
1.大数据概述
一、列举Hadoop生态的各个组件及其功能、以及各个组件之间的相互关系,以图呈现并加以文字描述。
Hadoop是一个由各个部件的构成的大数据分析处理的分布式框架软件。
其中,主要的核心是HDFS(Hadoop分布式文件系统)、mapreduce(分布式计算框架)、yarn(资源管理任务调度器)加上数据库管理组件(Hbase、Sqoop等)、数据分析引擎(Hive)构成一个比较完整的Hadoop生态体系。
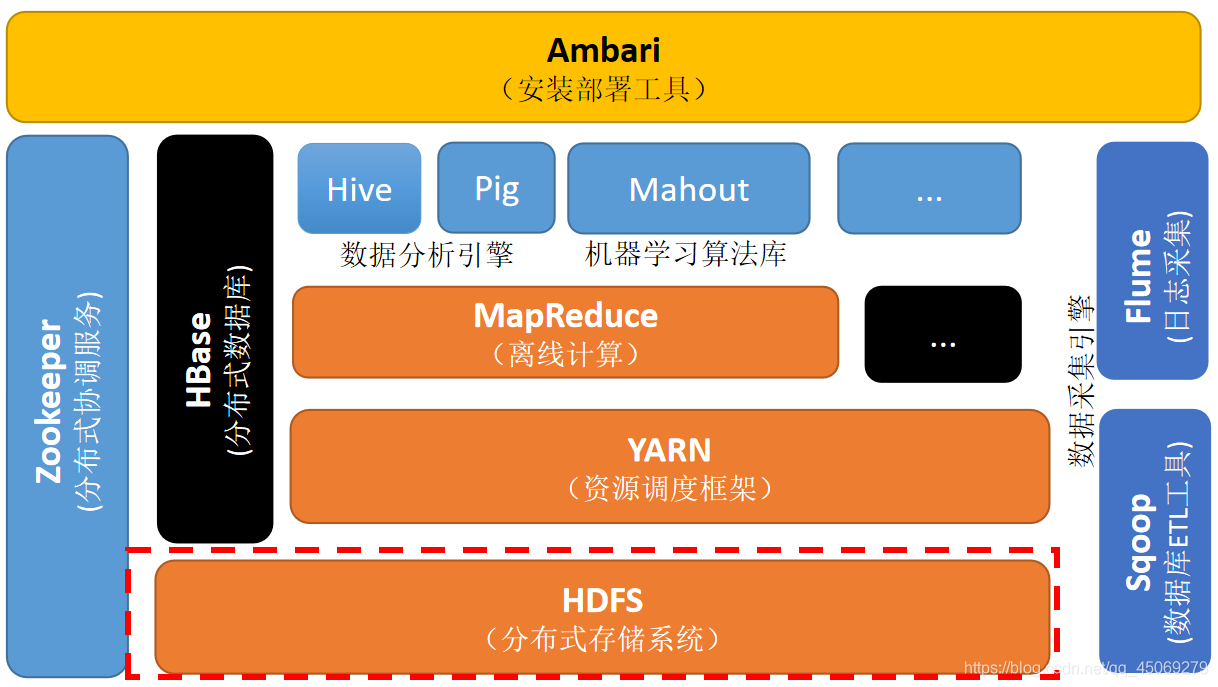
图1 Hadoop体系核心分布图
1、HDFS(Hadoop分布式文件系统)
HDFS是Hadoop生态体系中数据存储的的基础(与yarn不同,HDFS单单负责数据存储的管理,而yarn是负责Hadoop整个体系的资源调度),用HDFS可以访问namenode,与namenode进行交互获取所需文件所在的位置信息,然后用HDFS访问Datanode,与Datanode进行交互,进行数据的读写操作。
namenode是master节点,管理HDFS的名称空间和数据块映射信息,配置副本策略,处理客户端请求。
Datanode是salve节点,存储实际的数据,汇报存储信息给namenode。
在分布式的master节点主机上同时还存在secondary namenode,它有辅助namenode工作的用处,分担其工作量。例如:定期合并fsimage和fsedits,推送给namenode;紧急情况下和辅助恢复namenode,但其并非namenode的热备(热备:热备份,使namenode秒级恢复到一个时间点的状态)。
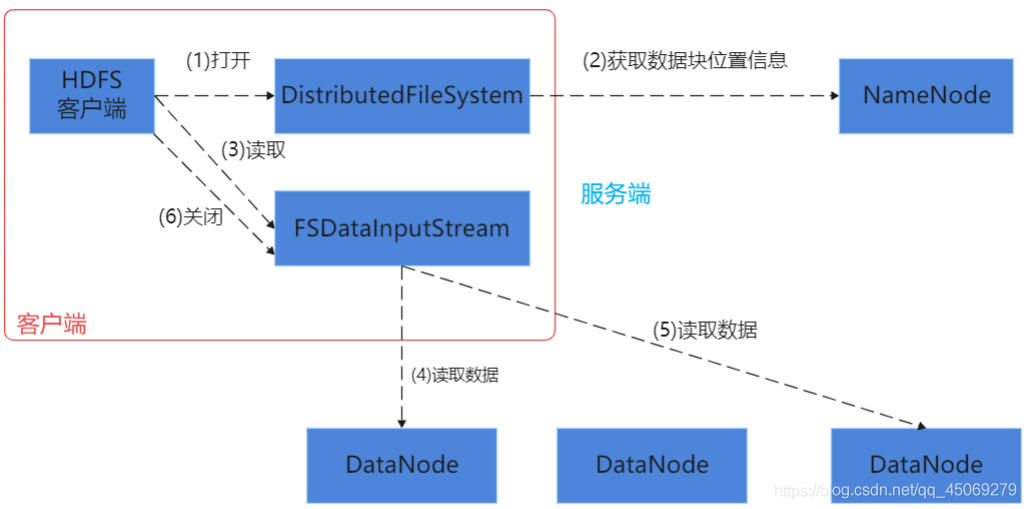
图2 HDFS读取文件过程
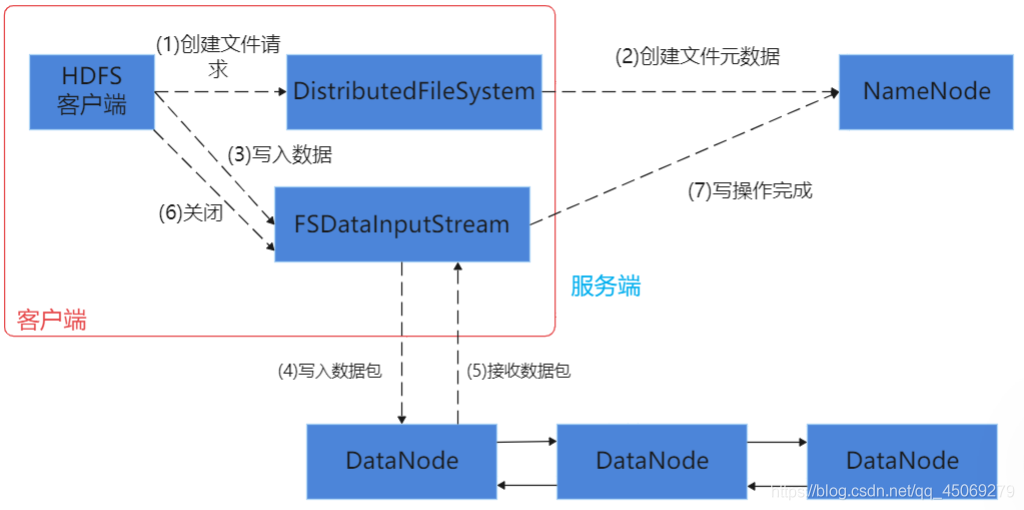
图3 HDFS写入过程
2、mapreduce(分布式计算框架)
mapreduce主体分为map( )和redeuce( )两个方法,map( )主要是把任务分解为各个没有依赖关系的小任务去进行,而reduce( )则是把map( )执行之后的所有结果进行合并。
mapreduce主要是以<k:v>键值对的方式去对数据进行处理,然后进行一个<k:v>键值对形式的输出。
mapreduce有两种运行模式,一种是本地运行模式,一种是集群运行模式。
本地运行模式主要适用于在开发环境模拟mapreduce执行环境,处理的数据输出结果都是在本地系统。而集群运行模式是把mapreduce程序打成jar包提交到yarn集群上去运行任务,其对数据的输出结果都是在HDFS文件系统中。
3、yarn(资源管理任务调度器)
yarn组件包括:
ResourceManager:资源管理
Application Master:任务调度
NodeManager:节点管理,负责任务执行
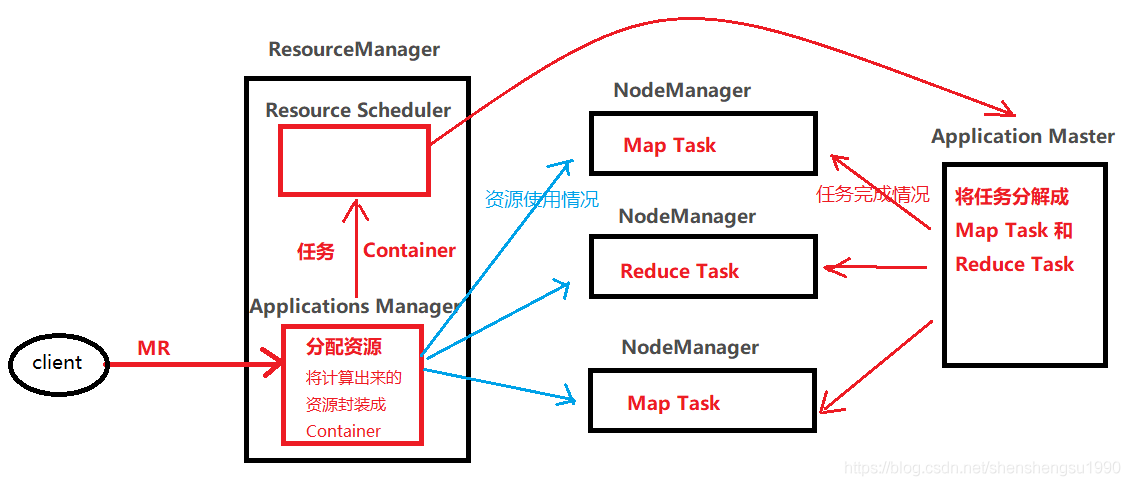
图4 yarn工作原理图
1.当用户向yarn提交一个mapreduce任务时,是由ResourceManager的Application Master接收
2.Application Master对任务进行一个资源分配的计算,然后封装成Container连同任务一起发送给Resourcfe Scheduler(资源调度器)
3.Resourcfe Scheduler将Container连同任务分给Application Master,由Application Master进行对任务的分解,分解成MapTask(map( ))和ReduceTask(reduce( )).
4.Application Master将分解好的MapTask和ReduceTask随机分配给NodeManager,由NodeManager负责执行接收到的Map Task或者ReduceTask
5.当任务执行成功时,NodeManager会把成功信息反馈给ApplicationManager和ApplicationMaster,然后ApplicationManager会对资源进行回收
6.当任务执行失败时,Node Manager同样会反馈失败信息给ApplicationManager和ApplicationMaster,由ApplicationManger进行资源回收,然后ApplicationMaster再次对ApplicationManager进行资源申请,重新执行任务,直到任务执行成功
7.ApplicationMaster会对Node Manager进行任务完成情况的监控,ApplicationManager会对Node Manager的资源使用情况进行监控
4、数据库管理组件(Hbase(分布式列式存储数据库)、Sqoop(数据同步工具)等)
Hbase数据库可以大致说是一个四维数据库,[列簇,行键,时间戳,<k,v>],其作为Hadoop体系的主要使用数据库是因为它存储数据量大,同时其中存储的数据可以用MapReduce任务进行处理
Sqoop则是可以对其他的一些流行但是不能够用MapReduce任务进行处理的数据库里面的数据进行处理,使其数据能够传输到Hadoop,然后进行Map Reduce任务操作
5、数据分析引擎(Hive)
当数据被Hadoop处理好输出结果时,我们就需要通过这个输出结果进行分析,得到一些我们想要的有价值的信息,Hive就是这样一款对数据输出结果进行分析的数据分析引擎
二、对比Hadoop和Spark的优缺点
1、Hadoop优点
1)能够按位存储和处理数据能力高
2)可通过集群的扩展去多分配数据给多个集群点,具有高度的可扩展性
3)能够在节点中动态的自主的进行数据的移动以及备份,保证每个节点的动态平衡,处理速度快,具有高效性
4)能够把数据的多个副本保存在不同的节点中,并且能够自动重新将失败的任务进行分配,具有很高的容错性
2、Hadoop的缺点
1)很难存储对量大文件小的数据
2)不适用低延迟数据访问
3)不支持多用户对文件的写入与修改
4)不支持直接SQL查询
3、Spark优点
1)基于内存的快速处理能力
2)可以使用多种语言对其进行操作,易操作性
3)支持SQL查询和HQL查询(面向对象查询,对大小写敏感),不需要像Hadoop那样用Sqoop去对SQL查询进行转化
4)支持流式计算,Spark Streaming
5)可用性高,支持独立部署(Master和Slave模式)也持支基于yarn的混合模式
6)支持大多数的数据源,HDFS、Hbase、Hive等
4、Spark缺点
1)不稳定,集群偶尔会挂,因为Spark是基于内存的,一但数据溢出内存就会导致集群挂掉
2)任务分配到集群节点的不均匀
3)自身的任务调度优化不好
三、如何实现Hadoop与Spark的统一部署?
Hadoop的主要核心组件里面包括yarn在内,同时Spark也能够支持基于yarn的混合模式进行一个部署,所以Hadoop可以与Spark统一部署到yarn上进行管理,进行一个优劣势互补的使用。比如Hadoop的Storm组件可以实现一个毫秒级别的响应,而Spark则不能够实现这样一个毫秒级的响应,这就是一个优劣势互补的表现。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号