【11月12日】Hadoop架构
HDFS架构
HDFS采用主/从架构。HDFS群集由单个NameNode和多个DataNode组成。
简单一致性模型
HDFS应用程序需要文件的一写多读访问模式。文件一旦创建、写入和关闭,除了追加和截断外,不需要更改。支持将内容追加到文件末尾,但不能在任意位置更新。此假设简化了数据一致性问题,并实现了高吞吐量数据访问。MapReduce应用程序或Web爬虫应用程序非常适合此模型。
“移动计算比移动数据更划算”(“Moving Computation is Cheaper than Moving Data”)
NameNode and DataNodes
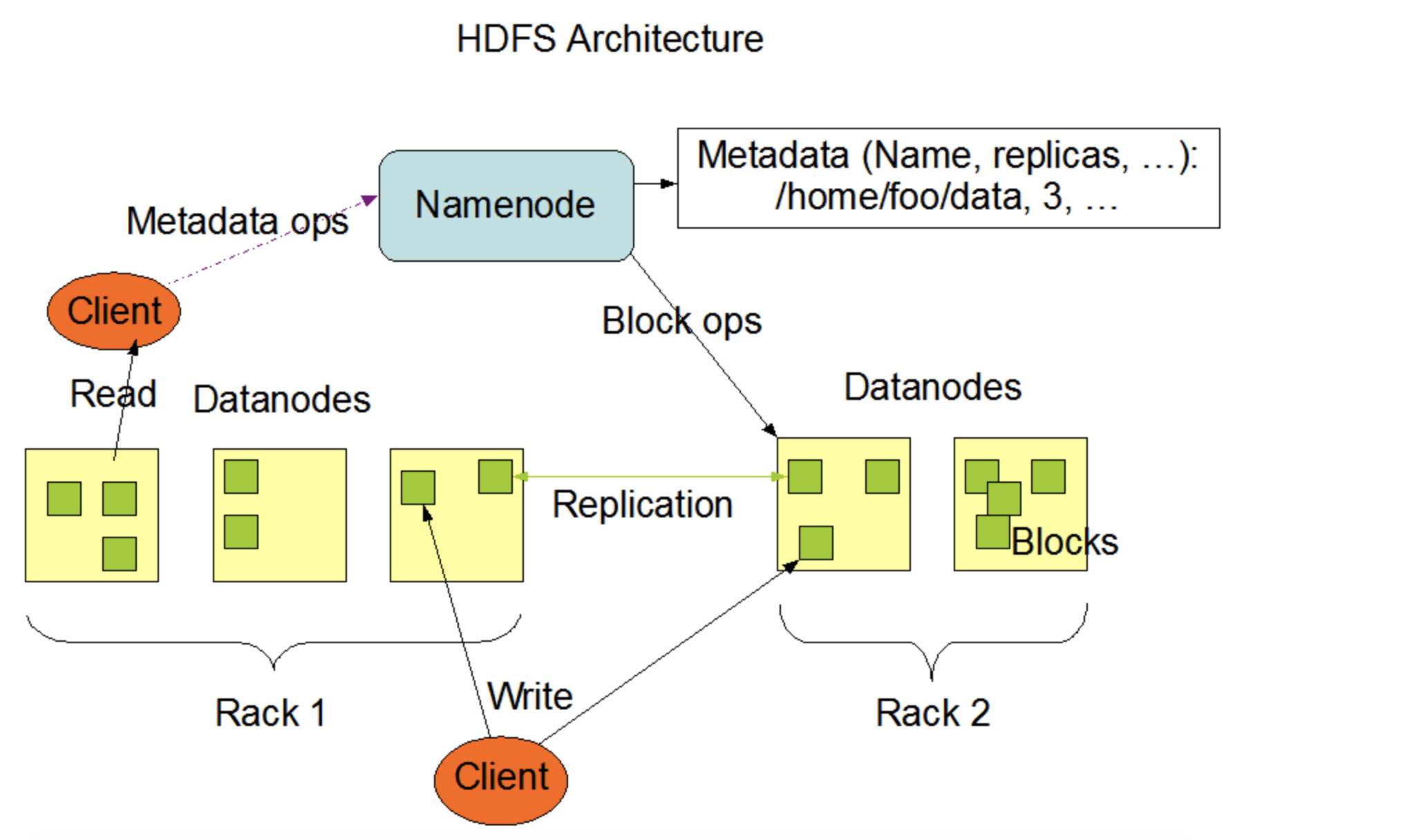
NameNode的职责:
- 控制客户端对文件的访问(客户端对文件的访问必须经过NN)
- NameNode执行文件系统命名空间 (namespace) 操作,如打开、关闭和重命名文件和目录
- 决定了块 (Data Block) 到DataNode的映射
DataNode的职责:
- 真正存储数据(Block)
- DataNode负责为客户端的读写请求提供服务
- DataNode还根据NameNode的指示执行块 (Data Block) 的创建、删除和复制
典型的部署有一台只运行NameNode软件的专用机器。集群中的每台其他机器都运行DataNode软件的一个实例。NameNode是所有HDFS元数据的仲裁器和存储库。系统的设计方式是用户数据永远不会流经NameNode。
The File System Namespace 文件系统命名空间
HDFS 也是目录树结构,根目录是 /
HDFS支持传统的分层文件组织。用户或应用程序可以创建目录并在这些目录中存储文件。文件系统命名空间层次结构类似于大多数其他现有文件系统;用户可以创建和删除文件、将文件从一个目录移动到另一个目录或重命名文件。HDFS支持用户配额和访问权限。HDFS不支持硬链接或软链接。但是,HDFS架构并不排除实施这些功能。
NameNode维护文件系统命名空间。对文件系统命名空间或其属性的任何更改都由NameNode记录。应用程序可以指定HDFS应该维护的文件副本数量。文件的副本数称为该文件的复制因子。此信息由NameNode存储。
Data Replication 数据副本
HDFS被设计用于在大型集群中跨机器可靠地存储非常大的文件。它以块序列的形式存储每个文件。复制文件的块是为了容错。块大小和复制因子可配置每个文件。
应用程序可以指定文件副本的数量。复制因子可以在文件创建时指定,以后可以更改。HDFS中的文件是一次性写的(除了追加和截断),并且在任何时候都严格只有一个writer。
NameNode负责所有与块复制有关的决策。它定期从集 群中的每个数据节点接收心跳和块报告。接收到心跳信号意味着DataNode正在正常工作。Blockreport包含 DataNode上所有块的列表。
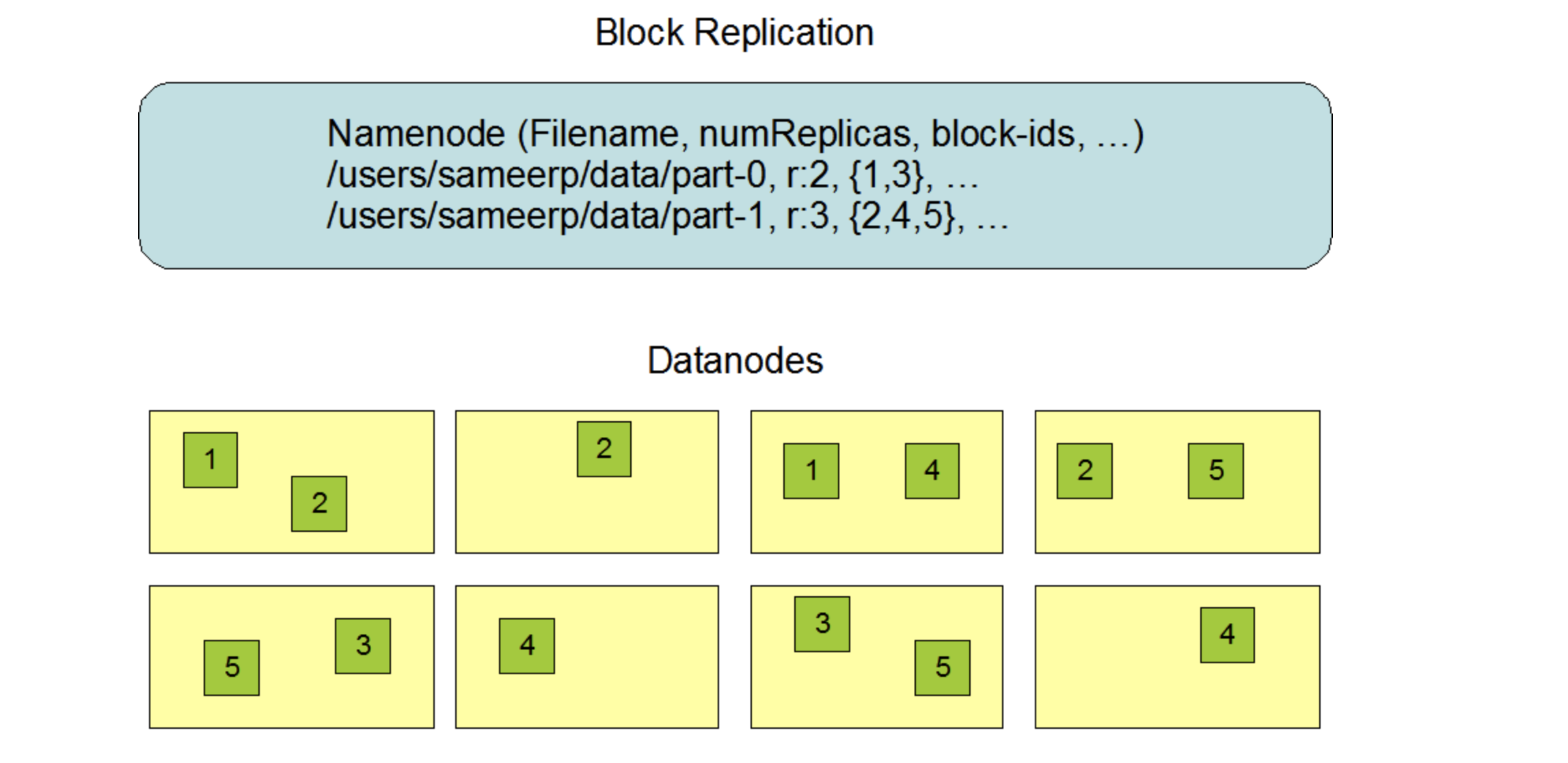
副本放置策略
支持机架的副本放置策略的目的是提高数据可靠性、可用性和网络带宽利用率。

副本的选择
原则: 就近原则
为了最小化全局带宽消耗和读取延迟,HDFS试图满足来自离读取器最近的副本的读取请求。如果在与reader节点相同的机架上存在一个副本,则首选该副本来满足读 请求。如果HDFS集群跨越多个数据中心,那么驻留在本 地数据中心的副本优于任何远程副本。
Safemode 安全模式
在启动时,NameNode进入一个称为Safemode的特殊状态。当NameNode处于Safemode状态时,不会发生数据块的复制。NameNode从数据节点接收心跳和 Blockreport消息。Blockreport包含DataNode托管的数据块列表。每个块都有一个指定的最小副本数量。当该数据块的最小副本数量( dfs.namenode.replication.min =1)已与 NameNode签入时,就认为该块是安全复制的。当安全复制的数据块的可配置百分比( dfs.namenode.safemode.threshold-pct =0.999f) 通过NameNode(加上额外的30秒)检查后, NameNode将退出安全模式状态。然后,它确定仍然少于指定副本数量的数据块列表(如果有的话)。然后 NameNode将这些块复制到其他数据节点。
Safemode模式开启时不能有写操作
Safemode的相关命令:
[hadoop@hadoop101 subdir0]$ hdfs dfsadmin [-safemode <enter | leave | get | wait>]
enter:#进入安全模式
leave:#退出安全模式
get:#获取安全模式的状态
如果NN的的存储空间不足也会进入安全模式。此时手 动是退不出安全模式。
The Persistence of File System Metadata 文件系统元数据的持久化
查看NN上editlog事务日志的命令:
[hadoop@hadoop101 current]$ hdfs oev -p XML -i edits_0000000000000000003-0000000000000000085 -o /home/hadoop/data/edit01.xml
查看NN上fsimage文件的命令:
[hadoop@hadoop101 current]$ hdfs oiv -p XML -i fsimage_0000000000000000085 -o /home/hadoop/data/image01.xml
我们发现内存中的元数据信息持久化成fsimage的时候,在fsimage中存储了目录树、副本数、文件和block的映射,但是没有block和DataNode的映射。为什么???
因为block和DataNode的映射根本就没有必要持久化。 NN中元数据信息存储的block和DataNode的映射是通 过DataNode定期向NN发送块报告得到了,只需要保存 在内存的元数据信息中即可。
注意:HDFS中一个block的元数据信息大约是150B。
所以HDFS不适合存储小文件。
checkpoint
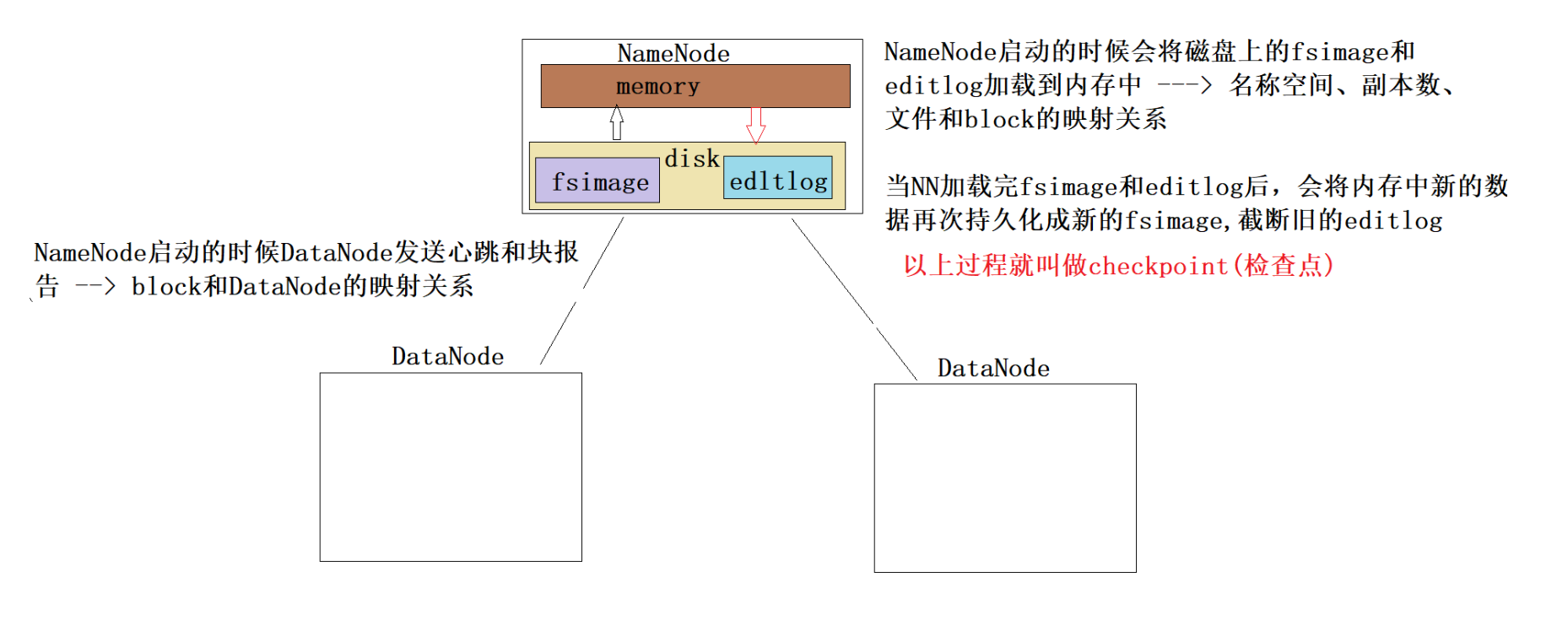
块报告
DataNode不了解HDFS文件。
当DataNode启动时,它会扫描它的本地文件系统,生成与每个本地文件对应的所有HDFS数据块的列表,并将该报告发送给NameNode: 这就是Blockreport。
SecondaryNameNode

配置2NN
vim hdfs-site.xml
<property>
<!--2NN位置-->
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop102:50090</value>
</property>
注意:
./hadoop-daemon.sh单启命令,你要在哪一个节点上启动哪一个进程,单启命令就必须在该节点上执行。sbin/start-dfs.sh hdfs集群的群起命令

 浙公网安备 33010602011771号
浙公网安备 33010602011771号