

作业①
1)
-
要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
-
输出信息:
代码如下:(复现书上代码)序号 地区 日期 天气信息 温度 1 北京 7日(今天) 晴间多云,北部山区有阵雨或雷阵雨转晴转多云 31℃/17℃ 2 北京 8日(明天) 多云转晴,北部地区有分散阵雨或雷阵雨转晴 34℃/20℃ 3 北京 9日(后台) 晴转多云 36℃/22℃ 4 北京 10日(周六) 阴转阵雨 30℃/19℃ 5 北京 11日(周日) 阵雨 27℃/18℃ 6...... -
from bs4 import BeautifulSoup from bs4 import UnicodeDammit import urllib.request import sqlite3 #031904120 class WeatherDB: #打开数据库的方法 def openDB(self): self.con=sqlite3.connect("weathers.db") self.cursor=self.con.cursor() try: self.cursor.execute("create table weathers (wCity varchar(16),wDate varchar(16),wWeather varchar(64),wTemp varchar(32),constraint pk_weather primary key (wCity,wDate))") except: self.cursor.execute("delete from weathers") #关闭数据库的方法 def closeDB(self): self.con.commit() self.con.close() #插入数据的方法 def insert(self, city, date, weather, temp): try: self.cursor.execute("insert into weathers (wCity,wDate,wWeather,wTemp) values (?,?,?,?)", (city, date, weather, temp)) except Exception as err: print(err) #打印数据库内容的方法 def show(self): self.cursor.execute("select * from weathers") rows = self.cursor.fetchall() print("%-16s%-16s%-32s%-16s" % ("city", "date", "weather", "temp")) for row in rows: print("%-16s%-16s%-32s%-16s" % (row[0], row[1], row[2], row[3])) class WeatherForecast: def __init__(self): self.headers = { "User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"} self.cityCode = {"北京": "101010100", "上海": "101020100", "广州": "101280101", "深圳": "101280601"} def forecastCity(self, city): if city not in self.cityCode.keys(): print(city + " code cannot be found") return url = "http://www.weather.com.cn/weather/" + self.cityCode[city] + ".shtml" #爬虫模板开始 try: req = urllib.request.Request(url, headers=self.headers) data = urllib.request.urlopen(req) data = data.read() dammit = UnicodeDammit(data, ["utf-8", "gbk"]) data = dammit.unicode_markup soup = BeautifulSoup(data, "lxml") lis = soup.select("ul[class='t clearfix'] li") for li in lis: try: date=li.select('h1')[0].text weather=li.select('p[class="wea"]')[0].text temp=li.select('p[class="tem"] span')[0].text+"/"+li.select('p[class="tem"] i')[0].text print(city,date,weather,temp) self.db.insert(city,date,weather,temp) except Exception as err: print(err) except Exception as err: print(err) #整个过程的方法 def process(self, cities): self.db = WeatherDB() self.db.openDB() for city in cities: self.forecastCity(city) # self.db.show() self.db.closeDB() ws = WeatherForecast() ws.process(["北京", "上海", "广州", "深圳"]) print("完成")
运行结果如下:
-
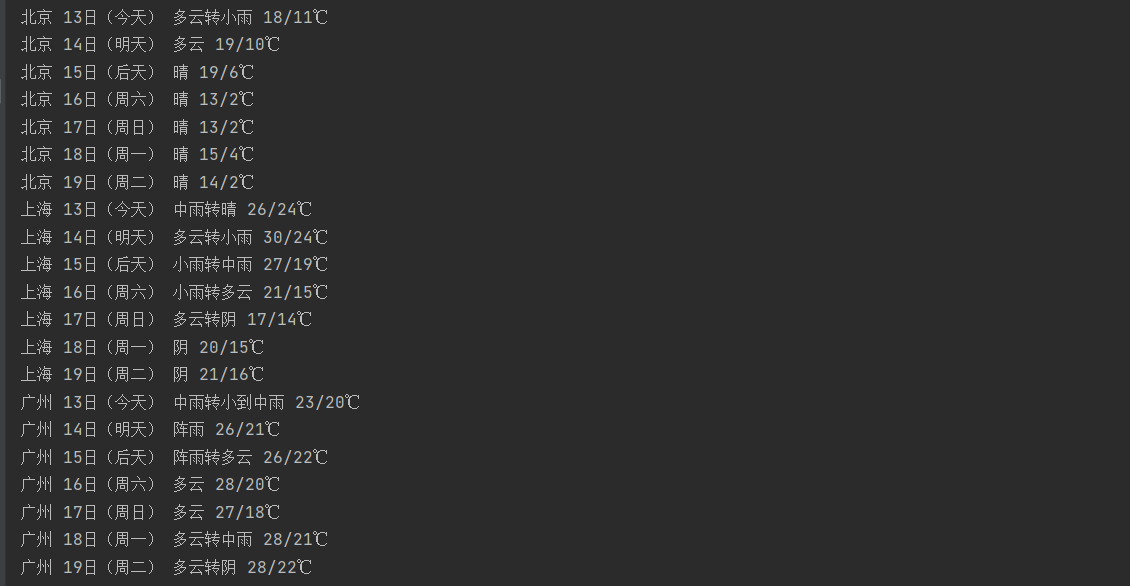
- 心得体会:复现了书本上的代码,对数据库有了初步的了解与认识
-
作业②
-
-
要求:用requests和BeautifulSoup库方法定向爬取股票相关信息。
-
候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
-
技巧:在谷歌浏览器中进入F12调试模式进行抓包,查找股票列表加载使用的url,并分析api返回的值,并根据所要求的参数可适当更改api的请求参数。根据URL可观察请求的参数f1、f2可获取不同的数值,根据情况可删减请求的参数。
-
输出信息:
序号 股票代码 股票名称 最新报价 涨跌幅 涨跌额 成交量 成交额 振幅 最高 最低 今开 昨收 1 688093 N世华 28.47 62.22% 10.92 26.13万 7.6亿 22.34 32.0 28.08 30.2 17.55 2...... -
- 代码如下:
-
import requests import sqlite3 import re #数据库部分参照第一份样例代码修改 class equity_marketDB: # 打开数据库的方法 def openDB(self): self.con = sqlite3.connect("equity_market.db") self.cursor = self.con.cursor() try: self.cursor.execute( "create table equity (sID varchar(16),sName varchar(64),sPrice varchar(16),sRFExtent varchar(16),sRFQuota varchar(16),sNum varchar(16),sQuota varchar(16),sExtent varchar(16),sHigh varchar(16),sLow varchar(16),sToday varchar(16),sYesterday varchar(16),constraint pk_stock primary key (sID,sName))") except: self.cursor.execute("delete from equity") # 关闭数据库的方法 def closeDB(self): self.con.commit() self.con.close() # 插入数据的方法 def insert(self, ID, name, price, RFextent, RFquota, num, quota, extent, high, low, today, yesterday): try: self.cursor.execute( "insert into equity (sID,sName,sPrice,sRFExtent,sRFQuota,sNum,sQuota,sExtent,sHigh,sLow,sToday,sYesterday) values (?,?,?,?,?,?,?,?,?,?,?,?)", (ID, name, price, RFextent, RFquota, num, quota, extent, high, low, today, yesterday)) except Exception as err: print(err) # 打印数据库内容的方法 def show(self): self.cursor.execute("select * from equity") rows = self.cursor.fetchall() print( "{:^10}\t{:^8}\t{:^10}\t{:^20}\t{:^10}\t{:^10}\t{:^10}\t{:^10}\t{:^10}\t{:^10}\t{:^10}\t{:^10}\t{:^10}\t".format( "序号", "代码", "名称", "最新价(元)", "涨跌幅(%)", "跌涨额(元)", "成交量", "成交额(元)", "振幅(%)", "最高", "最低", "今开", "昨收")) i = 1 for row in rows: print("{:^10}\t{:^8}\t{:^10}\t{:^20}\t{:^10}\t{:^18}\t{:^16}\t{:^10}\t{:^10}\t{:^10}\t{:^10}\t{:^10}\t{:^10}\t".format(i, row[0],row[1],row[2],row[3],row[4],row[5],row[6],row[7],row[8],row[9],row[10],row[11],)) i += 1 #获取 def getHTMLText(url, loginheaders): try: r = requests.get(url, headers=loginheaders, timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" class StockGet: def __init__(self): self.loginheaders = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.164 Safari/537.36', } def GetStock(self): url="http://6.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112408105779319969169_1634089326282&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1634089326289" data = getHTMLText(url, self.loginheaders) # print(data) # 名称 td1 = re.findall(r'"f14":(.*?),', data) # 代码 td2 = re.findall(r'"f12":(.*?),', data) # 最新报价 td3 = re.findall(r'"f2":(.*?),', data) # 涨跌幅 td4 = re.findall(r'"f25":(.*?),', data) # 涨跌额 td5 = re.findall(r'"f4":(.*?),', data) # 成交量 td6 = re.findall(r'"f5":(.*?),', data) # 成交额 td7 = re.findall(r'"f6":(.*?),', data) # 振幅 td8 = re.findall(r'"f7":(.*?),', data) # 最大 td9 = re.findall(r'"f15":(.*?),', data) # 最小 td10 = re.findall(r'"f16":(.*?),', data) # 今开 td11 = re.findall(r'"f17":(.*?),', data) # 昨收 td12 = re.findall(r'"f18":(.*?),', data) self.db = equity_marketDB() self.db.openDB() for i in range(len(td1)): self.db.insert(td1[i],td2[i],td3[i],td4[i],td5[i],td6[i],td7[i],td8[i],td9[i],td10[i],td11[i],td12[i]) self.db.show() self.db.closeDB() st=StockGet() st.GetStock()
运行结果如下:
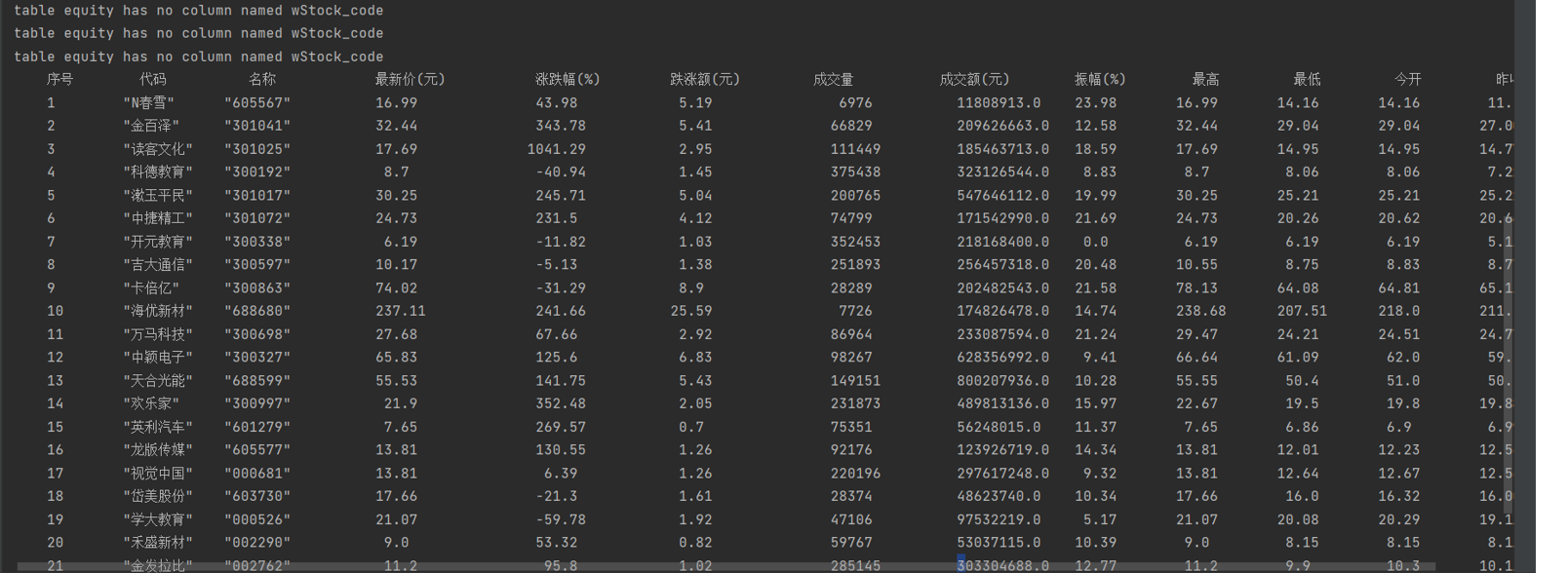
- 心得体会:加深了对谷歌F12模式的理解与掌握,同时对re正则匹配理解进一步加深,对数据库进一步了解。
-
作业③:
-
-
要求: 爬取中国大学2021主榜 https://www.shanghairanking.cn/rankings/bcur/2021
所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。 -
技巧: 分析该网站的发包情况,分析获取数据的api
-
输出信息:
排名 学校 总分 1 清华大学 969.2 -
- 代码如下:
import requests import re url = 'https://www.shanghairanking.cn/_nuxt/static/1632381606/rankings/bcur/2021/payload.js' loginheaders = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.164 Safari/537.36', } #获取 def getHTMLText(url, loginheaders): try: r = requests.get(url, headers=loginheaders, timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" data = getHTMLText(url,loginheaders) #print(data) #匹配 name = re.findall(r'univNameCn:"(.*?)"', data) score = re.findall(r'score:(.*?),', data) #print(name) #print(score) #输出 tplt = "{0:^10}\t{1:{3}^10}\t{2:^10}" print(tplt.format("排名 ", "学校名称", "总分",chr(12288))) for i in range(0,len(name)): print(tplt.format(i+1, name[i], score[i], chr(12288)))
运行结果如下:(这里显示的是后面的,完全图片太长了)
- 部分学校的分数无法爬取,发现是网页代码里面没有对应分数
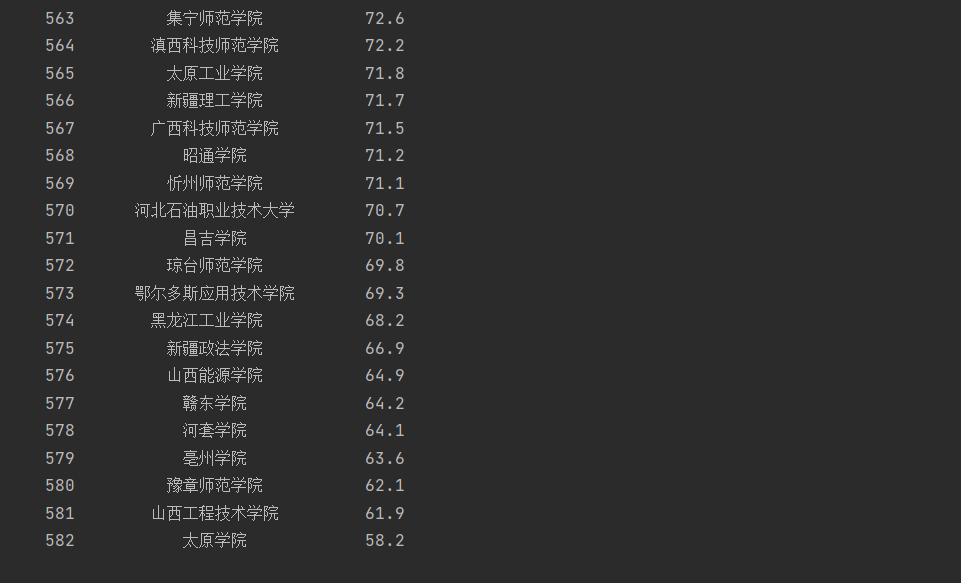
- 心得体会:重新爬取中国大学排名,这次与上次不同,先通过谷歌浏览器中进入F12调试模式进行抓包找到对应的js文件之后再进行re正则匹配,获得了全部的排名。
- 浏览器F12调试分析的过程录制Gif:

-
找到对应的js之后在pycharm转换编码格式,然后运用re正则表达式去匹配即可

