
2.安装Spark与Python练习
一、安装Spark
1.检查基础环境hadoop,jdk
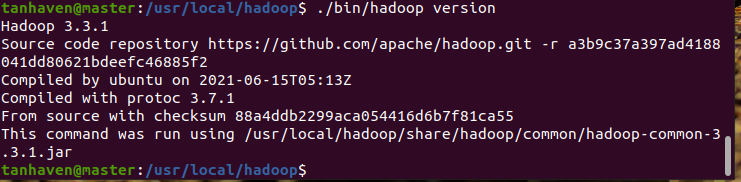
图一 Hadoop版本信息
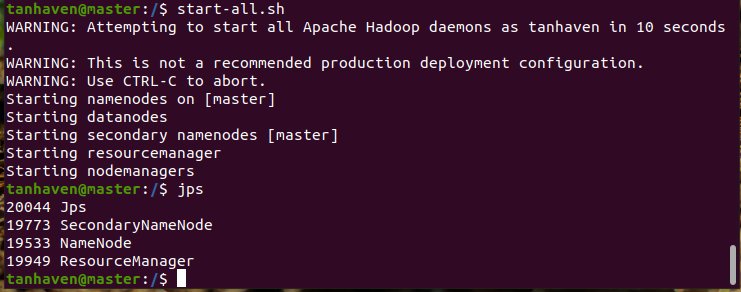
图二 Hadoop主节点master节点jps
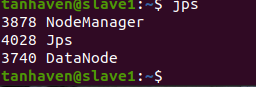
图三 Hadoop节点slave1 jps

图四 Java版本
2.下载spark
3.解压,文件夹重命名、权限
4.配置文件
5.环境变量
6.试运行Python代码
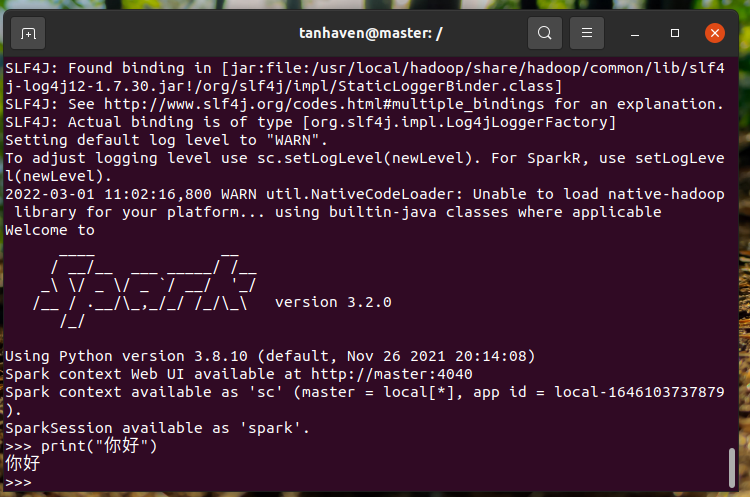
图五 运行pyspark命令
二、Python编程练习:英文文本的词频统计
- 准备文本文件
- 读文件
- 预处理:大小写,标点符号,停用词
- 分词
- 统计每个单词出现的次数
- 按词频大小排序
- 结果写文
path='D:\\english.txt'
with open(path) as f:
text=f.read()
words = text.split(" ")
wc={}
for word in words:
wc[word]=wc.get(word,0)+1
wclist=list(wc.items())
wclist.sort(key=lambda x:x[1],reverse=True)
print(wclist)
f = open('D:\\work.txt',"w")
f.write(str(wclist))
f.close()

图六 文件单词拆分输出
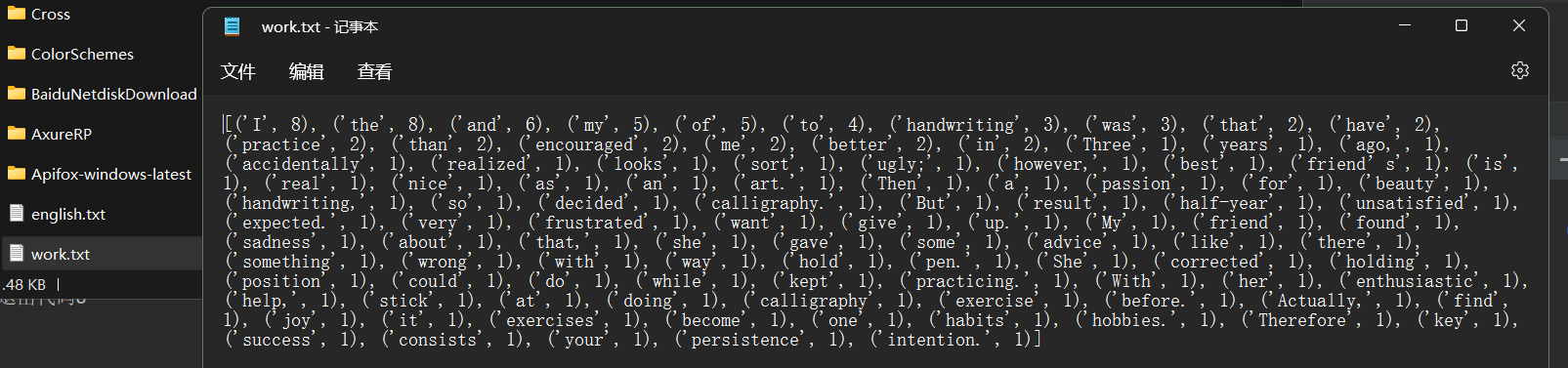
图七 结果写入文件
三、根据自己的编程习惯搭建编程环境(选做)
- 使用Jupyter Notebook调试PySpark程序:参考http://dblab.xmu.edu.cn/blog/2575-2/
- 使用PyCharm参考:Ubuntu 16.04 + PyCharm + spark 运行环境配置https://blog.csdn.net/zhurui_idea/article/details/72982598
三、根据自己的编程习惯搭建编程环境(选做)
- 使用Jupyter Notebook调试PySpark程序:参考http://dblab.xmu.edu.cn/blog/2575-2/
- 使用PyCharm参考:Ubuntu 16.04 + PyCharm + spark 运行环境配置https://blog.csdn.net/zhurui_idea/article/details/72982598
图八 下载pycharmLinux安装包
图九 下载py4j
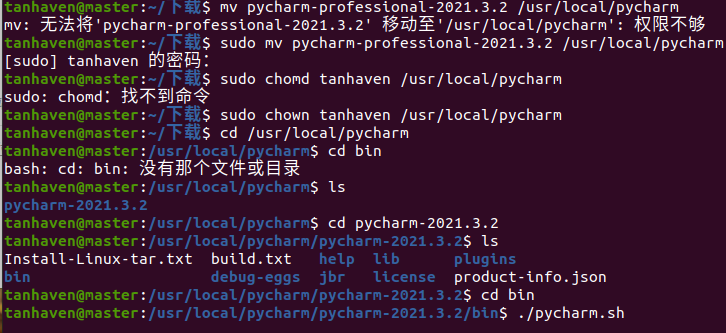
图十 安装pycharm
图十一 pycharm运行界面
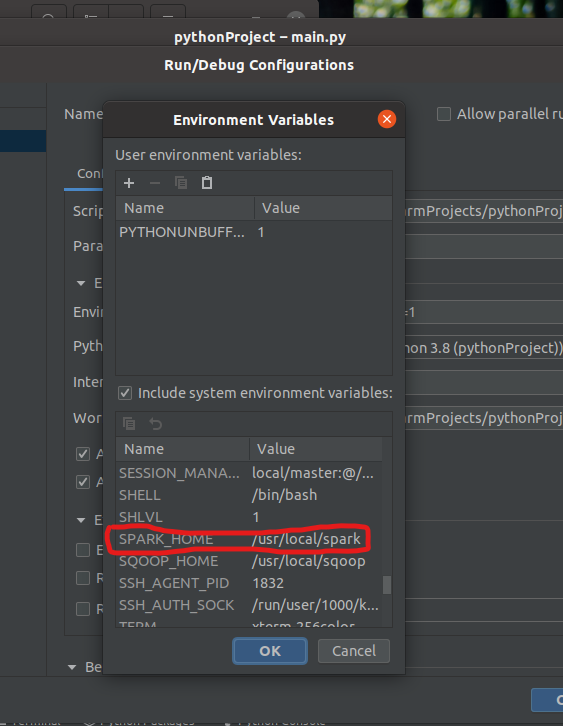
图十二 配置pycharmSpark环境

 浙公网安备 33010602011771号
浙公网安备 33010602011771号