ToG-2文献阅读
核心思想:KG×Text的紧耦合RAG框架
一、研究背景与动机
问题1:现有RAG系统存在浅层检索的问题
- 文本检索(Text-based RAG)侧重语义相似度 → 忽略实体间结构关系。
- KG检索(KG-based RAG)结构清晰但信息稀疏、不足以支撑深层推理。
- 现有混合方法(如CoK, GraphRAG)是松耦合,信息互不增强,不能协同导航推理路径。
研究目标
ToG-2 旨在解决上述问题:提出一种图-文本紧耦合的混合RAG框架,实现面向复杂问题的深度、可信、多跳推理能力。
二、核心方法架构(整体流程)
ToG-2 = Graph + Text 的 Tight-coupling(双向增强)
总体流程图:
- 初始化:问题 → Topic Entities(实体识别+Topic Prune)
- 文档检索(文档增强图探索):
- 以当前实体为中心,提取上下文片段。
- LLM判断是否信息足够。
- 图搜索(图结构增强文档检索):
- 基于KG关系发现更多关联实体。
- 结合语境信息,评分裁剪,生成下一轮实体集合。
- 迭代上述步骤:逐步扩展路径、更新知识上下文,直到能回答问题或达到最大深度。
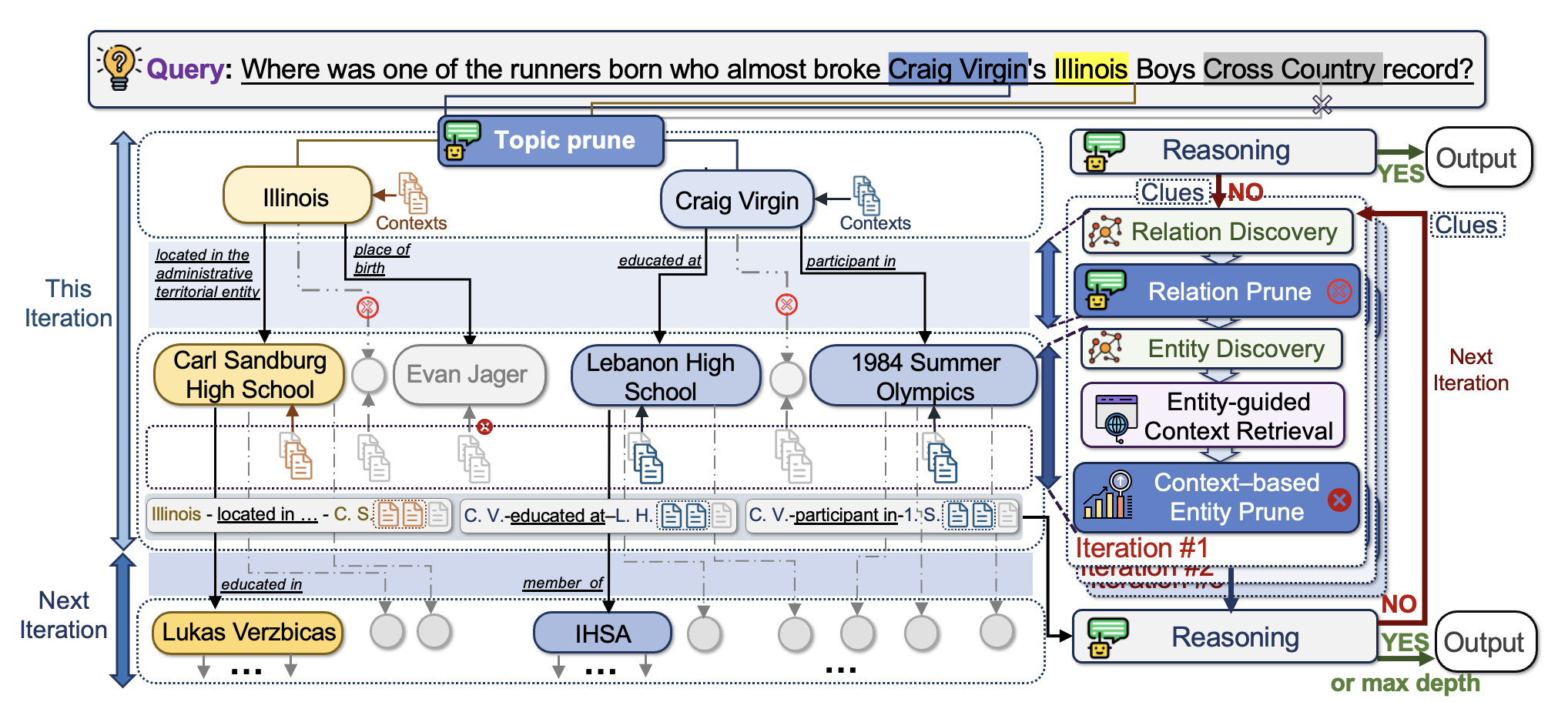
三、关键技术模块详解
1. Topic Entity Extraction & Pruning
- 使用 NER 和 Entity Linking(如 Azure AI)。
- 由 LLM 根据上下文判断哪些实体是“话题相关”的(即与问题直接相关)。
2. 图探索(Graph Retrieval)
Relation Discovery
- 找出所有与当前实体的出入边关系。
Relation Pruning
- 用 LLM 对所有边进行评分,选择可能指向有用实体的关系。
- 支持逐实体(低效)与统一处理(高效)两种模式。
Entity Discovery
- 根据被保留的关系从KG中检索相连实体。
3. 文档探索(Context Retrieval)
Context Collection
- 找到每个候选实体相关文档并切片为段落。
Relevance Scoring
- 使用DRM(如BGE-Reranker)+三元组句子 → 给段落打分。
Entity Pruning
- 按照实体上下文片段得分聚合结果裁剪,保留最相关的W个实体。
4. LLM推理模块
- 输入:所有检索出的KG路径 + 关联上下文。
- 若足够,输出答案。
- 否则,输出“Clues”并用来更新query,进入下一轮迭代。
四、算法伪代码概览
Algorithm ToG-2(q):
E0 ← topic entity extraction
Ctx0 ← 文档检索
if LLM(Ctx0)足够回答:
return answer
for i = 1 to D:
Ri ← LLM对所有实体关系打分 + 裁剪
Ci ← Entity Discovery
Ctxi ← 文档检索 + DRM打分
Ei+1 ← Context-based Entity Prune
if LLM(Pi, Ctxi, Clues)足够回答:
return answer
else:
Clues ← summarize hints
return failure or best-effort
五、实验设计与结果
1. 多任务评估(7个benchmark):
- WebQSP、QALD、AdvHotpotQA(多跳问答)
- FEVER, Creak(事实验证)
- Zero-Shot RE(关系抽取)
- ToG-FinQA(作者构建的新财报知识图谱)
2. SOTA表现
ToG-2 在6/7数据集上取得最佳:
- AdvHotpotQA:23.1% → 42.9%
- Zero-Shot RE:27.7% → 91.0%
- ToG-FinQA:0%(GPT原地答题) → 34.0%
3. 运行效率对比
- API调用数减少约70%(相较原始ToG)
- 实体裁剪用DRM代替LLM,速度提升约32%
六、消融实验与分析
模块重要性:
| 模块去除 | 性能下降幅度 |
|---|---|
| 无Topic Prune | 明显噪声上升(尤其是WebQSP) |
| 无Context Prune | 多余实体太多,路径混乱 |
| 无Clue Feedback | 下一轮难以收敛 |
Entity评分模型选择:
- 最佳:BGE-Reranker(兼顾准确率和效率)
- LLM-based评分虽强,但受输入长度限制、速度慢。
七、案例分析与能力来源分析
| 来源 | 占比 |
|---|---|
| Doc-enhanced Answer | 42% |
| Both-enhanced Answer | 32% |
| Triple-enhanced Answer | 10% |
| Direct Answer | 16% |
结论:文档信息是关键,KG用于导航,文本用于提供细节。
总结与启示
| 模块 | 功能 | 技术关键 |
|---|---|---|
| 实体抽取与Topic Prune | 找出核心话题实体 | NER + LLM打分 |
| KG检索 | 发现相关路径 | Relation Prune + Entity Discovery |
| 文档检索 | 补充细节语境 | BGE-Reranker |
| 多轮推理 | 判断是否完成 | PROMPTrs, Clues输出 |
| 结构融合 | KG+Text双向增强 | 迭代tight-coupling流程 |
优势总结
- 深度推理:上下文与结构信息双向互补,支持多跳逻辑链构建。
- 忠实回答:避免LLM幻觉,输出由可追踪知识证据支撑。
- 训练无关:无须训练,可直接接入任意LLM(GPT-3.5, LLaMA2, Qwen均验证)。
启发式价值
ToG-2 提供了一种通用、高效的“知识驱动+语言生成”协同范式,可被用于:
- 专业知识问答系统(如医疗、金融)
- 多跳图问答引擎开发
- 知识增强型agent(KIE+RAG+CoT)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号