redis内存模型
一、概述
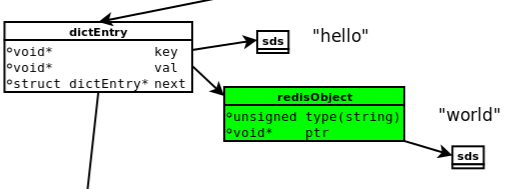
(1)dictEntry:Redis是Key-Value数据库,因此对每个键值对都会有一个dictEntry,里面存储了指向Key和Value的指针;next指向下一个dictEntry,与本Key-Value无关。
(2)Key:图中右上角可见,Key(”hello”)并不是直接以字符串存储,而是存储在SDS结构中。
struct sdshdr { int len; int free; char buf[]; };
一个SDS结构占据的空间为:free所占长度+len所占长度+ buf数组的长度=4+4+free+len+1=free+len+9。
(3)redisObject:Value(“world”)既不是直接以字符串存储,也不是像Key一样直接存储在SDS中,而是存储在redisObject中。实际上,不论Value是5种类型的哪一种,都是通过redisObject来存储的;而redisObject中的type字段指明了Value对象的类型,ptr字段则指向对象所在的地址。不过可以看出,字符串对象虽然经过了redisObject的包装,但仍然需要通过SDS存储。
typedef struct redisObject { unsigned type:4; unsigned encoding:4; unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */ int refcount; void *ptr; } robj;
redisObject的结构与对象类型、编码、内存回收、共享对象都有关系;一个redisObject对象的大小为16字节:4bit+4bit+24bit+4Byte+8Byte=16Byte。
内存分配器:内存分配器可以是 libc 、jemalloc或者tcmalloc,默认是jemalloc
二、Redis的对象类型与内部编码
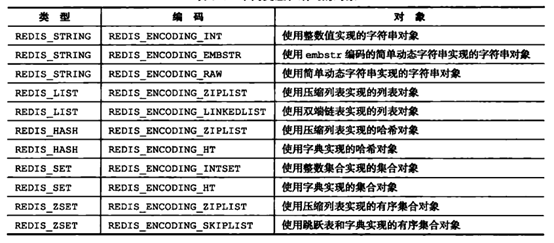
1、字符串
- int:8个字节的长整型。字符串值是整型时,这个值使用long整型表示。
- embstr:<=39字节的字符串。embstr与raw都使用redisObject和sds保存数据,区别在于,embstr的使用只分配一次内存空间(因此redisObject和sds是连续的),而raw需要分配两次内存空间(分别为redisObject和sds分配空间)。因此与raw相比,embstr的好处在于创建时少分配一次空间,删除时少释放一次空间,以及对象的所有数据连在一起,寻找方便。而embstr的坏处也很明显,如果字符串的长度增加需要重新分配内存时,整个redisObject和sds都需要重新分配空间,因此redis中的embstr实现为只读。
- raw:大于39个字节的字符串
2、list
列表的内部编码可以是压缩列表(ziplist)或双端链表(linkedlist)
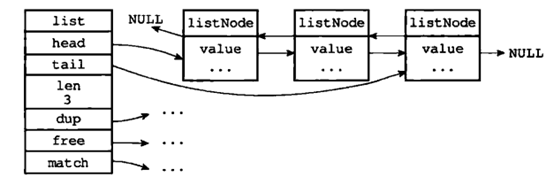
压缩列表:压缩列表是Redis为了节约内存而开发的,是由一系列特殊编码的连续内存块(而不是像双端链表一样每个节点是指针)组成的顺序型数据结构;具体结构相对比较复杂,略。与双端链表相比,压缩列表可以节省内存空间,但是进行修改或增删操作时,复杂度较高;因此当节点数量较少时,可以使用压缩列表;但是节点数量多时,还是使用双端链表划算。
列表中元素数量小于512个;列表中所有字符串对象都不足64字节。只能由ziplist转为linkedlist
3、hash
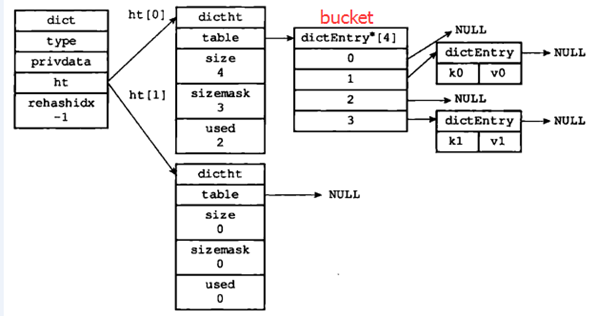
内部编码:压缩列表(ziplist)和哈希表(hashtable)
4、集合
集合的内部编码可以是整数集合(intset)或哈希表(hashtable)。
5、有序集合
有序集合的内部编码可以是压缩列表(ziplist)或跳跃表(skiplist)。
参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号