mysqld_multi;mysql多实例;mysql中间件;mysql云架构
http://club.alibabatech.org/article_detail.htm?articleId=23
http://blog.yufeng.info/archives/2349
Home > Erlang探索, 杂七杂八, 源码分析 > 低成本和高性能MySQL云数据的架构探索
低成本和高性能MySQL云数据的架构探索
原创文章,转载请注明: 转载自系统技术非业余研究
本文链接地址: 低成本和高性能MySQL云数据的架构探索
原文地址:http://www.alibabatech.org/article/detail/3405/0?ticket=d69f07f8-b60b-43f8-9572-7d795bb8429d
作者:鸣嵩
PPT这里下载:
该文已在《程序员》2012年10期上发表。
MySQL作为一个低成本、高性能、可靠性好而且开源的数据库产品,在互联网企业应用非常广泛,例如淘宝网有数千台MySQL服务器的规模。虽然近两年来NoSQL的发展很快,新产品层出不穷,但在业务中应用NoSQL对开发者来说要求比较高,而MySQL拥有成熟的中间件、运维工具,已经形成一个良性的生态圈等,因此从现阶段来看,MySQL占主导性,NoSQL为辅。
在过去一年时间里,我们(阿里集团核心系统数据库团队)在MySQL托管平台方向做了大量工作,设计和实现了一套UMP(Unified MySQL Platform)系统,提供低成本和高性能的MySQL云数据服务。开发者从平台上申请MySQL实例资源,通过平台提供的单一入口来访问数据,UMP系统内部维护和管理资源池,以对用户透明的形式提供主从热备、数据备份、迁移、容灾、读写分离、分库分表等一系列服务。平台通过在一台物理机上运行多个MySQL实例的方式来降低成本,并且实现了资源隔离,按需分配和限制CPU、内存和IO资源,同时支持不影响提供数据服务的前提下根据用户业务的发展动态的扩容和缩容。
架构的演变
UMP系统第一版基于mysql-proxy 0.8版修复若干bug,并对proxy插件中管理用户连接和数据库连接的状态机流程进行一些修改,同时编写Lua脚本实现去中心数据库获取用户认证信息和后台数据库地址,对用户进行验证,建立到后台数据库的连接和转发数据包等逻辑。
图1 UMP系统的第一版采用MySQL Proxy
在开发和部署第一版的过程中,我们逐渐认识到几个问题:
首先,mysql-proxy 0.8版对多线程的支持比较简单粗暴,多个工作线程共享同一个消息队列,同时监听着同一个socketpair通道,当有新事件进入消息队列后,socketpair会被写入一个字节,所有休眠中的线程都会被唤醒,去竞争一个互斥锁从消息队列中取任务。这种实现一是造成“惊群”现象,多个线程被唤醒但只有一个线程需要去任务,二是任务的CPU亲缘性比较差,在同一个状态机上触发的事件会在多个处理器上来回切换执行。此外,mysql-proxy中还使用了全局Lua锁,同时仅允许一个工作线程执行Lua脚本(计划在0.9版本中改进),因此mysql-proxy多线程模式下的性能远不能同CPU核数保持线性增长,甚至在16核上的性能还不如4核。而使用单进程模式时,一台物理机上需要部署多个进程才能有效利用机器的处理能力,但给部署、监控和服务的升级带来麻烦。
其次,限于mysql-proxy的框架,功能上不容易扩展,实现用户的连接数限制、QPS限制、以及主从切换、读写分离、分库分表等一系列功能比较困难。
最后,mysql-proxy的社区近些年来并不活跃,而且C语言对开发者功底的要求比较高,很难要求团队所有成员协同开发出兼顾优雅和正确性的代码。
因此我们决定用Erlang语言重新编写proxy服务器,替换了原有的mysql-proxy模块。目前整个项目拥有5万行Erlang源码,3万行C/C++源码,2万行其他语言源码。
为什么选择Erlang语言
Erlang是一个结构化的、动态的、函数式的编程语言。常见的一个说法是Erlang是面向并发的(concurrent-oriented),这主要指Erlang在语言中定义了Erlang进程的概念和行为(下文中凡是“Erlang进程”都是指Erlang语言中定义的进程,以区分于大家熟悉的操作系统进程),和操作系统的进程/线程相比,Erlang进程同样是并发执行的单位,但特别的轻量级,它是在Erlang虚拟机内管理和调度的“绿进程”,即用户态进程。举个例子,在关闭了HiPE和SMP支持的Erlang虚拟机中,一个新创建的进程占用的内存仅为309个字(word,64位服务器上为8个字节),其中233个字为堆空间(包含栈),创建和结束一个进程的代价约耗时1~3微秒,而一个Erlang虚拟机中可以同时支持几十万甚至更多个进程。
图2 Erlang的轻量级进程
说到Erlang语言,就必须提及OTP(Open Telecom Platform,开放电信平台),OTP是用于开发分布式的、高容错性的Erlang应用程序的框架与平台。例如,一个Erlang节点连接并注册到Erlang集群上,发现集群中的其他节点,与它们进行RPC通信,都在OTP里的kernel服务中实现的。OTP和Erlang语言关系如此紧密以至于两者通常合称为Erlang/OTP,因此从严格的意义上来讲,应该说我们选择了Erlang/OTP为主来构造UMP系统。Erlang/OTP很好的抽象了开发一个分布式的、高容错性的应用程序所需的要素,包括:网络编程框架、序列化和反序列化、容错、热部署。
为了支持并发,服务器端多采用多进程/多线程模型,即每个进程/线程处理一个客户端连接,受限于操作系统资源,每台服务器可以处理的并发连接数并不高,同时由于进程/线程上下文切换开销,系统的性能会受到影响。而开发高并发、高性能的服务器一般采用事件驱动的状态机模型,底层采用非阻塞I/O(Linux中的epoll,BSD系统中的kqueue,Java中的nio)或者异步I/O,或者采用异步的事件通知的I/O框架,例如C/C++下的ACE、boost::asio、libevent,Java下的MINA等,在业务层则使用状态机来表示每个客户端连接,通过I/O事件、超时事件驱动着状态机进行跳转,每个进程/线程可以处理成千上万个客户端连接。事件驱动的状态机模型和多进程/多线程模型相比虽然并发量更大、性能更好,但是把业务逻辑表达成状态机是一件困难的事情,相比而下,多进程/多线程模型中业务逻辑可以实现为顺序执行的代码,开发起来要简单的多。
Erlang/OTP中的网络编程模型则结合了两者的优点,每个Erlang进程处理一个客户端连接,业务逻辑是顺序执行的。而Erlang进程是极轻量级的,可以认为每个Erlang进程是一个状态机,堆和栈上的数据是这个状态机的状态,而Erlang进程收到数据包或是其他进程发来消息后执行处理例程相当于状态机的跳转,因此也具有高并发和高性能的优势。
Erlang/OTP定义了“external term format”协议将Erlang数据结构与二进制串相互转化,用C实现在Erlang虚拟机中,跨节点通讯时遵从这个协议。因此,开发者无需额外考虑序列化和反序列化的问题。
至于容错,Erlang进程的数据空间是相互隔离的,没有共享内存,因此一个Erlang进程崩溃不会影响其他Erlang进程的运行,更不会造成Erlang虚拟机崩溃。OTP还提供了监督树机制和heart模块,前者在监控到Erlang进程崩溃时进行故障恢复,后者发现Erlang虚拟机失去响应时重启程序。
Erlang/OTP提供热部署方式,可以避免服务升级时造成不可用时间。此外,OTP还提供了一些在系统运行时观察系统状态的工具,例如lcnt工具,可以统计虚拟机内部的锁使用次数和冲突次数,指导系统的优化。
当前系统架构
在设计UMP系统时,我们遵循了以下几条原则:
l 系统对外保持单一入口,对内维护单一的资源池。
l 保证服务的高可用性,消除单点故障。
l 保证系统是弹性可伸缩的,可以动态的增加、删减计算与存储节点。
l 保证分配给用户的资源也是弹性可伸缩的,资源之间相互隔离。
UMP系统中的角色包括:controller服务器、proxy服务器、agent服务器、API/Web服务器、日志分析服务器、信息统计服务器。
依赖的开源组件有:Mnesia、LVS、RabbitMQ、ZooKeeper
图3当前UMP系统架构图
Mnesia是OTP提供的分布式数据库,与MySQL NDB出自同门,都是上世纪90年代中期Ericsson为电信业务研发的数据产品。Mnesia支持事务,支持透明的数据分片,利用两阶段锁实现分布式事务,可以线性扩展到至少50个节点。从CAP理论的角度上来说,Mnesia更倾向于牺牲可用性来换取强一致性,属于CP阵营,但它也提供了脏读、脏写操作,可以绕过事务管理去操作数据,这时不保证一致性,这又类似于AP的系统。在工程实践中,我们用事务去修改关键数据例如路由表,而用脏写接口去写非关键数据例如用户的状态信息,读取数据用脏读接口。
Controller服务器向UMP集群提供各种管理服务,实现元数据存储、集群成员管理、MySQL实例管理、故障恢复、备份、迁移、扩容等功能。Controller服务器上运行了一组mnesia分布式数据库服务,系统的元数据比如集群成员,用户的配置和状态信息,以及用户名到后端MySQL实例地址的映射关系(路由表)等都存储在mnesia里,其它服务器组件通过发送请求到controller服务器获取用户数据。为了达到高可用性,系统中会部署多台controller服务器,它们会通过ZooKeeper提供的分布式锁算法选举出一个leader,这个leader负责调度和监控各种系统任务,例如创建和删除数据库实例、备份、迁移等。这些系统任务可以分成多个步骤,而且会涉及到系统中的多个组件,例如主库、从库、proxy服务器等,还需要提供失败时回滚的方法,因此我们采用类似工作流的方式来实现。每个系统任务都是分成多个阶段的Erlang进程,每执行完一个步骤跳进入下个步骤之前会把中间状态持久化到mnesia中,如果任务因为节点故障的原因停止,leader会检测到并重新发起该任务,任务重启后会从上一次失败的“断点”继续向下执行。
API/Web服务器向用户提供了系统管理界面。它们是基于开源项目Mochiweb与Chicago Boss开发的,Mochiweb提供http/https服务,而Chicago Boss是由Nginx的作者之一Evan Miller开发,提供类似Rails的MVC框架。和Rails比,Erlang开发的框架天生就对并发有很好的支持,每个请求占用一个轻量级的Erlang进程,而Rails虽然在最近引入了多线程安全,但处理每条请求的时候仍然是独占整个进程的,因此需要使用多进程模型处理并发请求,通过Phusion Passenger等应用服务器进行派发。
Proxy服务器向用户提供访问MySQL数据库的服务,它完全实现了MySQL协议,用户可以使用已有的MySQL客户端连接到proxy服务器,proxy服务器通过用户名获取到用户的认证信息、资源配额的限制(例如最大连接数、QPS、IOPS等),以及后台MySQL实例的地址(列表),再将用户的SQL查询请求转发到正确的MySQL实例上。除了数据路由的基本功能外,Proxy服务器中还实现了资源限制、屏蔽MySQL实例故障、读写分离、分库分表、记录用户访问日志的功能。Proxy服务器是无状态的,服务器宕机不会对系统中其他服务器造成影响,只会造成连接到该proxy的用户连接断开。多台Proxy服务器采用LVS HA方案实现负载均衡,用户应用重连后会被LVS定向到其他的proxy上。
Agent服务器部署在运行MySQL进程的机器上,用来管理每台物理机上MySQL实例,执行创建、删除、备份、迁移、主从切换等操作,收集和分析MySQL进程的统计信息、bin log、slow query log。
日志分析服务器会存储和分析Proxy服务器传入的用户访问日志,并实现了实时索引供用户查询一段时间内的慢日志和统计报表。信息统计服务器定期将采集到的用户的连接数、QPS数值,以及MySQL实例的进程状态用RRDtool进行统计,可以画图展示到Web界面上,也可以为今后实现弹性的资源分配和自动化的MySQL实例迁移提供依据。
UMP系统中各节点间的通信(不包括SQL查询、日志等大数据流的传输,这些还是直接走TCP的)都通过RabbitMQ,作为消息通讯的中间件来使用,来保证消息发送的可靠性。ZooKeeper则主要发挥配置服务器、分布式锁,以及监控所有MySQL实例的作用。在多个组件的协同作业下,整个系统实现了对用户透明的容灾、读写分离、分库分表功能。系统内部还通过多个小规模用户共享同一个MySQL实例,中等规模用户独占一个MySQL实例,多个MySQL实例共享同一个物理机的方式实现资源的虚拟化,降低整体成本。在资源隔离方面,通过Cgroup限制MySQL进程资源,以及在proxy服务器端限制QPS相结合的方法,UMP系统实现了资源虚拟化的同时保障用户的服务质量。此外,UMP系统综合运用SSL数据库连接、数据访问IP白名单、记录用户操作日志、SQL拦截等技术保护用户的数据安全。
结束语
UMP系统的一些组件,例如proxy服务器和日志分析服务器,目前已经运用在天猫的聚石塔平台中,为电商和ISV提供安全的数据云服务。此外,UMP系统还运用在淘宝的店铺装修平台中,为开发者提供数据服务。下一阶段,我们希望UMP系统可以为进一步降低集团内部数据存储的成本做出贡献。
附上UMP portal部份截屏:
图4 MySQL实例情况
图5 用户实例管理
图6 dashboard
祝玩得开心!
Post Footer automatically generated by wp-posturl plugin for wordpress.
mysql中间件研究(Atlas,cobar,TDDL)
mysql-proxy是官方提供的mysql中间件产品可以实现负载平衡,读写分离,failover等,但其不支持大数据量的分库分表且性能较差。下面介绍几款能代替其的mysql开源中间件产品,Atlas,cobar,tddl,让我们看看它们各自有些什么优点和新特性吧。
Atlas
Atlas是由 Qihoo 360, Web平台部基础架构团队开发维护的一个基于MySQL协议的数据中间层项目。它是在mysql-proxy 0.8.2版本的基础上,对其进行了优化,增加了一些新的功能特性。360内部使用Atlas运行的mysql业务,每天承载的读写请求数达几十亿条。
Altas架构:
Atlas是一个位于应用程序与MySQL之间,它实现了MySQL的客户端与服务端协议,作为服务端与应用程序通讯,同时作为客户端与MySQL通讯。它对应用程序屏蔽了DB的细节,同时为了降低MySQL负担,它还维护了连接池。

以下是一个可以参考的整体架构,LVS前端做负载均衡,两个Altas做HA,防止单点故障。
Altas的一些新特性:
1.主库宕机不影响读
主库宕机,Atlas自动将宕机的主库摘除,写操作会失败,读操作不受影响。从库宕机,Atlas自动将宕机的从库摘除,对应用没有影响。在mysql官方的proxy中主库宕机,从库亦不可用。
2.通过管理接口,简化管理工作,DB的上下线对应用完全透明,同时可以手动上下线。
图1是手动添加一台从库的示例。
图1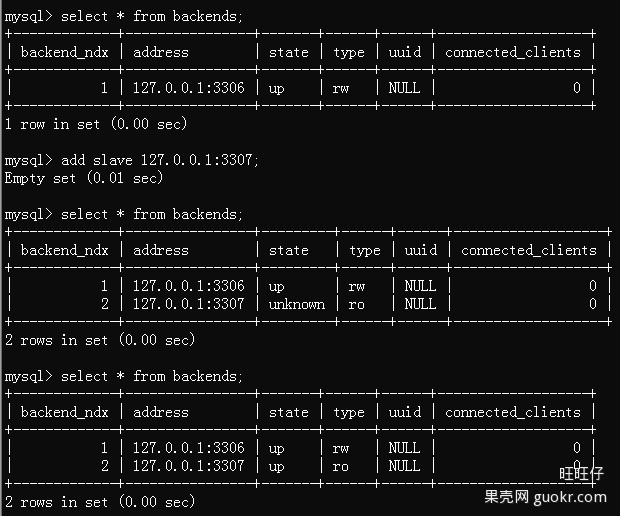
3.自己实现读写分离
(1)为了解决读写分离存在写完马上就想读而这时可能存在主从同步延迟的情况,Altas中可以在SQL语句前增加 /*master*/ 就可以将读请求强制发往主库。
(2)如图2中,主库可设置多项,用逗号分隔,从库可设置多项和权重,达到负载均衡。
图2
4.自己实现分表(图3)
(1)需带有分表字段。
(2)支持SELECT、INSERT、UPDATE、DELETE、REPLACE语句。
(3)支持多个子表查询结果的合并和排序。
图3 
这里不得不吐槽Atlas的分表功能,不能实现分布式分表,所有的子表必须在同一台DB的同一个database里且所有的子表必须事先建好,Atlas没有自动建表的功能。
5.之前官方主要功能逻辑由使用lua脚本编写,效率低,Atlas用C改写,QPS提高,latency降低。
6.安全方面的提升
(1)通过配置文件中的pwds参数进行连接Atlas的用户的权限控制。
(2)通过client-ips参数对有权限连接Atlas的ip进行过滤。
(3)日志中记录所有通过Altas处理的SQL语句,包括客户端IP、实际执行该语句的DB、执行成功与否、执行所耗费的时间 ,如下面例子(图4)。
图4
7.平滑重启
通过配置文件中设置lvs-ips参数实现平滑重启功能,否则重启Altas的瞬间那些SQL请求都会失败。该参数前面挂接的lvs的物理网卡的ip,注意不是虚ip。平滑重启的条件是至少有两台配置相同的Atlas且挂在lvs之后。
source:https://github.com/Qihoo360/Atlas
alibaba.cobar
Cobar是阿里巴巴(B2B)部门开发的一种关系型数据的分布式处理系统,它可以在分布式的环境下看上去像传统数据库一样为您提供海量数据服务。那么具体说说我们为什么要用它,或说cobar--能干什么?以下是我们业务运行中会存在的一些问题:
1.随着业务的进行数据库的数据量和访问量的剧增,需要对数据进行水平拆分来降低单库的压力,而且需要高效且相对透明的来屏蔽掉水平拆分的细节。
2.为提高访问的可用性,数据源需要备份。
3.数据源可用性的检测和failover。
4.前台的高并发造成后台数据库连接数过多,降低了性能,怎么解决。
针对以上问题就有了cobar施展自己的空间了,cobar中间件以proxy的形式位于前台应用和实际数据库之间,对前台的开放的接口是mysql通信协议。将前台SQL语句变更并按照数据分布规则转发到合适的后台数据分库,再合并返回结果,模拟单库下的数据库行为。 
Cobar应用举例
应用架构:
应用介绍:
1.通过Cobar提供一个名为test的数据库,其中包含t1,t2两张表。后台有3个MySQL实例(ip:port)为其提供服务,分别为:A,B,C。
2.期望t1表的数据放置在实例A中,t2表的数据水平拆成四份并在实例B和C中各自放两份。t2表的数据要具备HA功能,即B或者C实例其中一个出现故障,不影响使用且可提供完整的数据服务。
cabar优点总结:
1.数据和访问从集中式改变为分布:
(1)Cobar支持将一张表水平拆分成多份分别放入不同的库来实现表的水平拆分
(2)Cobar也支持将不同的表放入不同的库
(3) 多数情况下,用户会将以上两种方式混合使用
注意!:Cobar不支持将一张表,例如test表拆分成test_1,test_2, test_3.....放在同一个库中,必须将拆分后的表分别放入不同的库来实现分布式。
2.解决连接数过大的问题。
3.对业务代码侵入性少。
4.提供数据节点的failover,HA:
(1)Cobar的主备切换有两种触发方式,一种是用户手动触发,一种是Cobar的心跳语句检测到异常后自动触发。那么,当心跳检测到主机异常,切换到备机,如果主机恢复了,需要用户手动切回主机工作,Cobar不会在主机恢复时自动切换回主机,除非备机的心跳也返回异常。
(2)Cobar只检查MySQL主备异常,不关心主备之间的数据同步,因此用户需要在使用Cobar之前在MySQL主备上配置双向同步。
cobar缺点:
开源版本中数据库只支持mysql,并且不支持读写分离。
source:http://code.alibabatech.com/wiki/display/cobar/Home
TDDL
淘宝根据自己的业务特点开发了TDDL(Taobao Distributed Data Layer 外号:头都大了 ©_Ob)框架,主要解决了分库分表对应用的透明化以及异构数据库之间的数据复制,它是一个基于集中式配置的 jdbc datasource实现,具有主备,读写分离,动态数据库配置等功能。
TDDL所处的位置(tddl通用数据访问层,部署在客户端的jar包,用于将用户的SQL路由到指定的数据库中):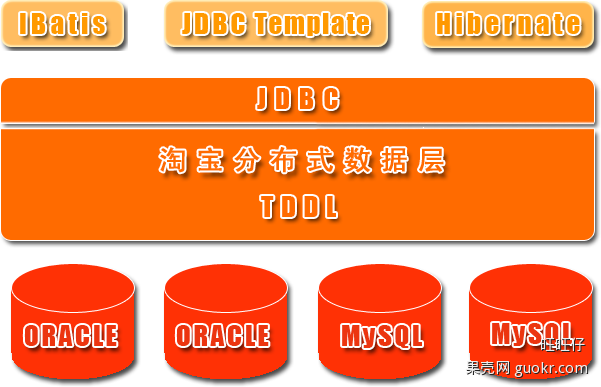
淘宝很早就对数据进行过分库的处理, 上层系统连接多个数据库,中间有一个叫做DBRoute的路由来对数据进行统一访问。DBRoute对数据进行多库的操作、数据的整合,让上层系统像操作一个数据库一样操作多个库。但是随着数据量的增长,对于库表的分法有了更高的要求,例如,你的商品数据到了百亿级别的时候,任何一个库都无法存放了,于是分成2个、4个、8个、16个、32个……直到1024个、2048个。好,分成这么多,数据能够存放了,那怎么查询它?这时候,数据查询的中间件就要能够承担这个重任了,它对上层来说,必须像查询一个数据库一样来查询数据,还要像查询一个数据库一样快(每条查询在几毫秒内完成),TDDL就承担了这样一个工作。在外面有些系统也用DAL(数据访问层) 这个概念来命名这个中间件。
下图展示了一个简单的分库分表数据查询策略:
主要优点:
1.数据库主备和动态切换
2.带权重的读写分离
3.单线程读重试
4.集中式数据源信息管理和动态变更
5.剥离的稳定jboss数据源
6.支持mysql和oracle数据库
7.基于jdbc规范,很容易扩展支持实现jdbc规范的数据源
8.无server,client-jar形式存在,应用直连数据库
9.读写次数,并发度流程控制,动态变更
10.可分析的日志打印,日志流控,动态变更
TDDL必须要依赖diamond配置中心(diamond是淘宝内部使用的一个管理持久配置的系统,目前淘宝内部绝大多数系统的配置,由diamond来进行统一管理,同时diamond也已开源)。
TDDL动态数据源使用示例说明:http://rdc.taobao.com/team/jm/archives/1645
diamond简介和快速使用:http://jm.taobao.org/tag/diamond%E4%B8%93%E9%A2%98/
TDDL源码:https://github.com/alibaba/tb_tddl
TDDL复杂度相对较高。当前公布的文档较少,只开源动态数据源,分表分库部分还未开源,还需要依赖diamond,不推荐使用。
终其所有,我们研究中间件的目的是使数据库实现性能的提高。具体使用哪种还要经过深入的研究,严谨的测试才可决定。
前言:
相对于传统行业的相对服务时间9x9x6或者9x12x5,因为互联网电子商务以及互联网游戏的实时性,所以服务要求7*24小时,业务架构不管是应用还是数据库,都需要容灾互备,在mysql的体系中,最好通过在最开始阶段的数据库架构阶段来实现容灾系统。所以这里从业务宏观角度阐述下mysql 架构的方方面面。
一,MySQL架构设计—业务分析
(1)读多写少
虚线表示跨机房部署,比如电子商务系统,一个Master既有读也有些写,对读数据一致性需要比较重要的,读要放在Master上面。
M(R)仅仅是一个备库,只有M(WR)挂了之后,才会切换到M(R)上,这个时候M(R)就变成了读写库。比如游戏系统,有很多Salve会挂载后面一个M(R)上面。
(2)读多写少MMS-电商
如果是电子商务类型的,这种读多写少的,一般是1个master拖上4到6个slave,所有slave挂载在一个master也足够了。
切换的时候,把M1的读写业务切换到M2上面,然后把所有M1上的slave挂到M2上面去,如下所示:

(3)读多写少MMSS-游戏
如果是游戏行业的话,读非常多蛮明显的,会出现一般1个Master都会挂上10个以上的Slave的情况,所以这个时候,可以把一部分Slave挂载新的M(R)上面。至少会减少一些压力,这样至少服务器挂掉的时候,不会对所有的slave有影响,还有一部分在M(R)上的slave在继续,不会对所有的slave受到影响,见图3,

图3
(4)读少写多
意味着读并不会影响写的效率,所以读写都可以放在一个M1(WR),而另外一个不提供读也不提供写,只提供standby冗余异地容灾。

这个异地容灾是非常重要的,否则如果是单机的,单边的业务,万一idc机房故障了,一般就会影响在线业务的,这种 造成业务2小时无法应用,对于在线电子商务交易来说,影响是蛮大的,所以为了最大限度的保证7*24小时,必须要做到异地容灾,MM要跨idc机房。虽然对资源有一些要求,但是对HA来说是不可缺少的,一定要有这个MM机制。
做切换的时候,把所有的读写从M1直接切换到M2上就可以了。

(5)读写平分秋色
读和写差不多,但是读不能影响写的能力,把读写放在M1(WR)上,然后把一部分读也放在M2(R)上面,当然M1和M2也是跨机房部署的。
切换的时候,把一部分读和全部写从M1切换到M2上就可以了。
二:MySQL架构设计—常见架构
(1)强一致性
对读一致性的权衡,如果是对读写实时性要求非常高的话,就将读写都放在M1上面,M2只是作为standby,就是采取和上面的一(4)的读少写多的一样的架构模式。
比如,订单处理流程,那么对读需要强一致性,实时写实时读,类似这种涉及交易的或者动态实时报表统计的都要采用这种架构模式

(2)弱一致性
如果是弱一致性的话,可以通过在M2上面分担一些读压力和流量,比如一些报表的读取以及静态配置数据的读取模块都可以放到M2上面。比如月统计报表,比如首页推荐商品业务实时性要求不是很高,完全可以采用这种弱一致性的设计架构模式。

(3)中间一致性
如果既不是很强的一致性又不是很弱的一致性,那么我们就采取中间的策略,就是在同机房再部署一个S1(R),作为备库,提供读取服务,减少M1(WR)的压力,而另外一个idc机房的M2只做standby容灾方式的用途。
当然这里会用到3台数据库服务器,也许会增加采购压力,但是我们可以提供更好的对外数据服务的能力和途径,实际中尽可能两者兼顾。

(4)统计业务
比如PV、UV操作、页数的统计、流量的统计、数据的汇总等等,都可以划归为统计类型的业务。
数据库上做大查询的统计是非常消耗资源的。统计分为实时的统计和非实时的统计,由于mysql主从是逻辑sql的模式,所以不能达到100%的实时,如果是online要严格的非常实时的统计比如像火车票以及金融异地结算等的统计,mysql这块不是它的强项,就只有查询M1主库来实现了。
A,但是对于不是严格的实时性的统计,mysql有个很好的机制是binlog,我们可以通过binlog进行解析Parser,解析出来写入统计表进行统计或者发消息给应用端程序来进行统计。这种是准实时的统计操作,有一定的短暂的可接受的统计延迟现象,如果要100%实时性统计只有查询M1主库了。
通过binlog的方式实现统计,在互联网行业,尤其是电商和游戏这块,差不多可以解决90%以上的统计业务。有时候如果用户或者客户提出要实时read-time了,大家可以沟通一下为什么需要实时,了解具体的业务场景,有些可能真的不需要实时统计,需要有所权衡,需要跟用户和客户多次有效沟通,做出比较适合业务的统计架构模型。
B,还有一种offline统计业务,比如月份报表年报表统计等,这种完全可以把数据放到数据仓库里面或者第三方Nosql里面进行统计。

(5)历史数据迁移
历史数据迁移,需要尽量不影响现在线上的业务,尽量不影响现在线上的查询写入操作,为什么要做历史数据迁移?因为有些业务的数据是有时效性的,比如电商中的已经完成的历史订单等,不会再有更新操作了,只有很简单的查询操作,而且查询也不会很频繁,甚至可能一天都不会查询一次。
如果这时候历史数据还在online库里面或者online表里面,那么就会影响online的性能,所以对于这种,可以把数据迁移到新的历史数据库上,这个历史数据库可以是mysql也可以是nosql,也可以是数据仓库甚至hbase大数据等。
实现途径是通过slave库查询出所有的数据,然后根据业务规则比如时间、某一个纬度等过滤筛选出数据,放入历史数据库(History Databases)里面。迁移完了,再回到主库M1上,删除掉这些历史数据。这样在业务层面,查询就要兼顾现在实时数据和历史数据,可以在filter上面根据迁移规则把online查询和history查询对接起来。比如说一个月之内的在online库查询一个月之前的在history库查询,可以把这个规则放在DB的迁移filter层和应用查询业务模块层。如果可以的话,还可以配置更细化,通过应用查询业务模块层来影响DB的迁移filter层,比如以前查询分为一个月为基准,现在查询业务变化了,以15天为基准,那么应用查询业务模块层变化会自动让DB的filter层也变化,实现半个自动化,更加智能一些。

(6)MySQL Sharding
像oracle这种基于rac基于共享存储的方式,不需要sharding只需要扩从rac存储就能实现了。但是这种代价相对会比较高一些,共享存储一般都比较贵,随着业务的扩展数据的爆炸式增长,你会不停累计你的成本,甚至达到一个天文数字。
目前这种share disk的方式,除了oracle的业务逻辑层做的非常完善之外其他的解决方案都还不是很完美。
Mysql的sharding也有其局限性,sharding之后的数据查询访问以及统计都会有很大的问题,mysql的sharding是解决share nothing的存储的一种分布式的方法,大体上分为垂直拆分和水平拆分。
(6.1)垂直拆分
可以横向拆分,可以纵向拆分,可以横向纵向拆分,还可以按照业务拆分。
6.1.1横向拆分
Mysql库里面的横向拆分是指,每一个数据库实例里面都有很多个db库,每一个db库里面都有A表B表,比如db1库有A表B表,db2库里也有A表和B表,那么我们把db1、db2库的A表B表拆分出来,把一个库分成2个,就拆分成db1、db2、db3、db4,其中db1库和db2库放A表数据,db3库和db4库放B表的数据,db1、db2库里面只有A表数据,db3、db4库里面只有B表的数据。
打个比方,作为电商来说,每个库里面都有日志表和订单表,假如A表是日志表log表,B表是订单表Order表,一般说来写日志和写订单没有强关联性,我们可以讲A表日志表和B表订单表拆分出来。那么这个时候就做了一次横向的拆分工作,将A表日志表和B表订单表拆分开来放在不同的库,当然A表和B表所在的数据库名也可以保持一致(PS:在不同的实例里面),如下图所示:

PS:这种拆分主要针对于不同的业务对表的影响不大,表之间的业务关联很弱或者基本上没有业务关联。拆分的好处是不相关的数据表拆分到不同的实例里面,对数据库的容量扩展和性能提高的均衡来说,都是蛮有好处的。
6.1.2纵向拆分
把同一个实例上的不同的db库拆分出来,放入单独的不同实例中。这种拆分的适应场景和要求是db1和db2是没有多少业务联系的,类似6.1.2里面的A表和B表那样。如果你用到了跨库业务同时使用db1和db2的话,个人建议要重新考虑下业务,重新梳理下尽量把一个模块的表放在一个库里面,不要垮库操作。
这种库纵向拆分里面,单独的库db1,表A和表B是强关联的。如下图所示:

PS:看到很多使用mysql的人,总是把很多没有业务关联性的表放在一个库里面,或者总是把很多个的db库放在同一个实例里面,就像使用oracle那样就一个instance的概念而已。Mysql的使用一大原则就是简单,尽量单一,简单的去使用mysql,库要严格的分开;表没有关系的,要严格拆分成库。这样的话扩展我们的业务就非常方便简单了,只需要把业务模块所在的db拆分出来,放入新的数据库服务器上即可。
6.1.3 横向纵向拆分
有些刚起步的,开始为了快速出产品,就把所以的库所有的表都放在一个实例上,等业务发展后,就面临着数据拆分,这里就会把横向纵向拆分结合起来,一起实现,如下图所示:

6.1.4 业务拆分
跟水平拆分有点类似,但是有不同的地方。比如一个供应商,可能整个网站上有10个供应商,一个网站上面每一个供应商都有一定的量,而且供应商之间的数据量规模都差不多的规模,那么这个时候就可以使用供应商的纬度来做拆分。
比如usern库中,a、b、c表都是强关联的,都有完整的业务逻辑存在,这里只有用户(供应商)纬度是没有关联的,那这个时候就可以把数据以用户的纬度来进行拆分。
就是用户1和用户2各自都有一套完整的业务逻辑,而且彼此之间不关联,所以就可以把用户1和用户2数据拆分到不同的数据库实例上面。目前很多互联网公司或者游戏公司有很多业务都是以用户纬度进行拆分的,比如qunaer、sohu game、sina等。

(6.2) 水平拆分
水平拆分相对要简单一些,但是难度偏大,会导致分布式的情况、跨数据的情况、跨事务的情况可以分为大概三类,1是历史数据和实时数据拆分,2是单库多表拆分,3是多库多表拆分。
6.2.1 实时数据历史数据的拆分和历史数据迁移是一样的逻辑,就是要将online库的数据迁移到listory的数据库里面,对于实时的读写来说,数据是放在online db库里面,对于时间较远的数据来说,是放在历史History DB记录库里面的,这里的历史库可以是mysql也可以是别的nosql库等。

6.2.2 单库多表拆分
主要不是解决容量问题,而是解决性能问题而扩展的,加入当前实例只有一个DB,有一个大表,一个大表就把整个实例占满了,这个时候就不能拆分db了,因为只有一个单表,这个时候我们就只能拆表了,拆表的方式主要是解决性能问题,因为单个表越大,对于mysql来说遍历表的树形结构遍历数据会消耗更多的资源,有时候一个简单的查询就可能会引起整个db的很多叶子节点都要变动。表的insert、update、delete操作都会引起几乎所有节点的变更,此时操作量会非常大,操作的时候读写性能都会很低,这个时候我们就可以考虑把大表拆分成多个小表,工作经历中是按照hash取模打散成16个小表,也有按照id主键/50取模打散到50个小表当中,下图实例是打散成2个小表。

6.2.3 多库多表拆分
在单库多表的基础上,如果单库空间资源已经不足以提供业务支撑的话,可以考虑多库多表的方式来做,解决了空间问题和性能问题,不过会有一个问题就是跨库查询操作,查询就会有另外的策略,比如说加一个logic db层来实现跨库跨实例自动查询,简单如下图所示:

6.2.4水平拆分小结
水平拆分原则:
-- a. 尽量均匀的拆分维度。
-- b. 尽量避免跨库事务。
-- c. 尽量避免跨库查询。
设计:
--a根据拆分维度,做mod进行数据表拆分,大部分都是取模的拆分机制,比如hash的16模原则等。
--b根据数据容量,划分数据库拆分
数据操作
--a跨事务操作:分布式事务,通过预写日志的方式来间接地实现。
--b跨库查询:数据汇总or消息服务
u 案例:
– 按照用户维度进行拆分成64个分库,1024个分表
? user_id%1024 拆分到1024张分表中
? 每个分库中存放1024/64张分表
? 取模的时候,可以用id的最后4位数据或者3位数字来取模就可以了。

u 操作1:采用Configure DB
– 拆分之后的查询操作,做一个Configure DB,这个DB存放的是所有实例的库表的映射关系,当我APP发来有一个请求查询user1的数据,那么这个user1的数据是存放在上千个实例中的哪一个库表呢?这个关联信息就在Configure DB里面,APP先去Configure DB里面取得user1的关联系信息(比如是存放在d_01库上的t_0016表里面),然后APP根据关联信息直接去查询对应的d_01实例的t_0016表里面取得数据。

u 操作2:采用Proxy
– 拆分之后的查询操作,做一个Proxy,APP访问Proxy,Proxy根据访问规则就可以直接路由到具体的db实例,生成新的sql去操作对应的db实例,然后通过Proxy协议进行操作把操作结果返回给APP。
– 优势是Proxy和db实例是在一个网段,这样Proxy与db实例的操作的时间是非常短的。

u 操作3:采用Data Engine
– 拆分之后的查询操作,有一个Data Engine Service,这个DES里面配置了所有数据库实例的映射关系,需要在APP应用端安装一个Agent,是同步逻辑,在JDBC层实现,DES可以实现读写分离,原理可以参考TDDL的实现。

6.3 集群管理
纵向扩容:一个实例拆分成多个实例,纵向拆分比较简单,修改的东西比较少,拆分的时候要通知到Configure DB或者DES,以免拆分之后查询不到数据或者数据录入不到新的db上面,如下图所示:

横向扩容:比较复杂,在纵向扩容成2个库的基础之上,再一次对库的表进行扩容,所以需要及时通知Configure DB和DES更细库和表的路由连接信息。

----------------------------------------------------------------------------------------------------------------
<版权所有,文章允许转载,但必须以链接方式注明源地址,否则追究法律责任!>
原文章地址: http://blog.csdn.net/mchdba/article/details/39810363
mysqld_multi 配置MySQL多实例
1、下载MySQL源码安装版本
到MySQL官网查找到相应版本下载,本文下载的是5.1版本
wget -c ftp://ftp.mirrorservice.org/sites/ftp.mysql.com/Downloads/MySQL-5.1/mysql-5.1.60.tar.gz
2、解压安装
tar -zxv -f mysql-5.1.60.tar.gz
./configure \ --prefix=/usr/local/m \ --enable-assembler \ --enable-local-infile \ --with-charset=utf8 \ --with-collation=utf8_general_ci \ --with-extra-charsets=none \ --with-openssl \ --with-pthread \ --with-unix-socket-path=/var/lib/mysql/mysql.sock \ --with-mysqld-user=mysql \ --with-mysqld-ldflags \ --with-client-ldflags \ --with-comment \ --with-big-tables \ --without-ndb-debug \ --without-docs \ --without-debug \ --without-bench make && make install
3、添加用户和用户组
4、初始化数据目录
#把用到的工具添加到/usr/bin目录 ln -s /usr/local/mysql/bin/mysqld_multi /usr/bin/mysqld_multi ln -s /usr/local/mysql/bin/mysql_install_db /usr/bin/mysql_install_db #初始化四个数据目录 mysql_install_db --datadir=/usr/local/var/mysql1 --user=mysql mysql_install_db --datadir=/usr/local/var/mysql2 --user=mysql mysql_install_db --datadir=/usr/local/var/mysql3 --user=mysql mysql_install_db --datadir=/usr/local/var/mysql4 --user=mysql #修改属性 chown -R mysql /usr/local/var/mysql1 chown -R mysql /usr/local/var/mysql2 chown -R mysql /usr/local/var/mysql3 chown -R mysql /usr/local/var/mysql4
5、配置多实例启动脚本
从MySQL的源码中把复制到/etc/init.d/目录下
cp /usr/local/src/mysql-5.1.60/support-files/mysqld_multi.server /etc/init.d/mysqld_multi.server #修改basedir和bindir为安装路径 basedir=/usr/local/mysql bindir=/usr/local/mysql/bin
6、配置多实例数据库配置文件
用mysqld_multi工具查看该配置文件的模板方法,命令为:mysqld_multi --example
在/etc/目录下创建创建文件/etc/mysqld_multi.cnf,把mysqld_multi --example产生的文件粘进去,修改相应属性,如:mysqld,mysqladmin,socket,port,pid-file,datadir,user等。
[mysqld_multi] mysqld = /usr/local/mysql/bin/mysqld_safe mysqladmin = /usr/local/mysql/bin/mysqladmin #user = mysql #password = my_password [mysqld1] socket = /usr/local/var/mysql1/mysql1.sock port = 3306 pid-file = /usr/local/var/mysql1/mysql1.pid datadir = /usr/local/var/mysql1 #language = /usr/local/mysql/share/mysql/english user = mysql [mysqld2] socket = /usr/local/var/mysql2/mysql2.sock port = 3307 pid-file = /usr/local/var/mysql2/mysql2.pid datadir = /usr/local/var/mysql2 #language = /usr/local/mysql/share/mysql/english user = mysql [mysqld3] socket = /usr/local/var/mysql3/mysql3.sock port = 3308 pid-file = /usr/local/var/mysql3/mysql3.pid datadir = /usr/local/var/mysql3 #language = /usr/local/mysql/share/mysql/english user = mysql [mysqld4] socket = /usr/local/var/mysql4/mysql4.sock port = 3309 pid-file = /usr/local/var/mysql4/mysql4.pid datadir = /usr/local/var/mysql4 #language = /usr/local/mysql/share/mysql/english user = mysql注意:除了以上配置方法,还可以直接写到主配置文件中。如下:
7、启动多实例数据库
将/usr/local/mysql/bin加到$PATH环境变量里 export PATH=/usr/local/mysql/bin:$PATH #查看数据库状态 mysqld_multi --defaults-extra-file=/etc/mysqld_multi.cnf report #结果都为没有运行 Reporting MySQL servers MySQL server from group: mysqld1 is not running MySQL server from group: mysqld2 is not running MySQL server from group: mysqld3 is not running MySQL server from group: mysqld4 is not running #启动 mysqld_multi --defaults-extra-file=/etc/mysqld_multi.cnf start #结果为 Reporting MySQL servers MySQL server from group: mysqld1 is not running MySQL server from group: mysqld2 is not running MySQL server from group: mysqld3 is not running MySQL server from group: mysqld4 is not running #启动具体某一个实例可在start、stop后面加上具体数据1,2,3等
8、查看运行结果
#查看相应端口是否已经被监听 netstat -tunlp #查看是否有活动进程 ps -aux|grep mysql
9、登录相应数据库
#进入端口为3306的数据库 mysql -uroot -p -h127.0.0.1 -P3306 #通过sock文件登录 mysql -uroot -p -S /usr/local/var/mysql1/mysql1.sock #查看socket文件 mysql> SHOW VARIABLES LIKE 'socket'; #查看pid文件 mysql> SHOW VARIABLES LIKE '%pid%';
| 特性 | MySQL | PostgreSQL |
| 实例 | 通过执行 MySQL 命令(mysqld)启动实例。一个实例可以管理一个或多个数据库。一台服务器可以运行多个 mysqld 实例。一个实例管理器可以监视 mysqld 的各个实例。 | 通过执行 Postmaster 进程(pg_ctl)启动实例。一个实例可以管理一个或多个数据库,这些数据库组成一个集群。集群是磁盘上的一个区域,这个区域在安装时初始化并由一个目录组成,所有数据都存储在这个目录中。使用 initdb 创建第一个数据库。一台机器上可以启动多个实例。 |
| 数据库 | 数据库是命名的对象集合,是与实例中的其他数据库分离的实体。一个 MySQL 实例中的所有数据库共享同一个系统编目。 | 数据库是命名的对象集合,每个数据库是与其他数据库分离的实体。每个数据库有自己的系统编目,但是所有数据库共享 pg_databases。 |
| 数据缓冲区 | 通过 innodb_buffer_pool_size 配置参数设置数据缓冲区。这个参数是内存缓冲区的字节数,InnoDB 使用这个缓冲区来缓存表的数据和索引。在专用的数据库服务器上,这个参数最高可以设置为机器物理内存量的 80%。 | Shared_buffers 缓存。在默认情况下分配 64 个缓冲区。默认的块大小是 8K。可以通过设置 postgresql.conf 文件中的 shared_buffers 参数来更新缓冲区缓存。 |
| 数据库连接 | 客户机使用 CONNECT 或 USE 语句连接数据库,这时要指定数据库名,还可以指定用户 id 和密码。使用角色管理数据库中的用户和用户组。 | 客户机使用 connect 语句连接数据库,这时要指定数据库名,还可以指定用户 id 和密码。使用角色管理数据库中的用户和用户组。 |
| 身份验证 | MySQL 在数据库级管理身份验证。 基本只支持密码认证。 | PostgreSQL 支持丰富的认证方法:信任认证、口令认证、Kerberos 认证、基于 Ident 的认证、LDAP 认证、PAM 认证 |
| 加密 | 可以在表级指定密码来对数据进行加密。还可以使用 AES_ENCRYPT 和 AES_DECRYPT 函数对列数据进行加密和解密。可以通过 SSL 连接实现网络加密。 | 可以使用 pgcrypto 库中的函数对列进行加密/解密。可以通过 SSL 连接实现网络加密。 |
| 审计 | 可以对 querylog 执行 grep。 | 可以在表上使用 PL/pgSQL 触发器来进行审计。 |
| 查询解释 | 使用 EXPLAIN 命令查看查询的解释计划。 | 使用 EXPLAIN 命令查看查询的解释计划。 |
| 备份、恢复和日志 | InnoDB 使用写前(write-ahead)日志记录。支持在线和离线完全备份以及崩溃和事务恢复。需要第三方软件才能支持热备份。 | 在数据目录的一个子目录中维护写前日志。支持在线和离线完全备份以及崩溃、时间点和事务恢复。 可以支持热备份。 |
| JDBC 驱动程序 | 可以从 参考资料 下载 JDBC 驱动程序。 | 可以从 参考资料 下载 JDBC 驱动程序。 |
| 表类型 | 取决于存储引擎。例如,NDB 存储引擎支持分区表,内存引擎支持内存表。 | 支持临时表、常规表以及范围和列表类型的分区表。不支持哈希分区表。 由于PostgreSQL的表分区是通过表继承和规则系统完成了,所以可以实现更复杂的分区方式。 |
| 索引类型 | 取决于存储引擎。MyISAM:BTREE,InnoDB:BTREE。 | 支持 B-树、哈希、R-树和 Gist 索引。 |
| 约束 | 支持主键、外键、惟一和非空约束。对检查约束进行解析,但是不强制实施。 | 支持主键、外键、惟一、非空和检查约束。 |
| 存储过程和用户定义函数 | 支持 CREATE PROCEDURE 和 CREATE FUNCTION 语句。存储过程可以用 SQL 和 C++ 编写。用户定义函数可以用 SQL、C 和 C++ 编写。 | 没有单独的存储过程,都是通过函数实现的。用户定义函数可以用 PL/pgSQL(专用的过程语言)、PL/Tcl、PL/Perl、PL/Python 、SQL 和 C 编写。 |
| 触发器 | 支持行前触发器、行后触发器和语句触发器,触发器语句用过程语言复合语句编写。 | 支持行前触发器、行后触发器和语句触发器,触发器过程用 C 编写。 |
| 系统配置文件 | my.conf | Postgresql.conf |
| 数据库配置 | my.conf | Postgresql.conf |
| 客户机连接文件 | my.conf | pg_hba.conf |
| XML 支持 | 有限的 XML 支持。 | 有限的 XML 支持。 |
| 数据访问和管理服务器 | OPTIMIZE TABLE —— 回收未使用的空间并消除数据文件的碎片 myisamchk -analyze —— 更新查询优化器所使用的统计数据(MyISAM 存储引擎) mysql —— 命令行工具 MySQL Administrator —— 客户机 GUI 工具 |
Vacuum —— 回收未使用的空间 Analyze —— 更新查询优化器所使用的统计数据 psql —— 命令行工具 pgAdmin —— 客户机 GUI 工具 |
| 并发控制 | 支持表级和行级锁。InnoDB 存储引擎支持 READ_COMMITTED、READ_UNCOMMITTED、REPEATABLE_READ 和 SERIALIZABLE。使用 SET TRANSACTION ISOLATION LEVEL 语句在事务级设置隔离级别。 | 支持表级和行级锁。支持的 ANSI 隔离级别是 Read Committed(默认 —— 能看到查询启动时数据库的快照)和 Serialization(与 Repeatable Read 相似 —— 只能看到在事务启动之前提交的结果)。使用 SET TRANSACTION 语句在事务级设置隔离级别。使用 SET SESSION 在会话级进行设置。 |
MySQL相对于PostgreSQL的劣势:
| MySQL | PostgreSQL |
| 最重要的引擎InnoDB很早就由Oracle公司控制。目前整个MySQL数据库都由Oracle控制。 | BSD协议,没有被大公司垄断。 |
| 对复杂查询的处理较弱,查询优化器不够成熟 | 很强大的查询优化器,支持很复杂的查询处理。 |
| 只有一种表连接类型:嵌套循环连接(nested-loop),不支持排序-合并连接(sort-merge join)与散列连接(hash join)。 | 都支持 |
| 性能优化工具与度量信息不足 |
提供了一些性能视图,可以方便的看到发生在一个表和索引上的select、delete、update、insert统计信息,也可以看到cache命中率。网上有一个开源的pgstatspack工具。 |
|
InnoDB的表和索引都是按相同的方式存储。也就是说表都是索引组织表。这一般要求主键不能太长而且插入时的主键最好是按顺序递增,否则对性能有很大影响。 |
不存在这个问题。 |
|
大部分查询只能使用表上的单一索引;在某些情况下,会存在使用多个索引的查询,但是查询优化器通常会低估其成本,它们常常比表扫描还要慢。 |
不存在这个问题 |
|
表增加列,基本上是重建表和索引,会花很长时间。 |
表增加列,只是在数据字典中增加表定义,不会重建表 |
|
存储过程与触发器的功能有限。可用来编写存储过程、触发器、计划事件以及存储函数的语言功能较弱 |
除支持pl/pgsql写存储过程,还支持perl、python、Tcl类型的存储过程:pl/perl,pl/python,pl/tcl。 也支持用C语言写存储过程。 |
|
不支持Sequence。 |
支持 |
|
不支持函数索引,只能在创建基于具体列的索引。 不支持物化视图。 |
支持函数索引,同时还支持部分数据索引,通过规则系统可以实现物化视图的功能。 |
|
执行计划并不是全局共享的, 仅仅在连接内部是共享的。 |
执行计划共享 |
|
MySQL支持的SQL语法(ANSI SQL标准)的很小一部分。不支持递归查询、通用表表达式(Oracle的with 语句)或者窗口函数(分析函数)。 |
都 支持 |
|
不支持用户自定义类型或域(domain) |
支持。 |
|
对于时间、日期、间隔等时间类型没有秒以下级别的存储类型 |
可以精确到秒以下。 |
|
身份验证功能是完全内置的,不支持操作系统认证、PAM认证,不支持LDAP以及其它类似的外部身份验证功能。 |
支持OS认证、Kerberos 认证 、Ident 的认证、LDAP 认证、PAM 认证 |
|
不支持database link。有一种叫做Federated的存储引擎可以作为一个中转将查询语句传递到远程服务器的一个表上,不过,它功能很粗糙并且漏洞很多 |
有dblink,同时还有一个dbi-link的东西,可以连接到oracle和mysql上。 |
|
Mysql Cluster可能与你的想象有较大差异。开源的cluster软件较少。 复制(Replication)功能是异步的,并且有很大的局限性.例如,它是单线程的(single-threaded),因此一个处理能力更强的Slave的恢复速度也很难跟上处理能力相对较慢的Master. |
有丰富的开源cluster软件支持。 |
|
explain看执行计划的结果简单。 |
explain返回丰富的信息。 |
|
类似于ALTER TABLE或CREATE TABLE一类的操作都是非事务性的.它们会提交未提交的事务,并且不能回滚也不能做灾难恢复 |
DDL也是有事务的。 |
PostgreSQL主要优势:
1. PostgreSQL完全免费,而且是BSD协议,如果你把PostgreSQL改一改,然后再拿去卖钱,也没有人管你,这一点很重要,这表明了 PostgreSQL数据库不会被其它公司控制。oracle数据库不用说了,是商业数据库,不开放。而MySQL数据库虽然是开源的,但现在随着SUN 被oracle公司收购,现在基本上被oracle公司控制,其实在SUN被收购之前,MySQL中最重要的InnoDB引擎也是被oracle公司控制的,而在MySQL中很多重要的数据都是放在InnoDB引擎中的,反正我们公司都是这样的。所以如果MySQL的市场范围与oracle数据库的市场范围冲突时,oracle公司必定会牺牲MySQL,这是毫无疑问的。
2. 与PostgreSQl配合的开源软件很多,有很多分布式集群软件,如pgpool、pgcluster、slony、plploxy等等,很容易做读写分离、负载均衡、数据水平拆分等方案,而这在MySQL下则比较困难。
3. PostgreSQL源代码写的很清晰,易读性比MySQL强太多了,怀疑MySQL的源代码被混淆过。所以很多公司都是基本PostgreSQL做二次开发的。
4. PostgreSQL在很多方面都比MySQL强,如复杂SQL的执行、存储过程、触发器、索引。同时PostgreSQL是多进程的,而MySQL是线程的,虽然并发不高时,MySQL处理速度快,但当并发高的时候,对于现在多核的单台机器上,MySQL的总体处理性能不如PostgreSQL,原因是 MySQL的线程无法充分利用CPU的能力。
目前只想到这些,以后想到再添加,欢迎大家拍砖。
PostgreSQL与oracle或InnoDB的多版本实现的差别
PostgreSQL与oracle或InnoDB的多版本实现最大的区别在于最新版本和历史版本是否分离存储,PostgreSQL不分,而oracle和InnoDB分,而innodb也只是分离了数据,索引本身没有分开。
PostgreSQL的主要优势在于:
1. PostgreSQL没有回滚段,而oracle与innodb有回滚段,oracle与Innodb都有回滚段。对于oracle与Innodb来说,回滚段是非常重要的,回滚段损坏,会导致数据丢失,甚至数据库无法启动的严重问题。另由于PostgreSQL没有回滚段,旧数据都是记录在原先的文件中,所以当数据库异常crash后,恢复时,不会象oracle与Innodb数据库那样进行那么复杂的恢复,因为oracle与Innodb恢复时同步需要redo和undo。所以PostgreSQL数据库在出现异常crash后,数据库起不来的几率要比oracle和mysql小一些。
2. 由于旧的数据是直接记录在数据文件中,而不是回滚段中,所以不会象oracle那样经常报ora-01555错误。
3. 回滚可以很快完成,因为回滚并不删除数据,而oracle与Innodb,回滚时很复杂,在事务回滚时必须清理该事务所进行的修改,插入的记录要删除,更新的记录要更新回来(见row_undo函数),同时回滚的过程也会再次产生大量的redo日志。
4. WAL日志要比oracle和Innodb简单,对于oracle不仅需要记录数据文件的变化,还要记录回滚段的变化。
PostgreSQL的多版本的主要劣势在于:
1、最新版本和历史版本不分离存储,导致清理老旧版本需要作更多的扫描,代价比较大,但一般的数据库都有高峰期,如果我们合理安排VACUUM,这也不是很大的问题,而且在PostgreSQL9.0中VACUUM进一步被加强了。
2、由于索引中完全没有版本信息,不能实现Coverage index scan,即查询只扫描索引,直接从索引中返回所需的属性,还需要访问表。而oracle与Innodb则可以;
进程模式与线程模式的对比
PostgreSQL和oracle是进程模式,MySQL是线程模式。
进程模式对多CPU利用率比较高。
进程模式共享数据需要用到共享内存,而线程模式数据本身就是在进程空间内都是共享的,不同线程访问只需要控制好线程之间的同步。
线程模式对资源消耗比较少。
所以MySQL能支持远比oracle多的更多的连接。
对于PostgreSQL的来说,如果不使用连接池软件,也存在这个问题,但PostgreSQL中有优秀的连接池软件软件,如pgbouncer和pgpool,所以通过连接池也可以支持很多的连接。
堆表与索引组织表的的对比
Oracle支持堆表,也支持索引组织表
PostgreSQL只支持堆表,不支持索引组织表
Innodb只支持索引组织表
索引组织表的优势:
表内的数据就是按索引的方式组织,数据是有序的,如果数据都是按主键来访问,那么访问数据比较快。而堆表,按主键访问数据时,是需要先按主键索引找到数据的物理位置。
索引组织表的劣势:
索引组织表中上再加其它的索引时,其它的索引记录的数据位置不再是物理位置,而是主键值,所以对于索引组织表来说,主键的值不能太大,否则占用的空间比较大。
对于索引组织表来说,如果每次在中间插入数据,可能会导致索引分裂,索引分裂会大大降低插入的性能。所以对于使用innodb来说,我们一般最好让主键是一个无意义的序列,这样插入每次都发生在最后,以避免这个问题。
由于索引组织表是按一个索引树,一般它访问数据块必须按数据块之间的关系进行访问,而不是按物理块的访问数据的,所以当做全表扫描时要比堆表慢很多,这可能在OLTP中不明显,但在数据仓库的应用中可能是一个问题。
PostgreSQL9.0中的特色功能:
PostgreSQL中的Hot Standby功能
也就是standby在应用日志同步时,还可以提供只读服务,这对做读写分离很有用。这个功能是oracle11g才有的功能。
PostgreSQL异步提交(Asynchronous Commit)的功能:
这个功能oracle中也是到oracle11g R2才有的功能。因为在很多应用场景中,当宕机时是允许丢失少量数据的,这个功能在这样的场景中就特别合适。在PostgreSQL9.0中把 synchronous_commit设置为false就打开了这个功能。需要注意的是,虽然设置为了异步提交,当主机宕机时,PostgreSQL只会丢失少量数据,异步提交并不会导致数据损坏而数据库起不来的情况。MySQL中没有听说过有这个功能。
PostgreSQL中索引的特色功能:
PostgreSQL中可以有部分索引,也就是只能表中的部分数据做索引,create index 可以带where 条件。同时PostgreSQL中的索引可以反向扫描,所以在PostgreSQL中可以不必建专门的降序索引了。
1. 为什么要用单机多实例
目前互联网的MySQL的服务器都配置了Flash卡或者SSD磁盘,IO能力得到大幅的提高;而Intel的CPU目前的能力不比IBM小型机的CPU差,轻松就是24或者48个超线程;内存现在也很便宜,一般的服务器配上128G的内存也用不了多少钱。
CPU,MEMORY和IO的问题解决以后,反而是MySQL不能充分利用服务器的资源了,短时间内由于MySQL代码重构和各种锁的分拆,并发编程的难度等问题,导致MySQL的对机器利用率又不能得到非常大的提升,所以我们需要尽量在一个服务器上运行多个MySQL,以充分发挥服务器的资源。
一个服务器上运行多个MySQL,我们最关心的是多个实例之间资源竞争的问题,而解决方案:第一个想到的可能就是使用xen或者vmware等虚拟机软件来在同一个服务器上虚拟多个服务器,每个虚拟机上跑独立的MySQL。但是众所周知,虚拟机软件本身要耗费资源,5%到20%不等。有没有一种即简单又能够满足实例资源分离的方案列?
目前,比较实用的,并且被广泛用于线上资源隔离的就是CGroup了。下面我们就来了解一下CGroup。
2. CGROUP简介
CGroup是Linux内核提供的一种资源隔离手段,分别对CPU,MEMORY,IO等资源进行隔离,并且把这些隔离分为多个子系统。
摘录王喆锋https://files.cnblogs.com/lisperl/cgroups%E4%BB%8B%E7%BB%8D.pdf中的介绍如下:
- blkio -- 这个子系统为块设备设定输入/输出限制,比如物理设备(磁盘,固态硬盘,USB 等等)。
- cpu -- 这个子系统使用调度程序提供对 CPU 的 cgroup 任务访问。
- cpuacct -- 这个子系统自动生成 cgroup 中任务所使用的 CPU 报告。
- cpuset -- 这个子系统为 cgroup 中的任务分配独立 CPU(在多核系统)和内存节点。
- devices -- 这个子系统可允许或者拒绝 cgroup 中的任务访问设备。
- freezer -- 这个子系统挂起或者恢复 cgroup 中的任务。
- memory -- 这个子系统设定 cgroup 中任务使用的内存限制,并自动生成由那些任务使用的内存资源报告。
- net_cls -- 这个子系统使用等级识别符(classid)标记网络数据包,可允许 Linux 流量控制程序(tc)识别从具体 cgroup 中生成的数据包。
- ns -- 名称空间子系统。
简单来说就是CGroup会监控进程中CPU,MEMORY,IO等各种资源,并根据用户的配置对它进行限制。它的消耗比虚拟机的消耗就要小的多了。
下面我们通过具体的配置简单了解CGroup的功能。
3. CGROUP配置
例如:我们在某个服务器上计划启动4个实例,需要设置每个实例的CPU只能用8个超线程,内存最大只能到16G。该服务器一共有48个超线程。
这里我们对MySQL不配置IO限制,也就是说我们这里允许IO有一定的竞争,我们希望从应用模块上尽量把一些耗费IO的时间段分隔开,各个应用模块的定时任务,全表扫描等操作对于在同一个服务器上的各个不同实例我们尽量分离。
这里我们也不开启cpuacct等CPU报告的子系统,节省服务器资源。
针对CPU和MEMORY等资源分离的话,就需要配置如下:
3.1. CGCONFIG配置
在/etc/cgconfig.conf,我们只对cpu和内存做限制,所以只需要挂载两个子系统。另外,我们在服务器上计划启动4个实例,这四个实例分别属于四个组,mysql_g1, mysql_g2, mysql_g3, mysql_g4。目前我们限制它们都在8个超线程并且每个实例的内存不超过16G。如下:
mount {
cpuset = /cgroup/cpuset;
memory = /cgroup/memory;
blkio = /cgroup/cpu_and_mem;
}
group mysql_g1 {
cpuset {
cpuset.cpus = "33,35,37,39,41,43,45,47";
cpuset.mems = "0";
}
memory {
memory.limit_in_bytes=17179869184;
memory.swappiness=0;
}
}
group mysql_g2 {
cpuset {
cpuset.cpus = "32,34,36,38,40,42,44,46";
cpuset.mems = "0";
}
memory {
memory.limit_in_bytes=17179869184;
memory.swappiness=0;
}
}
group mysql_g3 {
cpuset {
cpuset.cpus = "17,19,21,23,25,27,29,31";
cpuset.mems = "0";
}
memory {
memory.limit_in_bytes=17179869184;
memory.swappiness=0;
}
}
group mysql_g4 {
cpuset {
cpuset.cpus = "16,18,20,22,24,26,28,30";
cpuset.mems = "0";
}
memory {
memory.limit_in_bytes=17179869184;
memory.swappiness=0;
}
}
group mysql_admin {
cpuset {
cpuset.cpus = "1,3,5,7,9,11,13,15";
cpuset.mems="0";
}
memory {
memory.limit_in_bytes=2147483648;
memory.memsw.limit_in_bytes=2684354560;
memory.swappiness=0;
}
blkio {
blkio.throttle.read_iops_device = "8:0 2000";
}
}
3.1.1. 配置详解
CGoup的配置主要包括两个,一个是mount,一个是group。
1.MOUNT
这里,mount表示挂载了两个子系统:cpuset,memory,blkio,分别对cpu,内存和IO能力进行限制。
mount {
cpuset = /cgroup/cpu_and_mem;
memory = /cgroup/cpu_and_mem;
blkio = /cgroup/cpu_and_mem;
}
这里其实对应的linux操作系统中的/cgroup/cpu_and_mem这个目录。在linux里面,一切可以被视为文件,在这个目录里面有各种配置文件以及状态信息。
其实cgconfig也就是帮你把配置文件中的配置整理到/cgroup/cpu_and_mem这个目录里面,上面的mount对应的命令为:
mkdir -p /cgroup/cpu_and_mem
mount -t cgroup -o cpu,memory,blkio none /cgroup/cpu_and_mem
2.GROUP设置
对于mysql_g1的限制中,
- CPU限制
CPU我们限制该组只能在33,35,37,39,41,43,45,47一共8个超线程上运行。cpuset.mems是用来设置内存节点的。
cpuset {
cpuset.cpus = "33,35,37,39,41,43,45,47";
cpuset.mems = "0";
}
其实cgconfig也就是帮你把配置文件中的配置整理到/cgroup/cpu_and_mem这个目录里面,比如你需要动态设置mysql_group1/ cpuset.cpus的CPU超线程号,可以采用如下的办法。
echo "33,35,37,39,41,43,45,47" > mysql_group1/ cpuset.cpus
现在较新的服务器CPU都是numa结构,使用numactl --hardware可以看到numa各个节点的CPU超线程号,以及对应的节点号。
输出如下:
[root@test2 ~]# numactl --hardware
available: 2 nodes (0-1)
node 0 cpus: 0 2 4 6 8 10 12 14
node 0 size: 24575 MB
node 0 free: 15738 MB
node 1 cpus: 1 3 5 7 9 11 13 15
node 1 size: 24575 MB
node 1 free: 23945 MB
node distances:
node 0 1
0: 10 20
1: 20 10
我们这里关闭了numa,所以所有的cpuset.mems节点都是0。
这里33,35,37,39,41,43,45,47是间隔2个来的,也是因为我们希望限制MySQL运行在一个numa node上。
另外顺带提一下,关闭numa有三种方式:BIOS,numa=off和程序启动时内存interactive分配。
BIOS关闭是最彻底的,弊端是每个机型都不太一样;在/etc/grub中设置numa=off启动操作系统时关闭比较统一,方便操作;但是不如BIOS关闭那么彻底;程序启动时关闭能够更精确的控制numa使用,但是操作比较麻烦,每次启动都需要在前面加numactl --cpunodebind=$BIND_NO --localalloc前缀等。
- MEMORY限制
内存限制我们主要限制了MySQL可以使用的内存最大大小memory.limit_in_bytes=16G。而设置swappiness为0是为了让操作系统不会将MySQL的内存匿名页交换出去。
memory {
memory.limit_in_bytes=17179869184;
memory.swappiness=0;
}
- IO限制
这里我们也简单看一下IO限制的配置,在某些情况下,我们会单独分一个mysql_admin的组,用于限制xtrabackup,mysqldump等已知的耗费IO的程序的IO能力。
比如,我们设置/dev/sda的磁盘读iops最大只能到2000,那么我们就可以设置如下:
blkio {
blkio.throttle.read_iops_device = "8:0 2000";
}
其中比较奇怪的是8:0,这是LINUX ALLOCATED DEVICES,具体信息可以参考:https://www.kernel.org/doc/Documentation/devices.txt。并且使用ls -l命令可以查看对应设备的编号:
[root@test2 ~]# ls -l /dev/sda
brw-rw---- 1 root disk 8, 0 Sep 14 22:06 /dev/sda
这里备份程序其实主要耗费的是读,所以我们设置了blkio.throttle.read_iops_device。Blkio其实也提供了写IOPS,读/写吞吐量的限制。大家可以根据自己的需求进行设置,也可以参考褚霸:http://blog.yufeng.info/archives/2001的测试。
cpuset,memory和blkio其实还有很多其他的可以设置的配置项。我们这里就不一一列举了。
3.2. CGRULE配置
上面我们对分组进行了设置,下面我们就需要设置什么样的进程应该归到哪个分组。
在我们的示例配置/etc/cgrules.conf中,我们设置任何用户只要是使用mysqld_safe1启动的命令为mysql_g1组,这样就可以限制它的CPU和内存使用。其他的四个实例同样进行设置如下:
*:/home/mysql/program/Percona-Server-5.5.33-rel31.1-566-static-openssl-1.0.1e.Linux.x86_64 /bin/mysqld_safe1 * mysql_g1
*:/home/mysql/program/Percona-Server-5.5.33-rel31.1-566-static-openssl-1.0.1e.Linux.x86_64 /bin/mysqld_safe2 * mysql_g2
*:/home/mysql/program/Percona-Server-5.5.33-rel31.1-566-static-openssl-1.0.1e.Linux.x86_64 /bin/mysqld_safe3 * mysql_g3
*:/home/mysql/program/Percona-Server-5.5.33-rel31.1-566-static-openssl-1.0.1e.Linux.x86_64 /bin/mysqld_safe4 * mysql_g4
*:/home/mysql/program/Percona-Server-5.5.33-rel31.1-566-static-openssl-1.0.1e.Linux.x86_64 /bin/mysqldump * mysql_admin
这里注意,配置中命令需要写全路径,并且,我们现在是对MySQL一个程序分四个组,所以我们故意对mysqld_safe进行了链接,构造了同一个二进制程序的4个拷贝,用于在启动的时候进行区别。
Cgroup限制对子进程是有效的,这里我们设置了mysqld_safe1对应的cpu,memory,对应的mysqld_safe的子进程和各个线程都会收到cgroup的限制。
另外,不仅配置中命令需要写全路径,程序启动的时候也需要使用全路径。
4. CGROUP配置生效
配置完成以后我们需要使用:
/etc/init.d/cgconfig start
/etc/init.d/cgred start
来使得上述配置生效。
使用全路径的mysqld_safe1启动MySQL,就可以查看MySQL是否处于cgroup的限制中了,利用
ps -eLo pid,cgroup,cmd |grep –i mysqld
可以看到mysqld的cgroup情况。
http://www.t086.com/article/4247
http://www.t086.com/article/4247
http://blog.fity.cn/post/349/
http://blog.fity.cn/post/349/
http://www.icyfire.me/2014/09/12/mysql-multiple-instances.html
Mysql —— 多实例配置
概述
由于一些测试或者开发上的需要,我们可能需要多个的Mysql服务,但是在多个服务器上部署Mysql无疑成本太高,幸好Mysql提供了一个在一台服务器上运行多个mysql实例的工具:mysqld_multi。这个工具可以管理多个mysqld进程,而这些进程监听在不同的socket文件和端口上。通过这个工具,我们还可以启动和停止这些mysqld进程,也可以简单获取到它们的运行状态。
配置
要mysqld_multi工作,我们需要对mysql的配置文件进行修改。假设我们已经在Linux下安装好了Mysql(以我做试验的机器为例,Mysql安装在/usr/local/services/mysql下,配置文件my.cnf放在/etc下)。
首先我们需要添加一个配置组:[mysqld_multi]:
[mysqld_multi]mysqld = /usr/local/services/mysql/bin/mysqld_safemysqladmin = /usr/local/services/mysql/bin/mysqladminuser = multi_adminpassword = multi_pass |
这些配置主要让mysqld_multi能管理mysqld进程,包括启动、停止以及报告状态等。user和password用来停止mysqld服务,我们需要对每个实例添加这个帐号,并赋予SHUTDOWN权限(这一步我们后面再进行操作)。
然后我们需要为每个mysqld实例添加一个配置,例如我们需要运行两个实例:
[mysqld2]socket = /tmp/mysql.sock2port = 3307pid-file = /tmp/nmysqld2.piddatadir = /usr/local/services/mysql/data2user = mysql[mysqld3]socket = /tmp/mysql.sock3port = 3308pid-file = /tmp/mysqld3.piddatadir = /usr/local/services/mysql/data3user = mysql |
每一个实例我们需要增加一个[mysqldN]的配置。N是一个数字,从1开始,用来标识每个实例,mysqld_multi通过这个数字编号可以具体的管理到每个实例。
我们需要为每个实例配置不同的socket、port和pid-file。同时,我们也需要为每个实例配置不同的datadir,我们通过mysql_install_db命令来为每个实例创建datadir:
# mysql_install_db --user=mysql --datadir=/usr/local/services/mysql/data2# mysql_install_db --user=mysql --datadir=/usr/local/services/mysql/data3 |
my.cnf文件相关的配置方式,可以使用命令mysqld_multi --example获取更详细的信息。管理
现在,我们可以启动我们的多个实例了:
# mysqld_multi start |
mysqld_multi会查找my.cnf里所有[mysqldN]的配置,并逐一进行启动。我们可以用以下命令来查看实例的运行状态:
# mysqld_multi reportReporting MySQL serversMySQL server from group: mysqld2 is runningMySQL server from group: mysqld3 is running |
# mysqld_multi --log=/tmp/multi_mysqld.log start# mysqld_multi start 2前面说到过,我们需要对每个实例添加一个具有SHUTDOWN权限的帐号,用于停止实例。以其中一个实例为例子,我们先登录实例:
# mysql -u root -S /tmp/mysql.sock2 |
然后添加帐号和权限:
mysql> GRANT SHUTDOWN ON *.* TO 'multi_admin'@'localhost' IDENTIFIED BY 'multi_pass';mysql> FLUSH PRIVILEGES; |
所有实例的帐号权限都添加好后,我们就可以运行以下命令停止实例了:
# mysqld_multi stop |
查看状态如下:
# mysqld_multi reportReporting MySQL serversMySQL server from group: mysqld2 is not runningMySQL server from group: mysqld3 is not running |
# mysqld_multi stop 2系统环境:centos 6.2 64位
内核版本: 2.6.32-220.el6.x86_64
mysql版本:5.1.62
一,MySQL多实例介绍及MySQL多实例的特点
1、什么是MySQL多实例?
MySQL多实例就是在一台机器上开启多个不同的服务端口(如:3306,3307,3308),运行多个MySQL服务进程,通过不同的socket监听不同的服务端口来提供各自的服务。
2、MySQL多实例的特点有以下几点:
1)、有效利用服务器资源,当单个服务器资源有剩余时,可以充分利用剩余的资源提供更多的服务。
2)、节约服务器资源
3)、资源互相抢占问题,当某个服务实例服务并发很高时或者开启慢查询时,会消耗更多的内存、CPU、磁盘IO资源,导致服务器上的其他实例提供服务的质量下降。
二,MySQL多实例的安装配置
1、首先创建mysql用户和组:
1 |
[root@LVS_RS_104 ~]# groupadd mysql |
2 |
[root@LVS_RS_104 ~]# useradd -s /sbin/nologin -g mysql -M mysql |
2、下载MySQL源码包并解压安装
1 |
[root@LVS_RS_104 ~]# wget http://mysql.ntu.edu.tw/Downloads/MySQL-5.1/mysql-5.1.62.tar.gz |
2 |
[root@LVS_RS_104 ~]# tar zxvf mysql-5.1.62.tar.gz |
3 |
[root@LVS_RS_104 ~]# cd mysql-5.1.62 |
4 |
[root@LVS_RS_104 mysql-5.1.62]# ./configure --prefix=/usr/local/mysql --localstatedir=/usr/local/mysql/data --with-unix-socket-path=/usr/local/mysql/tmp/mysql.sock --with-extra-charsets=all --with-charset=utf8 --with-client-ldflags=-all-static--with-mysqld-ldflags=-all-static --with-plugins=all --with-pthread --enable-thread-safe-client --with-extra-charsets=all |
5 |
[root@LVS_RS_104 mysql-5.1.62]# make && make install |
3 mysql参数说明:
–prefix=/usr/local/mysql #指定mysql的安装路径
–enable-assembler #允许使用汇编模式(优化性能)
–enable-thread-safe-client #以线程方式编译mysql
–with-mysqld-user=mysql #指定mysql运行的系统的用户
–with-big-tables #支持大表,即使是32位的系统也能支持4G以上的表
–without-debug #使用非debug模式
–with-pthread #强制使用pthread线程库编译
–with-extra-charsets=complex #mysql默认的字符集使用complex
–with-ssl #支持ssl
–with-plugin=partition,innobase
–with-plugin-PLUGIN
–with-mysqld-ldflags=-all-static #服务器使用静态库(优化性能)
–with-client-ldfags=-all-static #客户端使用静态库(优化性能)
更多参数请看源码目录的INSTALL或者./configure –help
4、创建MySQL多实例的数据目录
01 |
[root@LVS_RS_104 mysql-5.1.62]# mkdir/usr/local/mysql/data/{3306,3307,3308}/data -p |
02 |
[root@LVS_RS_104 mysql-5.1.62]# tree /usr/local/mysql/data/ |
03 |
/usr/local/mysql/data/ |
04 |
├── 3306 |
05 |
│ └── data |
06 |
├── 3307 |
07 |
│ └── data |
08 |
└── 3308 |
09 |
└── data |
10 |
|
11 |
6 directories, 0 files |
5、创建MySQL多实例配置文件
这里和单实例配置不同。因为要配置多个配置文件要多份,我们可以通过vim命令来添加,如下
1 |
[root@LVS_RS_104 data]# vim /usr/local/mysql/data/3306/my.cnf |
2 |
[root@LVS_RS_104 data]# vim /usr/local/mysql/data/3307/my.cnf |
3 |
[root@LVS_RS_104 data]# vim /usr/local/mysql/data/3308/my.cnf |
MySQL多实例的配置文件my.cnf和启动文件在附件,读者可以下载下来放到各实例的目录,启动文件需要把属组和属主改为mysql并添加执行权限,如下:
1 |
[root@LVS_RS_104 data]# chownmysql.mysql /usr/local/mysql/data/3306/mysql |
2 |
[root@LVS_RS_104 data]# chownmysql.mysql /usr/local/mysql/data/3307/mysql |
3 |
[root@LVS_RS_104 data]# chownmysql.mysql /usr/local/mysql/data/3308/mysql |
4 |
[root@LVS_RS_104 data]# chmod+x /usr/local/mysql/data/3306/mysql |
5 |
[root@LVS_RS_104 data]# chmod+x /usr/local/mysql/data/3307/mysql |
6 |
[root@LVS_RS_104 data]# chmod +x /usr/local/mysql/data/3308/mysql |
6、初始化MySQL数据目录并添加mysql命令道全局路径
1 |
[root@LVS_RS_104 data]# echo 'export PATH=$PATH:/usr/local/mysql/bin/'>>/etc/profile |
2 |
[root@LVS_RS_104 data]# source /etc/profile |
3 |
[root@LVS_RS_104 data]# mysql_install_db --basedir=/usr/local/mysql --datadir=/usr/local/mysql/ |
4 |
data/3306/data/ |
5 |
[root@LVS_RS_104 data]# mysql_install_db --basedir=/usr/local/mysql --datadir=/usr/local/mysql/ |
6 |
data/3307/data/ |
7 |
[root@LVS_RS_104 data]# mysql_install_db --basedir=/usr/local/mysql --datadir=/usr/local/mysql/ |
8 |
data/3308/data/ |
7、启动MySQL多实例
1 |
[root@LVS_RS_104 3306]# ./mysql start |
2 |
Starting MySQL... |
3 |
[root@LVS_RS_104 3306]# ../3307/mysql start |
4 |
Starting MySQL... |
5 |
[root@LVS_RS_104 3306]# ../3308/mysql start |
6 |
Starting MySQL... |
检查端口看看mysql是否启动成功![]()
通过上面截图我们发现mysql启动成功。
MySQL多实例配置文件和启动文件下载地址 http://www.chlinux.net/download/my.cnf.tar.gz
过程中出现的问题:
错误:configure: error: no acceptable C compiler found in $PATH
See `config.log’ for more details.
解决办法:安装GCC软件套件
[root@server mysql-5.0.56]# yum install gcc
错误:configure: error: No curses/termcap library found
解决办法: 编译的时候加上–with-named-curses-libs=/usr/lib/libncurses.so.5
错误:depcomp: line 571: exec: g++: not found 缺少gcc-c++包
解决办法:
1 |
[root@XKWB3403 mysql-5.1.56]yum install gcc-c++ -y |
2 |
[root@XKWB3403 mysql-5.1.56]# make clean |
3 |
再重新编译 |
启动时候发生错误:Starting MySQL.Manager of pid-file quit without updating file
ls -l /var/lib/mysql
chown -R mysql.mysql /var/lib/mysql
chmod -R 755 /var/lib/mysql
http://blog.itechol.com/space-33-do-blog-id-6282.html
Mysql中的mysqld_multi命令,可用于在一台物理服务器运行多个Mysql服务,这些服务进程使用不同的unix socket或是监听于不同的端口。他可以启动、停止和监控当前的服务状态。
使用方法:
# mysqld_multi [options] {start|stop|report} [GNR[,GNR]…]
start,stop和report是指你想到执行的操作。
你可以在单独的服务或是多服务上指定一个操作,区别于选项后面的GNR列表。
如果没有指定GNR列表,那么mysqld_multi将在所有的服务中根据选项文件进行操作。
每一个GNR的值是组的序列号或是一个组的序列号范围。此项的值必须是组名字最后的数字,比如说如果组名为mysqld17,那么此项的值则为17.
如果指定一个范围,使用”-”(破折号)来连接二个数字。如GNR的值为10-13,则指组mysqld10到组mysqld13。多个组或是组范围可以在命令行中指定,使用”,”(逗号)隔开。不能有空白的字符(如空格或tab),在空白字符后面的参数将会被忽略。 (注:GNR值就是我们定义my.cnf中mysqld#中的值,我这里只有1-2).
示例说明:(注意:新版本的mysql中已将--config-file更改为--defaults-file)
# /usr/local/mysq/bin/mysqld_multi –-config-file=/etc/my.cnf start 1
只启动第一个mysql服务,相关文件由my.cnf中mysql1设定.
# /usr/local/mysq/bin/mysqld_multi –-config-file=/etc/my.cnf stop 1
停止第一个mysql服务
# /usr/local/mysq/bin/mysqld_multi –-config-file=/etc/my.cnf start 1-2
启动 第1至4mysql服务,其实就是我这里的全部.
# /usr/local/mysq/bin/mysqld_multi --config-file=/etc/my.cnf report 1-2
mysql5.5数据库多实例部署,我们可以分以下几个步骤来完成。
1、 mysql多实例的原理
2、 mysql多实例的特点
3、 mysql多实例应用场景
4、 mysql5.5多实例部署方法
一、mysql多实例的原理
mysql多实例,简单的说,就是在一台服务器上开启多个不同的mysql服务端口(如3306,3307),运行多个mysql服务进程。这些服务进程通过不同的socket监听不同的服务端口,来提供各自的服务。
这些mysql实例共用一套mysql安装程序,使用不同的my.cnf配置文件、启动程序、数据文件。在提供服务时,mysql多实例在逻辑上看来是各自独立的,各个实例之间根据配置文件的设定值,来取得服务器的相关硬件资源。
二、mysql多实例的特点
2.1 有效的利用服务器资源
当单个服务器资源有剩余时,可以充分利用剩余的服务器资源来提供更多的服务。
2.2 节约服务器资源
当公司资金紧张,但是数据库需要各自提供独立服务,而且需要主从同步等技术时,使用多实例就最好了。
2.3 出现资源互相抢占问题
当某个实例服务并发很高或者有慢查询时,会消耗服务器更多的内存、CPU、磁盘IO等资源,这时就会导致服务器上的其它实例提供访问的质量下降,出现服务器资源互相抢占的现象。
三、mysql多实例应用场景
3.1 资金紧张型公司的选择
当公司业务访问量不太大,又舍不得花钱,但同时又希望不同业务的数据库服务各自独立,而且需要主从同步进行等技术提供备份或读写分离服务时,使用多实例是最好不过的。
3.2 并发访问不是特别大的业务
当公司业务访问量不太大,服务器资源基本闲置的比较多,这是就很适合多实例的应用。如果对SQL语句优化的好,多实例是一个很值得使用的技术。即使并发很大,只要合理分配好系统资源,也不会有太大问题。
四、mysql5.5多实例部署方法
4.1 mysql5.5多实例部署方法
mysql5.5多实例部署方法一个是通过多个配置文件启动多个不同进程的方法,第二个是使用官方自带的mysqld_multi来实现。
第一种方法我们可以把各个实例的配置文件分开,管理比较方便。第二种方法就是把多个实例都放到一个配置文件中,这个管理不是很方便。所以在此我们选择第一种方法,而且以下实验我们全部是在此方法下进行的。
4.2 mysql5.5的安装及配置
要配置mysql5.5多实例,我们首先要安装mysql5.5,有关mysql5.5的安装可以查看《烂泥:mysql5.5数据库cmake源码编译安装》这篇文章。
mysql5.5安装完毕后,我们不要启动mysql,因为此时mysql是单实例的。
4.3 创建mysql多实例的数据目录
现在我们来创建mysql5.5多实例的数据目录,在此我们创建两个mysql实例3306和3307。创建各自的数据目录,如下:
mkdir -p /data/{3306,3307}/data
tree -L 2 /data/

4.4 修改mysql5.5多实例my.cnf文件
实例3306和3307的数据目录创建完毕后,我们来配置实例3306与3307的my.cnf配置文件。
复制mysql5.5安装目录support-files下的my-medium.cnf为my.cnf,并把内容修改为下。现在以3306这个实例为例,如下:
[client]
port = 3306
socket = /data/3306/mysql.sock
[mysqld]
port = 3306
socket = /data/3306/mysql.sock
basedir = /usr/local/mysql
datadir = /data/3306/data
skip-external-locking
key_buffer_size = 16M
max_allowed_packet = 1M
table_open_cache = 64
sort_buffer_size = 512K
net_buffer_length = 8K
read_buffer_size = 256K
read_rnd_buffer_size = 512K
myisam_sort_buffer_size = 8M
skip-name-resolve
log-bin=mysql-bin
binlog_format=mixed
max_binlog_size = 500M
server-id = 1
[mysqld_safe]
log-error=/data/3306/ilanni.err
pid-file=/data/3306/ilanni.pid
[mysqldump]
quick
max_allowed_packet = 16M
[mysql]
no-auto-rehash
[myisamchk]
key_buffer_size = 20M
sort_buffer_size = 20M
read_buffer = 2M
write_buffer = 2M
[mysqlhotcopy]
interactive-timeout

注意图中黄色标记出来的部分,就是我们主要修改的,其他默认保持不变。
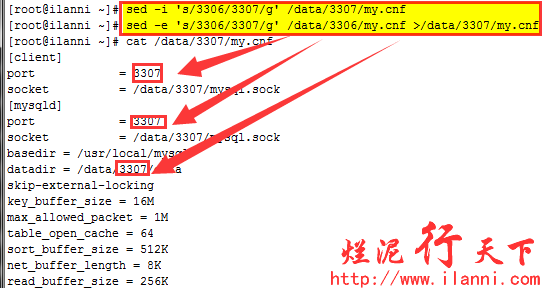
以上是实例3306的my.cnf配置文件,现在我们来配置实例3307的my.cnf。实例3307的配置文件my.cnf我们直接复制实例3306的my.cnf文件,然后通过sed命令把该文件中的3306修改为3307即可。如下:
cp /data/3306/my.cnf /data/3307/my.cnf
sed -i 's/3306/3307/g' /data/3307/my.cnf
或者
sed -e 's/3306/3307/g' /data/3306/my.cnf >/data/3307/my.cnf
4.5 初始化mysql多实例
实例3306和3307的my.cnf配置文件修改完毕后,我们需要来初始化这两个实例,使用mysql_install_db命令。如下:
/usr/local/mysql/scripts/mysql_install_db --basedir=/usr/local/mysql --datadir=/data/3306/data --user=mysql
/usr/local/mysql/scripts/mysql_install_db --basedir=/usr/local/mysql --datadir=/data/3307/data --user=mysql
注意mysql5.5的mysql_install_db在mysql5.5的/usr/local/mysql/scripts/mysql_install_db目录下。


查看实例初始化后的情况,如下:
tree -L 3 /data/

通过上图我们可以看到mysql实例在初始化后会创建基本的数据库。
现在再来看看初始化创建文件的属性,如下:

通过上图可以看到初始化创建的文件都是属于mysql这个用户的。
为什么会是这样呢?
这个是因为我们初始化加入--user=mysql这个选项。当然这个也是我们所需要的,因为这增加了mysql的安全性。
4.6 修改mysql实例的数据库目录权限
mysql实例初始化完毕后,我们现在把实例3306和实例3307的数据目录权限重新赋予给mysql用户。如下:
chown -R mysql:mysql /data/3306
chown -R mysql:mysql /data/3307

这个地方建议一定要操作一遍,否则在启动mysql实例时,会提示出错。导致mysql实例无法启动。
4.7 启动mysql5.5多实例
我们现在来启动实例。使用如下命令:
/usr/local/mysql/bin/mysqld_safe --defaults-file=/data/3306/my.cnf &
/usr/local/mysql/bin/mysqld_safe --defaults-file=/data/3307/my.cnf &
ps aux |grep mysqld

通过上图,我们可以看到实例3306和3307 都已经正常启动。也说明我们的mysql5.5多实例已经配置成功。
其实单实例mysql的启动也是通过mysqld_safe命令来启动。它默认会加载/etc/my.cnf文件。
4.8 登录mysql5.5多实例
登录多实例数据库时,我们需要加入该实例的socket文件,才能正常登录。现在以3306实例为例。
本地登录3306实例,如下:
mysql -uroot -p -S /data/3306/mysql.sock

本地登录进去后,我们在实例3306上创建一个ilanni3306的数据库。如下:
create database ilanni3306;
show databases;

现在我们远程登录实例3306,并查看刚刚新建的数据库。如下:
mysql -h192.168.1.213 -uroot -p -S /data/3306/mysql.sock

或者:mysql -h192.168.1.213 -uroot -p –P 3306

通过上图,我们可以看到远程也是可以连接3306实例的。
4.9 修改mysql5.5多实例root密码
修改实例3306的root密码,使用mysqladmin命令。如下:
mysqladmin -uroot -p password 123456 -S /data/3306/mysql.sock

到此我们的mysql多实例部署就已经完成。
http://www.361way.com/mysqld_multi/1773.html
如果想在单机上运行版本相同的多个mysql实例的,可以通过mysql_install_db初始化到不同的数据目录,通过不同的my.cnf指定相关的参数,分别设置不同的启动和关闭脚本。不过这样管理起来感觉非常麻烦。当然,如果只单台主机上启动两个实例,这样做还可以接受。如果启动四个、五个甚至更多,显然是无法让人接受的。不过mysql的设计者们显然先我们一步想到了这个问题,其提供了更方便的管理工具 ——— mysqld_multi 。
下面就结合mysql的多实例安装和mysqld_multi做个梳理总结。
一、安装和配置多个mysqld实例
首先以yum -y install mysql mysql-server mysql-devel完成安装。完装完成后,通过server mysqld start启动。我们便得到了第一个实例服务。接下来我们配置第二个实例:
mkdir -p /data/mysqldata
cd /data
chown -R mysql:mysql mysqldata
mysql_install_db --defaults-file=/data/mysqldata/my.cnf --datadir=/data/mysqldata
假设第二个实例的数据文件保存的位置为/data/mysqldata ,可以通过mysql_install_db完成初如化数据。此时我们可以通过以下方式分别启动两个实例:
mysqld_safe --defaults-file=/etc/my.cnf --datadir=$datadir --pid-file=$server_pid_file $other_args >/dev/null 2>&1 &
启动完成后,分别通过my.cnf修改相应参数文件的位置(下面会提到,在此不细说)。再通过mysql命令进行连接,看下是否能正常进行连接。两个都可以正常连接后,进行下一步——mysqld_multi管理。
注:按以上方式设置后,本机通过mysql命令进行连接时会受到影响,需要通过-S选项指定socket文件的位置,而其他主机连接不受影响。如:
mysql -uroot -p -S /var/lib/mysql/mysql3306.sock //可正常连接(本机)
mysql -h192.168.10.24 -uroot -p //远程26主机可正常连接(远程,未指定socket文件)
而本机不加-S选项指接进行连接时会有下面的提示:
[root@localhost mysqldata]# mysql -uroot -p
Enter password:
ERROR 2002 (HY000): Can't connect to local MySQL server through socket '/var/lib/mysql/mysql.sock' (2)
二、mysqld_multi管理多实例
配置mysqld_multi配置文件,以下我是以一个最小化的配置参数进行的配置,这个配置文件和单实例下的my.cnf没多大的区别。如果想设置两个实例里的内存设置,数据文件大小不同,可以在相应的mysqld下增加相应的配置就行了。
[mysqld_multi]
mysqld=/usr/bin/mysqld_safe
mysqladmin=/usr/bin/mysqladmin
user=mysql
log=/data/multi.log
[mysqld1]
port = 3306
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql3306.sock
user=mysql
pid-file=/var/lib/mysql/mysql.pid
log=/var/log/mysqld.log
[mysqld3307]
port = 3307
datadir=/data/mysqldata
socket=/data/mysqldata/mysql3307.sock
user=mysql
pid-file=/data/mysqldata/mysql/mysql.pid
log=/data/mysqldata/mysqld.log
mysqld_multi默认读取的配置文件是/etc/my.cnf ,当然也可以指定到其他位置,在启动时通过 “ --config-file= ” 参数进行指定。
配置完上面的配置文件,就可以通过mysqld_multi进行管理了。
mysqld_multi --config-file=/etc/my.cnf start 1 启动实例1 //配置文件的位置为/etc/my.cnf时,可以ith mysqld_multi --config-file=/etc/my.cnf stop 1 关闭实例1
mysqld_multi start 3307 启动实例3307
mysqld_multi stop 3307 关闭实例3307
由上面不难看出,其后面跟的参数1、3307是个配置文件中的mysqld后面跟的内容是一致的。如果配置的内容为mysqld1、mysqld2、mysqld3这样连续性的配置。也可以通过下面的方法批量启动和关闭:
mysqld_multi start 1-3 启动实例1、2、3
mysqld_multi stop 1-3 关闭实例1、2、3
注,按上面的配置进行mysqld_multi可以正常启动,但关闭时确无法正常关闭。我将上面的配置文件做了修改后发现可以正常关闭。
mysqladmin -uroot -p123456 -S /var/lib/mysql/mysql3306.sock shutdown
如上所示,其关闭原理是通过调用mysqladmin命令进行的关闭。
[mysqld_multi]
mysqld=/usr/bin/mysqld_safe
mysqladmin=/usr/bin/mysqladmin
user=root
password=123456
如果两个实例的root密码(mysql的密码,不是系统密码)相同时,可以通过上面的方式进行设置,如果不同,需要在mysqld_multi项里注释掉password项(相当于全局配置),在各实例里(有生效作用域的配置)添加相应的pasword密码。也可以通过下面的方式在各个实例里授权一个具有关闭数据库权限的用户。具上面配置用的root用户可以换成multi_admin,密码换成multipass 。
grant shutdown on *.* to multi_admin@'localhost' identified by 'multipass';
三、脚本化管理
通过./configure 源码包方式进行的安装。会在support-files目录里找到mysqld_multi.server脚本。其内容如下:
#!/bin/sh
#
# A simple startup script for mysqld_multi by Tim Smith and Jani Tolonen.
# This script assumes that my.cnf file exists either in /etc/my.cnf or
# /root/.my.cnf and has groups [mysqld_multi] and [mysqldN]. See the
# mysqld_multi documentation for detailed instructions.
#
# This script can be used as /etc/init.d/mysql.server
#
# Comments to support chkconfig on RedHat Linux
# chkconfig: 2345 64 36
# description: A very fast and reliable SQL database engine.
#
# Version 1.0
#
basedir=/usr/local/mysql
bindir=/usr/local/mysql/bin
if test -x $bindir/mysqld_multi
then
mysqld_multi="$bindir/mysqld_multi";
else
echo "Can't execute $bindir/mysqld_multi from dir $basedir";
exit;
fi
case "$1" in
'start' )
"$mysqld_multi" start $2
;;
'stop' )
"$mysqld_multi" stop $2
;;
'report' )
"$mysqld_multi" report $2
;;
'restart' )
"$mysqld_multi" stop $2
"$mysqld_multi" start $2
;;
*)
echo "Usage: $0 {start|stop|report|restart}" >&2
;;
esac
该脚本可以根据在使用中的实际情况进行更改后使用。
http://www.sohu.io/article/2678.html
表 读写 分离
一、 背景介绍
1.大数据量的存储需要大量的数据库资源;
2.数据量的不断增长要求数据库存储具有可扩展性;
3.在保证大数据量的情况下,要保证性能、高可用性等质量要求;
4.现有框架中没有彻底解决大数据量的存储问题;
5.Oracle等海量存储方案价格不菲,采用MySQL进行分库分表节约IT成本。
二、 可行性分析
1. 风险评估
1) DBA数据库管理的资源和规范要求;
2. 业务数据量规模和变化的影响
1) 对于事先可规划的中等以上数据规模,采用单库分表(一个数据库实例,分多张表)、读写分离、或者多库多表(多个数据库实例,多张表)可以满足业务需求,且相应设计和实现相对简单,不易出错。
2) 对于初期数据规模不可准确预知,但随着业务发展数据规模不断增长的系统,要求数据存储具有可扩展性。这种可扩展性通过分库分表解决,要求分库分表在路由上具有极强的伸缩性,这也是分库分表的难点,本方案提出一个循序渐进的实现路线逐步解决这个问题。
3. 技术积累
1) 公司已有简单的分库分表方案
2) 这个方案缺乏扩展性
3) 本方案将提出短期实现一定扩展性、中长期高可扩展性的方案
4. 开源或产品
1) 商业版数据库Sharding:MySQL Proxy,提供MySQL协议接口(非JDBC),主从结构,可以负载平衡,读写分离,failover等,lua语法复杂,不支持大数据量的分库分表;
2) Amoeba,支持分数据库实例,每个数据相同的表,不支持事务;类似MySQL Proxy,设计上抛弃lua,更简单;
3) 阿里集团研究院开源的CobarClient,主要面向小规模的数据库sharding集群访问,基于ibatis,需要规划数据规模,缺乏扩展性;另外有Cobar,阿里集团内部的一个完整DAL层,实现完整JDBC代理;
4) HibernateShards,Hibernate提供的sharding,支持分数据库实例,比较复杂,事先规划数据规模,和框架不符;
5) guzz,多库(虚拟的数据库,实际数据库的路由规则仍然自定义)、表分切、读写分离,以及多台数据库之间透明的分布式事务支持,设计目标是支持大型在线生产应用;需完全替换ibatis;完全和框架不符。
6) TDDL,淘宝的DAL,很强的分库分表能力,仍然需要数据量实现规划,动态扩展有限。
7) 以上某些产品在一定程度上可以满足我们的需求,但不能彻底解决我们大数据量可扩展的问题。
三、 性能指标
1. 和没有引入分库分表时相比,每次操作最大延迟<1ms;
四、 特性列表和RoadMap
1. 垂直分库,不同业务数据使用不同数据库实例存储
2. 数据切分:
a) 根据切分字段Hash取模;
b) 确定需要切分的数据,尽量将可能进行关联的分片数据放在一个数据库实例中,例如同一用户的基本信息、好友信息或者文件信息等;
3. 短期:分库分表
a) 数据库实例编号递增
b) 每个数据库内分表序号从1递增,不全局编号
c) 基于数据源(ibatis基础上)拦截建立访问层,应用感知
d) 应用需在底层进行数据源、分布式事务考虑和管理等
e) 可扩展性:只支持向上扩展,不支持收缩
4. 长期:数据库访问层
a) 建立灵活的数据切分和路由规则
b) 支持MySQL集群
c) 读写分离和负载均衡
d) 可用性探测
e) 分布式事务
f) 对应用透明
附录:


单库单表
单库单表是最常见的数据库设计,例如,有一张用户(user)表放在数据库db中,所有的用户都可以在db库中的user表中查到。
单库多表
随着用户数量的增加,user表的数据量会越来越大,当数据量达到一定程度的时候对user表的查询会渐渐的变慢,从而影响整个DB的性能。如果使用mysql, 还有一个更严重的问题是,当需要添加一列的时候,mysql会锁表,期间所有的读写操作只能等待。
可以通过某种方式将user进行水平的切分,产生两个表结构完全一样的user_0000,user_0001等表,user_0000 + user_0001 + …的数据刚好是一份完整的数据。
多库多表
随着数据量增加也许单台DB的存储空间不够,随着查询量的增加单台数据库服务器已经没办法支撑。这个时候可以再对数据库进行水平区分。
分库分表规则
设计表的时候需要确定此表按照什么样的规则进行分库分表。例如,当有新用户时,程序得确定将此用户信息添加到哪个表中;同理,当登录的时候我们得通过用户的账号找到数据库中对应的记录,所有的这些都需要按照某一规则进行。
路由
通过分库分表规则查找到对应的表和库的过程。如分库分表的规则是user_id mod 4的方式,当用户新注册了一个账号,账号id的123,我们可以通过id mod 4的方式确定此账号应该保存到User_0003表中。当用户123登录的时候,我们通过123 mod 4后确定记录在User_0003中。
分库分表产生的问题,及注意事项
1. 分库分表维度的问题
假如用户购买了商品,需 要将交易记录保存取来,如果按照用户的纬度分表,则每个用户的交易记录都保存在同一表中,所以很快很方便的查找到某用户的购买情况,但是某商品被购买的情 况则很有可能分布在多张表中,查找起来比较麻烦。反之,按照商品维度分表,可以很方便的查找到此商品的购买情况,但要查找到买人的交易记录比较麻烦。
所以常见的解决方式有:
a.通过扫表的方式解决,此方法基本不可能,效率太低了。
b.记录两份数据,一份按照用户纬度分表,一份按照商品维度分表。
c.通过搜索引擎解决,但如果实时性要求很高,又得关系到实时搜索。
2. 联合查询的问题
联合查询基本不可能,因为关联的表有可能不在同一数据库中。
3. 避免跨库事务
避免在一个事务中修改db0中的表的时候同时修改db1中的表,一个是操作起来更复杂,效率也会有一定影响。
4. 尽量把同一组数据放到同一DB服务器上
例如将卖家a的商品和交易信息都放到db0中,当db1挂了的时候,卖家a相关的东西可以正常使用。也就是说避免数据库中的数据依赖另一数据库中的数据。
一主多备
在实际的应用中,绝大部分情况都是读远大于写。Mysql提供了读写分离的机制,所有的写操作都必须对应到Master,读操作可以在Master和Slave机器上进行,Slave与Master的结构完全一样,一个Master可以有多个Slave,甚至Slave下还可以挂Slave,通过此方式可以有效的提高DB集群的QPS.
所有的写操作都是先在Master上操作,然后同步更新到Slave上,所以从Master同步到Slave机器有一定的延迟,当系统很繁忙的时候,延迟问题会更加严重,Slave机器数量的增加也会使这个问题更加严重。
此外,可以看出Master是集群的瓶颈,当写操作过多,会严重影响到Master的稳定性,如果Master挂掉,整个集群都将不能正常工作。
所以,1. 当读压力很大的时候,可以考虑添加Slave机器的分式解决,但是当Slave机器达到一定的数量就得考虑分库了。 2. 当写压力很大的时候,就必须得进行分库操作。
另外,可能会因为种种原因,集群中的数据库硬件配置等会不一样,某些性能高,某些性能低,这个时候可以通过程序控制每台机器读写的比重,达到负载均衡。
转载:http://blog.csdn.net/doliu6/article/details/7321255
http://www.blogjava.net/happyenjoylife/archive/2011/05/13/350177.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号