mongoDB同步机制oplog
http://chuansong.me/n/854004
从底层代码实现探讨不同NoSQL数据库之间的性能差异
如今,随着大数据时代的来临,越来越多的人开始跳脱传统的关系型数据库的思维,开始转投NoSQL数据库。这也造成NoSQL数据库市场上也出现百家争鸣的局面。其中MongoDB一马当先,在DB-Engine的数据库影响力排名上达到了第五位,仅次于几个传统的关系型“大户”。可是MongoDB其实在设计和性能表现上也并不是十全十美的。
国内的SequoiaDB 巨杉数据库作为同类的文档型NoSQL数据库,就在多项性能表现上超越了MongoDB,那么现在我们就要来谈谈两者不同的底层架构对于高性能表现的影响。
1.日志
日志作为数据库非常重要的一个运行机制,不仅直接影响着数据库操作的方式效率,也会影响到其他许多功能的实现。
MongoDB的日志使用的是CappedCollection机制。CappedCollection是一种固定大小的集合,当集合的大小达到指定大小时,新数据就会覆盖老数据。基于这种机制,可以实现“Auto-FIFO”以及“Age-Out”的功能。
SequoiaDB的日志则使用的是日志序列号LSN机制,这也是一直被各种数据库所采用的经典日志机制。不仅因为其实现方便,更因为LSN的日志机制可以更好的支持事务功能。
2.锁机制
锁机制也是数据库中重要的一个部分,与性能表现息息相关。
MongoDB对锁的处理相对简单,只有库级粒度的锁,也就是当一个写锁处于占用时,整个库的数据将被锁住,无法使用。虽然设计简洁,且在一般情况下这种机制能发挥很好的作用,但是一旦出现高并发高压力的情况,MongoDB的总体吞吐量就会出现性能的瓶颈。
SequoiaDB的设计理念之一,就是在正常流程下尽可能无锁,异常流程可以使用额外的代码或锁机制保证逻辑正确。这样在遇到像32核的这种大机器下进行高压力并发操作,SequoiaDB也可以把CPU打满,不会在某些代码上出现性能瓶颈。
3.事务
事务也是数据库的重要功能,然而如今的NoSQL基本都没有加入事务功能。
MongoDB也没有事务处理的功能,在原子性的保证方面,其只能做到单个文档级别,不能支持多文件的原子性。
SequoiaDB则在设计之初就融入了事务功能,基于传统的事务日志的机制就是为了更好的实现事务。当然,还有记录锁、表锁这些机制,包括多副本之间数据根据日志的分发同步,节点失效重新选举后日志的同步等一系列机制。都需要为支持事务而量身定制。
4.分区组
在分区组的架构上,MongoDB和SequoiaDB都是使用分片Sharding机制,每个分片里采用Master-Slave结构做数据的复制和同步,同时也通过Sharding分片的机制实现了读写分离,保证了实时读写和后台分析同步进行。其中SequoiaDB的分区组使用了自动选举的功能,当主节点(Master)出现问题时,分区会在剩余可用的从数据节点(Slave)中选举出一个最佳方案,让其替代故障的主节点作为新的主节点。这样不仅保障了系统的安全,也可以提高系统处理故障的性能。
5.代码优化
代码优化看似一项细节上的工程,但是只有每个细小之处的累积,才能汇聚成性能表现的整体提升,也正是细微之处的优化,才更能体现出产品设计和开发人员精益求精、追求完美的精神。
MongoDB作为当今NoSQL数据库的领头羊,其架构设计和代码编写已经是业内一流的水准,但是MongoDB在一些部分相对简单的处理反而在后来造成了其一些性能上的瓶颈,比如锁的机制设计的过于粗放。
SequoiaDB在代码优化和精细化设计这部分做了很多工作,譬如上面提到的并发性和锁的这一部分,为了追求尽量无锁的整体架构,投入了大量的时间和精力。此外,SequoiaDB还有很多细节上的优化,比如在性能敏感的代码里面完全不允许使用String这种STL库,就是为了避免这些深度封装的库会引发额外的操作,造成不必要的损耗。
此外,在分布式架构、自动分区等部分,MongoDB和SequoiaDB也有许多的不同,这里就不一一赘述了。
高性能的数据库产品,不仅要在设计之初就充分考虑到每一种影响性能的情况和任何可能引起性能瓶颈的操作,在设计上考虑周全,同时也需要在实际开发、测试和应用过程中,针对遇到的情况不断的改进、优化代码。对于NoSQL数据库,因为在应用上与大数据息息相关,所以更加需要充分考虑比如突发性、高并发、多样性等原来不被重视的问题,此外面对大数据的快速海量多变,还应该对代码做好充分的测试和优化,这样才能在实际运用中能做到处变不惊,成为真正高性能的NoSQL数据库!
http://www.uml.org.cn/sjjm/2014043011.asp
|
搭建高可用mongodb集群(三)—— 深入副本集内部机制
|
|
|
作者 严澜 火龙果软件 发布于 2014-04-30
|
|
|






http://blog.chinaunix.net/uid-28813259-id-3810714.html
分类: NOSQL
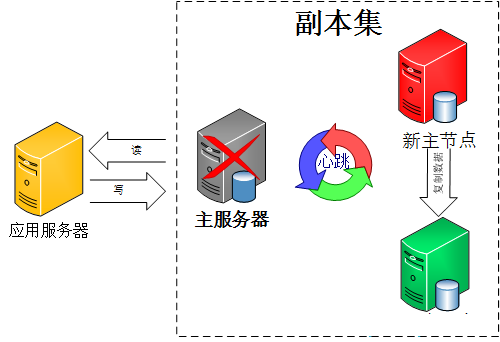
副本集数据同步机制
实例启动后,副本集成员首先通过一次初始化同步来复制数据,然后就开始利用oplog日志和主节点连续进行数据同步。如下日志反应这一过程
点击(此处)折叠或打开
- Wed Jul 17 13:18:39.473 [rsSync] replSet initial sync pending
- Wed Jul 17 13:18:39.473 [rsSync] replSet syncing to: 192.168.69.44:10000
- Wed Jul 17 13:18:39.476 [rsSync] build index local.me { _id: 1 }
- Wed Jul 17 13:18:39.479 [rsSync] build index done. scanned 0 total records. 0.002 secs
- Wed Jul 17 13:18:39.481 [rsSync] build index local.replset.minvalid { _id: 1 }
- Wed Jul 17 13:18:39.482 [rsSync] build index done. scanned 0 total records. 0 secs
- Wed Jul 17 13:18:39.482 [rsSync] replSet initial sync drop all databases
- Wed Jul 17 13:18:39.482 [rsSync] dropAllDatabasesExceptLocal 1
- Wed Jul 17 13:18:39.483 [rsSync] replSet initial sync clone all databases
- Wed Jul 17 13:18:39.483 [rsSync] replSet initial sync cloning db: test
- Wed Jul 17 13:18:39.485 [FileAllocator] allocating new datafile /mongodb/sh1/data/test.ns, filling with zeroes...0.001 secs
- Wed Jul 17 13:18:39.497 [rsSync] build index test.test { _id: 1 }
- Wed Jul 17 13:18:39.498 [rsSync] fastBuildIndex dupsToDrop:0
- Wed Jul 17 13:18:39.498 [rsSync] build index done. scanned 1 total records. 0 secs
- Wed Jul 17 13:18:39.498 [rsSync] replSet initial sync data copy, starting syncup
- Wed Jul 17 13:18:39.498 [rsSync] oplog sync 1 of 3
- Wed Jul 17 13:18:39.499 [rsSync] oplog sync 2 of 3
- Wed Jul 17 13:18:39.499 [rsSync] replSet initial sync building indexes
- Wed Jul 17 13:18:39.499 [rsSync] replSet initial sync cloning indexes for : test
- Wed Jul 17 13:18:39.500 [rsSync] oplog sync 3 of 3
- Wed Jul 17 13:18:39.500 [rsSync] replSet initial sync finishing up
- Wed Jul 17 13:18:39.527 [rsSync] replSet set minValid=51e6290b:1
- Wed Jul 17 13:18:39.527 [rsSync] replSet RECOVERING
- Wed Jul 17 13:18:39.527 [rsSync] replSet initial sync done
- Wed Jul 17 13:18:40.384 [rsBackgroundSync] replSet syncing to: 192.168.69.44:10000
- Wed Jul 17 13:18:40.527 [rsSyncNotifier] replset setting oplog notifier to 192.168.69.44:10000
oplog 在replica set中存在于local.oplog.rs集合,是一个capped collection,启动时候可以通过--oplogSize设置大小,对于linux 和windows 64位,oplog size默认为剩余磁盘空间的5%。
点击(此处)折叠或打开
- sh1:PRIMARY> db.printReplicationInfo()
- configured oplog size: 23446.183007812502MB --配置的oplog日志大小
- log length start to end: 23055secs (6.4hrs) --日志记录的文档的时间范围
- oplog first event time: Wed Jul 17 2013 09:48:00 GMT+0800 (CST) --最早的日志时间
- oplog last event time: Wed Jul 17 2013 16:12:15 GMT+0800 (CST) --最近一次的日志时间
- now: Wed Jul 17 2013 16:12:18 GMT+0800 (CST)
- 下面命令展示的更为直观:
- sh1:PRIMARY> db.getReplicationInfo()
- {
- "logSizeMB" : 23446.183007812502,
- "usedMB" : 11.22,
- "timeDiff" : 23521,
- "timeDiffHours" : 6.53,
- "tFirst" : "Wed Jul 17 2013 09:48:00 GMT+0800 (CST)",
- "tLast" : "Wed Jul 17 2013 16:20:01 GMT+0800 (CST)",
- "now" : "Wed Jul 17 2013 16:20:20 GMT+0800 (CST)"
- }
Init sync同步在下面两种情况发生:
1. secondary第一次加入,就会进行初始化同步,把所有的数据同步过来。
2. Secondary被移出,重新移入后由于数据落后,也会进行init sync应用新的日志。如果节点落后的数量超过opolog大小,也就是说,oplog被覆盖过,那么他会启用一次全量备份,把所有数据复制过来。所以,已经有大量的数据时,加入一个新节点要注意全量复制带来的网络负担。应用高峰期时,不适合做这些操作。
Keep模式复制:
这种复制方式是持续性的,是主节点和副节点正常运行期间的数据同步方式。
Init sync过后,节点之间的复制方式就是实时同步了,一般情况下,secondaries从primary复制数据,但是secondary的复制对象可能会根据网络延时做出一些选择,也许会形成链式同步结构,参见http://www.cnw.com.cn/software-database/htm2012/20120513_246718.shtml
如果两个副节点节在进行复制,那么要求设置相同的buildindex值(默认已经是true)。Secondaries不可能从延迟节点和隐藏节点复制数据。
手从修改syn target:
sh0:SECONDARY> db.adminCommand({replSetSyncFrom:"192.168.69.40:10000"})
{
"syncFromRequested" : "192.168.69.40:10000",
"prevSyncTarget" : "192.168.69.40:10000",
"ok" : 1
}
同步过程如下:
从数据源复制数据(源不一定非要primary),应用日志
建立相应索引
sh1:PRIMARY> db.printSlaveReplicationInfo()
source: 192.168.69.45:10000
syncedTo: Wed Jul 17 2013 16:52:29 GMT+0800 (CST)
= 32 secs ago (0.01hrs)
source: 192.168.69.46:10000
syncedTo: Wed Jul 17 2013 16:52:29 GMT+0800 (CST)
= 32 secs ago (0.01hrs)
可以使用调试命令观察secondary最后同步的一条日志信息:
点击(此处)折叠或打开
- sh1:SECONDARY> rs.debug.getLastOpWritten()
- {
- "ts" : {
- "t" : 1374154241,
- "i" : 1
- },
- "h" : NumberLong("7643447760057625437"),
- "v" : 2,
- "op" : "i",
- "ns" : "test.test",
- "o" : {
- "_id" : ObjectId("51e7ee01b5ed8bdc9436becf"),
- "name" : 5258
- }
- }
{ "ts" : { "t" : 1374154241, "i" : 1 }, "h" : NumberLong("7643447760057625437"), "v" : 2, "op" : "i", "ns" : "test.test", "o" : { "_id" : ObjectId("51e7ee01b5ed8bdc9436becf"), "name" : 5258 } }
oplog结构:
由7部分组成:{ts:{},h{},v{} op:{},ns:{},o:{},o2:{} }
ts:8字节的时间戳,由4字节unix timestamp + 4字节自增计数表示
h: 一个哈希值(2.0+),确保oplog的连续性
v:
op:1字节的操作类型
ns:操作所在的namespace。
o:操作所对应的document
o2:在执行更新操作时o只记录id而o2记录具体内容,仅限于update
op操作类型:
“i”:insert操作
“u”:update操作
“d”:delete操作
“c”:db cmd操作
"db":声明当前数据库 (其中ns 被设置成为=>数据库名称+ '.')
"n": no op,即空操作,定期执行以确保时效性
参见:
http://www.cnw.com.cn/software-database/htm2012/20120513_246718.shtml
http://www.cnblogs.com/daizhj/archive/2011/06/27/mongodb_sourcecode_oplog.html
Replica Sets系列文章之:同步
MongoDB核心开发工程师 Kristina Chodorow(@kchodorow) 最近在她的博客上表示,她会发表一系列关于MongoDB Replica Sets 相关的文章,向大家详细的进行一次 Replica Sets 的知识培训。其系列文章内容包括下面一些章节:
- Elections(选举)
- Creating a set(创建一个replica sets)
- Reconfiguring(更新配置)
- Syncing(同步)
- Initial Sync(初始化同步)
- Rollback(数据回滚)
- Authentication(权限控制)
- Debugging(故障排除)
本文主要对Replica Sets节点间的同步机制和同步协议进行了深入讲解。
同步过程
一个健康的secondary在运行时,会选择一个离自己最近的,数据比自己新的节点进行数据同步。选定节点后,它会从这个节点拉取oplog同步日志,具体流程是这样的:
- 执行这个op日志
- 将这个op日志写入到自己的oplog中(local.oplog.rs)
- 再请求下一个op日志
如果同步操作在第1步和第2步之间出现问题宕机,那么secondary再重新恢复后,会检查自己这边最新的oplog,由于第2步还没有执行,所以自己这边还没有这条写操作的日志。这时候他会再把刚才执行过的那个操作执行一次。那对同一个写操作执行两次会不会有问题呢?MongoDB在设计oplog时就考虑到了这一点,所以所有的oplog都是可以重复执行的,比如你执行 {$inc:{counter:1}} 对counter字段加1,counter字段在加1 后值为2,那么在oplog里并不会记录 {$inc:{counter:1}} 这个操作,而是记录 {$set:{counter:2}}这个操作。所以无论多少次执行同一个写操作,都不会出现问题。
w参数
当我们在MongoDB时执行一个写操作时,默认会直接返回成功,同时也可以通过设置w参数,指定这个写操作同步到几个节点后才返回成功。如下:
db.foo.runCommand({getLastError:1, w:2})
上面例子就是执行getLastError命令,使其在上一个写操作同步到两个节点上后再返回。不同的客户端可能在写法上不太一样,不过这个功能应该都是有的。对于重要数据,可以考虑采用这样的方式,通过牺牲一部分写性能来提升数据的安全性。
这个功能是如何实现的呢,primary节点是如何知道数据同步了几份呢?
在调用上面命令时,实际上MongoDB内部执行了如下的一些流程:
- 在primary上完成写操作
- 在primary上记录一条oplog日志,日志中包含一个ts字段,值为写操作执行的时间,比如本例中记为t
- 客户端调用{getLastError:1, w:2}命令等待primary返回结果
- secondary从primary拉取oplog,获取到刚才那一次写操作的日志
- secondary按获取到的日志执行相应的写操作
- 执行完成后,secondary再获取新的日志,其向primary上拉取oplog的条件为{ts:{$gt:t}}
- primary此时收到secondary的请求,了解到secondary在请求时间大于t的写操作日志,所以他知道操作在t之前的日志都已经成功执行了
- 这时候getLastError命令检测到primary与secondary都完成了这次写操作,于是 w:2 的条件满足了,返回给客户端成功
启动初始化
当一个新节点启动并加入到现在的Replica Sets中时,这时候新启动的节点会查看自己的oplog,通过一个叫 lastOpTimeWritten 的命令查找到它最近的一条写操作。这个命令你也可以随便在命令行执行:
> rs.debug.getLastOpWritten()
这个命令会返回一条oplog记录,其中的ts字段就是最近一次写操作的时间了。
如果你这个节点是全新的,没有数据,那么oplog里也没有数据,这时候节点会选择执行一次全量的同步。本文暂时不对全量同步的方法进行描述。
选择同步源节点
Replica Sets中的节点之间总在同步数据,但是他们不是通过传统的一主多从的方式来同步的。MongoDB的策略是选择一个合适的节点作为数据源。
首先secondary节点会通过ping的时间来确定其它节点与它的距离。时间越长的识为距离越远。然后通过下面方法确定其源节点:
for each member that is healthy:
if member[state] == PRIMARY
add to set of possible sync targets
if member[lastOpTimeWritten] > our[lastOpTimeWritten]
add to set of possible sync targets
sync target = member with the min ping time from the possible sync targets
对于节点是否healthy的判断,各个版本不同,但是其目的都是找出正常运转的节点。在2.0版本中,它的判断还包括了salve delay这个因素。
你可以通过运行db.adminCommand({replSetGetStatus:1})命令来查看当前的节点状况,在secondary上运行这个命令,你能看到syncingTo这个字段,这个字段的值就是这个secondary的同步源。(其实名字应该是叫syncingFrom,但是由于版本兼容的原因,沿用了这个错误的名字)
链式同步结构
 上面对w参数的实现,讲解上比较简单,只讲了w为2的情况,但是当w更大时,由于我们并不是采用一主多从的方式进行同步。所以情况会复杂一些。
上面对w参数的实现,讲解上比较简单,只讲了w为2的情况,但是当w更大时,由于我们并不是采用一主多从的方式进行同步。所以情况会复杂一些。
比如我们有节点A,为primary节点,然后B节点为secondary节点,它从A节点同步数据,同时又有secondary节点C,它从同是secondary的B节点同步数据。这样A->B->C之间就形成了一个链式的同步结构。如果我们设定w为3,那么A节点如何能知道C节点已经从B节点同步成功了呢?
这是通过oplog同步协议来实现的,我们用通俗的语言来解释一下oplog的同步协议。
- 当C从B同步数据时,C会在协议中对B说:我要从你这同步数据了,如果写操作有w参数的话,我的同步也算上吧。
- 然后B会回答说:我不是一个primary节点,我会把你的这个计数转到我的同步源上去。
- 然后B再对A打开一个新的连接,并且对A说:这个连接你就当成是C的吧,也算一个计数在w里。
- 这时候在A看来,就有两个连接连到他上面,一个是B,一个是虚拟的C,这两个连接都能报告他说完成了同步操作。
当一个写操作在A上执行后,B首先同步到这个操作的oplog,执行完后会告诉A,我执行完了。然后C同样从B上获取到B的oplog,也执行了这一条写操作,然后他告诉B,我执行完了,B在收到这个响应后,会通过刚才开通的虚拟通道跟A说,我是虚拟的C节点,我也完成写操作了。这时候A就知道,A、B、C三个节点都完成写操作了。w:3的条件满足,然后返回给调用getLastError的客户端,完成这次操作。
具体三个节点间的连接如下图:
C B A
<====>
<====> <---->
B和A之间有两条通道,双线那条是真正的同步连接,单线那条是一个虚拟连接。
新功能展望
上面就是当前的Replica Sets同步的内部实现,在后续这一块还会进行一些新特性的开发。在2.2版本中,我们会提供replSetSyncFrom命令,让用户可以手动设置一个secondary的同步源。使用方法大概是这样:
> db.adminCommand({replSetSyncFrom:"otherHost:27017"})
敬请期待,thx
http://www.cnblogs.com/guoyuanwei/p/3293668.html
mongoDB研究笔记:复制集数据同步机制
http://www.cnblogs.com/guoyuanwei/p/3279572.html 概述了复制集,整体上对复制集有了个概念,但是复制集最重要的功能之一数据同步是如何实现的?带着这个问题,下面展开分析。
先利用mongo客户端登录到复制集的primary节点上。
>mongo --port 40000
查看实例上所有数据库
rs0:PRIMARY> show dbs
local 0.09375GB
可以看到只有一个local数据库,因为此时还没有在复制集上创建任何其它数据库,local数据库为复制集所有成员节点上默认创建的一个数据库。在primary节点上查看local数据上的集合:
rs0:PRIMARY> show collections
oplog.rs
slaves
startup_log
system.indexes
system.replset
如果是在secondary节点则local数据库上的集合与上面有点不同,secondary节点上没有slaves集合,因为这个集合保存的是需要从primary节点同步数据的secondary节点;secondary节点上会有一个me集合,保存了实例本身所在的服务器名称;secondary节点上还有一个minvalid集合,用于保存对数据库的最新操作的时间截。其它集合primary节点和secondary节点都有,其中startup_log集合表示的是mongod实例每一次的启动信息;system.indexes集合保存的是当前数据库(local)上的所有索引信息;system.replset集合保存的是复制集的成员配置信息,复制集上的命令rs.conf()实际上是从这个集合取的数据返回的。最后要介绍的集合是oplog.rs,这个可是重中之中。
mongoDB就是通过oplog.rs来实现复制集间数据同步的,为了分析数据的变化,先在复制集上的primary节点上创建一个数据库students,然后插入一条记录。
rs0:PRIMARY> use students
switched to db students
rs0:PRIMARY> db.scores.insert({"stuid":1,"subject":"math","score":99});
接着查看一下primary节点上oplog.rs集合的内容:
rs0:PRIMARY> use local
switched to db local
rs0:PRIMARY> db.oplog.rs.find();
返回记录中会多出一条下面这样的记录(里面还有几条记录是复制集初始化时创建的):
{ "ts" : { "t" : 1376838296, "i" : 1 }, "h" : NumberLong("6357586994520331181"),
"v" : 2, "op" : "i", "ns" : "students.scores", "o" : { "_id" : ObjectId("5210e2
98d7b419b44afa58cc"), "stuid" : 1, "subject" : "math", "score" : 99 } }
里面有几个重要字段,其中"ts"表示是这条记录的时间截,"t"是秒数,"i"每秒操作的次数;字段"op"表示的是操作码,值为"i"表示的是insert操作;"ns"表示插入操作发生的命名空间,这里值为: "students.scores",由数据库和集合名构成;"o"表示的是此插入操作包含的文档对象;
当primary节点完成插入操作后,secondary节点为了保证数据的同步也会完成一些动作:
所有secondary节点检查自己的local数据上oplog.rs集合,找出最近的一条记录的时间截;接着它会查询primary节点上的oplog.rs集合,找出所有大于此时间截的记录;最后它将这些找到的记录插入到自己的oplog.rs集合中并执行这些记录所代表的操作;通过这三步策略,就能保证secondary节点上的数据与primary节点上的数据同步了。
查看一下secondary节点上的数据,证明上面的分析是正确的。
rs0:SECONDARY> show dbs
local 0.09375GB
students 0.0625GB
在secondary节点上新插入了一个数据库students。但是有一点要注意:现在还不能在secondary节点上直接查询students集合上的内容,默认情况下mongoDB的所有读写操作都是在primary节点上完成的,后面也会介绍通过设置从secondary节点上来读,这将引入一个新的主题,后面再分析。
关于oplog.rs集合还有一个很重要的方面,那就是它的大小是固定的,mongoDB这样设置也是有道理的,假如大小没限制,那么随着时间的推移,在数据库上的操作会逐渐累积,oplog.rs集合中保存的记录也会逐渐增多,这样会消耗大量的存储空间,同时对于某个时间点以前的操作记录,早已同步到secondary节点上,也没有必要一直保存这些记录,因此mongoDB将oplog.rs集合设置成一个capped类型的集合,实际上就是一个循环使用的缓冲区。
固定大小的oplog.rs会带来新的问题,考虑下面这种场景:假如一个secondary节点因为宕机,长时间不能恢复,而此时大量的写操作发生在primary节点上,当secondary节点恢复时,利用自己oplog.rs集合上最新的时间截去查找primary节点上的oplog.rs集合,会出现找不到任何记录。因为长时间不在线,primary节点上的oplog.rs集合中的记录早已全部刷新了一遍,这样就不得不手动重新同步数据了。因此oplog.rs的大小是很重要,在32位的系统上默认大小是50MB,在64位的机器上默认是5%的空闲磁盘空间大小,也可以在mongod启动命令中通过项—oplogSize设置其大小。
http://www.chinacloud.cn/show.aspx?id=16102&cid=12
http://www.chinacloud.cn/show.aspx?id=16102&cid=12
搭建高可用的MongoDB集群
| [日期:2014-04-25] | 来源:CSDN 作者:严澜 | [字体:大 中 小] |
MongoDB公司原名10gen,创立于2007年,在2013年收到一笔2.31亿美元的融资后,公司市值评估已增至10亿美元级别,这个高度是知名开源公司Red Hat(创建于1993年)20年的奋斗成果。
高性能、易扩展一直是MongoDB的立足之本,同时规范的文档和接口更让其深受用户喜爱,这一点从分析DB-Engines的得分结果不难看出——仅仅1年时间,MongoDB就完成了第7名到第五名的提升,得分就从124分上升至214分,上升值是第四名PotgreSQL的两倍,同时当下与PostgreSQL的得分也只相差16分不到。

MongoDB能以如此速度发展,很大程度上归结于许多传统关系数据库已无法应对当下数据处理的扩展性需求,虽然它们久经考验,并具备不错的性能及稳定性。然而区别于以往的使用方法,许多NoSQL都有着自己的限制,从而也导致了入门难的问题。这里我们为大家分享 严澜的博文——如何搭建高效的MongoDB集群。
以下为博文:
深入副本集内部机制
该系列文章的第一部分介绍了副本集的配置,这个部分将深入研究一下副本集的内部机制。还是带着副本集的问题来看吧!
副本集故障转移,主节点是如何选举的?能否手动干涉下架某一台主节点。
官方说副本集数量最好是奇数,为什么?
MongDB副本集是如何同步的?如果同步不及时会出现什么情况?会不会出现不一致性?
MongDB的故障转移会不会无故自动发生?什么条件会触发?频繁触发可能会带来系统负载加重?
Bully算法
MongDB副本集故障转移功能得益于它的选举机制。选举机制采用了Bully算法,可以很方便从分布式节点中选出主节点。一个分布式集群架构中一般都有一个所谓的主节点,可以有很多用途,比如缓存机器节点元数据,作为集群的访问入口等等。主节点有就有吧,我们干嘛要什么Bully算法?要明白这个我们先看看这两种架构:
指定主节点的架构,这种架构一般都会申明一个节点为主节点,其他节点都是从节点,如我们常用的MySQL就是这样。但是这样架构我们在第一节说了整个集群如果主节点挂掉了就得手工操作,上架一个新的主节点或者从从节点恢复数据,不太灵活。

不指定主节点,集群中的任意节点都可以成为主节点。MongoDB也就是采用这种架构,一但主节点挂了其他从节点自动接替变成主节点。如下图:

好了,问题就在这个地方,既然所有节点都是一样,一但主节点挂了,怎么确定下一个主节点?这就是Bully算法解决的问题。
那什么是Bully算法,Bully算法是一种协调者(主节点)竞选算法,主要思想是集群的每个成员都可以声明它是主节点并通知其他节点。别的节点可以选择接受这个声称或是拒绝并进入主节点竞争。被其他所有节点接受的节点才能成为主节点。节点按照一些属性来判断谁应该胜出。这个属性可以是一个静态ID,也可以是更新的度量像最近一次事务ID(最新的节点会胜出)。详情请参考 NoSQL数据库分布式算法的协调者竞选还有 维基百科的解释。
选举
那么,MongDB是怎进行选举的呢?官方这么描述:
We use a consensus protocol to pick a primary. Exact details will be spared here but that basic process is:
get maxLocalOpOrdinal from each server.
if a majority of servers are not up (from this server’s POV), remain in Secondary mode and stop.
if the last op time seems very old, stop and await human intervention.
else, using a consensus protocol, pick the server with the highest maxLocalOpOrdinal as the Primary.
大致翻译过来为使用一致协议选择主节点。基本步骤为:
得到每个服务器节点的最后操作时间戳。每个MongDB都有oplog机制记录本机操作,方便和主服务器进行对比数据是否同步还可以用于错误恢复。
如果集群中大部分服务器down机了,保留活着的节点都为secondary状态并停止,不选举了。
如果集群中选举出来的主节点或者所有从节点最后一次同步时间看起来很旧,停止选举等待人来操作。
如果上面都没有问题就选择最后操作时间戳最新(保证数据是最新的)的服务器节点作为主节点。
这里提到了一个一致协议(其实就是bully算法),这个和数据库的一致性协议还是有些区别,一致协议主要强调的是通过一些机制保证大家达成共识;而一致性协议强调的是操作的顺序一致性,比如同时读写一个数据会不会出现脏数据。一致协议在分布式里有一个经典的算法叫“Paxos算法”,后续再介绍。
上面有个问题,就是所有从节点的最后操作时间都是一样怎么办?就是谁先成为主节点的时间最快就选谁。
选举触发条件
选举不是什么时刻都会被触发的,有以下情况可以触发。
初始化一个副本集时。
副本集和主节点断开连接,可能是网络问题。
主节点挂掉。
选举还有个前提条件,参与选举的节点数量必须大于副本集总节点数量的一半,如果已经小于一半了所有节点保持只读状态。日志将会出现:
can't see a majority of the set, relinquishing primary
1. 主节点挂掉能否人为干预?答案是肯定的。
可以通过replSetStepDown命令下架主节点。这个命令可以登录主节点使用
db.adminCommand({replSetStepDown : 1})
如果杀不掉可以使用强制开关
db.adminCommand({replSetStepDown : 1, force : true})
或者使用 rs.stepDown(120)也可以达到同样的效果,中间的数字指不能在停止服务这段时间成为主节点,单位为秒。
2. 设置一个从节点有比主节点有更高的优先级。
先查看当前集群中优先级,通过rs.conf()命令,默认优先级为1是不显示的,这里标示出来
[java] view plaincopyrs.conf();
[java] view plaincopy{
"_id" : "rs0",
"version" : 9,
"members" : [
{
"_id" : 0,
"host" : "192.168.1.136:27017" },
{
"_id" : 1,
"host" : "192.168.1.137:27017" },
{
"_id" : 2,
"host" : "192.168.1.138:27017" }
]
}
如果不想让一个从节点成为主节点可以怎么操作?
使用rs.freeze(120)冻结指定的秒数不能选举成为主节点。
按照上一篇设置节点为Non-Voting类型。
当主节点不能和大部分从节点通讯。把主机节点网线拔掉,嘿嘿:)
优先级还可以这么用,如果我们不想设置什么hidden节点,就用secondary类型作为备份节点也不想让他成为主节点怎么办?看下图,共三个节点分布在两个数据中心,数据中心2的节点设置优先级为0不能成为主节点,但是可以参与选举、数据复制。架构还是很灵活吧!

奇数
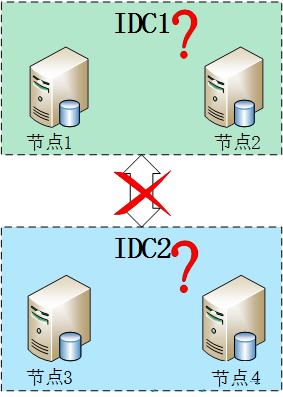
官方推荐副本集的成员数量为奇数,最多12个副本集节点,最多7个节点参与选举。最多12个副本集节点是因为没必要一份数据复制那么多份,备份太多反而增加了网络负载和拖慢了集群性能;而最多7个节点参与选举是因为内部选举机制节点数量太多就会导致1分钟内还选不出主节点,凡事只要适当就好。这个“12”、“7”数字还好,通过他们官方经过性能测试定义出来可以理解。具体还有哪些限制参考官方文档 《 MongoDB Limits and Thresholds 》。 但是这里一直没搞懂整个集群为什么要奇数,通过测试集群的数量为偶数也是可以运行的,参考这个文章http://www.itpub.net/thread-1740982-1-1.html。后来突然看了一篇 stackoverflow的文章终于顿悟了,mongodb本身设计的就是一个可以跨IDC的分布式数据库,所以我们应该把它放到大的环境来看。
假设四个节点被分成两个IDC,每个IDC各两台机器,如下图。但这样就出现了个问题,如果两个IDC网络断掉,这在广域网上很容易出现的问题,在上面选举中提到只要主节点和集群中大部分节点断开链接就会开始一轮新的选举操作,不过MongoDB副本集两边都只有两个节点,但是选举要求参与的节点数量必须大于一半,这样所有集群节点都没办法参与选举,只会处于只读状态。但是如果是奇数节点就不会出现这个问题,假设3个节点,只要有2个节点活着就可以选举,5个中的3个,7个中的4个……

心跳
综上所述,整个集群需要保持一定的通信才能知道哪些节点活着哪些节点挂掉。MongoDB节点会向副本集中的其他节点每两秒就会发送一次pings包,如果其他节点在10秒钟之内没有返回就标示为不能访问。每个节点内部都会维护一个状态映射表,表明当前每个节点是什么角色、日志时间戳等关键信息。如果是主节点,除了维护映射表外还需要检查自己能否和集群中内大部分节点通讯,如果不能则把自己降级为secondary只读节点。
同步
副本集同步分为初始化同步和keep复制。初始化同步指全量从主节点同步数据,如果主节点数据量比较大同步时间会比较长。而keep复制指初始化同步过后,节点之间的实时同步一般是增量同步。初始化同步不只是在第一次才会被处罚,有以下两种情况会触发:
secondary第一次加入,这个是肯定的。
secondary落后的数据量超过了oplog的大小,这样也会被全量复制。
那什么是oplog的大小?前面说过oplog保存了数据的操作记录,secondary复制oplog并把里面的操作在secondary执行一遍。但是oplog也是mongodb的一个集合,保存在local.oplog.rs里;然而这个oplog是一个capped collection,也就是固定大小的集合,新数据加入超过集合的大小会覆盖,所以这里需要注意,跨IDC的复制要设置合适的oplogSize,避免在生产环境经常产生全量复制。oplogSize 可以通过–oplogSize设置大小,对于Linux 和Windows 64位,oplog size默认为剩余磁盘空间的5%。
同步也并非只能从主节点同步,假设集群中3个节点,节点1是主节点在IDC1,节点2、节点3在IDC2,初始化节点2、节点3会从节点1同步数据。后面节点2、节点3会使用就近原则从当前IDC的副本集中进行复制,只要有一个节点从IDC1的节点1复制数据。
设置同步还要注意以下几点:
secondary不会从delayed和hidden成员上复制数据。
只要是需要同步,两个成员的buildindexes必须要相同无论是否是true和false。buildindexes主要用来设置是否这个节点的数据用于查询,默认为true。
如果同步操作30秒都没有反应,则会重新选择一个节点进行同步。
到此,本章前面提到的问题全部解决了,不得不说MongoDB的设计还真是强大!
后续继续解决上一节这几个问题:
主节点挂了能否自动切换连接?目前需要手工切换。
主节点的读写压力过大如何解决?
在系统早期,数据量还小的时候不会引起太大的问题,但是随着数据量持续增多,后续迟早会出现一台机器硬件瓶颈问题的。而MongoDB主打的就是海量数据架构,他不能解决海量数据怎么行!“分片”就用这个来解决这个问题。
传统数据库怎么做海量数据读写?其实一句话概括:分而治之。上图看看就清楚了,如下TaoBao岳旭强提到的架构图:

上图中有个TDDL,是TaoBao的一个数据访问层组件,他主要的作用是SQL解析、路由处理。根据应用的请求的功能解析当前访问的sql判断是在哪个业务数据库、哪个表访问查询并返回数据结果。具体如图:

说了这么多传统数据库的架构,那NoSQL怎么去做到了这些呢?MySQL要做到自动扩展需要加一个数据访问层用程序去扩展,数据库的增加、删除、备份还需要程序去控制。一但数据库的节点一多,要维护起来也是非常头疼的。不过MongoDB所有的这一切通过他自己的内部机制就可以搞定!还是上图看看MongoDB通过哪些机制实现路由、分片:

从图中可以看到有四个组件:mongos、config server、shard、replica set。
mongos,数据库集群请求的入口,所有的请求都通过mongos进行协调,不需要在应用程序添加一个路由选择器,mongos自己就是一个请求分发中心,它负责把对应的数据请求请求转发到对应的shard服务器上。在生产环境通常有多mongos作为请求的入口,防止其中一个挂掉所有的mongodb请求都没有办法操作。
config server,顾名思义为配置服务器,存储所有数据库元信息(路由、分片)的配置。mongos本身没有物理存储分片服务器和数据路由信息,只是缓存在内存里,配置服务器则实际存储这些数据。mongos第一次启动或者关掉重启就会从 config server 加载配置信息,以后如果配置服务器信息变化会通知到所有的 mongos 更新自己的状态,这样 mongos 就能继续准确路由。在生产环境通常有多个 config server 配置服务器,因为它存储了分片路由的元数据,这个可不能丢失!就算挂掉其中一台,只要还有存货, mongodb集群就不会挂掉。
shard,这就是传说中的分片了。上面提到一个机器就算能力再大也有天花板,就像军队打仗一样,一个人再厉害喝血瓶也拼不过对方的一个师。俗话说三个臭皮匠顶个诸葛亮,这个时候团队的力量就凸显出来了。在互联网也是这样,一台普通的机器做不了的多台机器来做,如下图:

一台机器的一个数据表 Collection1 存储了 1T 数据,压力太大了!在分给4个机器后,每个机器都是256G,则分摊了集中在一台机器的压力。也许有人问一台机器硬盘加大一点不就可以了,为什么要分给四台机器呢?不要光想到存储空间,实际运行的数据库还有硬盘的读写、网络的IO、CPU和内存的瓶颈。在mongodb集群只要设置好了分片规则,通过mongos操作数据库就能自动把对应的数据操作请求转发到对应的分片机器上。在生产环境中分片的片键可要好好设置,这个影响到了怎么把数据均匀分到多个分片机器上,不要出现其中一台机器分了1T,其他机器没有分到的情况,这样还不如不分片!
replica set,上两节已经详细讲过了这个东东,怎么这里又来凑热闹!其实上图4个分片如果没有 replica set 是个不完整架构,假设其中的一个分片挂掉那四分之一的数据就丢失了,所以在高可用性的分片架构还需要对于每一个分片构建 replica set 副本集保证分片的可靠性。生产环境通常是 2个副本 + 1个仲裁。
说了这么多,还是来实战一下如何搭建高可用的mongodb集群:
首先确定各个组件的数量,mongos 3个, config server 3个,数据分3片 shard server 3个,每个shard 有一个副本一个仲裁也就是 3 * 2 = 6 个,总共需要部署15个实例。这些实例可以部署在独立机器也可以部署在一台机器,我们这里测试资源有限,只准备了 3台机器,在同一台机器只要端口不同就可以,看一下物理部署图:

架构搭好了,安装软件!
1. 准备机器,IP分别设置为: 192.168.0.136、192.168.0.137、192.168.0.138。
2. 分别在每台机器上建立mongodb分片对应测试文件夹。
#存放mongodb数据文件
mkdir -p /data/mongodbtest
#进入mongodb文件夹
cd /data/mongodbtest
3. 下载mongodb的安装程序包
wget http://fastdl.mongodb.org/linux/mongodb-linux-x86_64-2.4.8.tgz
#解压下载的压缩包
tar xvzf mongodb-linux-x86_64-2.4.8.tgz
4. 分别在每台机器建立mongos 、config 、 shard1 、shard2、shard3 五个目录。
因为mongos不存储数据,只需要建立日志文件目录即可。
#建立mongos目录
mkdir -p /data/mongodbtest/mongos/log
#建立config server 数据文件存放目录
mkdir -p /data/mongodbtest/config/data
#建立config server 日志文件存放目录
mkdir -p /data/mongodbtest/config/log
#建立config server 日志文件存放目录
mkdir -p /data/mongodbtest/mongos/log
#建立shard1 数据文件存放目录
mkdir -p /data/mongodbtest/shard1/data
#建立shard1 日志文件存放目录
mkdir -p /data/mongodbtest/shard1/log
#建立shard2 数据文件存放目录
mkdir -p /data/mongodbtest/shard2/data
#建立shard2 日志文件存放目录
mkdir -p /data/mongodbtest/shard2/log
#建立shard3 数据文件存放目录
mkdir -p /data/mongodbtest/shard3/data
#建立shard3 日志文件存放目录
mkdir -p /data/mongodbtest/shard3/log
5. 规划5个组件对应的端口号,由于一个机器需要同时部署 mongos、config server 、shard1、shard2、shard3,所以需要用端口进行区分。
这个端口可以自由定义,在本文 mongos为 20000, config server 为 21000, shard1为 22001 , shard2为22002, shard3为22003.
6. 在每一台服务器分别启动配置服务器。
/data/mongodbtest/mongodb-linux-x86_64-2.4.8/bin/mongod --configsvr --dbpath /data/mongodbtest/config/data --port 21000 --logpath /data/mongodbtest/config/log/config.log --fork
7. 在每一台服务器分别启动mongos服务器。
/data/mongodbtest/mongodb-linux-x86_64-2.4.8/bin/mongos --configdb 192.168.0.136:21000,192.168.0.137:21000,192.168.0.138:21000 --port 20000 --logpath /data/mongodbtest/mongos/log/mongos.log --fork
8. 配置各个分片的副本集。
#在每个机器里分别设置分片1服务器及副本集shard1
/data/mongodbtest/mongodb-linux-x86_64-2.4.8/bin/mongod --shardsvr --replSet shard1 --port 22001 --dbpath /data/mongodbtest/shard1/data --logpath /data/mongodbtest/shard1/log/shard1.log --fork --nojournal --oplogSize 10
为了快速启动并节约测试环境存储空间,这里加上 nojournal 是为了关闭日志信息,在我们的测试环境不需要初始化这么大的redo日志。同样设置 oplogsize是为了降低 local 文件的大小,oplog是一个固定长度的 capped collection,它存在于”local”数据库中,用于记录Replica Sets操作日志。注意,这里的设置是为了测试!
#在每个机器里分别设置分片2服务器及副本集shard2
/data/mongodbtest/mongodb-linux-x86_64-2.4.8/bin/mongod --shardsvr --replSet shard2 --port 22002 --dbpath /data/mongodbtest/shard2/data --logpath /data/mongodbtest/shard2/log/shard2.log --fork --nojournal --oplogSize 10
#在每个机器里分别设置分片3服务器及副本集shard3
/data/mongodbtest/mongodb-linux-x86_64-2.4.8/bin/mongod --shardsvr --replSet shard3 --port 22003 --dbpath /data/mongodbtest/shard3/data --logpath /data/mongodbtest/shard3/log/shard3.log --fork --nojournal --oplogSize 10
分别对每个分片配置副本集,深入了解副本集参考本系列前几篇文章。
任意登陆一个机器,比如登陆192.168.0.136,连接MongoDB
#设置第一个分片副本集
/data/mongodbtest/mongodb-linux-x86_64-2.4.8/bin/mongo 127.0.0.1:22001
#使用admin数据库
use admin
#定义副本集配置
config = { _id:"shard1", members:[
{_id:0,host:"192.168.0.136:22001"},
{_id:1,host:"192.168.0.137:22001"},
{_id:2,host:"192.168.0.138:22001",arbiterOnly:true}
]
}
#初始化副本集配置
rs.initiate(config);
#设置第二个分片副本集
/data/mongodbtest/mongodb-linux-x86_64-2.4.8/bin/mongo 127.0.0.1:22002
#使用admin数据库
use admin
#定义副本集配置
config = { _id:"shard2", members:[
{_id:0,host:"192.168.0.136:22002"},
{_id:1,host:"192.168.0.137:22002"},
{_id:2,host:"192.168.0.138:22002",arbiterOnly:true}
]
}
#初始化副本集配置
rs.initiate(config);
#设置第三个分片副本集
/data/mongodbtest/mongodb-linux-x86_64-2.4.8/bin/mongo 127.0.0.1:22003
#使用admin数据库
use admin
#定义副本集配置
config = { _id:"shard3", members:[
{_id:0,host:"192.168.0.136:22003"},
{_id:1,host:"192.168.0.137:22003"},
{_id:2,host:"192.168.0.138:22003",arbiterOnly:true}
]
}
#初始化副本集配置
rs.initiate(config);
9. 目前搭建了mongodb配置服务器、路由服务器,各个分片服务器,不过应用程序连接到 mongos 路由服务器并不能使用分片机制,还需要在程序里设置分片配置,让分片生效。
#连接到mongos /data/mongodbtest/mongodb-linux-x86_64-2.4.8/bin/mongo 127.0.0.1:20000
#使用admin数据库 user admin
#串联路由服务器与分配副本集1
db.runCommand( { addshard : "shard1/192.168.0.136:22001,192.168.0.137:22001,192.168.0.138:22001"});
如里shard是单台服务器,用 db.runCommand( { addshard : “ [: ]” } )这样的命令加入,如果shard是副本集,用db.runCommand( { addshard : “replicaSetName/ [:port][,serverhostname2[:port],…]” });这样的格式表示 。
#串联路由服务器与分配副本集2
db.runCommand( { addshard : "shard2/192.168.0.136:22002,192.168.0.137:22002,192.168.0.138:22002"});
#串联路由服务器与分配副本集3
db.runCommand( { addshard : "shard3/192.168.0.136:22003,192.168.0.137:22003,192.168.0.138:22003"});
#查看分片服务器的配置
db.runCommand( { listshards : 1 } );
#内容输出
[plain] view plaincopy{
"shards" : [
{
"_id" : "shard1",
"host" : "shard1/192.168.0.136:22001,192.168.0.137:22001"
},
{
"_id" : "shard2",
"host" : "shard2/192.168.0.136:22002,192.168.0.137:22002"
},
{
"_id" : "shard3",
"host" : "shard3/192.168.0.136:22003,192.168.0.137:22003"
}
],
"ok" : 1
}
因为192.168.0.138是每个分片副本集的仲裁节点,所以在上面结果没有列出来。
10. 目前配置服务、路由服务、分片服务、副本集服务都已经串联起来了,但我们的目的是希望插入数据,数据能够自动分片,就差那么一点点,一点点。。。
连接在mongos上,准备让指定的数据库、指定的集合分片生效。
#指定testdb分片生效
db.runCommand( { enablesharding :"testdb"});
#指定数据库里需要分片的集合和片键
db.runCommand( { shardcollection : "testdb.table1",key : {id: 1} } )
我们设置testdb的 table1 表需要分片,根据 id 自动分片到 shard1 ,shard2,shard3 上面去。要这样设置是因为不是所有mongodb 的数据库和表 都需要分片!
11. 测试分片配置结果。
#连接mongos服务器
/data/mongodbtest/mongodb-linux-x86_64-2.4.8/bin/mongo 127.0.0.1:20000
#使用testdb use testdb;
#插入测试数据
for (var i = 1; i <= 100000; i++)
db.table1.save({id:i,"test1":"testval1"});
#查看分片情况如下,部分无关信息省掉了
db.table1.stats();
[java] view plaincopy{
"sharded" : true,
"ns" : "testdb.table1",
"count" : 100000,
"numExtents" : 13,
"size" : 5600000,
"storageSize" : 22372352,
"totalIndexSize" : 6213760,
"indexSizes" : {
"_id_" : 3335808,
"id_1" : 2877952
},
"avgObjSize" : 56,
"nindexes" : 2,
"nchunks" : 3,
"shards" : {
"shard1" : {
"ns" : "testdb.table1",
"count" : 42183,
"size" : 0,
...
"ok" : 1
},
"shard2" : {
"ns" : "testdb.table1",
"count" : 38937,
"size" : 2180472,
...
"ok" : 1
},
"shard3" : {
"ns" : "testdb.table1",
"count" :18880,
"size" : 3419528,
...
"ok" : 1
}
},
"ok" : 1
}
可以看到数据分到3个分片,各自分片数量为: shard1 “count” : 42183,shard2 “count”: 38937,shard3 “count” : 18880。已经成功了!不过分的好像不是很均匀,所以这个分片还是很有讲究的,后续再深入讨论。
12. Java程序调用分片集群,因为我们配置了三个mongos作为入口,就算其中哪个入口挂掉了都没关系,使用集群客户端程序如下:[java] view plaincopypublic class TestMongoDBShards { public static void main(String[] args)
{ try { List addresses = new ArrayList();
ServerAddress address1 = new ServerAddress("192.168.0.136" , 20000); ServerAddress
address2 = new ServerAddress("192.168.0.137" , 20000); ServerAddress address3
= new ServerAddress("192.168.0.138" , 20000); addresses.add(address1);
addresses.add(address2); addresses.add(address3); MongoClient client =
new MongoClient(addresses); DB db = client.getDB( "testdb" ); DBCollection
coll = db.getCollection( "table1" ); BasicDBObject object = new BasicDBObject();
object.append( "id" , 1); DBObject dbObject = coll.findOne(object); System.
out .println(dbObject); } catch (Exception e) { e.printStackTrace(); }
} }
整个分片集群搭建完了,思考一下我们这个架构是不是足够好呢?其实还有很多地方需要优化,比如我们把所有的仲裁节点放在一台机器,其余两台机器承担了全部读写操作,但是作为仲裁的192.168.0.138相当空闲。让机器3 192.168.0.138多分担点责任吧!架构可以这样调整,把机器的负载分的更加均衡一点,每个机器既可以作为主节点、副本节点、仲裁节点,这样压力就会均衡很多了,如图:

当然生产环境的数据远远大于当前的测试数据,大规模数据应用情况下我们不可能把全部的节点像这样部署,硬件瓶颈是硬伤,只能扩展机器。要用好mongodb还有很多机制需要调整,不过通过这个东东我们可以快速实现高可用性、高扩展性,所以它还是一个非常不错的Nosql组件。
再看看我们使用的mongodb java 驱动客户端 MongoClient(addresses),这个可以传入多个mongos 的地址作为mongodb集群的入口,并且可以实现自动故障转移,但是负载均衡做的好不好呢?打开源代码查看:

它的机制是选择一个ping 最快的机器来作为所有请求的入口,如果这台机器挂掉会使用下一台机器。那这样。。。。肯定是不行的!万一出现双十一这样的情况所有请求集中发送到这一台机器,这台机器很有可能挂掉。一但挂掉了,按照它的机制会转移请求到下台机器,但是这个压力总量还是没有减少啊!下一台还是可能崩溃,所以这个架构还有漏洞!限于文章篇幅,请待后续解决。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号