run-mysql-on-SSDs_centos;优化
http://www.codes51.com/article/detail_103108.html
一次惊心动魄的Percona XTRA Cluster DB数据修复过程
2014.12.27日中午约12:30,电话响起,是同事YI的电话,告之说库中出现大量死锁,用“service mysql restart”无法重启。这里我先说明下:我们在移动音乐项目中使用的是
Percona XTRA Cluster DB,在生成环境中,建议最低是3个节点。但移动移动机器紧张为由,导致数据库运行在单一节点上。虽然此前已经告之了这样导致单点故障,无法保障HA。但移动不以为然,终于导致数据库崩溃发生了。
问题发生后,先用“/etc/init.d/mysql bootstrap-pxc”启动数据库,但显示“table not exists”。分析后,判断这是数据库崩溃导致数据丢失。之后,立即投入数据恢复的紧张工作。
恢复方案为:
1、新建数据库;
2、新建表;
3、discard表空间;
4、拷贝备份的.ibd文件;
5、import表空间;
至此,在新建库上恢复正常。
但又一个新问题,程序中已经引用了之前的数据库名,必须改回原数据库名。至此,立即动手。
方案为:
1、删除原数据库;
2、用原库名新建数据库;
3、拷贝原备份目录(idbata、.ibd文件)
4、之后重复上面的恢复方案
后发现数据库无法正常启动,把my.cnf改为"innodb_force_recovery = 4"。数据库可以启动,但无法新建、删除和更新。这种情况,一种方案是把数据dump出来,
再dump进去。为此,新建了另一个数据库。这次是采用的MySQL官方社区版。在数据DUMP的过程中,发现有的表无法dump。后采用联邦表把数据导入进去。在导入的过程中,还发生了“字段太长,导入失败”的问题,查找后把my.cnf中改为“# sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES”问题解决。
至此,这次Mysql崩溃导致的数据恢复工作完成,数据没有丢失。下面要做的就是MySQL HA了。主要脚本如下:
alter table AUTH_USER discard tablespace;
IT经典笑语录:学习 + 思考 + 实践,前两步做好了,实践起来就会相对轻松愉悦。厚积而薄发,可以让一段程序相对而言得到最优化。缩短写程序的时间,提高写程序的效率,能给自己增强自信。保持愉悦自信的心态,在程序生涯中非常重要。
cp -f /data/munion_db_bak/munion_db/AUTH_USER.ibd /data/munion_db/munion_db
alter table AUTH_USER import tablespace;
mysqldump -u root -pmunion123 -c --default-character-set=gbk munion_db AUTH_USER > /data/dump/AUTH_USER
mysqldump -u root -pmunion123 --default-character-set=gbk munion_db AUTH_USER < /data/dump/AUTH_USER
此次Mysql数据恢复是次难得的经验,当然最好是不要出现这样的问题。这就需要把HA先做在前面了。附另一种数据恢复方案(没有实际验证过):
1. drop these tables from mysql:
innodb_index_stats innodb_table_stats slave_master_info slave_relay_log_info slave_worker_info
2. delete all .frm & .ibd of the tables above.
3. run this file to recreate the tables above (source five-tables.sql).
4. restart mysqld.
Cheers, CNL
以上就介绍了一次惊心动魄的Percona XTRADB Cluster数据修复过程【MySQL】,包括了方面的内容,希望对MySql有兴趣的朋友有所帮助。
http://blog.itpub.net/22664653/viewspace-1140915/
InnoDB 的Page Size一般是16KB,其数据校验也是针对这16KB来计算的,将数据写入到磁盘是以Page为单位进行操作的。而计算机硬件和操作系统,在极端情况下(比如断电)往往并不能保证这一操作的原子性,16K的数据,写入4K 时,发生了系统断电/os crash ,只有一部分写是成功的,这种情况下就是 partial page write 问题。
很多DBA 会想到系统恢复后,MySQL 可以根据redolog 进行恢复,而mysql在恢复的过程中是检查page的checksum,checksum就是pgae的最后事务号,发生partial page write 问题时,page已经损坏,找不到该page中的事务号,就无法恢复。
一 double write是什么?
Double write 是InnoDB在 tablespace上的128个页(2个区)是2MB;
其原理:
为了解决 partial page write 问题 ,当mysql将脏数据flush到data file的时候, 先使用memcopy 将脏数据复制到内存中的double write buffer ,之后通过double write buffer再分2次,每次写入1MB到共享表空间,然后马上调用fsync函数,同步到磁盘上,避免缓冲带来的问题,在这个过程中,doublewrite是顺序写,开销并不大,在完成doublewrite写入后,在将double write buffer写入各表空间文件,这时是离散写入。
如果发生了极端情况(断电),InnoDB再次启动后,发现了一个Page数据已经损坏,那么此时就可以从doublewrite buffer中进行数据恢复了。
二double write的缺点是什么?
位于共享表空间上的double write buffer实际上也是一个文件,写DWB会导致系统有更多的fsync操作, 而硬盘的fsync性能, 所以它会降低mysql的整体性能. 但是并不会降低到原来的50%. 这主要是因为:
1) double write 是一个连接的存储空间, 所以硬盘在写数据的时候是顺序写, 而不是随机写, 这样性能更高.
2) 将数据从double write buffer写到真正的segment中的时候, 系统会自动合并连接空间刷新的方式, 每次可以刷新多个pages;
三 double write在恢复的时候是如何工作的?
If there’s a partial page write to the doublewrite buffer itself, the original page will still be on disk in its real location.-
--如果是写doublewrite buffer本身失败,那么这些数据不会被写到磁盘,InnoDB此时会从磁盘载入原始的数据,然后通过InnoDB的事务日志来计算出正确的数据,重新 写入到doublewrite buffer.
When InnoDB recovers, it will use the original page instead of the corrupted copy in the doublewrite buffer. However, if the doublewrite buffer succeeds and the write to the page’s real location fails, InnoDB will use the copy in the doublewrite buffer during recovery.
--如果 doublewrite buffer写成功的话,但是写磁盘失败,InnoDB就不用通过事务日志来计算了,而是直接用buffer的数据再写一遍.
InnoDB knows when a page is corrupt because each page has a checksum at the end; the checksum is the last thing to be written, so if the page’s contents don’t match the checksum, the page is corrupt. Upon recovery, therefore, InnoDB just reads each page in the doublewrite buffer and verifies the checksums. If a page’s checksum is incorrect, it reads the page from its original location.
--在恢复的时候,InnoDB直接比较页面的checksum,如果不对的话,就从硬盘载入原始数据,再由事务日志 开始推演出正确的数据.所以InnoDB的恢复通常需要较长的时间.
四 我们是否一定需要 double write ?
In some cases, the doublewrite buffer really isn’t necessary—for example, you might want to disable it on slaves. Also, some filesystems (such as ZFS) do the same thing themselves, so it is redundant for InnoDB to do it. You can disable the doublewrite buffer by setting InnoDB_doublewrite to 0.
五 如何使用 double write
InnoDB_doublewrite=1表示启动double write
show status like 'InnoDB_dblwr%'可以查询double write的使用情况;
相关参数与状态
Double write的使用情况:
show status like "%InnoDB_dblwr%";
InnoDB_dblwr_pages_written 从bp flush 到 DBWB的个数
InnoDB_dblwr_writes 写文件的次数
每次写操作合并page的个数= InnoDB_dblwr_pages_written/InnoDB_dblwr_writes
http://blog.csdn.net/yanghua_kobe/article/details/7485296
当一个传统的向外扩展的方式对于MySQL来讲变得流行,看看我们不得不扩充哪一方面(便宜的内存?快速存储?更好的电源效率?)将会变得非常有趣。这里确实有很多种选择——我每周大概会遇到一个客户使用Fushion-IO 卡。然而,我却看到了他们一个有趣的选择——他们选择购买一个SSD,当他们每秒仍然能读取很多页的时候(这时,我宁愿选择购买内存来取代),而使用存储驱动器做“写操作”使用。
在这里,我提出几个参考标准来供你确认是否是以上我说的这种情况:
- Percona-XtraDB-9.1 release
- Sysbench(开源性能测试工具)的OLTP有8千万行的“工作量”(大概等同于18GB的数据+索引)
- XFS 文件系统选择nobarrier选项安装
- 测试运行具有:
1. 带有BBU的RAID 10硬盘超过8块(所谓BBU,社区的解释是在掉电的情况下,能够cache数据72h,当机器供电正常,再从cache中将数据写入磁盘)
2. Inter SSD X25-E 32GB
3. FushionIO 320GB MLC【1】
- 对于每一次测试,在运行的时候将缓冲池设置在2G到22G之间(为了和合适的内存比较性能)
- 硬件配置:
Dell PowerEdgeR900
4 QuadCoreIntel(R) Xeon(R) CPU E7320 @ 2.13GHz (16 cores in total)
32GB of RAM
RAID10 on 8disks 2.5” 15K RPMS
FusionIO 160GBSLC
FusionIO 320GBMLC
OS:
CentOS 5.5
XFS filesystem
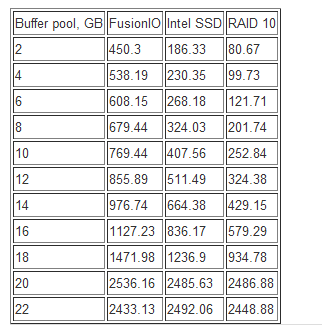
开始,我们对RAID 10的存储做一个测试以建立一个基线。Y轴是每秒传输的数据(传输速率,它越大越好)。X轴是innodb_buffer_pool_size的大小。

我特地挑选了关于该测试中的三个有趣的点
- A点,当数据完全符合缓冲池大小(最佳性能)。一旦你达到该点,简直就像内存的进一步增加,了解该信息很重要。
- B坐标出现在当数据刚开始超过缓冲池的大小。这对于许多用户来讲是最让人头疼的一点了。因为当内存下降仅10%,而性能却比原来降低了2.6倍。在产品中,这通常应对着这样的说辞——“上个星期一切看起来都还OK,但它却正在变得越来越慢!”。我想建议你,增加内存是迄今为止最好的做法,在这种情况下。
- C点展示数据大约是缓冲池三倍的地方。它是一个有趣的点,既然你不能够计算出内存的花费(可能不了解未来遇到瓶颈需要耗费多少购买内存的成本),这是购买一个SSD可能更为合适。

在C点,在这幅图中,一个Fusion-IO卡提升性能达5(如果你采用Interl SSD将会是2倍)。为了用增加内存的方式获得相同的性能提升,你将需要增加多于60%的内存-或者如果你想提升5倍的性能,需要增加超过260%的内存大小。想象一下这样一个生产环境:你的C点(假设像上面说的系统越来越慢)产生是在当你采用了32GB的RAM以及100GB的数据时。那么它将变得有趣了:
- 你能简单地增加另一个32G的RAM(你的内存插槽以及被插满了吗?)
- 你的预算允许你安装一个SSD卡吗?(你可能仍然需要不止一个,因为它们都相对较小。已经有一些市场上的家电,它们使用了8块Intel的SSD设备)。
- 是否2倍或者5倍的性能提升能够足够满足你的需求?如果你能够买得起所有需要的内存,我想你可能会获得更好的性能。
这里的测试被设计为——尽可能多地保证“热”数据,但我猜想这里最需要吸取的教训是不要低估你的“活动集”数据的大小。比如,某些人他只是追加数据到一些排序的日志表,它可能只需要很小的百分比,但在其他情况下,它可能被认为需要占用很大的百分比(比如日志记录地相对频繁)。
重要的注意点:该图以及这些结论只是在sysbenchuniform中被验证。在你特殊的工作场合中,B点和C点可能的分布位置会有所不同。
图中的源结果数据:
引用:
【1】:目前SSD硬盘使用两种形式的NAND闪存:单级单元(SLC)和多级单元(MLC)。两者之间的差额是每单元存储的数据量,SLC每单元存储1比特而 MLC每单元存储2比特。关键在于,SLC和MLC占据了相同大小的芯片面积。因此,在同样的价格下,MLC可以有两倍容量的效果。
SLC和MLC的擦除性能是一样的,MLC闪存的读取性能需花费两倍长的时间,写入性能需花费四倍长的时间。
SLC的最大优势不在于它的性能好而在于它的使用寿命长。
ps:SLC因为速度快,使用寿命长,一般被用在企业级SSD上。而MLC则多用在消费级市场,如workstation。Fusion-io开发出一种管理MLC闪存的新技术SMLC(Single Mode Level Cell),将SLC技术的企业可靠性与消费级MLC闪存结合起来。SMLC技术的带宽与SLC接近,其耐用性和写入性能也可以与SLC媲美,且成本大大低于传统SLC解决方案。
http://backend.blog.163.com/blog/static/2022941262013102811320942/
我们的性能测试使用的测试工具是Sysbench,测试场景主要包括5类:全内存非事务更新(nontrx)、全内存事务更新(complex)、非全内存查询(select)、非全内存非事务更新(nontrx)、非全内存的事务更新(complex)。在非全内存的事务更新测试中,我们发现了一个奇怪的现象,如下图所示:

MySQL一般使用Innodb作为底层存储引擎,而Innodb是一种基于磁盘存储的系统,即所有的数据最终都需要保存在磁盘上。为了提高效率,MySQL使用了内存缓冲池的技术,对于每次用户的更新请求,如果用户需要更新的数据已经在缓冲池中,则直接更新内存的缓冲池;如果缓冲池未命中,Innodb会将要更新的数据页先从磁盘读入内存,然后进行更新,也就是说所有的更新都是在内存中完成的!
但是内存能够容纳的脏页是有限的,同时由于redo log只有记录的更新刷新到磁盘,redo log才可以被覆盖重写,所以MySQL使用了检查点的技术,根据一定的策略将内存中的脏页刷出到磁盘上。

所以整个日志空间可以描述为下面这个图。

为了保证未刷脏页的redo log不被覆盖,MySQL使用了下面的脏页刷新策略,例如当log cap 大于整个日志空间的75%时,系统会异步的将log cap部分的日志涉及的脏页刷到磁盘上,但是此时事务提交不会终止,也就是说还允许有redo log的继续写入。但是如果log cap继续增加,当超过整个日志空间的90%时,MySQL会停止事务的更新,此时redo log也会停止写入,必须等到刷足够的脏页时,才能允许事务再次提交。本质上说,如果事务提交的速度大于脏页刷盘的速度,最终都会触发上述日志保护的功能,即最终系统停止事务的更新,来保证日志记录的脏页能够刷新到磁盘上。
这就解释了我们上面看到的TPS出现周期性的降到0的情况,但是有一个疑问,为什么在物理盘上却很少看到上述的情况呢?这要从SSD IO特性讲起。普通的机械磁盘是依靠磁头移动来实现数据的定位的,所以其随机读写能力受限于磁盘的转速,相对于SSD有非常明显的差距,而顺序IO,普通机械磁盘相对于SSD,并没有太多的差距。那就有个疑问,日志本身是顺序IO,在SSD上和物理磁盘上写日志本身应该没有太大的差别,但是千万不要忘记,在写日志的时候,同时也在刷脏页,为了保证事务安全,一般我们会设置每次事务提交都会刷新log buffer到磁盘,而log buffer默认8M,本身是很小的IO,刷脏页是随机IO,刷脏页和写日志交错进行,磁盘的IO也不再顺序IO,而会变成随机IO,这样物理磁盘和SSD就会出现差别,SSD虽然会有写放大的因素,随机写相对随机读性能较差,但是相对于普通机械磁盘,还是有非常大的优势的,所以SSD就会出现日志的写入速度远远大于检查点的推进速度,但是在普通物理机械磁盘上,就不容易出现,因为刷脏页的随机IO会拖慢事务的提交速度,日志写入序号与检查点之间的差距增长不会那么快。这也就是为什么在SSD的场景下更容易出现MySQL TPS周期性波动的原因。
分析清楚了问题产生的原因,下一步我们来看看有什么办法来解决这个问题。首先,问题产生的原因归根到底就是脏页刷的太慢,事务提交的太快,日志空间不足以支撑他们之间速度的差距。事务提交的速度我们固然无法让其降低,但是我们可以从加快脏页的刷新来想想办法。Innodb在刷脏页的时候有一个关键特性就是会将脏页临近的脏页一并刷出,这样也可以将随机IO转化成顺序IO,当然,如果脏页被再次更新,就会存在重复刷新的问题,但是对于普通磁盘而言,这点开销是完全值得的。但是对于SSD,随机IO能力相对于顺序IO并没有非常大的差距,所以完全可以关闭刷新邻接脏页!这样一方面可以减少脏页刷新的数量,另一方面也可以避免脏页再次被更新后出现的重复刷新的问题。
在MySQL中一次刷新的脏页的数量有一个 innodb_io_capacity的参数进行控制, innodb_io_capacity越大,一次刷新的脏页的数量也就越大,在SSD的场景下,由于IO能力大大增强,所以 innodb_io_capacity需要调高,可以配置到2000以上,但是对于普通机械磁盘,由于其随机IO的IOPS最多也就是300,所以 innodb_io_capacity开的过大,反而会造成磁盘IO不均匀。最后还需要再提一点,就是可以在SSD的场景下适当增大redo log的大小,当然这个不能从根本解决上述TPS 波动的问题,只是能够将两次TPS波动的距离拉长。经过上述优化测试,我们得到对于结果如下图所示:

红色是优化后的TPS曲线,蓝色是原先的TPS曲线,TPS周期性的降到0的问题消失啦!
——EOF——
http://www.mysqlab.net/blog/2010/06/mysql-innodb-ssd-solution-double-write-buffer-redo-log/
使用SSD跑InnoDB注意事项及解决方案
相信有不少同仁已经做过过SSD作为存储对IO瓶颈的数据库性能测试,在得到可喜的成绩之余,在用于生产环境之前需要解决一些问题。
InnoDB共享表空间包含:
Data dictonary
Double write buffer
Insert buffer
Rollback segments
UNDO space
其中为了实现在脏数据异步回写到磁盘的过程中不造成页面(page)完整性问题,默认2M大小的Innodb的Double write buffer在做checkpoint的过程中会不停的擦写,而当前SSD对固定区域的读写次数是有限制的(比如200万次),这将造成这块区域在很短的时间内损坏。同样,InnoDB的redo log也会进行循环写操作,只因为大小可以设置,一般比Double write buffer要大上很多,损坏会慢一点。
因此如果我们打算在生产环境使用SSD,那么我们可以将 Redo log 和 Double write buffer设置指定到具有电池模块,能开启WB策略的Raid上,从而避免问题的出现。Redo log的配置不难,那么Double write buffer怎么处理? percona新发布的MySQL版本提供percona_innodb_doublewrite_path 参数,可以将Double write buffer单独指定到独立位置,从而将问题加以解决。
AD:
1:MySQL实验室将组织一批志同道合的朋友共同翻译、创作和维护MySQL中文参考手册,以最新的GPLMySQL英文文档为基础。新的内容我们根据实际情况自行添加和维护,并且计划提供comment功能,帮助充实文档内容,欢迎英文基础较好并且有相关经验的朋友参加。文档将在 http://www.mysqlab.net/docs/ 同步发布。
2:MySQL实验室网站放在美国加州, 需要稳定的CDN(目前2M带宽即可)赞助,有好心人请联系QQ:55300231。
3:MySQL实验室BLOG将有新作者/译者加盟,将翻译/创作一些国外优秀的文章和博客。
4:如果免费提供监控报警应用,是愿意开放一个限制权限的帐号,还是愿意安装agent(提供能多的监控服务)?
Related posts:
***************************************************************************************************
http://codemonkey.ravelry.com/2011/05/09/so-you-want-to-run-mysql-on-ssds/'
So you want to run MySQL on SSDs?
Here’s why I do: it’s time for me to build a new master database server. Our current main slave is too underpowered to be handle our entire load in an emergency, which means that our failover situation isn’t that great. I’ll replace the master with something new and shiny, make some performance improvements while I’m at it, and the old master will work just fine in an emergency.
For IO intensive servers, I conserve space and electricity by using 1U machines with 6 or 8 2.5″ drives.
I’d normally buy 8 Seagate Savvio 15K SAS drives and set them up as a RAID 10 array. This would run me about $1850.
We’re pretty frugal when it comes to our technology budget and I can’t really stomach spending that kind of money to effectively get 550 GB of redundant, fast magnetic disk storage. SATA MLC SSDs that blow traditional drives out of the water are currently under $2 / GB.
Disclaimer
This is a collection of information that I’ve used to inform my decisions. I don’t know what I’m doing, so I don’t want you to take my word for it (seriously) – I’m just hoping that this collection of links will be useful to some people.
Also, this plan might make no sense to you depending on your situation. We buy 1 or 2 servers a year and saving a thousand dollars is a big deal to us.
One more thing: Today is May 9th, 2011. The SSD universe is expanding quickly and this post will likely be obsolete in a matter of months.
Should you buy RAM instead?
Yes. Increasing the size of your InnoDB buffer pool is the best way to speed up MySQL. If you can add more RAM, do it.
It costs $1000 to buy 48 GB of RAM. If your working set (your hot data) can fit into RAM, you probably don’t need to bother with SSDs at all.
Which SSD to choose?
The Intel 320 Series.
It’s an MLC based, Serial ATA SSD in the 2.5″ form factor.

Why?
- Same price as magnetic disks: the 300 GB version is $540. This is the same price (!!) as the soon to be available Savvio 15K.3 300 GB SAS hard drive.
- Same level of relability as magnetic disks: This drive is more reliable than the X25-M which I have had great success with. Check out this marketing slide with failure rates from over 1 million deployed X25-M units.
- This device includes power-loss data protection. Many SSDs can lose the data that is in the process of being written in the event of a power loss. This is very bad. (Intel PDF link)
- This is the 3rd generation of a proven piece of hardware. I feel very comfortable choosing this Intel device and feeling comfortable is good.
- Intel has published spec information for server applications that addresses my write endurance concerns. The biggest problem with using MLC based SSDs is that the number of writes that they can handle over their lifetime is drastically smaller than what an SLC can do. This specification PDF gives you some information as well as documentation on the SMART attributes that you can use to predict the life span of the drive given your load.
You might say…
Q: MLCs are bad, shouldn’t you be using an SLC drive like the Intel X25-E.
A. The X25-E is $10 a gigabyte. Even if I weren’t trying to save money, I can’t see spending that much on a 3 Gbps Serial ATA drive. This MLC would be a bad choice for me (vs SLC) if it wouldn’t be able to meet my write needs… but it will.
Check out the PDF mentioned in the last item above. As an aside, Intel’s strategy with this drive is a little strange – they clearly intend for it to be used in server environments but it doesn’t appear to be marketed that way.
Q. Why not choose a PCI solution like Fusion-io ioDrive or Virident TachIOn?
A. The Virident TachIOn looks like a fantastic piece of hardware – check out this benchmark/post on MySQL Performance Blog.
Unfortunately, the 400 GB TachIOn is over $13,000 and I’d probably need the 600 GB model. These are for people who have a serious need for hundreds of gigabytes of persistent flash storage. If this were my only good option, I’d stick with 15K SAS disks.
Q: Why Intel? There are much faster SSDs on the market. The 320 isn’t even a 6 Gbps drive
A: I’m not convinced that it matters much for currently available versions and forks of MySQL, but even if it did – these other vendors can’t really touch Intel’s reliability. I researched the market before this Intel drive was released (> 5 weeks ago) and I had tentatively decided that I wouldn’t be able to use SSDs at all.
Your RAID controller might matter
Check out this slide from Yoshinori Matsunobu’s (highly recommended!) “Linux and H/W Optimizations for MySQL“

Scary, huh? I tend to use LSI’s low profile battery-backed MegaRAID controllers. I did a little looking to make sure my usual controller of choice (LSI 9261) would still be a good choice and I found something interesting. For about $100, I can get a software upgrade called “FastPath” that improves performance when RAIDing SSDs.
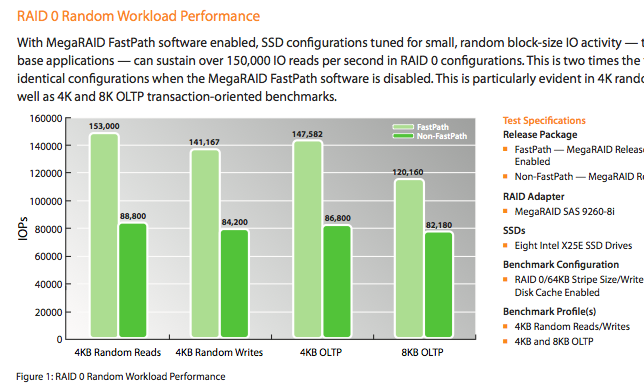
Neat. I haven’t really heard about this product much and it could be snake oil for all I know ![]() but I figure that it’s worth a try.
but I figure that it’s worth a try.
LSI has a fancy new controller that claims it doubles the IOPS of the 9260s when used with SSDs. It’s about $700 so by the time you add battery backup and the FastPath software, you’ve paid $1000 for a RAID controller. Too rich for my blood, I’ll stick with the 9261 for now.
The Hardware Configuration
Here’s what I’ve purchased:
- Supermicro 1016T – my favorite server building block. 1U, eight 2.5″ drives, Xeon 5600, 12 DIMM sockets, redundant power, built in management
- 6 x Intel 320 SSDs configured in RAID 10. SSDs aren’t mechanical, but they can still fail.
- 2 x Seagate Savvio 15K SAS drives Yup! Trusty Savvio SAS drives – these guys are going to handle the bulk of the sequential writes (doublewrite buffer, transaction logs) since that’s what they do best.
- The LSI 9261 with FastPath software upgrade
Linux Tuning
I’ll keep this short:
- Use the latest kernel
- Do not use the default IO scheduler. CFQ is a little slower with MySQL on regular disks as it is! Change the scheduler to
deadlineornoop. - Use the best filesystem that you can (XFS or EXT4) Someday we’ll have ZFS or SSD optimized filesystems on Linux, but we don’t have either today.
- You probably want to disable your filesystem’s access time and write barrier /write through options (
noatime,nobarrierorbarrier=0in fstab)
MySQL Tuning
If you are going to run MySQL on SSD drives you MUST use Percona’s XtraDB
Really. Stock MySQL’s performance is not even close to what Percona Server can do with SSDs. You can get Percona’s improvements in two ways: in Percona Server orMariaDB.
I usually recommend MariaDB but they do not yet have a release that builds on MySQL 5.5. I may use Percona Server myself.
Put your logs and your doublewrite buffer on traditional hard disks
These files are sequentially (and heavily) written – they are not a good fit for SSD and they are a good fit for traditional disks. The doublewrite buffer location is configurable in Percona Server. The setting is: innodb_doublewrite_file
Here’s a longer explanation with benchmarks:http://yoshinorimatsunobu.blogspot.com/2009/05/tables-on-ssd-redobinlogsystem.html
…and here is the TL;DR

Tune InnoDB internals
Set innodb_adaptive_checkpoint = keep_average
Set innodb_flush_neighbor_pages = 0
See http://www.percona.com/docs/wiki/percona-server:features:innodb_io_51
You’ll probably want to tune innodb_io_capacity as well:http://dev.mysql.com/doc/refman/5.1/en/innodb-parameters.html#sysvar_innodb_io_capacity
Um… Yeah, I’m just going to buy more RAM instead
Good choice ![]()
I’ll leave you with recommendation: consider trying out SSDs on for slave databases. They are especially awesome for backup slaves because any old box and a single SSD may be fast enough to replicate your MySQL database. It’s really nice to have a slave that is dedicated to only backups and with SSDs, doing this is so cheap that there are few reasons not to.
Some Best Practices for your Next MySQL Installation with SSD

Do you plan on installing a new MySQL server?
Did you ask yourself what is the best file system for it?
What modification are recommended?
What MySQL version to use?
Do you consider using SSD?
You got to the right place.
Linux, SSD and MySQL. The Best Practices
- Up to date CentOS (6.3). MySQL RPM are easily available for this platform w/o the need to compile them.
- ext4 file system. It is has some goodies over ext3 and is even more recommended if you plan to use SSD (and you may need SSD if your system is resource demanding).
- File system discard option. Recommended for SSD to avoid the need to read before write.
- Consider some extra cheaper disks. SSD disks are highly expensive and can have a relatively short life if they are not used properly. Consider placing some cheaper disks (SAS or SATA) to handle tasks that do not require the high end SSD disks.
- Some more recommendations about Linux and SSD from Patrick's:
- File system layer: remove 'relatime' if present and add 'noatime,nodiratime,discard' to reduce writes and improve performance and disk life expectancy.
- Scheduler: use the 'deadline' scheduler instead of 'CFQ' to match SSD behavior.
- Swap: set a small swappiness
- tmp: move /tmp and /var/tmp to RAM disk to improve performance and avoid unneeded writes to disk.
- Partition Alignment: when creating a partition, enter a start sector of at least 2,048 and divisible by 512 to align pages.
- MySQL 5.6. 5.6 if finally in GA and it good idea to start working with it before 5.5 become obsolete.
Bottom Line
Few decisions can enhance your MySQL performance. Make your decisions right.
Keep Performing,
Moshe Kaplan
I'm testing SSDs for use with MySql and am unable to see any performance benefits. This makes me feel like I must be doing something wrong.
Here is the setup:
- Xeon 5520 2.26 Ghz Quad Core
- 12 GB Ram
- 300GB 15k in RAID 1
- 64GB SSD in RAID 1
For the test I moved the mysql directory on the SSD.
I imported a table with 3 million rows. Then imported the same table with the data and index directories symlinked to the 15k drive.
Loading the data into the tables via a dump from mysqldump the 15k drives showed a faster insert rate over the SSDs:
- 15k ~= 35,800 inserts/sec
- SSD != 27,000 inserts/sec
Then I tested SELECT speed by doing 'SELECT * FROM table INTO OUTFILE '/tmp/table.txt':
- 15kk ~= 3,000,000 rows in 4.19 seconds
- SSD ~= 3,000,000 rows in 4.21 seconds
The SELECTS were almost identical and the writes were actually slower on the SSD which does not seem right at all. Any thoughts on what I should look into next?
http://www.simplemachines.org/community/index.php?topic=454535.0
#############################################################################
...
http://blog.sina.com.cn/s/blog_b721372d01019955.html
首先,需要知道的是,我们购买固态硬盘的初衷是为了使用,不是为了永久性地维护;既然使用,磨损和消耗是不可避免的。所以我觉得适当的设置一下是可以的,但是追求绝对的优化是得不偿失的,甚至会脱离我们的初衷。
谷歌一下linux ssd, 第一篇就是这个SSD (固态硬盘) - Linux Wiki,这篇文章写的相当不错,非常严谨地给出了具体的分析,不是像一般的人那种告诉你只要这么做就行。那只是对他的情况有效而已,或者是他认为有效而已。
下面是我总结的linux下SSD设置的一般性方法:
- 4k对齐。这是对于ssd硬盘非常重要的。我采用的方式是安装系统时将整个盘都分配给/目录下。安全省心。linux下如何检查4k对齐?
- I/O调度方案。具体的做法是sudo nano /etc/rc.local,然后在exit 0之前输入
echo noop > /sys/block/sdX/queue/scheduler
- 定时trim。我选择的方式在使用crontab定时执行fstrim -v /命令。sudo nano /etc/crontab ,然后按照下图的样式添加一行。我添加的是每一个小时执行一次trim,具体可以搜索crontab的相关命令,自己修改。当然你也可以自己手动进行trim,或者将其写进开机执行的命令当中。
经过以上的优化,正常情况下一般用户的操作基本上可以保证SSD使用数年,估计它还没坏你就要换电脑了,所以不建议做进一步的优化,因为其他的优化很可能会导致意外的情况发生或者影响性能。
http://www.jianshu.com/p/nQpqsN
Linux环境下的SSD优化
前提
- 升级到最新的Linux发行版本(主要是Kernel)
- 升级到最新的SSD Firmware
使用sudo smartctl -a /dev/sda命令查看Firmware版本。 - 使用Ext4文件系统
btrfs 虽然支持专门的SSD mountc参数,但是本身文件系统的稳定性还不高。 - 开启BIOS AHCI
- 有条件的加满RAM,因为它比SSD便宜。
配置RAMDISK可以有效的将SWAP操作减少。参见Reduction of SSD write frequency via RAMDISK - 不要使用TLC芯片的SSD
- 不要做碎片整理操作Defragmentation
- 不建议开启hibernation休眠功能,因为会有大量的数据读写。但是从笔记本使用角度来说,还是开着吧,关了也要操作很多配置。
开启磁盘的TRIM功能:
Linux对文件的删除只是删除对数据的指向,所以文件恢复非常方便。在删除数据后,文件系统在了解到这些存储空间的释放后,会对其进行重新分配。HDD在对这些空间的数据重写上效率很高,但是SSD就慢很多。SSD具有非常高效的写操作速度,但是对已有数据的重写速度比较忙。TRIM可以定期的将删除文件清除掉,避免重写过程,释放出空间,保证SSD的高效写操作。如果SSD空间充足,可以不必开启TRIM。
引用资料描述:
An SSD organizes data internally into 4k pages and groups 128 pages into a 512k block. SSDs can write only into empty 4k pages and erase in big 512k block increments. This means that although SSDs can write very quickly, overwriting is a much slower process. The TRIM command keeps your SSD running at top speed by giving the filesystem a way to tell the SSD about deleted pages. This gives the drive a chance to do the slow overwriting procedures in the background, ensuring that you always have a large pool of empty 4k pages at your disposal.
方法1-修改/etc/rc.local文件 推荐
在最后一条命令exit 0 前增加如下内容:
fstrim -v //为root分区(SSD硬盘分区)
不建议使用fstrim-all命令,在非三星和Intel SSD上会有性能瓶颈,参考URL:deepin 2014对SSD支持如何
方法2-cron
echo -e "#\x21/bin/sh\nfstrim -v /" | sudo tee /etc/cron.daily/trim
sudo chmod +x /etc/cron.daily/trim
方法3-修改/etc/fstab文件
修改SSD相关分区条目,增加discard 和 noatime参数
/dev/sda1 / ext4 discard,noatime,commit=600,errors=remount-ro 0 1
- discard参数启动SSD的TRIM功能,可以提升性能和使用持久性。
- notime参数告诉文件系统不要记录文件的最后访问(读取)时间,只记录最后修改时间。可以有效减少对磁盘的读写次数,因为访问频率相对修改来说非常多。
PS:
1.如果发现noatime参数影响了某些应用的使用,可以修改notime为relatime,将会让文件系统将最后修改时间作为文件的最后访问时间。
2.不推荐这个方式(只针对discard参数,noatime还是推荐的)。The disadvantage of this method is, that it may cause the system to slow down. Because it forces the system to apply TRIM instantly on every file deletion. That's why this method is not my favourite.
分区对齐
SSD硬盘内部的操作是512k的块大小。在SSD刚刚发布的时候,磁盘分区系统可能会有分区对其的问题,现在的版本都支持SSD的512k分区范围了:
- fdisk uses a one megabyte boundary since util-linux version 2.17.1 (January 2010).
- LVM uses a one megabyte boundary as the default since version 2.02.73 (August 2010).
建议使用fdisk, fdisk 会预留 2048 个扇区,gdisk 却是从 64 扇区开始分。 。
一个例子看一下512k对其的效果:
~$ sudo sfdisk -d /dev/sda
Warning: extended partition does not start at a cylinder boundary.
DOS and Linux will interpret the contents differently.
# partition table of /dev/sda
unit: sectors
/dev/sda1 : start= 2048, size= 497664, Id=83, bootable
/dev/sda2 : start= 501758, size=155799554, Id= 5
/dev/sda3 : start= 0, size= 0, Id= 0
/dev/sda4 : start= 0, size= 0, Id= 0
/dev/sda5 : start= 501760, size=155799552, Id=83每一个分区的开始和结束都是可以整除512的。
减少SWAP读写频率
完全不使用SWAP将会导致hibernation(休眠)机制失效,所以最好的方案就是将swappiness 值修改为最小,最小化SWAP分区的操作。这样Linux会优先使用RAM,然后才是SSD。
$ sudo vim /etc/sysctl.d/99-sysctl.conf
vm.swappiness = 1
vm.vfs_cache_pressure = 50
vm.swappiness=0太激进,有可能会导致内存不够用。
重启后生效
更换低延迟 IO-Scheduler
默认的IO调度器CFQ(Copletely Fair Queuing)是针对HDD的优化,对多个读操作进行分组队列。但是SSD的读取效率非常高,完全不必要分组排队,使用一个队列就可以了。建议更换为:
- NOOP(当系统只有SSD的情况下非常建议)
- Deadline模式
配置文件/etc/default/grub
将
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash video-1024x768M@75m"
修改为:
GRUB_CMDLINE_LINUX_DEFAULT="elevator=noop quiet splash video-1024x768M@75m"
更新grub配置:grub-mkconfig -o /boot/grub/grub.cfg
插播小技巧
如果grub需要改变分辨率,修改/etc/default/grub
GRUB_GFXMODE=1024x768
定期检查SSD状态,并做数据备份
可以使用命令sudo smartctl -data -A /dev/sda查看SSD状态,观察寿命。
maurits@nuc:~$ sudo smartctl -data -A /dev/sda
smartctl 5.41 2011-06-09 r3365 [x86_64-linux-3.8.0-26-generic] (local build)
Copyright (C) 2002-11 by Bruce Allen, http://smartmontools.sourceforge.net
=== START OF READ SMART DATA SECTION ===
SMART Attributes Data Structure revision number: 18
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x0000 006 000 000 Old_age Offline - 6
3 Spin_Up_Time 0x0000 100 100 000 Old_age Offline - 0
4 Start_Stop_Count 0x0000 100 100 000 Old_age Offline - 0
5 Reallocated_Sector_Ct 0x0000 100 100 000 Old_age Offline - 0
9 Power_On_Hours 0x0000 100 100 000 Old_age Offline - 2592
12 Power_Cycle_Count 0x0000 100 100 000 Old_age Offline - 258
232 Available_Reservd_Space 0x0000 100 100 000 Old_age Offline - 4914564640
233 Media_Wearout_Indicator 0x0000 100 000 000 Old_age Offline - 100
maurits@nuc:~$233一行的值就是寿命,默认为100,当小于10的时候就要非常注意了。
更加深入的优化
Solid State Drive (SSD): optimize it for Ubuntu 14.04, Linux Mint 17.1 and Debian
参考链接
- Archlinux Wiki SSD
- How To Optimize Linux For SSDs
- 5 crucial optimizations for SSD usage in Ubuntu Linux
- Solid State Drive (SSD): optimize it for Ubuntu 14.04, Linux Mint 17.1 and Debian
- Debian Wiki's SSDOptimization
- How to properly activate TRIM for your SSD on Linux: fstrim, lvm and dm-crypt
- Linux系统中对SSD硬盘优化的方法
http://www.programgo.com/tag/linux/458825365/;jsessionid=DC017F2DAFBA6900D3D183A9ECF4D1AA
Linux下的trim支持叫discard,现在ext4和xfs都支持(btrfs应该也支持),内核需要>=2.6.37,xfs的支持在3.0才比较完善。具体需要设置这几个方面:
1. 内核
升级到2.6.37以上,最好用最新的3.0。
禁用disk IO scheduler模块。
2. 文件系统表
修改fstab文件,在挂载参数中加上discard;最好也同时加上noatime。
3. 调整文件系统参数
ext4的话最好禁用日志功能,能防止写入额外的数据而减少ssd寿命。
4. 相关文档:
xfs官网对ssd支持的说明
ext4的ssd设置
suse官方对ssd支持的相关说明
fdisk -H 224 -S 56 /dev/sdd
fdisk -H 32 -S 32 /dev/sdd
配置固态硬盘(SSD)的Ext 4
接着需要关注的就是文件系统。想要优化文件系统删除字节区块的效率,就必须确保小于512K的文件分布在不同的删除字节区块上。要做到这一点,必须 确保在创建可扩展文件系统时指定了需要使用的条带的宽度和幅度。这些值在页面中指定,默认大小为4KB。要创建一个最佳的可扩展文件系统,应该使用如下命 令:
mkfs.ext4 -E stride=128,stripe-width=128 /dev/sda1
如果要修改现有的文件系统的参数,可以使用tune2fs实用程序:
tune2fs -E stride=128,stripe-width=128 /dev/sda1
配置固态硬盘(SSD)的I/O调度程序
优化的第三个部分涉及到I/O调度程序。该模块是一个决定如何处理I/O请求的核心组件。默认情况下就是非常公平的排队,对于普通的磁盘驱动器来说,这是很好的方案,但对于以期限调度为优势的固态硬盘来说,这并不是最好的。
如果你想在系统中对所有磁盘采用期限调度,可以在内核加 载时把elevator=deadline这句话加入到系统引导管理器(GURB)中;如果你只是想针对某一个磁盘,就应该在rc.local文件中加入 类似如下实例的一句话,那么每次当系统重启,期限调度就会应用到指定的磁盘。如下实例将会对/dev/sdb磁盘采用期限调度。
echo deadline > /sys/block/sda/queue/scheduler
清理固态硬盘(SSD)中的数据块
最后一个重要的步骤称为“清理”,该操作可以确保在删除文件后相应的数据块真正清空,然后在创建新的文件时才能有可用的数据块。如果没有清理操作, 一旦数据块空间填满,固态硬盘的性能就会下降。如果使用丢弃挂载选项,当文件删除后,数据块也会被相应地清除,这样可以显著提高固态硬盘的性能。 2.6.33以上的内核已经支持清理操作。
要启用清理功能,需要在固态硬盘的/etc/fstab配置中为挂载文件系统添加丢弃选项。示例中的命令为挂载的根逻辑卷启用了清理操作。
/dev/system/root/ext4 discard,errors=remount-ro,noatime 0 1
该命令同时也添加了Noatime选项,该选项保证了文件的访问时间不会因为每次读取而更新,从而降低对文件系统的写入次数。
在fasab配置文件中完成对文件系统的这些修改后,重启计算机,或者通知文件系统重新读取其配置,然后使用/etc/fstab文件中包含的mount -o命令重新安装每个文件系统。
http://tieba.baidu.com/p/2244307121
关于对新装Linux的固态硬盘(SSD)做优化配置
原文来自http://forum.suse.org.cn/viewtopic.php?f=2&t=100![]() 由 比利海灵顿 » 周日 3月 31日, 2013年 9:39 pm初来乍到,写一篇小文交流一下日常应用心得,如有错漏疏忽之处,敬请指正!
由 比利海灵顿 » 周日 3月 31日, 2013年 9:39 pm初来乍到,写一篇小文交流一下日常应用心得,如有错漏疏忽之处,敬请指正!
去年可以说是SSD的普及年,目前128GB的SSD价格已经降到600到800的价位,进入了不少喜欢尝鲜的用户的接受范围之内,想当年我买的第一个SSD镁光M4,最便宜的64GB版本的时候就得七八百,而现在64GB的产品基本淘汰。新年过后,我也趁X东促销给新买的笔记本入了一个三星840。
关于Linux下如何对SSD做优化配置,网上众说纷纭,很多人都拿不定主意,或者某些配置很麻烦但收效甚微,对初心者来说,确实一头雾水。
我也不妨献丑说一下我平时的做法,希望能帮到大家:
1、安装系统前,确定BIOS中SATA工作在AHCI模式下,而非IDE模式,进BIOS的方法一般开机时都有提示。以AMI的BIOS为例,在chipset -> sourth bridge -> sb SATA configuration里可以找到配置项,至于其他的BIOS我就不一一举例,通常在BIOS界面都有提示,再不济逐个找也花不了多少时间。
2、4K对齐
网上很多人说Linux分区不需要4K对齐,其实这是一个误区!百度Linux吧曾经有一篇横测对比的文章,除了btrfs文件系统之外,对其余文件系统的影响还是很大的,当然,我不是说btrfs文件系统就比其他文件系统强,我本人用的是ext4,孰优孰劣可以谷歌一下各种文件系统的性能对比。在这方面Linux各大发行版基本上已经帮你考虑了这个问题,就算是arch和gentoo安装时用到的fdisk,在创建分区时也默认首扇区对齐,所以基本上不需要太担心这个问题。如果实在不放心可以使用sudo /sbin/fdisk -l /dev/sda(假设ssd是sda)命令,看看各分区首扇区是否能被8整除,如果可以就是对齐了!(至于为什么能被8整除就算对齐呢?有兴趣的朋友可以谷歌一下“4K对齐”的含义)
3、修改/etc/fstab。
在网上基本上每一篇教程都会推荐加discard和noatime参数,但很少人知道加上后具体有什么用。
discard参数就是每删除一次文件就执行一次trim指令,至于什么是trim,估计购买过ssd的同学都不陌生,简单来说就是告诉SSD哪些数据块已经不再使用,以便SSD回收,利于损耗平衡。但这个过程不可能不耗费资源,每删除一次文件就执行一次trim肯定会损失性能,所以我认为只要定时trim足矣(配合crontab定时执行trim),没必要加上discard参数。
noatime就是在读文件时不修改文件的atime属性,也就是不需要记录时间等信息,节约资源,可以加上noatime参数!
4、fstrim
fstrim命令即向ssd发送trim指令,如:sudo /sbin/fstrim -v /,一般只需要加[-v] mountpoint参数就可以。当然,不可能每执行一次就要手动输入,使用contab可以自动定时执行。我的方法是将fstrim命令写入bash脚本,主要是方便多个SSD或者多个挂载点的使用,如果想知道命令是否正常执行可以在命令后加上“ >> filename”写入某个文件。如图。
ps:contab的使用方法也很简单,具体来说就是可以控制在指定时间执行某条命令。请注意,fstrm需要root权限才能执行,设置contab时要使用root身份,以确定定时执行命令的权限为root。
输入contab -e命令后会打开vim窗口,直接按照 “ * * * * * 想要执行的命令” 的格式配置即可,前面的五个星号代表“分 时 日 月 星期的某天”,假如我要每天上午7时执行一次命令,我可以设置为“ * 7 * * * 想要执行的命令”。(contrim还有很多用法,如果想了解可以谷歌相关资料)
图3:执行fstrim指令
图5:contab的配置
图6:log文件
关于SSD优化配置具体内容暂时说到这里,最后想强调一个观点,永远不比为了节省SSD寿命而减少写入,这是本末倒置的行为。就算是颇受非议的三星840使用的27nm tlc芯片,在理论寿命上依然可以达到750次左右,虽然跟slc比起来确实有点短,但对于大多数人来说足够用上好几年!
http://www.trueeyu.com/?p=1655
linux优化使用SSD的方法
Linux 绝对可以说是一个即装即用的操作系统,但针对不同的使用场景还是需要进行不同的手动调节和细节优化,使用SSD 固态磁盘降低功耗和提升磁盘性能可以说是对 Linux 比较基础的一项优化了,为了让你的固态磁盘运行在最佳性能并降到最低损耗,我们大约需要从如下几个方面对 Linux 系统进行优化操作。
升级Linux系统版本
虽然这对大多数 Linux 用户来说不是什么大的问题,但还是值得对大家提一下。为了使用操作系统的最新功能、内核、文件系统等,最好是将操作系统升级到最新版本。虽然老的操作系统如 Ubuntu 12.04 仍然在支持期,但最好还是升级到最新的如 Ubuntu 14.04 版本,以使操作系统对 SSD 支持更加友好。
升级SSD固件
更重要的一项优化和提升 SSD 运行性能和修复缺陷的操作就是定期查看厂商是否发布了最新的 SSD 固件更新。大多数SSD 厂商都会在产品发布一段提供了放出最新的固件以修复 Bug 和存在的问题,具体步骤按官方给出的操作手册进行即可
使用ext4文件系统
在安装 Linux 时,最好选择 EXT4 文件系统,EXT4 是目前支持 TRIM 最常用也是最稳定可靠的可用文件系统。
其实该步也不是大的总是,大多数 Linux 发行版默认都已经使用 EXT4 了。
启用时的Mount选项
Linux 系统每次启动时,都是需要加载计算机中的各种驱动器才能够正常进行驱动和使用,其中有不少加载选项是针对SSD 固态磁盘的,当然是否开启某些选项要取决于不同的使用环境。
Linux 老手都知道,我们可以更改 /etc/fstab 来调整系统启动时对磁盘的挂载选项,在该文件中同样会列出 Linux 中的 SSD 固态磁盘分区 UUID。

我们可以为 SSD 磁盘分区添加 discard 和 noatime挂载选项,discard 挂载选项会开启 SSD 磁盘的 TRIM 功能以提升磁盘性能和使用寿命,noatime 挂载选项会告诉 Linux 文件系统不保存上次访问的时间轨迹,只存储最后一次更改时间,这可以减少 Linux 对 SSD 磁盘的读写操作以减少损耗。
注意:如果你发现添加 noatime 挂载选项后某些应用系统出现不兼容,可以将其更改为 relatime。该选项可以将上次访问时间的值作为最后修改时间。
禁用Linux的SWAP交换分区
使用固态磁盘就没太大必要使用 SWAP 交换分区了,如果你的了解 SWAP 分区可以查看前文Linux中的SWAP交换分区。

对 SWAP 交换分区的频繁读写必然会损耗 SSD 使用寿命,如果你需要使用 SWAP 分区最好还是将其放到非固态磁盘分区上。
小结
使用以上这些小技巧和优化操作可以让 Linux 更好的适应和优化对 SSD 磁盘的应用体验,如果你在操作过程中有问题可以直接留言进行探讨。
http://www.oenhan.com/linux-ssd-optimization
笔记本换了X230也有一段时间了,SSD也在迁移默化中使用,本来也没感到SSD的优势,直到昨日听到室友老爷机的咔咔风扇声音。SSD速度是极好的,就是损坏的太快,尤其是服务器,每次从我手中转出的硬件问题就让硬件部门头痛的,个人的硬件个人珍惜,还是把之前自己用的配置方法(针对PC)总结一下,以便重装系统时再看吧。 SSD损坏的原因是一个点写的次数过多了,优化的方式就是减少总的写入量。
1.更改BLOS中磁盘读写设置为AHCI,改为顺序写,提高读写效率
2.将SSD分一个区,如果是多个区就要注意文件系统的块开头和SSD的块开通对齐,否则就会文件系统的一个块写转换成硬件就是两个块写,是为骑马。
3.更改系统挂载文件/etc/fstab 首先搞清楚SSD挂在了哪里?一般情况下是sdb
|
1
2
|
$ df -Th 文件系统 类型 容量 已用 可用 已用% 挂载点/dev/sdb1 ext4 59G 8.0G 48G 15% / |
在fstab中添加“noatime,nodiratime,discard”参数
|
1
|
UUID=123456-123-123-123-123456 / ext4 noatime,nodiratime,discard</span>,errors=remount-ro 0 1 |
如果你内存充裕,在末尾加上如下3句话:
|
1
2
3
|
tmpfs /tmp tmpfs defaults,noatime,nodiratime,mode=1777 0 0tmpfs /var/log tmpfs defaults,noatime,mode=1777 0 0tmpfs /var/tmp tmpfs defaults,noatime,mode=1777 0 0 |
4.用之前安装的系统盘进入到试用模式下,执行如下命令清除掉EXT4的journal
|
1
|
sudo tune2fs -O ^has_journal /dev/sdb1 |
5./etc/rc.local可以在里面加一些启动命令 更改内核的磁盘调度算法,SSD不需要,就要noop最简单,
|
1
2
|
echo noop > /sys/block/sdb/queue/schedulerecho 1 > /sys/block/sdb/queue/iosched/fifo_batch |
更改内存脏页写回SSD的时机,整体配置是减少写入量,台式机一旦掉电会丢失相关工作,需谨慎
|
1
2
3
4
|
echo 50 > /proc/sys/vm/dirty_ratioecho 10 > /proc/sys/vm/dirty_background_ratioecho 6000 > /proc/sys/vm/dirty_expire_centisecsecho 30000 > /proc/sys/vm/dirty_writeback_centisecs |
6.把一些经常写的目录挂到内存中去
|
1
2
|
ln -sf /run/lock /var/lockln -sf /tmp/.viminfo . |
主要是浏览器 Firefox
* 打开Firefox,输入about:config * 单击右键新建String类型 * 添加 browser.cache.disk.parent_directory 将值设为 /tmp * 重启Firefox
Chrome
|
1
|
cd ~/.cache/google-chrome/Default/ && rm -rf Cache && ln -sf /tmp Cache |
7.关于journal和noatime对SSD的影响,请参考TedTs’o大神的文章
SSD’s, Journaling, and noatime/relatime
8.补充更新:通常安装硬盘和ssd之后,应尽量将ssd分一个分区,双系统分给自己最常用的系统,如果分给linux,就需要将grub安装到ssd设备上,才能保证成功引导.
http://www.linuxidc.com/Linux/2015-03/114278.htm
摘要:固态硬盘-SSDs -是一个便利的产品,但不是一个好的架构。存储系统需要重新架构,以达到闪存, 和即将推出的字节寻址的非易失性存储的最高性能。这里的一个例子。
固态硬盘的发展是因为有数以亿计的SATA和SAS磁盘端口的存在。将其中的一些端口连接SSDs硬盘,肯定是有利可图的,这已经在过去的5年中变成现实。
但现在,今天的非易失性存储器技术-闪存,加之明天的RRAM技术已被广泛接受,是时候来建立直接采用闪存而不是通过我们的老旧的存储栈技术了。各种为减少延时的努力- SATA 3,NVMe,和其他,仍然是在我们的应用和数据之间加入软件层,这既增加了复杂性又浪费了CPU周期。最近的博士论文让我思考这个问题。
间接性(Indirection)
当出现一些需要太多层来解决的问题时,在计算机科学界就出现了著名的一句名言:“所有的问题都可以通过迂回的方式用计算机解决,除了那些需要间接迂回太多层的问题。”
我们要说的SSD就是这一点问题。SSD所依赖于的闪存转换层(FTL)使得闪存-及其写入速度之慢与寿命之有限的特点-看起来就是块磁盘驱动器。这个FTL就是前面所说的迂回层。
FTL已过时
文件系统已经提供了这么一个迂回层使得我们的存储设备看上去就是一个连续的逻辑可寻址存储空间。这些系统通过维护类似用于跟踪设备块分配位图信息这样的元数据来管理逻辑地址。
但是,FTL同样维护了一个连续逻辑寻址空间,在这背后隐藏着像耗损平衡和垃圾回收等活动。那么就有一个很明显的问题了:为什么要维护着两个逻辑地址空间?为什么不让文件系统来直接管理闪存呢?
如果我们摆脱了FTL的束缚,那么SSD将变得更快、更低功耗、以及更可靠。何乐而不为呢?
存储位(该如何)获取
SSD在架构而不是功能层面是过时的。其具有许多传统硬盘所不具有的优越性,这也使得未来将会持续有着数以百万计的销量,但是这背后却是为了填补那些SATA端口的原因所引起的,这就与今天的系统背道而驰了。
不久之后,我们需要结合闪存和字节寻址的NVM存储,只有这样才不至于让他们还是一块”类磁盘“。这一步需要不小的努力,但是面对今天处理器性能增长的缓慢,我们完全有必要在其它方面寻求系统性能提升点。当前存储堆栈已使得颠覆性改进的时机变得成熟。
http://forum.ubuntu.org.cn/viewtopic.php?f=126&t=396075
硬件改造
固态硬盘(64G,2.5寸,SATA3.0)装入原先的硬盘位置,购买一个光驱位硬盘托架,将机械硬盘(500G)装入原先的光驱位置。这几种材料都已经很常见,笔记本外观不会有什么瑕疵。
系统安装
1.下载ubuntu光盘镜像
http://www.ubuntu.com/download。
2.利用u盘安装
此时,计算机已经没有光驱可用,利用UltraISO的“写入硬盘镜像”将ISO文件写入u盘中。
3.安装
大部分过程与普通安装方法一致,/挂载点分配20G,/home挂载点分配其他SSD容量,再新创建一个/store挂载点分配所有的机械硬盘容量。所有的分区格式都选ext4。
[size=150]优化设置[/size]
这部分重点介绍。
1.使用Ext4 without journaling文件系统
传统的SSD+Linux组合一般推荐Ext2文件系统,主要是考虑到Ext3、Ext4需要额外的记录日志,会缩短SSD使用寿命,而且新出现的TRIM技术在Ext2中有两个缺点:
仅支持离线TRIM,换句话说文件系统必须只读挂载;
需要手动执行hdparm命令或wiper.sh脚本。
Ext4则没有这些限制,允许TRIM后台运行,并且日志记录功能可以手动关闭(没有日志的情况下,文件系统更容易损坏,如突然断电),如果你甘愿冒这样的风险,从而延长SSD使用寿命,值得一试。另外,许多测试中如:Testing EXT4 & Btrfs On A Serial ATA 3.0 SSD,像Btrfs这样为SSD准备的文件系统不如Ext4速度快(用SSD不就为了快么)。
所以,上面安装系统时,选择了Ext4系统,接下来需要关闭日志功能。
首先,系统挂载时无法停用日志功能,所以需要进入刚才的U盘系统,利用root权限执行:
即关闭/dev/sda1上的日志功能。
然后,运行操作系统检测:
不这样,文件系统可能会出错。
最后,重启,进入SSD中的系统,检查是否设置成功:
如果出现:
说明设置成功。
原来是:mounted filesystem with ordered data mode
如果需要再次开启日志功能,只要运行tune2fs -O has_journal /dev/sda1即可。
2.开启TRIM功能
TRIM是一种操作系统调度SSD块写入的方式。主要是因为同一个SSD的闪存单元频繁操作会磨损,影响使用寿命,区别于传统的机械硬盘处理删除数据。Linux内核自2.6.33开始支持TRIM。
首先,检查内核版本是否支持TRIM:
然后,检查SSD硬盘是否支持TRIM:
如果显示比如(不同硬件可能不同提示):
说明支持。
这两个条件都满足,在/etc/fstab中将:
/dev/sda1 / ext4 defaults 改为:
/dev/sda1 / ext4 discard,defaults 分区、挂载点、已经存在的选项不一定一样。
测试新的fstab文件:
然后挂载:
如果显示discard字样,说明成功,如:
3.swap空间处理
对于大内存来说swap基本上都是空闲的,除非电脑进入休眠状态,系统会将内存内容转到swap中。有了SSD,开关机都在几秒中,对我来说swap没用,所以上面直接不分配swap空间。
如果分配了也行,空间要小,而且通过设置/proc/sys/vm/swappiness里面的值,来减少swap换出量:
0到100之间,值越大换出量越大。
4.设置noatime
当访问文件时,系统会更新last-access这个文件/目录元数据,设置noatime后可以减少这种操作。
将2步中的:
/dev/sda1 / ext4 discard,defaults 改为:
/dev/sda1 / ext4 noatime,discard,defaults 测试设置成功方法与上面一样。
5.使用noop磁盘调度
通常操作系统调度机械硬盘时会提供一些数据的物理位置,这样有利于机械硬盘优化寻道,但是对SSD没意义,所以采用noop磁盘调度,即简单发送请求,可以提高效率。
可以通过以下命令查看调度方法:
比如显示:
在/etc/rc.local中添加如下语句:
6.内存分区加速
如果内存够大,可以用ramdisk的方式,将一些经常变化的位置如/tmp放入内存,加快速度,减少对SSD的访问。
依然是加在/etc/fstab中:
更新方法与2相同,记得将浏览器等程序的缓存目录设置到/tmp下。
Ubuntu SSD 现在开机时间10秒左右。
转载自 http://plumgo.cc/blog/2012/01/05/ssd-op ... untu-note/
.............

 浙公网安备 33010602011771号
浙公网安备 33010602011771号{kind=link}