

Python网络爬虫-淘宝信息爬取与解析
一、选题的背景
为什么要选择此选题?要达到的数据分析的预期目标是什么?(10 分)
从社会、经济、技术、数据来源等方面进行描述(200 字以内)
互联网时代下,网络购物已经风靡全球,网络购物蕴含巨大的商机,中国有句古话,‘知己知彼,方能百战不殆’,在信息网络时代对数据的有所分析是十分有经济效益的。本次实验我从淘宝网提取数据,通过Python语言进行网络爬虫分析消费者对某商品定价的接受范围,分析商品的发货地址可以了解原产地,通过对商品热词的搜索可以了解当下商家对客户需求的理解和客户对商品的附加属性的要求
二、主题式网络爬虫设计方案(10 分)
1.主题式网络爬虫名称
淘宝书包搜索的信息爬取与解析,URL='https://s.taobao.com/search?q=' + goods,goods是搜索内容,下面选取的是书包
,
2.主题式网络爬虫爬取的内容与数据特征分析
爬取的是淘宝的商品界面HTML网页,网页信息如下

通过对淘宝商品页面的观察发现商品的标题属性是raw_title,价格属性是view_price,付款人数属性是view_sales,发货地址属性是item_loc,本次实验仅提取4个属性内容
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
本次实验的思路是;首先查看淘宝的网页信息,查看robots协议是否网站允许可以爬取,利用python的request库进行网页信息获取,然后对信息进行筛选清洗操作,分析数据之间的广联性和特征,利用一些算法对数据进行了整理,然后利用一些可视化的工具进行展示。这是一个比较简单的爬虫,技术难点主要是是否能成功爬取页面信息
三、主题页面的结构特征分析(10 分)
1.主题页面的结构与特征分析
网页的结构如下,他是在html标签下的head标签下的script标签下的g_page_config字典下的一些关键词


2.Htmls 页面解析
先获取网页信息生成r.text文件,如下
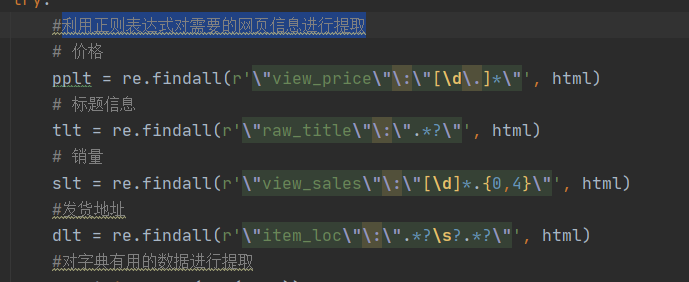
利用正则表达式对r.text文件中需要的属性进行信息提取解析,全部采用正则表达式来获取信息
3.节点(标签)查找方法与遍历方法 (必要时画出节点树结构)
节点比较简单在html标签下的head标签下的script标签的g_page_config字典,查找和遍历都是只需要进行自顶向下逐步提取即可
四、网络爬虫程序设计(60 分)
1 # --*-- coding:utf-8 --*-- 2 import requests 3 import re 4 import jieba 5 from matplotlib import pyplot as plt 6 from wordcloud import WordCloud 7 from PIL import Image 8 from openpyxl import Workbook 9 import pandas as pd 10 import seaborn as sns 11 from pylab import * 12 #解决seaborn中文显示问题 13 mpl.rcParams['font.sans-serif'] = ['SimHei'] 14 mpl.rcParams['axes.unicode_minus'] = False 15 import numpy as np 16 #加这句是防止jieba报错 17 jieba.setLogLevel(jieba.logging.INFO) 18 19 """ 20 第一部分:数据爬取与清洗处理 21 """ 22 #获取网页信息 23 def getHTMLText(url): 24 """ 25 cookie和user-agent的获取 26 cookie: 以火狐浏览器为例子 登录淘宝后 F12 -> 网络 -> cookie 27 user-agent: F12 -> 网络 -> 消息头 -> user-agent 28 """ 29 try: 30 h = { 31 'user-agent': 'Mduilla/5.0 (Wijlows ET 19.0; Win31; x68) AppleWbmKit/545.39 (KHTML, like Gecko) ' 32 'Chrome/74.0.3447.09 Safari/527.35', 33 'cookie': 'mt=ci%3D-1_0; miid=17408760223435249817; ' 34 'cna=LBVFFx64wA0CAXUaTVrFHYAf; thw=cn; ' 35 'UM_distinctid=171fdCFb9919$#6-02e6370f1f9988-d37VH66-14*&00-1^*fd5$^991aad4;' 36 ' hng=CN%7Czh-CN%7CCNY%7C156; t=c8d5b8e4au83540b9f1d89651cc7c3186; ' 37 'sgcookie=EeO9E%2FwgWC5au8Q5VMV0d; ' 38 'uc3=id2=UU8PaFVhyzoQfQ%3D%3D&nk2=BJMA0wtUMBQ%3D&lg2=U%2BGCWk%2F75gdr5Q%3D%3D&vt3=F8dB' 39 'xGPv6jNaK6AfgyI%hgc=genbus%5Ch5583; uc4=id4=0%40U287Bcj7JvSXznY2i%2Bj%gfV21hBadw&nk' 40 '4=0%40BpcYBaKiAr32ZEpB7RhudsaZCw%3D%3D; tracknick=genius%5Cu5583; _cc_=UIHiLt3xSw%3D%3D; ' 41 'enc=3l4nQJg7r52fI2znd1h9h%2BHTaI%2FBPKKkiFXVwD1cQdzAds3LtteSxeWW08j7Q3thzjidOKapR' 42 '%2FQtp5w%3Dwvmeci=-1_0; cookie2=105w2f755a5e5296b8324ead8efbe01c; _' 43 'tb_token_=f3385b508; _samesite_flag_=true; ' 44 'tfstkewHfBbqxeZbbdZON34KxYc62OZ437qIaxcbRoJU75NzifiVXURuSmsaX89u1..; ' 45 'v=0; tk_trace=oTRxwqWSB23n9dPyorMJE%2FoPdY8zfvmw%2FqhhorJivuy%2Bq%2Bov56yRDuM1G4jw2ss' 46 '7aqgnfvR9sfFt2zXGPgG%2B4t4it%2BDQMfnl%2Fk19qXlKFxgqfEgZqD3djuQucs0DHEvqcx9877JqD5' 47 '8uOoykmNvxoEAEs6aqqC7G0sGsnndZjihCAFi8um6tJx%2FYUGCSf2VJp8MgWoqQ8HGUc9rezUeaqH5EVAf%2' 48 'FPSmcq%2BKpora7IuKl1BxJoyYqTITjjhBexGpw4QZT7R%2FcUHh6ARVioGfylhtpynA%3bgr; lLtC1_=1; ' 49 'alitrackid=www.taobao.com; laflitrackid=www58obao.com; ' 50 '_m_h5_tk=6ade9ee0a399583f349c5e7fc53829_1595072067188; ' 51 '_m_h5_tk_enc=9cdec253c83ecb04d7c7818af12ff2f; JSESSIONID=3FC462CF563310838C9718367464A9; ' 52 'uc1=cookie14=Uofee21dGZ5GA%3D%3D; ' 53 'l=eBjyarvuQ3-ebwiABO^fsaurza77OFIRbzsPzaNfdhMiInhg66FsFs24Qq345dtjgtfYmFKrA67hR7S5ULREgKqe' 54 'lrgnspB42-; isg=BOzsK7f634tog15HcfYCughoepZBPdwlPkqs2Bc6UYe5ba7e30yncRlr456cin'} 55 r = requests.get(url, timeout=30, headers=h) 56 #状态码 200表示成功 57 r.raise_for_status() 58 r.encoding = r.apparent_encoding 59 return r.text 60 except: 61 return "" 62 63 #对网页的数据进行解析,提取想要的数据 64 def parsePage(ilt, html): 65 try: 66 #利用正则表达式对需要的网页信息进行提取 67 # 价格 68 pplt = re.findall(r'\"view_price\"\:\"[\d\.]*\"', html) 69 # 标题信息 70 tlt = re.findall(r'\"raw_title\"\:\".*?\"', html) 71 # 销量 72 slt = re.findall(r'\"view_sales\"\:\"[\d]*.{0,4}\"', html) 73 #发货地址 74 dlt = re.findall(r'\"item_loc\"\:\".*?\s?.*?\"', html) 75 #对字典有用的数据进行提取 76 for i in range(len(pplt)): 77 price = eval(pplt[i].split(':')[1]) 78 title = eval(tlt[i].split(':')[1]) 79 sale = slt[i].split(':')[1] 80 deliver = eval(dlt[i].split(':')[1]) 81 number = "" 82 #提取sale中的数字信息 83 for i in sale: 84 if ord(i) >= 48 and ord(i) <= 57: 85 number += i 86 ilt.append([price, number, deliver, title]) 87 except: 88 print("") 89 90 #对网页信息进行输出 91 def printGoodsList(ilt): 92 tpplt = "{:4}\t{:8}\t{:16}\t{:20}\t{:30}" 93 print(tpplt.format("序号", "价格", "销量", "发货地", "商品名称")) 94 count = 0 95 for g in ilt: 96 count = count + 1 97 print(tpplt.format(count, g[0], g[1], g[2], g[3])) 98 99 infoList = [] 100 def main(): 101 #这是搜索的内容goods 102 goods = '书包' 103 depth = 5 104 start_url = 'https://s.taobao.com/search?q=' + goods 105 for i in range(depth): 106 try: 107 url = start_url + '&s=' + str(44 * i) 108 html = getHTMLText(url) 109 parsePage(infoList, html) 110 except: 111 continue 112 printGoodsList(infoList) 113 114 print("--------------------爬取信息--------------------") 115 main()
下图是第一部分爬取的信息

1 """ 2 第二部分:jieba分词和wordcloud的分词可视化 3 """ 4 #对存放信息的数组利用jieba来分词处理 5 list1=[] 6 for i in range(len(infoList)): 7 j=jieba.lcut(infoList[i][-1]) 8 #除杂操作,对无用字符进行清洗 9 for part in j: 10 if part==' ' or '/' or '「' or'【' or '】' or'-': 11 j.remove(part) 12 list1.extend(j) 13 14 #将列表中的数据写入一个txt文本中 15 with open('d:/b.txt','w',encoding='gb18030') as f: 16 for i in list1: 17 w=str(i)+' ' 18 f.write(w) 19 20 #SimHei.ttf中文字体需要自己下载 21 font = r'D:\rooms\SimHei.ttf' 22 text = (open('D:\\b.txt', 'r',encoding='gb18030')).read() 23 # 打开图片 24 mg = Image.open('D:\\rooms'+ r'\pkq.png') 25 # 将图片装换为数组 26 img_array = np.array(mg) 27 # stopword = [] # 设置停止词,也就是你不想显示的词 28 w = WordCloud( 29 background_color='white', 30 width=1000, 31 height=800, 32 mask=img_array, 33 font_path=font, 34 # stopwords=stopword 35 ) 36 w.generate_from_text(text) # 绘制图片 37 plt.imshow(w) 38 plt.axis('off') 39 plt.show() # 显示图片 40 # 保存图片 可根据需要修改路径 41 w.to_file('d:/wordcloud1.png')
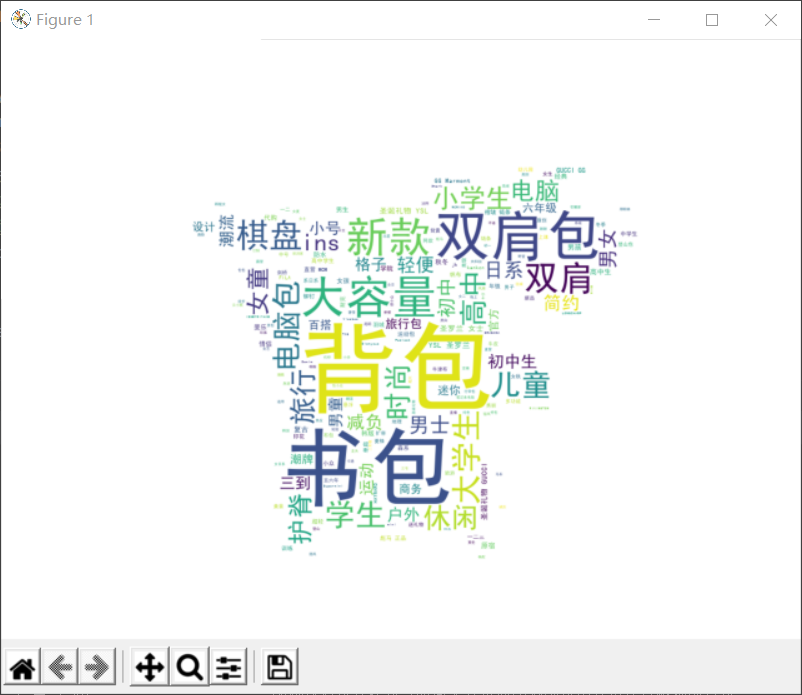
下面是第二部分以皮卡丘形状的词云
1 """ 2 第三部分:数据分析与可视化 3 """ 4 #分析价格分布 扇形图 5 n1=0 6 n2=0 7 n3=0 8 n4=0 9 n5=0 10 n6=0 11 n7=0 12 n8=0 13 n9=0 14 n10=0 15 for i in range(len(infoList)): 16 num=int(float(infoList[i][0])) 17 if 0<=num<30: 18 n1+=1 19 elif 30<=num<60: 20 n2+=1 21 elif 60<=num<90: 22 n3+=1 23 elif 90<=num<120: 24 n4+=1 25 elif 120<=num<150: 26 n5+=1 27 elif 150<=num<180: 28 n6+=1 29 elif 180<=num<210: 30 n7+=1 31 elif 210<=num<240: 32 n8+=1 33 elif 240<=num<300: 34 n9+=1 35 else: 36 n10+=1 37 # 用Matplotlib画饼图 38 nums=[n1,n2,n3,n4,n5,n6,n7,n8,n9,n10] 39 labels=["0-30","30-60","60-90","90-120","120-150","150-180","180-210","210-240","240-300","300up"] 40 plt.pie(x = nums, labels=labels) 41 plt.show() 42 43 #统计发货地的直方图 请放大查看 44 address=[] 45 #提取发货地的后面两个字 其实用正则更好 46 for i in range(len(infoList)): 47 pp=str(infoList[i][2][-2:-1]) 48 pp2=pp+infoList[i][2][-1] 49 address.append(pp2) 50 #去除重复的关键字 51 address2=set(address) 52 x=list(address2) 53 sx=' '.join(x) 54 y=[0 for i in range(len(x))] 55 mark1=0 56 #对关键字进行统计 57 for i in x: 58 n=0 59 for j in address: 60 if j==i: 61 n+=1 62 y[mark1]+=n 63 mark1+=1 64 # 用Seaborn画条形图 65 data=pd.DataFrame({ 66 'number':y, 67 'delivers':x}) 68 sns.barplot(x="delivers", 69 y="number", 70 data=data) 71 plt.show()
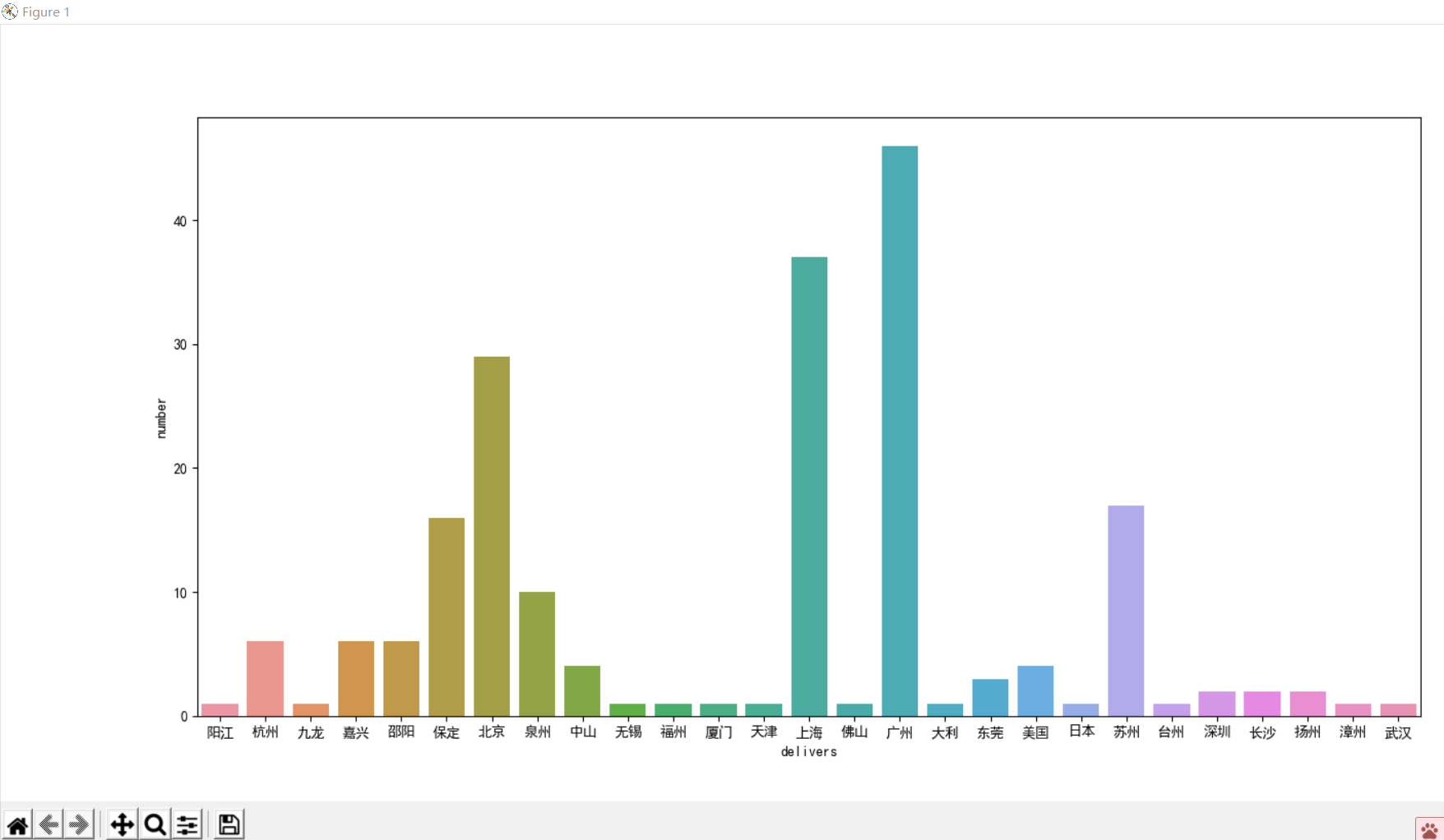
下图是第三部分数据分析与可视化的圆盘图和直方图

1 #关于销量和价格的散点图 2 N =len(infoList) 3 x=[] 4 y=[] 5 #提取价格和销量信息 6 for i in range(len(infoList)): 7 x1=int(float(infoList[i][0])) 8 y1=int(infoList[i][1]) 9 x.append(x1) 10 y.append(y1) 11 # 用Matplotlib画散点图 12 plt.scatter(x, y,marker='x') 13 plt.show()
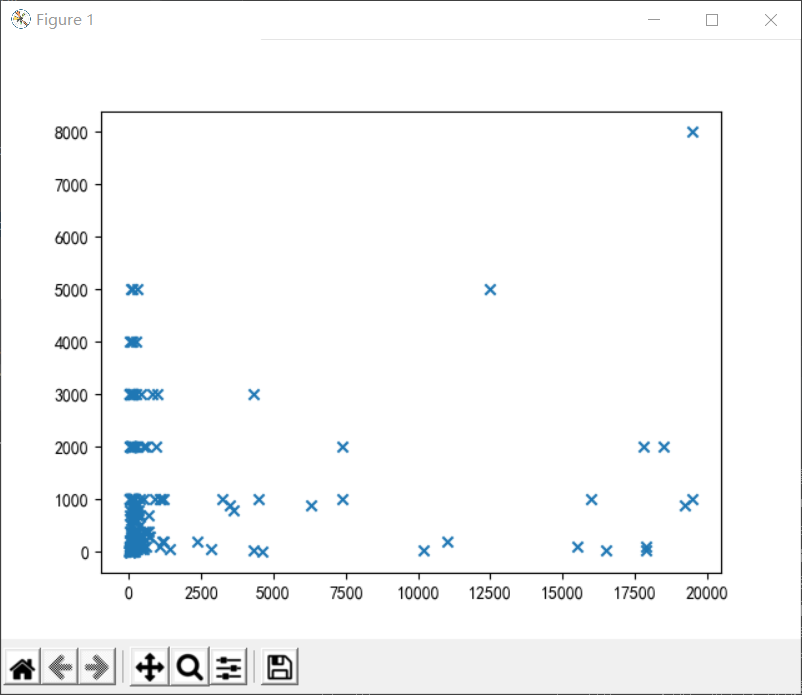
下图是第三部分数据关系的散点图
1 """ 2 第四部分:数据持久化 将数据写入Excel文件中 3 """ 4 mybook = Workbook() 5 wa = mybook.active 6 for i in infoList: 7 wa.append(i) 8 #文件地址自己在save()里改 9 mybook.save('d://ff.xlsx')
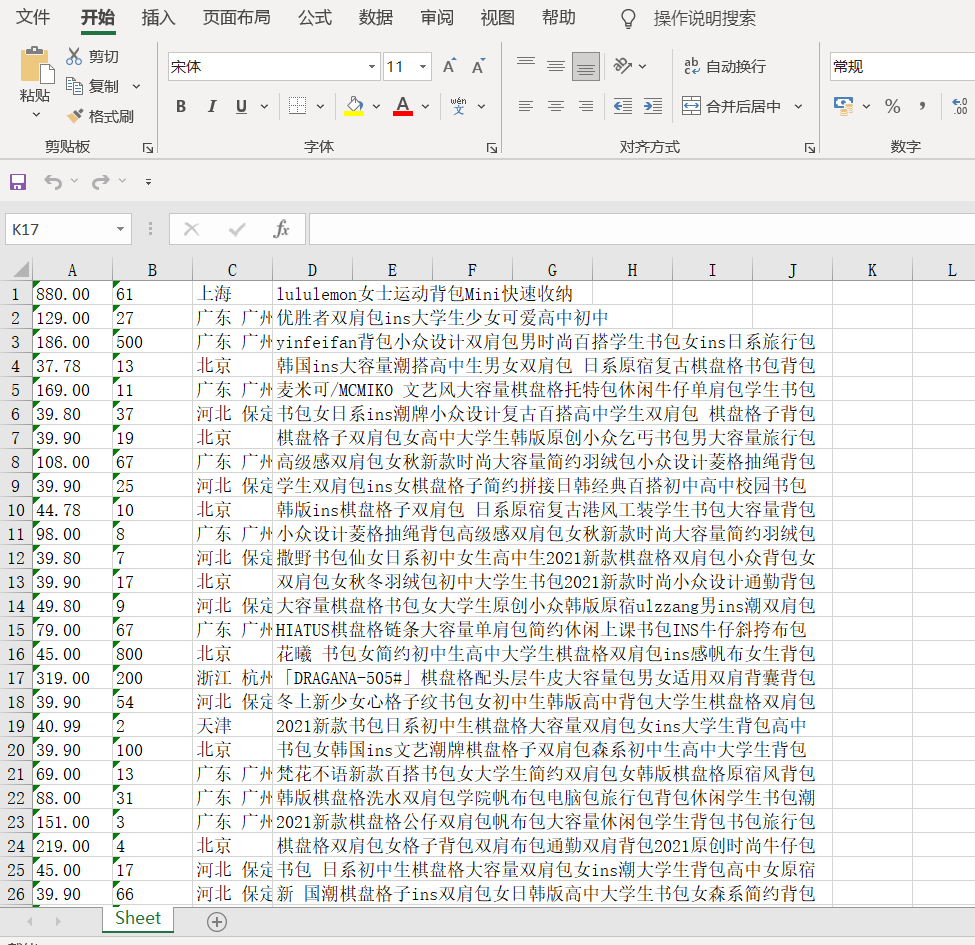
下图是第四部分的数据持久化的图片
下面是项目的完整代码
1 # --*-- coding:utf-8 --*-- 2 import requests 3 import re 4 import jieba 5 from matplotlib import pyplot as plt 6 from wordcloud import WordCloud 7 from PIL import Image 8 from openpyxl import Workbook 9 import pandas as pd 10 import seaborn as sns 11 from pylab import * 12 #解决seaborn中文显示问题 13 mpl.rcParams['font.sans-serif'] = ['SimHei'] 14 mpl.rcParams['axes.unicode_minus'] = False 15 import numpy as np 16 #加这句是防止jieba报错 17 jieba.setLogLevel(jieba.logging.INFO) 18 19 """ 20 第一部分:数据爬取与清洗处理 21 """ 22 #获取网页信息 23 def getHTMLText(url): 24 """ 25 cookie和user-agent的获取 26 cookie: 以火狐浏览器为例子 登录淘宝后 F12 -> 网络 -> cookie 27 user-agent: F12 -> 网络 -> 消息头 -> user-agent 28 """ 29 try: 30 h = { 31 'user-agent': 'Mduilla/5.0 (Wijlows ET 19.0; Win31; x68) AppleWbmKit/545.39 (KHTML, like Gecko) ' 32 'Chrome/74.0.3447.09 Safari/527.35', 33 'cookie': 'mt=ci%3D-1_0; miid=17408760223435249817; ' 34 'cna=LBVFFx64wA0CAXUaTVrFHYAf; thw=cn; ' 35 'UM_distinctid=171fdCFb9919$#6-02e6370f1f9988-d37VH66-14*&00-1^*fd5$^991aad4;' 36 ' hng=CN%7Czh-CN%7CCNY%7C156; t=c8d5b8e4au83540b9f1d89651cc7c3186; ' 37 'sgcookie=EeO9E%2FwgWC5au8Q5VMV0d; ' 38 'uc3=id2=UU8PaFVhyzoQfQ%3D%3D&nk2=BJMA0wtUMBQ%3D&lg2=U%2BGCWk%2F75gdr5Q%3D%3D&vt3=F8dB' 39 'xGPv6jNaK6AfgyI%hgc=genbus%5Ch5583; uc4=id4=0%40U287Bcj7JvSXznY2i%2Bj%gfV21hBadw&nk' 40 '4=0%40BpcYBaKiAr32ZEpB7RhudsaZCw%3D%3D; tracknick=genius%5Cu5583; _cc_=UIHiLt3xSw%3D%3D; ' 41 'enc=3l4nQJg7r52fI2znd1h9h%2BHTaI%2FBPKKkiFXVwD1cQdzAds3LtteSxeWW08j7Q3thzjidOKapR' 42 '%2FQtp5w%3Dwvmeci=-1_0; cookie2=105w2f755a5e5296b8324ead8efbe01c; _' 43 'tb_token_=f3385b508; _samesite_flag_=true; ' 44 'tfstkewHfBbqxeZbbdZON34KxYc62OZ437qIaxcbRoJU75NzifiVXURuSmsaX89u1..; ' 45 'v=0; tk_trace=oTRxwqWSB23n9dPyorMJE%2FoPdY8zfvmw%2FqhhorJivuy%2Bq%2Bov56yRDuM1G4jw2ss' 46 '7aqgnfvR9sfFt2zXGPgG%2B4t4it%2BDQMfnl%2Fk19qXlKFxgqfEgZqD3djuQucs0DHEvqcx9877JqD5' 47 '8uOoykmNvxoEAEs6aqqC7G0sGsnndZjihCAFi8um6tJx%2FYUGCSf2VJp8MgWoqQ8HGUc9rezUeaqH5EVAf%2' 48 'FPSmcq%2BKpora7IuKl1BxJoyYqTITjjhBexGpw4QZT7R%2FcUHh6ARVioGfylhtpynA%3bgr; lLtC1_=1; ' 49 'alitrackid=www.taobao.com; laflitrackid=www58obao.com; ' 50 '_m_h5_tk=6ade9ee0a399583f349c5e7fc53829_1595072067188; ' 51 '_m_h5_tk_enc=9cdec253c83ecb04d7c7818af12ff2f; JSESSIONID=3FC462CF563310838C9718367464A9; ' 52 'uc1=cookie14=Uofee21dGZ5GA%3D%3D; ' 53 'l=eBjyarvuQ3-ebwiABO^fsaurza77OFIRbzsPzaNfdhMiInhg66FsFs24Qq345dtjgtfYmFKrA67hR7S5ULREgKqe' 54 'lrgnspB42-; isg=BOzsK7f634tog15HcfYCughoepZBPdwlPkqs2Bc6UYe5ba7e30yncRlr456cin'} 55 r = requests.get(url, timeout=30, headers=h) 56 #状态码 200表示成功 57 r.raise_for_status() 58 r.encoding = r.apparent_encoding 59 return r.text 60 except: 61 return "" 62 63 #对网页的数据进行解析,提取想要的数据 64 def parsePage(ilt, html): 65 try: 66 #利用正则表达式对需要的网页信息进行提取 67 # 价格 68 pplt = re.findall(r'\"view_price\"\:\"[\d\.]*\"', html) 69 # 标题信息 70 tlt = re.findall(r'\"raw_title\"\:\".*?\"', html) 71 # 销量 72 slt = re.findall(r'\"view_sales\"\:\"[\d]*.{0,4}\"', html) 73 #发货地址 74 dlt = re.findall(r'\"item_loc\"\:\".*?\s?.*?\"', html) 75 #对字典有用的数据进行提取 76 for i in range(len(pplt)): 77 price = eval(pplt[i].split(':')[1]) 78 title = eval(tlt[i].split(':')[1]) 79 sale = slt[i].split(':')[1] 80 deliver = eval(dlt[i].split(':')[1]) 81 number = "" 82 #提取sale中的数字信息 83 for i in sale: 84 if ord(i) >= 48 and ord(i) <= 57: 85 number += i 86 ilt.append([price, number, deliver, title]) 87 except: 88 print("") 89 90 #对网页信息进行输出 91 def printGoodsList(ilt): 92 tpplt = "{:4}\t{:8}\t{:16}\t{:20}\t{:30}" 93 print(tpplt.format("序号", "价格", "销量", "发货地", "商品名称")) 94 count = 0 95 for g in ilt: 96 count = count + 1 97 print(tpplt.format(count, g[0], g[1], g[2], g[3])) 98 99 infoList = [] 100 def main(): 101 #这是搜索的内容goods 102 goods = '书包' 103 depth = 5 104 start_url = 'https://s.taobao.com/search?q=' + goods 105 for i in range(depth): 106 try: 107 url = start_url + '&s=' + str(44 * i) 108 html = getHTMLText(url) 109 parsePage(infoList, html) 110 except: 111 continue 112 printGoodsList(infoList) 113 114 print("--------------------爬取信息--------------------") 115 main() 116 117 """ 118 第二部分:jieba分词和wordcloud的分词可视化 119 """ 120 #对存放信息的数组利用jieba来分词处理 121 list1=[] 122 for i in range(len(infoList)): 123 j=jieba.lcut(infoList[i][-1]) 124 #除杂操作,对无用字符进行清洗 125 for part in j: 126 if part==' ' or '/' or '「' or'【' or '】' or'-': 127 j.remove(part) 128 list1.extend(j) 129 130 #将列表中的数据写入一个txt文本中 131 with open('d:/b.txt','w',encoding='gb18030') as f: 132 for i in list1: 133 w=str(i)+' ' 134 f.write(w) 135 136 #SimHei.ttf中文字体需要自己下载 137 font = r'D:\rooms\SimHei.ttf' 138 text = (open('D:\\b.txt', 'r',encoding='gb18030')).read() 139 # 打开图片 140 mg = Image.open('D:\\rooms'+ r'\pkq.png') 141 # 将图片装换为数组 142 img_array = np.array(mg) 143 # stopword = [] # 设置停止词,也就是你不想显示的词 144 w = WordCloud( 145 background_color='white', 146 width=1000, 147 height=800, 148 mask=img_array, 149 font_path=font, 150 # stopwords=stopword 151 ) 152 w.generate_from_text(text) # 绘制图片 153 plt.imshow(w) 154 plt.axis('off') 155 plt.show() # 显示图片 156 # 保存图片 可根据需要修改路径 157 w.to_file('d:/wordcloud1.png') 158 159 """ 160 第三部分:数据分析与可视化 161 """ 162 #分析价格分布 扇形图 163 n1=0 164 n2=0 165 n3=0 166 n4=0 167 n5=0 168 n6=0 169 n7=0 170 n8=0 171 n9=0 172 n10=0 173 for i in range(len(infoList)): 174 num=int(float(infoList[i][0])) 175 if 0<=num<30: 176 n1+=1 177 elif 30<=num<60: 178 n2+=1 179 elif 60<=num<90: 180 n3+=1 181 elif 90<=num<120: 182 n4+=1 183 elif 120<=num<150: 184 n5+=1 185 elif 150<=num<180: 186 n6+=1 187 elif 180<=num<210: 188 n7+=1 189 elif 210<=num<240: 190 n8+=1 191 elif 240<=num<300: 192 n9+=1 193 else: 194 n10+=1 195 # 用Matplotlib画饼图 196 nums=[n1,n2,n3,n4,n5,n6,n7,n8,n9,n10] 197 labels=["0-30","30-60","60-90","90-120","120-150","150-180","180-210","210-240","240-300","300up"] 198 plt.pie(x = nums, labels=labels) 199 plt.show() 200 201 #关于销量和价格的散点图 202 N =len(infoList) 203 x=[] 204 y=[] 205 #提取价格和销量信息 206 for i in range(len(infoList)): 207 x1=int(float(infoList[i][0])) 208 y1=int(infoList[i][1]) 209 x.append(x1) 210 y.append(y1) 211 # 用Matplotlib画散点图 212 plt.scatter(x, y,marker='x') 213 plt.show() 214 215 #统计发货地的直方图 请放大查看 216 address=[] 217 #提取发货地的后面两个字 其实用正则更好 218 for i in range(len(infoList)): 219 pp=str(infoList[i][2][-2:-1]) 220 pp2=pp+infoList[i][2][-1] 221 address.append(pp2) 222 #去除重复的关键字 223 address2=set(address) 224 x=list(address2) 225 sx=' '.join(x) 226 y=[0 for i in range(len(x))] 227 mark1=0 228 #对关键字进行统计 229 for i in x: 230 n=0 231 for j in address: 232 if j==i: 233 n+=1 234 y[mark1]+=n 235 mark1+=1 236 # 用Seaborn画条形图 237 data=pd.DataFrame({ 238 'number':y, 239 'delivers':x}) 240 sns.barplot(x="delivers", 241 y="number", 242 data=data) 243 plt.show() 244 245 """ 246 第四部分:数据持久化 将数据写入Excel文件中 247 """ 248 mybook = Workbook() 249 wa = mybook.active 250 for i in infoList: 251 wa.append(i) 252 #文件地址自己在save()里改 253 mybook.save('d://ff.xlsx')
五、总结(10 分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?是否达到预期的目标?
通过热词可以了解到商家销售最多的是双肩包、电脑包,客户喜欢大容量、新款、双肩的书包,消费的主要面向群体是大学生、高中生、小学生。通过一些可视化数据分析图可以看出多数背包的价格在30-60和300以上,发货地多在在北京、上海、广州等的发达地区。散点图可以看出多数集中在售价不那么高的地方。已经达到了分析数据的目的,了解了商家的认定和用户的需求。
2.在完成此设计过程中,得到哪些收获?以及要改进的建议?
本次课程设计进一步了解了爬虫和数据分析可视化原理,需要改进的建议是获得更多数据进行分析能更加充分了解供需。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号