Linux - 12 Shell(read、函数、正则、文本处理、cut、awk)
1)read 读取用户输入或
read 是 Shell 中读取用户输入或文件内容的核心命令,用法灵活,既能让脚本和用户交互(比如输入密码、参数),也能逐行读取文件(自动化运维常用)。以下是 read 的 核心用法+场景示例,新手也能快速上手:
核心语法(基础模板)
read [选项] 变量名1 变量名2 ...
# 或者
read [-ers] [-a aname] [-d delim] [-i text] [-n nchars] [-N nchars] [-p prompt] [-t timeout] [-u fd] [name ...]
- 无选项时:读取用户输入的一行内容,按空格/制表符分割,依次赋值给变量;多余内容全赋值给最后一个变量;
- 加选项时:实现特殊功能(如提示文字、超时、静默输入等);
- 变量名可省略:输入内容会默认存入内置变量
REPLY。
参数说明:
- -a 后跟一个变量,该变量会被认为是个数组,然后给其赋值,默认是以空格为分割符。
- -d 后面跟一个标志符,其实只有其后的第一个字符有用,作为结束的标志。
- -p 后面跟提示信息,即在输入前打印提示信息。
- -e 在输入的时候可以使用命令补全功能。
- -n 后跟一个数字,定义输入文本的长度,很实用。
- -r 屏蔽\,如果没有该选项,则\作为一个转义字符,有的话 \就是个正常的字符了。
- -s 安静模式,在输入字符时不再屏幕上显示,例如login时输入密码。
- -t 后面跟秒数,定义输入字符的等待时间。
- -u 后面跟fd,从文件描述符中读入,该文件描述符可以是exec新开启的。
最常用的 5 个选项(高频场景)
| 选项 | 作用(核心功能) | 适用场景 |
|---|---|---|
-p "提示文字" |
输入前显示提示信息(无需单独写 echo) |
交互输入(如输分数、用户名) |
-t 秒数 |
超时时间:超过指定秒数未输入,脚本继续执行 | 避免脚本一直等待用户输入 |
-s |
静默输入(不显示输入内容) | 输入密码、敏感信息 |
-n 字符数 |
读取指定个数的字符后自动结束(无需按回车) | 短输入(如选择 y/n、验证码) |
-r |
原样读取输入(不忽略反斜杠 \) |
读取含特殊字符的内容(如文件路径) |
6 个实用示例(覆盖日常场景)
示例1:基础交互输入(带提示文字 -p)
最常用场景:让用户输入内容,脚本接收后处理(搭配 -p 更友好)。
# 读取用户名和年龄(用空格分隔输入)
read -p "请输入你的姓名和年龄(空格分隔):" name age
echo "你好,$name!你今年 $age 岁了~"
运行效果:
请输入你的姓名和年龄(空格分隔):张三 25
你好,张三!你今年 25 岁了~
[root@node01 scripts]# ./read_test.sh tangge 11 # 不是后面跟参数
请输入你的姓名和年龄(空格分隔):tony 12
你好,tony!你今年 12 岁了~
- 若输入多个空格分隔的内容,多余部分会赋值给最后一个变量(如输入
张三 25 男,age=25 男); - 若只输入一个内容(如
张三),未赋值的变量(age)会为空。
示例2:静默输入密码(-s 隐藏输入)
输入密码时不显示明文,避免泄露(搭配 -p 提示)。
# 输入密码(静默模式,不显示输入内容)
read -p "请输入密码:" -s pwd
echo -e "\n" # 换行(因为 -s 会抑制回车的换行)
# 验证密码(简单示例)
if [[ "$pwd" == "123456" ]]; then
echo "密码正确,登录成功!"
else
echo "密码错误!"
fi
运行效果:
请输入密码: # 输入时不显示任何字符
密码正确,登录成功!
示例3:超时输入(-t 避免无限等待)
设置超时时间(如 5 秒),超时未输入则执行默认逻辑(适合自动化脚本)。
echo "请在 5 秒内输入 yes 确认操作(否则取消):"
if read -t 5 -r confirm; then # -t 5 超时5秒,-r 原样读取
if [[ "$confirm" == "yes" ]]; then
echo "已确认,执行操作..."
else
echo "输入不是 yes,取消操作!"
fi
else
echo -e "\n超时未输入,取消操作!"
fi
运行效果(5秒内未输入):
请在 5 秒内输入 yes 确认操作(否则取消):
超时未输入,取消操作!
示例4:读取固定字符数(-n 无需回车)
读取指定个数的字符后自动结束(无需按回车),适合短输入(如 y/n 选择)。
read -p "是否继续执行?(y/n):" -n 1 choice # -n 1 只读取1个字符
echo -e "\n" # 换行
case "$choice" in
y|Y) echo "继续执行..." ;;
n|N) echo "取消执行!" ;;
*) echo "无效输入,取消执行!" ;;
esac
运行效果:
是否继续执行?(y/n):y
继续执行...
- 输入
y后无需按回车,脚本直接继续执行。
示例5:逐行读取文件内容(搭配 while)
read 最核心的运维场景:逐行读取文件(如配置文件、日志文件),避免一次性加载大文件。
# 逐行读取 /etc/passwd 文件(系统用户配置)
echo "系统用户列表(用户名:登录Shell):"
while read -r line; do # -r 原样读取(避免反斜杠被解析)
# 提取用户名(第1列)和登录Shell(第7列),用 : 分隔
username=$(echo "$line" | cut -d ":" -f 1)
shell=$(echo "$line" | cut -d ":" -f 7)
echo "$username → $shell"
done < /etc/passwd # < 表示从文件读取输入(而非用户输入)
运行效果(部分输出):
系统用户列表(用户名:登录Shell):
root → /bin/bash
bin → /sbin/nologin
daemon → /sbin/nologin
...
示例6:读取含空格的输入(变量加双引号)
若输入内容含空格(如文件名 my file.txt),变量必须加双引号,否则会被分割。
read -p "请输入含空格的文件名:" filename
echo "你输入的文件名是:$filename" # 加双引号保留空格
运行效果:
请输入含空格的文件名:my file.txt
你输入的文件名是:my file.txt
必避的 3 个坑
-
变量不加双引号,含空格被分割:
❌ 错误:read filename; echo $filename(输入my file.txt会变成my file.txt但后续处理可能出错)
✅ 正确:echo "$filename"(加双引号,确保空格被保留)。 -
读取文件时未用
-r,反斜杠被忽略:
若文件内容含反斜杠\(如路径a\b.txt),不加-r会被解析为转义字符,导致内容错误,务必加-r。 -
超时输入未处理换行:
read -t超时后,终端光标会停留在当前行,用echo -e "\n"手动换行,优化用户体验。
2)函数
2.1 系统函数
basename 和 dirname 有什么区别?
| 命令 | 功能 | 示例输入 | 示例输出 |
|---|---|---|---|
basename |
提取路径最后部分 | /a/b/c.txt | c.txt |
dirname |
提取目录部分 | /a/b/c.txt | /a/b |
2.1.1 basename
basename 是 Linux 系统中一个简单但实用的命令行工具,用于从文件路径中提取文件名部分。它就像是一个路径解析器,能够剥离目录信息,只保留最后的文件名。
类比理解:想象你有一个完整的邮寄地址(如"中国/北京市/海淀区/中关村大街1号"),basename 的功能就是只提取最后的"中关村大街1号"部分。
basename 命令的基本语法
basename [选项] 路径 [后缀]
参数说明
- 路径(必需):要处理的完整路径字符串
- 后缀(可选):如果指定,会从结果中移除这个后缀
常用选项
| 选项 | 说明 |
|---|---|
-a |
支持多个路径作为参数 |
-s 后缀 |
移除指定的后缀(等同于在命令末尾加后缀参数) |
-z |
使用空字符分隔输出结果(而不是换行符) |
基础用法示例
示例1:基本文件名提取
$ basename /home/user/documents/report.txt
report.txt
示例2:移除文件扩展名
$ basename /home/user/documents/report.txt .txt
report
示例3:处理多个文件(使用 -a 选项)
$ basename -a /path/to/file1.txt /another/path/file2.log
file1.txt
file2.log
实际应用场景
场景1:批量处理文件扩展名
for file in *.jpg; do
mv "$file" "$(basename "$file" .jpg).png"
done
解释:这个脚本会将当前目录下所有 .jpg 文件重命名为 .png 文件,只修改扩展名而保留原文件名。
场景2:在脚本中获取当前脚本名称
*#!/bin/bash*
SCRIPT_NAME=$(basename "$0")
echo "正在运行脚本: $SCRIPT_NAME"
场景3:与 find 命令结合使用
find /var/log -name "*.log" -exec basename {} \;
作用:找出 /var/log 目录下所有 .log 文件并只显示文件名(不含路径)
2.1.2 dirname
dirname 是 Linux/Unix 系统中一个简单但实用的命令行工具,用于从文件路径中提取目录部分。它可以帮助你快速获取路径中的父目录,而无需手动解析字符串。
基本功能
- 输入:一个文件路径字符串
- 输出:该路径的目录部分(即去掉最后一个斜杠后的内容)
dirname [选项] 文件名...
参数说明
- 文件名:可以是一个或多个文件路径(支持绝对路径和相对路径)
- ...:表示可以同时处理多个文件路径
选项参数
虽然大多数情况下 dirname 不需要选项,但 GNU 版本支持以下标准选项:
| 选项 | 说明 |
|---|---|
-z |
使用 NUL 字符(\0)分隔输出,而不是换行符 |
使用示例
基础用法
$ dirname /home/user/docs/file.txt
/home/user/docs
$ dirname relative/path/to/file
relative/path/to
处理多个文件
$ dirname /a/b/c.txt /x/y/z.txt
/a/b
/x/y
特殊路径处理
$ dirname /usr/bin/ # 注意末尾斜杠
/usr
$ dirname file.txt # 只有文件名*
.
$ dirname / # 根目录
/
在脚本中使用
#!/bin/bash
# 获取脚本所在目录
SCRIPT_DIR=$(dirname "$0")
echo "脚本目录: $SCRIPT_DIR"
# 获取配置文件路径的目录
CONFIG_PATH="/etc/app/config.cfg"
CONFIG_DIR=$(dirname "$CONFIG_PATH")
echo "配置目录: $CONFIG_DIR"
常见应用场景
1. 获取脚本所在目录
#!/bin/bash
# 获取脚本所在绝对路径
SCRIPT_DIR=$(dirname "$(readlink -f "$0")")
echo "脚本所在目录: $SCRIPT_DIR"
2. 构建相对路径
*# 假设我们知道文件在某个目录的子目录中*
BASE_DIR="/var/log"
FULL_PATH="$BASE_DIR/app/error.log"
*# 获取日志目录*
LOG_DIR=$(dirname "$FULL_PATH")
3. 与 basename 配合使用
*# 分解完整路径*
FULL_PATH="/home/user/docs/report.pdf"
DIR=$(dirname "$FULL_PATH")
FILE=$(basename "$FULL_PATH")
echo "目录: $DIR"
echo "文件名: $FILE"
注意事项
符号链接:dirname 不会解析符号链接,如需解析,可结合 readlink 使用
dirname "$(readlink -f "/path/with/symlink")"bash
空格处理:路径包含空格时,确保使用引号
dirname "/path/with spaces/file.txt"
相对路径:输出结果会保持相对路径形式
$ dirname ../parent/file.txt
../parent
空输入:如果没有提供参数,GNU 版本会输出 ".",但这不是 POSIX 标准行为
2 自定义函数
Shell(Bash)中的函数是一组可复用的命令集合,能把重复执行的逻辑封装起来,让脚本更简洁、易维护、可复用。它和其他编程语言的函数类似,支持参数传递、返回值,还能控制脚本的逻辑结构,是编写复杂脚本的核心工具。
一、函数的3种定义方式
Bash函数有3种常用定义格式,可根据场景选择,核心逻辑一致:
# 格式1:标准格式(推荐,兼容性好)
函数名() {
函数体命令 # 要执行的逻辑
}
# 格式2:带 function 关键字(更直观,和其他语言风格接近)
function 函数名 {
函数体命令
}
# 格式3:单行格式(适合简单逻辑,命令间用 ; 分隔)
函数名() { 命令1; 命令2; }
⚠️ 注意:函数定义必须放在调用之前,否则Shell会识别为未定义命令。
二、基础用法:定义与调用
先定义函数,再通过「函数名」直接调用,最简单的示例如下:
#!/bin/bash
# 定义函数:输出欢迎信息
say_hello() {
echo "欢迎学习Shell函数!"
}
# 调用函数(直接写函数名)
say_hello
say_hello # 可多次调用
运行结果:
欢迎学习Shell函数!
欢迎学习Shell函数!
三、核心功能:传递参数给函数
Shell函数不支持显式的参数声明,而是通过位置参数接收外部传入的值,和脚本接收命令行参数的规则一致:
| 位置参数 | 含义 |
|---|---|
$1~$n |
函数的第1到第n个参数 |
$# |
函数接收的参数总个数 |
$*/$@ |
所有参数的集合 |
$0 |
脚本文件名(不是函数名,注意区分) |
示例:带参数的函数(计算两数之和)
#!/bin/bash
# 定义函数:计算两个整数的和
add() {
# 判断参数个数是否为2
if (( $# != 2 )); then
echo "错误:请传入2个整数!"
return 1 # 返回非0状态码,表示函数执行失败
fi
local sum=$(( $1 + $2 )) # local 定义局部变量,仅函数内生效
echo "两数之和:$sum"
}
# 调用函数,传入参数
add 10 20 # 传入2个参数,正常执行
add 5 # 传入1个参数,提示错误
运行结果:
两数之和:30
错误:请传入2个整数!
⚠️ 用 local 定义局部变量很重要,避免函数内变量覆盖脚本的全局变量。
四、函数的返回值
Shell函数没有像其他语言那样的“返回值”,而是通过两种方式反馈执行结果:
- 状态返回值:用
return 数字返回(0=成功,非0=失败),通过$?查看; - 结果输出值:用
echo输出结果,调用时通过变量=$(函数名)捕获。
示例:两种返回值用法
#!/bin/bash
# 方式1:状态返回值(判断数字是否为正数)
is_positive() {
if (( $1 > 0 )); then
return 0 # 是正数,返回成功状态码
else
return 1 # 非正数,返回失败状态码
fi
}
# 方式2:结果输出值(计算数字平方)
square() {
echo $(( $1 * $1 )) # 输出计算结果
}
# 测试状态返回值
is_positive 15
if (( $? == 0 )); then
echo "15 是正数"
fi
# 测试结果输出值(捕获echo输出)
result=$(square 8)
echo "8 的平方是:$result"
运行结果:
15 是正数
8 的平方是:64
五、进阶用法:函数嵌套
函数内部可以调用其他函数,实现复杂逻辑的分层,示例如下(计算1-n的累加和,嵌套实现):
#!/bin/bash
# 定义内层函数:加法
add() {
echo $(( $1 + $2 ))
}
# 定义外层函数:计算1到n的累加和
sum_from_1_to_n() {
local total=0
local n=$1
for ((i=1; i<=n; i++)); do
total=$(add $total $i) # 嵌套调用 add 函数
done
echo $total
}
# 调用函数
sum=$(sum_from_1_to_n 10)
echo "1-10的累加和:$sum" # 输出:55
六、实战:完整函数脚本(文件备份工具)
整合函数的参数传递、返回值、逻辑判断,编写一个实用的文件备份脚本:
#!/bin/bash
# 函数1:提示用法
usage() {
echo "用法:$0 要备份的文件路径 备份目录"
echo "示例:$0 /etc/nginx/nginx.conf /tmp/backup"
}
# 函数2:备份文件
backup_file() {
local src_file=$1
local backup_dir=$2
# 校验源文件是否存在
if [[ ! -f "$src_file" ]]; then
echo "错误:文件 $src_file 不存在!"
return 1
fi
# 校验备份目录,不存在则创建
if [[ ! -d "$backup_dir" ]]; then
echo "备份目录 $backup_dir 不存在,正在创建..."
mkdir -p "$backup_dir" || { echo "创建目录失败!"; return 1; }
fi
# 执行备份(添加时间戳避免覆盖)
local backup_name=$(basename "$src_file").$(date +%Y%m%d%H%M%S)
cp "$src_file" "$backup_dir/$backup_name"
echo "备份成功:$backup_dir/$backup_name"
return 0
}
# 主逻辑:判断参数个数
if (( $# != 2 )); then
usage # 调用用法提示函数
exit 1
fi
# 调用备份函数
backup_file "$1" "$2"
运行测试
# 给脚本加执行权限
chmod +x backup.sh
# 执行备份
./backup.sh /etc/hosts /tmp/backup
运行结果:
备份目录 /tmp/backup 不存在,正在创建...
备份成功:/tmp/backup/hosts.20250820153000
七、return 遇到的问题
#!/bin/bash
function add(){
let s=$1+$2;
return $s;
}
sum=$(add 5 10)
echo $sum
echo $?
echo $sum
echo $?
[root@node01 scripts]# ./func_test.sh
0
0
## 为什么结果不行没有值?
这个脚本输出全是 0 的核心原因是:完全混淆了 Shell 函数的「结果输出」和「状态返回值」,这是 Shell 函数最容易踩的坑!下面用通俗的语言拆解每一步原因:
先明确 2 个核心规则(关键前提)
Shell 函数和其他编程语言(如 Python/Java)的函数完全不同,没有“return 结果”的概念,只有两个核心机制:
- 结果输出:函数内用
echo打印的内容(会显示在终端),只有用变量=$(函数名)才能捕获; - 状态返回值:用
return 数字返回,仅表示“函数执行成功/失败”(0=成功,非0=失败),取值范围只能是0~255,且只能用$?捕获(只能获取上一条命令的状态)。
逐行拆解你的脚本为什么输出 0
1. 函数 add 的执行过程
function add(){
let s=$1+$2; # 计算 5+10=15,s=15
#echo "和:$s" # 注释了!没有任何输出到终端
return $s; # 试图用 return 返回 15,但这是错误的!
}
- 函数内没有
echo,所以没有任何“结果输出”; return $s中的15被当作「状态返回值」(而非计算结果),但状态返回值的意义是“成功/失败”,不是传递数据。
2. sum=$(add 5 10) 的捕获结果
$(函数名) 的作用是:捕获函数执行时输出到终端的所有内容(也就是 echo 的内容)。
- 你的
add函数没有echo,所以捕获到的是「空字符串」,因此sum=""(空变量)。
3. 四次输出的本质
echo $sum # 输出空变量 → 终端显示空白行(第一行输出)
echo $? # $? 是上一条命令(echo $sum)的状态码:echo 执行成功 → 返回 0(第二行输出 0)
echo $sum # 再次输出空变量 → 又一个空白行(第三行输出)
echo $? # 上一条命令(echo $sum)还是成功 → 再返回 0(第四行输出 0)
一句话总结核心错误
你以为 return $s 是“返回计算结果 15”,但 Shell 只把它当成“函数执行成功的状态码”;你以为 sum=$(add 5 10) 能捕获 return 的 15,但它只能捕获 echo 的内容(而你没写 echo),所以 sum 是空的;最后 echo $? 捕获的不是 return 15,而是 echo $sum 这个命令的成功状态码 0。
想要得到正确结果(输出 15),该怎么改?
有两种正确写法,按需选择:
写法 1:用 echo 输出结果(推荐,最常用)
核心:函数内用 echo 打印计算结果,外部用 sum=$(add 5 10) 捕获。
#!/bin/bash
function add(){
let s=$1+$2;
echo $s # 关键:用 echo 输出计算结果(会被 $(...) 捕获)
return 0; # 可选:显式返回 0 表示函数执行成功(默认也是 0)
}
sum=$(add 5 10) # 捕获 echo 的 15 → sum=15
echo $sum # 输出 15(第一行输出)
echo $? # 上一条 echo 的状态码 → 0(第二行输出)
echo $sum # 输出 15(第三行输出)
echo $? # 上一条 echo 的状态码 → 0(第四行输出)
运行结果:
15
0
15
0
写法 2:用 $? 捕获状态返回值(仅适合 0~255 的小数字)
如果确实想用车 return 传递数字(仅限 0~255),需要用 $? 捕获(且必须在函数执行后立即捕获):
#!/bin/bash
function add(){
let s=$1+$2;
return $s; # 返回 15(作为状态码,仅限 0~255)
}
add 5 10 # 执行函数(不捕获输出,因为没有 echo)
sum=$? # 立即用 $? 捕获 return 的 15 → sum=15
echo $sum # 输出 15
echo $? # 上一条 echo 的状态码 → 0
echo $sum # 输出 15
echo $? # 上一条 echo 的状态码 → 0
运行结果和上面一致,但注意:如果 s 超过 255(如 300),return $s 会取模(300%256=44),导致结果错误,所以这种写法仅适合小数字。
最终结论
- Shell 函数不能用
return返回计算结果,只能用echo输出,再用$(函数名)捕获; return仅用于表示“执行状态”(0=成功),$?仅用于判断上一条命令是否成功,不是获取函数计算结果;- 你的脚本因为没有
echo,导致sum为空,后续echo $?都是echo命令的成功状态码0,所以全输出0。
把函数内的 #echo "和:$s" 注释去掉(或改成 echo $s),就能得到正确的 15 了!
3)正则表达式 (grep | sed | awk)
Shell(Bash)中的正则表达式,常和 grep、sed、awk 等文本处理工具搭配,用于匹配、查找、替换字符串,是处理日志、配置文件等文本的核心工具。Shell 正则分两种风格(基础正则BRE、扩展正则ERE),下面结合实战示例,讲清常用语法和用法。
一、先分清两种正则风格(避免踩语法坑)
Shell 中不同工具支持的正则风格不同,核心区别是特殊字符是否需要转义,用表格快速区分:
| 正则风格 | 支持工具 | 特点(核心差异) |
|---|---|---|
| 基础正则(BRE) | grep、sed(默认) |
? + () ` |
| 扩展正则(ERE) | grep -E、sed -E、awk |
上述特殊字符无需转义,写法更简洁 |
后续示例会标注对应风格,优先用扩展正则(写法简单,日常更常用)。
二、Shell 正则核心语法(常用+实战)
以下是日常高频的正则元字符,结合 grep -E(扩展正则)示例说明,测试文本用 test.txt,内容如下:
1. 张三 13812345678 25岁
2. 李四 13987654321 30岁
3. 王五 17766668888 28岁
4. 赵六 123456 未成年
5. abc123def 测试字符串
6. Hello World
7. 邮箱:test@163.com,备用邮箱:demo_123@gmail.com
1. 基础匹配(字符、数字、位置)
| 元字符 | 作用 | 示例 | 匹配结果 |
|---|---|---|---|
[a-z]/[A-Z] |
匹配小写/大写字母 | grep -E '[A-Z]' test.txt |
匹配第6行的 Hello World(H、W 是大写) |
[0-9] 或 \d |
匹配数字(\d 部分工具支持,如 grep -P) |
grep -E '[0-9]{11}' test.txt |
匹配11位手机号(第1-3行) |
^ |
匹配行首 | grep -E '^3' test.txt |
匹配以3开头的第3行 |
$ |
匹配行尾 | grep -E '岁$' test.txt |
匹配以“岁”结尾的第1-3行 |
. |
匹配任意单个字符(除换行) | grep -E 'a.c' test.txt |
匹配第5行的 abc(. 匹配 b) |
* |
匹配前一个字符0次或多次 | grep -E 'ab*c' test.txt |
匹配 ac、abc、abbc 等,此处匹配第5行 abc |
2. 数量限定(精准控制匹配次数)
| 元字符 | 作用 | 示例 | 匹配结果 |
|---|---|---|---|
? |
匹配前一个字符0次或1次 | grep -E '13[89]?' test.txt |
匹配13、138、139,此处匹配第1-2行的138、139 |
+ |
匹配前一个字符1次或多次 | grep -E '[0-9]+' test.txt |
匹配所有包含数字的行(第1-7行) |
{n} |
匹配前一个字符恰好n次 | grep -E '[0-9]{6}' test.txt |
匹配6位数字(第4行的123456、手机号中的连续6位) |
{n,} |
匹配前一个字符至少n次 | grep -E '[0-9]{8,}' test.txt |
匹配8位及以上数字(第1-3行的11位手机号) |
{n,m} |
匹配前一个字符n到m次 | grep -E '[0-9]{2,3}' test.txt |
匹配2-3位数字(年龄25、30等) |
3. 逻辑与分组(复杂匹配)
| 元字符 | 作用 | 示例 | 匹配结果 |
|---|---|---|---|
| ` | ` | 逻辑或,匹配任意一个 | `grep -E '138 |
() |
分组,将多个字符视为整体 | grep -E '(abc)+' test.txt |
匹配连续的abc,此处匹配第5行的abc |
[] |
匹配括号内任意一个字符 | grep -E '[张李王]' test.txt |
匹配张、李、王任意一字(第1-3行) |
[^] |
反向匹配,排除括号内字符 | grep -E '[^0-9]' test.txt |
匹配非数字的字符(几乎所有行,仅纯数字行不匹配) |
4. 特殊场景匹配(邮箱、手机号等)
结合上述语法,可实现常见场景的精准匹配:
# 1. 匹配邮箱(基础格式:用户名@域名.后缀)
grep -E '[a-zA-Z0-9_]+@[a-zA-Z0-9]+\.[a-zA-Z]{2,4}' test.txt
# 匹配结果:test@163.com、demo_123@gmail.com
# 2. 匹配11位手机号(13/17开头)
grep -E '1[37][0-9]{9}' test.txt
# 匹配结果:13812345678、13987654321、17766668888
# 3. 匹配以字母开头的字符串
grep -E '^[a-zA-Z]' test.txt
# 匹配结果:第5行的abc123def、第6行的Hello World
三、正则在常用工具中的应用
正则很少单独使用,大多搭配文本工具,以下是3个核心工具的实战用法:
1. grep:查找匹配内容
# 扩展正则匹配手机号,只显示匹配内容(-o)
grep -Eo '1[37][0-9]{9}' test.txt
# 反向匹配(-v),排除含数字的行
grep -Ev '[0-9]' test.txt
2. sed:替换匹配内容
# 用扩展正则(-E)替换所有手机号为“****”
sed -E 's/1[37][0-9]{9}/****/g' test.txt
# 替换邮箱后缀为“xxx.com”
sed -E 's/[a-zA-Z]+\.[a-zA-Z]{2,4}/xxx.com/g' test.txt
3. awk:按匹配处理文本
# 匹配含11位手机号的行,输出姓名和年龄
awk -F '[ 0-9岁]+' '/1[37][0-9]{9}/{print "姓名:"$2", 年龄:"$3}' test.txt
四、新手必避的3个坑
- 风格混淆:
grep不加-E时,+?等需转义(如grep '13[89]\?' test.txt),否则不生效; - 位置符误用:
^和$要注意行首行尾的空格,比如grep -E '岁$' test.txt不会匹配行尾带空格的“岁 ”; - 特殊字符转义:
.*等在正则中有特殊含义,若要匹配字面意思,需加\(如匹配.com需写\.com)。
4)文本处理工具
Shell 中的文本处理工具是运维、开发的核心利器,核心常用工具为 grep(查找)、sed(替换/编辑)、awk(分析/格式化),再配合 cut(截取)、sort(排序)、uniq(去重)、wc(统计)等辅助工具,可覆盖 99% 的文本处理场景(日志分析、配置提取、数据格式化等)。
下面按「工具定位+核心用法+实战示例」拆解,所有示例基于统一测试文本 data.txt(模拟日志/数据格式):
张三 13812345678 25 北京 85
李四 13987654321 30 上海 92
王五 17766668888 28 广州 78
赵六 15599990000 22 深圳 60
孙七 13888889999 35 北京 88
周八 13977776666 29 上海 95
吴九 17755554444 26 北京 72
郑十 15588887777 24 深圳 65
一、核心三剑客(必掌握)
1. grep:文本查找(“过滤器”)
核心定位:按正则/字符串匹配行,只保留符合条件的行,不修改原文本。
常用选项
| 选项 | 作用 |
|---|---|
-E |
支持扩展正则(无需转义 ? + ` |
-P |
支持 Perl 正则(\d \w 环视等高级特性) |
-o |
只输出匹配的部分(而非整行) |
-v |
反向匹配(保留不匹配的行) |
-n |
显示匹配行的行号 |
-i |
忽略大小写 |
实战示例
# 1. 查找“北京”相关的行(字符串匹配)
grep "北京" data.txt
# 2. 查找 90 分以上的行(扩展正则,数字 >=90)
grep -E ' [9][0-9]$' data.txt
# 3. 查找 138/139 开头的手机号(Perl 正则,\d 匹配数字)
grep -Po '13[89]\d{8}' data.txt # 只输出手机号
# 4. 反向匹配:排除“深圳”的行
grep -v "深圳" data.txt
# 5. 显示行号:查找 25-30 岁的行
grep -nE ' 2[5-9] | 30 ' data.txt
2. sed:文本编辑(“流编辑器”)
核心定位:按行/正则批量修改文本(替换、删除、插入、追加),默认输出到终端,不修改原文件(需加 -i 原地修改)。
常用语法(核心是 s/源/目标/选项)
| 语法 | 作用 |
|---|---|
sed 's/old/new/' |
替换每行第一个匹配的 old 为 new |
sed 's/old/new/g' |
全局替换(每行所有匹配的 old) |
sed 's/old/new/2' |
替换每行第 2 个匹配的 old |
sed '/pattern/d' |
删除匹配 pattern 的行 |
sed '3a 内容' |
在第 3 行后追加内容 |
sed '3i 内容' |
在第 3 行前插入内容 |
sed -i |
原地修改原文件(慎用,建议先备份) |
实战示例
# 1. 全局替换:将“北京”改为“北京市”
sed 's/北京/北京市/g' data.txt
# 2. 按正则替换:手机号中间 4 位改为 ****
sed -E 's/(1[357])\d{4}(\d{4})/\1****\2/' data.txt
# 3. 删除行:删除分数 <70 的行(以 6 开头的分数)
sed '/ 6[0-9]$/d' data.txt
# 4. 插入内容:在第 1 行前插入标题
sed '1i 姓名 手机号 年龄 城市 分数' data.txt
# 5. 原地修改:将“上海”改为“上海市”(修改原文件,先备份)
cp data.txt data.txt.bak # 备份
sed -i 's/上海/上海市/g' data.txt
3. awk:文本分析(“数据处理引擎”)
awk 是 Linux/Unix 系统中功能强大的文本处理工具,核心用于按行处理文本、提取数据、格式化输出,支持模式匹配、条件判断、循环计算等复杂逻辑,被誉为“文本处理瑞士军刀”。
一、awk 基础语法
1. 核心结构
awk 的基本语法由 模式(Pattern) 和 动作(Action) 组成,格式如下:
awk [option] '/Pattern/ { Action }' 文件名/输入流
options:是一些选项,用于控制awk的行为。- Pattern:筛选条件(可选),只有满足条件的行才执行 Action(如行号、正则匹配);
- Action:对匹配行的操作(用
{}包裹,可选),如打印字段、计算、赋值等; - 若省略 Pattern:对所有行执行 Action;
- 若省略 Action:默认打印(
print)满足 Pattern 的行。
options 参数说明:
-F <分隔符>或--field-separator=<分隔符>: 指定输入字段的分隔符,默认是空格。使用这个选项可以指定不同于默认分隔符的字段分隔符。-v <变量名>=<值>: 设置awk内部的变量值。可以使用该选项将外部值传递给awk脚本中的变量。-f <脚本文件>: 指定一个包含awk脚本的文件。这样可以在文件中编写较大的awk脚本,然后通过-f选项将其加载。
2. 关键概念:字段与分隔符
awk 自动将每行文本拆分为多个 字段(列),默认分隔符是任意空白字符(空格、制表符):
$0:代表整行文本;$1、$2、$n:分别代表第 1 列、第 2 列、第 n 列(字段从 1 开始计数);NF:内置变量,当前行的字段总数(Number of Fields);NR:内置变量,当前行的行号(Number of Records);FS:字段分隔符(Field Separator),可自定义(如逗号、冒号)。
| 变量 | 含义 |
|---|---|
$0 |
整行文本 |
$n |
第 n 个字段(列) |
NR |
全局行号(所有文件累计) |
FNR |
当前文件的行号 |
NF |
当前行的字段总数 |
FS |
字段分隔符(默认空白) |
OFS |
输出字段分隔符(默认空格) |
FILENAME |
当前处理的文件名 |
RS |
记录分隔符(默认换行) |
二、常用场景与示例
示例1
测试文本 data.txt
张三 13812345678 25 北京 85
李四 13987654321 30 上海 92
王五 17766668888 28 广州 78
赵六 15599990000 22 深圳 60
孙七 13888889999 35 北京 88
周八 13977776666 29 上海 95
吴九 17755554444 26 北京 72
郑十 15588887777 24 深圳 65
# 1. 按列输出:只显示姓名和分数($1 和 $5)
awk '{print "姓名:"$1", 分数:"$5}' data.txt
# 2. 条件过滤:显示分数 >=80 的行($5 >=80)
awk '$5 >=80 {print $1" "$3"岁 "$5"分"}' data.txt
# 3. 列分隔符:若文本是逗号分隔(如 data.csv),按逗号分割
awk -F ',' '$3 == "北京" {print $1}' data.csv
# 4. 数据统计:计算所有分数的总和
awk '{sum += $5} END {print "总分数:"sum}' data.txt
# 5. 行号过滤:显示第 3-5 行的姓名和城市
awk 'NR >=3 && NR <=5 {print $1" - "$4}' data.txt
# 6. 多条件:显示北京且分数 >=80 的行
awk '$4 == "北京" && $5 >=80 {print $0}' data.txt # $0 表示整行
示例2
以下示例基于测试文件 data.txt(内容如下):
Alice 28 Engineer 8000
Bob 32 Designer 9500
Charlie 25 Developer 7500
Diana 30 Manager 12000
1. 基础打印:提取字段/整行
(1)打印所有行(默认动作)
awk '{print $0}' data.txt # 等价于 awk '1' data.txt(1 代表条件为真)
输出:与原文件内容一致。
(2)提取指定字段(列)
打印姓名($1)和薪资($4),用逗号分隔:
awk '{print $1 ", " $4}' data.txt
输出:
Alice, 8000
Bob, 9500
Charlie, 7500
Diana, 12000
(3)打印行号 + 内容
awk '{print "Line" NR ":", $0}' data.txt
输出:
Line1: Alice 28 Engineer 8000
Line2: Bob 32 Designer 9500
...
2. 模式匹配:筛选目标行
(1)按行号筛选
- 打印第 2 行:
awk 'NR==2 {print $0}' data.txt - 打印第 1-3 行:
awk 'NR>=1 && NR<=3 {print $1}' data.txt - 打印奇数行:
awk 'NR%2==1 {print}' data.txt
(2)按内容正则匹配
- 打印包含 “Designer” 的行:
awk '/Designer/ {print $0}' data.txt - 打印姓名以 “A” 开头的行:
awk '$1 ~ /^A/ {print $1, $3}' data.txt(~表示匹配正则) - 打印薪资不包含 “8” 的行:
awk '$4 !~ /8/ {print}' data.txt(!~表示不匹配)
(3)按条件判断筛选
- 打印薪资 > 9000 的行($4 自动按数字处理):
awk '$4 > 9000 {print $1, "Salary:", $4}' data.txt - 打印年龄 >=28 且职业是 Engineer 的行:
awk '$2 >=28 && $3 == "Engineer" {print $0}' data.txt
3. 自定义分隔符
默认分隔符是空白字符,可通过 -F 参数或 FS 变量指定(如逗号、冒号、多字符分隔符)。
示例:处理 CSV 文件(users.csv)
id,name,age,city
1,Tom,22,Beijing
2,Lily,25,Shanghai
3,Jack,30,Guangzhou
- 按逗号分隔,提取姓名和城市:
awk -F ',' 'NR>1 {print $2, "lives in", $4}' users.csv # NR>1 跳过表头 - 按多字符分隔符(如
:;):
假设文件用:;分隔,如Alice:;28:;Engineer,则:awk -F ':;' '{print $1, $3}' file.txt
4. 数值计算与统计
awk 支持算术运算(+、-、*、/、%)和统计功能(求和、平均值、最大值等)。
示例:统计薪资相关数据
# 求和、平均值、最大值
awk '
BEGIN {sum=0; max=0} # 开始前初始化变量(BEGIN 模式:处理文本前执行)
{
sum += $4; # 累加薪资
if ($4 > max) max=$4; # 更新最大值
}
END { # 结束后执行(所有行处理完后)
print "Total Salary:", sum;
print "Average Salary:", sum/NR;
print "Max Salary:", max;
}
' data.txt
输出:
Total Salary: 37000
Average Salary: 9250
Max Salary: 12000
说明:BEGIN 与 END 模式
BEGIN {Action}:在读取文本前执行(仅一次),用于初始化变量、打印表头;END {Action}:在读取所有文本后执行(仅一次),用于统计结果、输出汇总。
5. 格式化输出(printf)
printf 比 print 更灵活,支持格式化字符串(如指定宽度、小数位数):
# 格式化打印姓名(占10字符)、年龄(占3字符)、薪资(保留1位小数)
awk '{printf "Name: %-10s Age: %3d Salary: %.1f\n", $1, $2, $4}' data.txt
输出:
Name: Alice Age: 28 Salary: 8000.0
Name: Bob Age: 32 Salary: 9500.0
...
%-10s:字符串左对齐,占 10 字符;%3d:整数占 3 字符(不足补空格);%.1f:浮点数保留 1 位小数。
6. 处理多文件/管道输入
awk 可同时处理多个文件,或接收管道(|)传递的输入。
(1)处理多个文件
# 处理 data.txt 和 users.csv,打印文件名、行号、内容
awk '{print FILENAME ": Line" NR ":", $0}' data.txt users.csv # FILENAME 是内置变量,当前文件名
(2)管道输入(结合其他命令)
- 统计
ls -l输出中文件的总大小(第 5 列是大小):ls -l | awk 'NR>1 {sum+=$5} END {print "Total Size:", sum, "bytes"}' - 过滤
df -h输出中使用率 > 50% 的分区:df -h | awk '$5 ~ /%/ && substr($5,1,length($5)-1) > 50 {print $1, $5}'
三、进阶技巧
1. 数组应用(去重、分组)
示例:文本去重(统计重复行出现次数)
# 统计 data.txt 中重复行的次数(假设存在重复)
awk '{count[$0]++} END {for (line in count) print line ":", count[line]}' data.txt
示例:按职业分组统计人数
awk '{job[$3]++} END {for (j in job) print j ":", job[j]}' data.txt
输出:
Engineer: 1
Designer: 1
Developer: 1
Manager: 1
2. 条件判断与循环
(1)if-else 条件
# 按薪资分级
awk '{
if ($4 >= 10000) grade="High";
else if ($4 >= 8000) grade="Medium";
else grade="Low";
print $1, "Grade:", grade;
}' data.txt
(2)for 循环
# 打印每行的所有字段(反向输出)
awk '{for (i=NF; i>=1; i--) printf $i " "; print ""}' data.txt
3. 调用外部命令(system 函数)
在 awk 中通过 system() 调用 Linux 命令:
# 对每行的姓名执行 echo 命令(示例)
awk '{system("echo Hello, " $1)}' data.txt
四、常见问题排查
- 字段分隔符错误:若分隔符是制表符(Tab),用
-F '\t'(注意单引号); - 数值与字符串混淆:awk 自动识别数值,但字段含非数字时会按字符串处理(如
$4是8000元则无法直接计算,需先用gsub(/元/, "", $4)去除非数字); - 空格问题:动作内的变量赋值、运算需注意空格(如
sum +=$4可写成sum+=$4,但sum = $4不能省略空格); - 多行脚本:复杂逻辑可将脚本写入文件(如
script.awk),用awk -f script.awk data.txt执行。
总结
awk 的核心优势是按行处理、字段提取、灵活计算,配合模式匹配和内置变量,可高效解决文本处理、数据统计、日志分析等场景。熟练掌握 $n、NR、NF、BEGIN/END、数组等核心特性,能大幅提升 Linux 文本处理效率。
二、辅助工具(搭配三剑客使用)
1. cut:按列截取文本
核心定位:快速截取指定列(按字符位置或分隔符),适合格式规整的文本。
cut [-c] [file]
cut [-df] [file]
常用选项
| 选项 | 作用 |
|---|---|
-d |
指定分隔符(如 -d "," 按逗号) |
-f |
指定列号(如 -f 1,3 截取第 1、3 列) |
-c |
按字符位置截取(如 -c 1-5 截取前 5 个字符) |
| --output-delimiter | 指定输出结果中字段之间的分隔符为单个空格 |
示例1
# 1. 截取姓名和年龄(第 1、3 列,默认空格分隔)
cut -f 1,3 data.txt
# 2. 按逗号分隔:截取 data.csv 的第 2 列
cut -d "," -f 2 data.csv
# 3. 按字符位置:截取前 10 个字符(姓名+手机号前几位)
cut -c 1-10 data.txt
示例2
准备数据 cat.txt, 注意:第五行得 le 和 le 之间有3个空格
dong shen
guan zhen
wo wo
lai lai
le le
# 截取每行前 5-10 个字符
[root@node01 scripts]# cut -c 5-10 cut.txt
shen
zhen
o
lai
le
# 1. 截取每行第 1 个字段(姓名前半,如 dong、guan、wo 等)
[root@node01 scripts]# cut -d " " -f 1 cut.txt
dong
guan
wo
lai
le
# 2. 截取每行第 2 个字段
[root@node01 scripts]# cut -d " " -f 2 cut.txt
shen
zhen
wo
lai
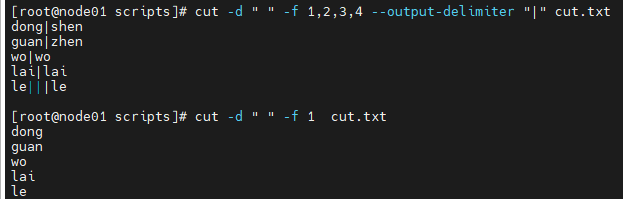
# 3. 加上输出, --output-delimiter "|" 的作用是指定输出结果中字段之间的分隔符为单个空格。
[root@node01 scripts]# cut -d " " -f 1,2,3,4 --output-delimiter "|" cut.txt
dong|shen
guan|zhen
wo|wo
lai|lai
le|||le #这里有3个"|"
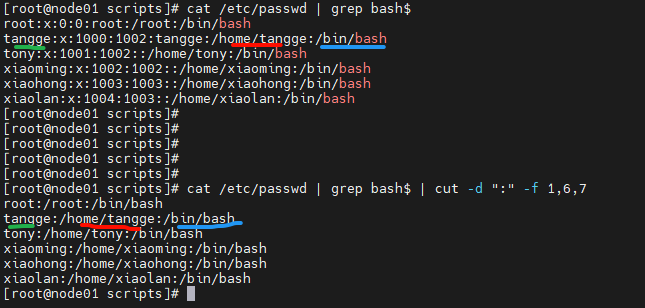
示例3
cat /etc/passwd | grep bash$ | cut -d ":" -f 1,6,7
2. sort:文本排序
核心定位:按字母、数字、列排序,配合 uniq 去重更实用。
常用选项
| 选项 | 作用 |
|---|---|
-n |
按数字排序(默认按字符排序) |
-r |
倒序排序 |
-k |
按第 k 列排序(如 -k 3 按第 3 列年龄排序) |
-t |
指定分隔符(配合 -k 使用) |
示例
# 1. 按年龄升序排序(第 3 列,数字排序)
sort -n -k 3 data.txt
# 2. 按分数倒序排序(第 5 列)
sort -n -r -k 5 data.txt
# 3. 按城市排序(第 4 列,字母排序)
sort -k 4 data.txt
3. uniq:去除重复行
核心定位:去除连续的重复行(需先排序,否则不生效),常和 sort 搭配。
常用选项
| 选项 | 作用 |
|---|---|
-c |
统计重复行的次数 |
-u |
只显示不重复的行 |
-d |
只显示重复的行 |
示例
# 1. 统计每个城市的人数(先按城市排序,再统计)
sort -k 4 data.txt | uniq -c
# 2. 只显示重复的城市(即出现多次的城市)
sort -k 4 data.txt | uniq -d
4. wc:文本统计
核心定位:统计行数、单词数、字符数。
常用选项
| 选项 | 作用 |
|---|---|
-l |
只统计行数 |
-w |
只统计单词数(按空格分隔) |
-c |
只统计字符数(含空格、换行) |
示例
# 1. 统计数据总行数
wc -l data.txt
# 2. 统计单词数(总字段数)
wc -w data.txt
# 3. 统计分数 >=80 的行数(先过滤再统计)
grep -E ' [89][0-9]$' data.txt | wc -l
三、工具组合使用(实战高频场景)
实际工作中,很少单独使用一个工具,通常组合使用完成复杂需求:
场景 1:分析日志,统计访问最多的前 3 个 IP
假设日志文件 access.log 中,IP 位于每行第 1 列:
# 步骤:提取 IP → 排序 → 去重统计 → 倒序 → 取前 3
cut -d " " -f 1 access.log | sort | uniq -c | sort -nr | head -3
场景 2:格式化输出数据(姓名+城市+分数,分数倒序)
# 步骤:按分数倒序 → 用 awk 格式化输出
sort -n -r -k 5 data.txt | awk '{printf "姓名:%-4s 城市:%-4s 分数:%d\n", $1, $4, $5}'
场景 3:提取 138 开头手机号,去重后保存到文件
# 步骤:提取手机号 → 排序去重 → 写入文件
grep -Po '138\d{8}' data.txt | sort | uniq > 138_phone.txt
场景 4:批量修改配置文件,替换端口号
假设 config.conf 中 port=8080 需改为 port=9090:
# 步骤:备份文件 → 原地替换
cp config.conf config.conf.bak
sed -i 's/port=8080/port=9090/g' config.conf
四、工具选择建议(快速选型)
| 需求场景 | 首选工具 | 辅助工具 |
|---|---|---|
| 查找匹配行/字符串 | grep | - |
| 批量替换/删除/插入文本 | sed | - |
| 按列处理/数据统计/格式化输出 | awk | cut |
| 排序/去重 | sort + uniq | - |
| 统计行数/单词数 | wc | grep(过滤后统计) |
| 按列截取(简单场景) | cut | awk(复杂场景) |
五、新手必避的坑
- sed -i 原地修改:修改前务必备份文件(如
cp file file.bak),避免误操作; - awk 列分隔符:默认按空格/制表符分隔,若文本有连续空格,无需额外处理(awk 自动合并);
- uniq 去重:必须先排序(
sort),否则无法去除非连续的重复行; - grep 正则转义:
-E支持扩展正则,-P支持 Perl 正则,避免转义混乱; - 中文处理:确保文本编码为 UTF-8,避免工具无法识别中文(如 grep 匹配中文需确保终端编码一致)。
总结
文本处理的核心是「三剑客+辅助工具」的组合:
- 查找用
grep,修改用sed,分析用awk; - 排序去重找
sort+uniq,统计找wc,简单截取找cut; - 复杂需求通过管道
|组合工具,效率翻倍。
多结合实际文本(日志、配置文件、数据表格)练习,很快就能熟练运用!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号