangdangPipeline(object): def open_spider(self,spider): print("opened") try: self.con=pymysql.connect(host="127.0.0.1",port=3306,user="root",passwd="20010109l?y!",db="dangdang",charset="utf8") self.cursor=self.con.cursor(pymysql.cursors.DictCursor) self.cursor.execute("delete from books") self.opened=True self.count=0 except Exception as err: print(err) def close_spider(self,spider): if self.opened: self.con.commit() self.con.close() self.opened=False print("closed") print("总共爬取",self.count,"本书籍") def process_item(self, item, spider): try: print(item["title"]) print(item["author"]) print(item["publisher"]) print(item["date"]) print(item["price"]) print(item["detail"]) print() if self.opened: self.cursor.execute("insert into books(bTitle,bAuthor,bPublisher,bDate,bPrice,bDetail)values(%s,%s,%s,%s,%s,%s)",(item["title"],item["author"],item["publisher"],item["date"],item["price"],item["detail"])) self.count+=1 except Exception as err: print(err) return item
settings部分与前面几次作业的改动一样,这里就不贴上来了
运行结果如下:
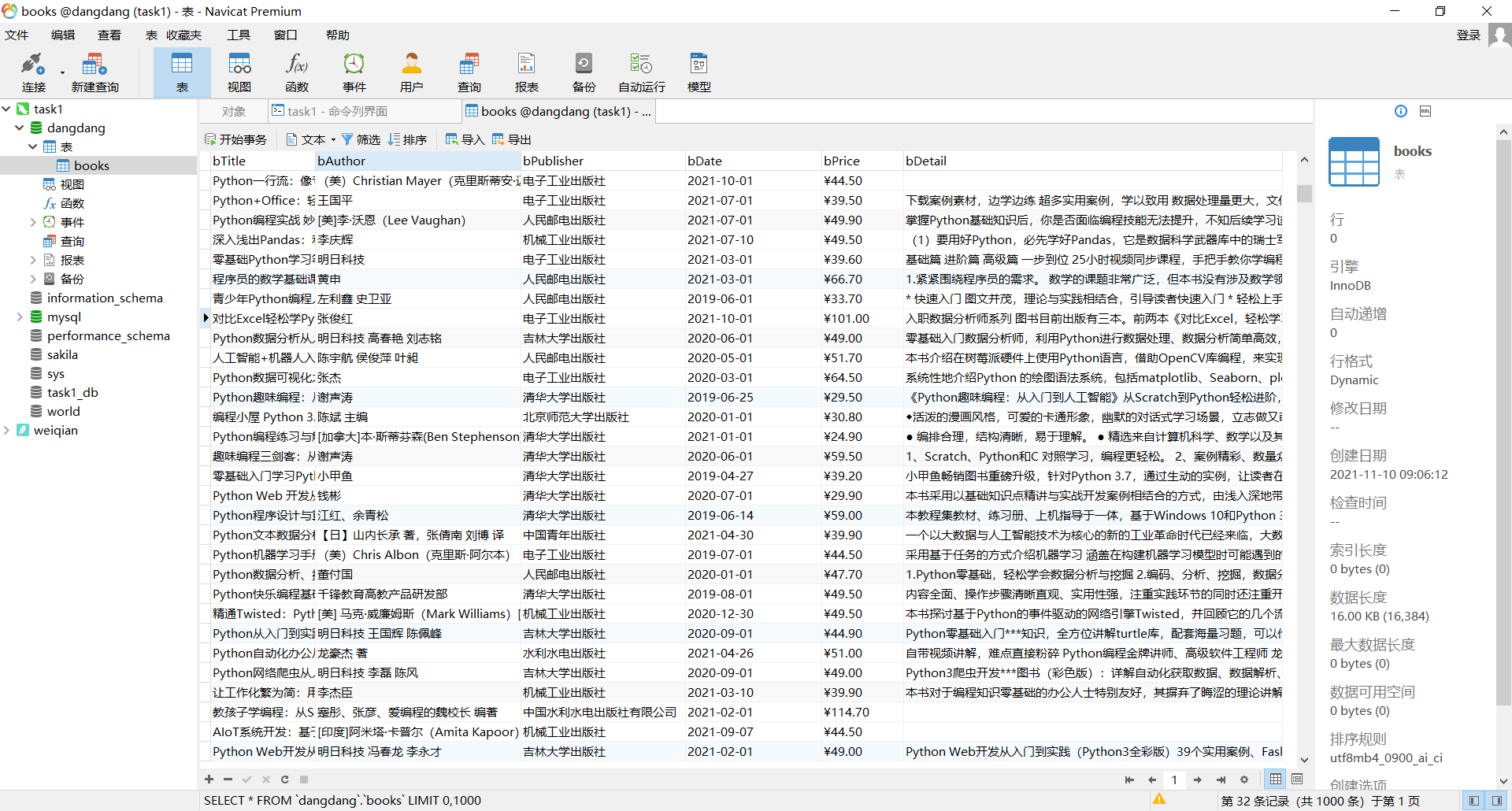
通过navicat查看结果:
实验心得:
作业1是代码的复现,我进一步巩固了scrapy用法,还有对网页元素寻找更加熟练。
码云地址:作业4/dangdang/dangdang · 刘洋/2019数据采集与融合 - 码云 - 开源中国 (gitee.com)
作业二
银行汇率爬取实验
作业内容
-
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
-
候选网站:招商银行网:http://fx.cmbchina.com/hq/
实验过程:
找到对应要爬取的数据的xpath路径
然后编写spiders:
这里要注意一点就是要把table后面的tbody删除掉,否则无法爬取的数据,全是none。好像是因为是实时数据的原因
class MySpider(scrapy.Spider): name = "MySpider" source_url = "http://fx.cmbchina.com/hq/" def start_requests(self): url = MySpider.source_url yield scrapy.Request(url=url,callback=self.parse) def parse(self,response): try: #各个数据对应的xpath路径 Currency=response.xpath("/html/body/div[5]/div[2]/div[2]/div[1]/table//tr/td[1]/text()").extract() TSP=response.xpath("/html/body/div[5]/div[2]/div[2]/div[1]/table//tr/td[4]/text()").extract() CSP=response.xpath("/html/body/div[5]/div[2]/div[2]/div[1]/table//tr/td[5]/text()").extract() TBP=response.xpath("/html/body/div[5]/div[2]/div[2]/div[1]/table//tr/td[6]/text()").extract() CBP =response.xpath("/html/body/div[5]/div[2]/div[2]/div[1]/table//tr/td[7]/text()").extract() shijian=response.xpath("/html/body/div[5]/div[2]/div[2]/div[1]/table//tr/td[8]/text()").extract() item=CashItem() item["Currency"]=Currency item["TSP"] = TSP item["CSP"] = CSP item["TBP"] = TBP item["CBP"] = CBP item["shijian"] = shijian yield item except Exception as err: print(err)
然后去编写pipelines:
class CashPipeline: def open_spider(self, spider): print("opened") try: self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="20010109l?y!", db="waihui", charset="utf8") self.cursor = self.con.cursor(pymysql.cursors.DictCursor) self.cursor.execute("delete from cash") self.opened = True except Exception as err: print(err) def close_spider(self, spider): if self.opened: self.con.commit() self.con.close() self.DBOpen = False print("DB closed") def process_item(self, item, spider): Currency = item["Currency"] TSP = item["TSP"] CSP = item["CSP"] TBP = item["TBP"] CBP = item["CBP"] shijian = item["shijian"] #因为直接爬取下来的数据含有空格,所以在打印以及存储的时候使用strip()处理数据 for i in range(1,len(Currency)): print(i, Currency[i].strip(), TSP[i].strip(), CSP[i].strip(), TBP[i].strip(), CBP[i].strip(), shijian[i].strip()) self.cursor.execute( "insert into cash(id,Currency,TSP,CSP,TBP,CBP,Time) values (%s,%s,%s,%s,%s,%s,%s)",(str(i),Currency[i].strip(), TSP[i].strip(), CSP[i].strip(), TBP[i].strip(), CBP[i].strip(), shijian[i].strip())) return item
其余的框架极为相似,这里不贴代码上来了
实验结果:
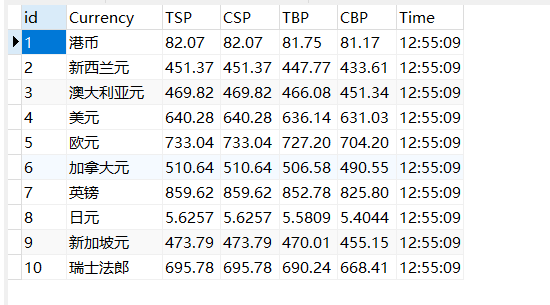
实验心得:通过这次实验,我进一步巩固了scrapy用法,对网页元素寻找更加熟练,对数据库的连接编写更加熟练。
码云地址:作业4/cash/cash · 刘洋/2019数据采集与融合 - 码云 - 开源中国 (gitee.com)
作业三
股票信息爬取实验
作业内容
-
要求:熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容;使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
-
候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
实验步骤
初始化谷歌浏览器:
# 初始化谷歌浏览器 chrome_options = Options() chrome_options.add_argument('--headless') chrome_options.add_argument('--disable-gpu') self.driver = webdriver.Chrome(chrome_options=chrome_options)
获取页面数据的信息:
#获取信息 trs = self.driver.find_elements_by_xpath("//table[@id='table_wrapper-table']/tbody/tr") time.sleep(1) for tr in trs: time.sleep(1) number = tr.find_element_by_xpath("./td[position()=1]").text while len(number) < 6: number = "0" + number code = tr.find_element_by_xpath("./td[position()=2]/a").text name = tr.find_element_by_xpath("./td[position()=3]/a").text the_latest_price = tr.find_element_by_xpath("./td[position()=5]/span").text price_limit = tr.find_element_by_xpath("./td[position()=6]/span").text change_amount = tr.find_element_by_xpath("./td[position()=7]/span").text trading_volume = tr.find_element_by_xpath("./td[position()=8]").text turnover = tr.find_element_by_xpath("./td[position()=9]").text swing = tr.find_element_by_xpath("./td[position()=10]").text tallest = tr.find_element_by_xpath("./td[position()=11]/span").text lowest = tr.find_element_by_xpath("./td[position()=12]/span").text today_open = tr.find_element_by_xpath("./td[position()=13]/span").text yesterday_get = tr.find_element_by_xpath("./td[position()=14]").text
模拟翻页:
#模拟点击翻页至下一板块 while self.count < 4: print(self.count) tiihi = self.driver.find_element_by_xpath( "//div/ul[@class='tab-list clearfix']/li[@id='nav_" + list[self.count - 1] + "_a_board']/a") print(tiihi) print(list[self.count - 1]) self.driver.execute_script('arguments[0].click()', tiihi) time.sleep(3) WebDriverWait(self.driver, 1000).until( EC.presence_of_element_located((By.XPATH, "//span[@class='paginate_page']/a[last()]"))) self.processspider() self.count = self.count + 1 print("Spider closing......") self.closeup()
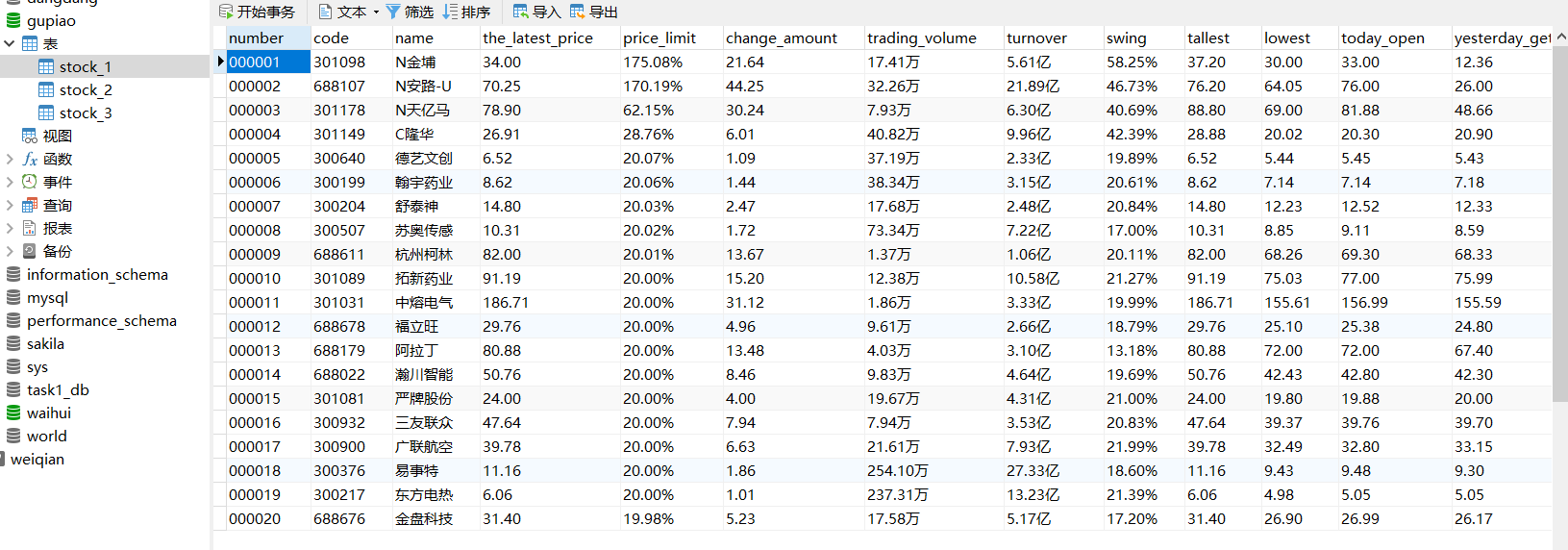
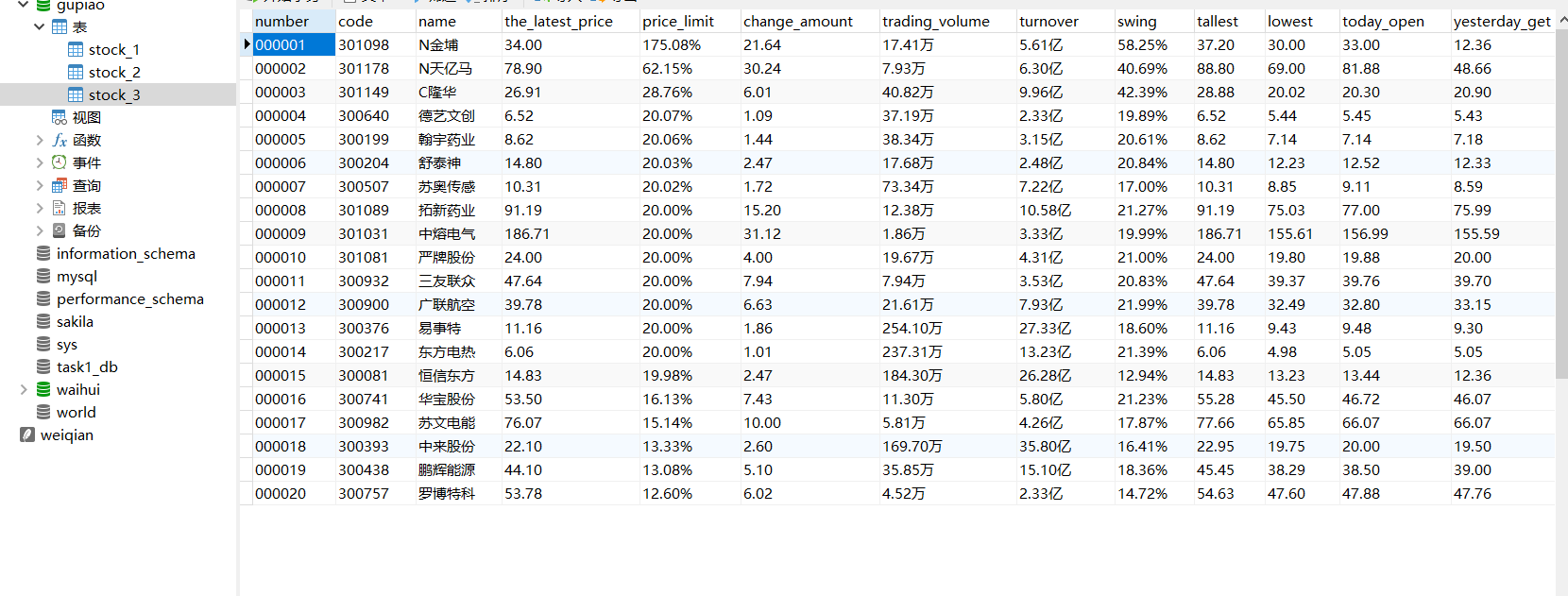
实验结果如下:
沪深A股:
上证: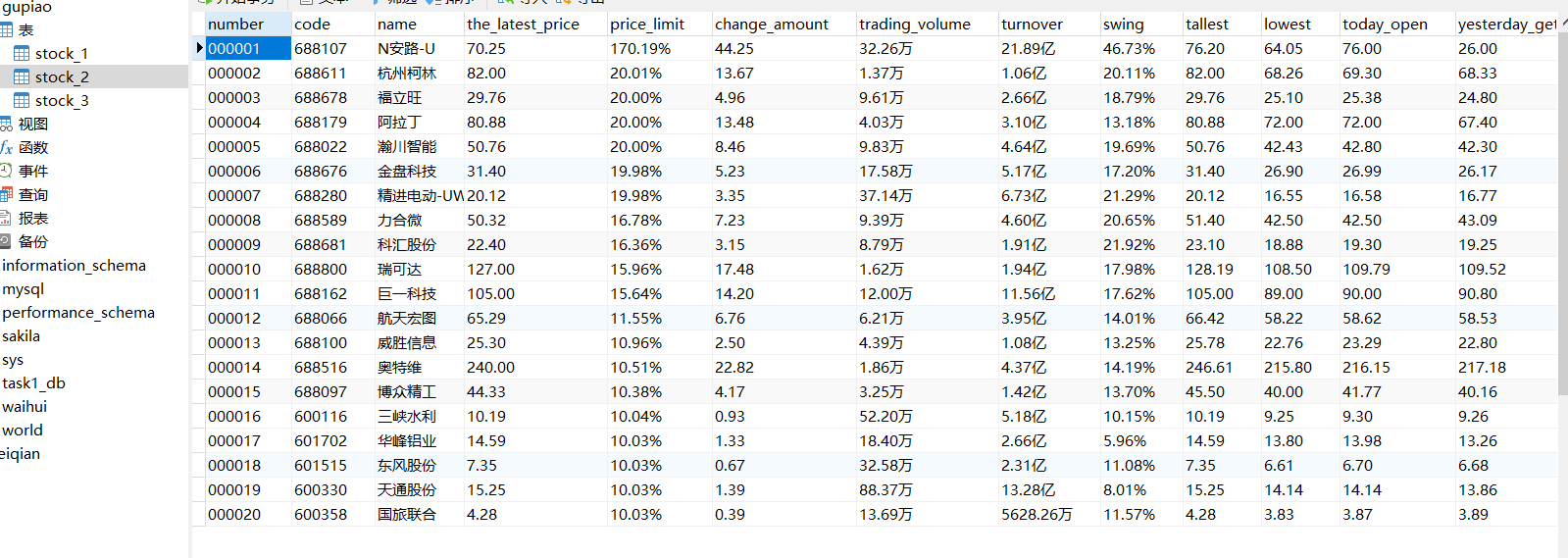
深证:
实验心得:
熟悉了selenium的使用,加强了网页爬虫和解决问题的能力,对不同框架下的xpath使用有了更深的理解,进一步加深了对数据库的理解和使用。
