elastic search 原理介绍
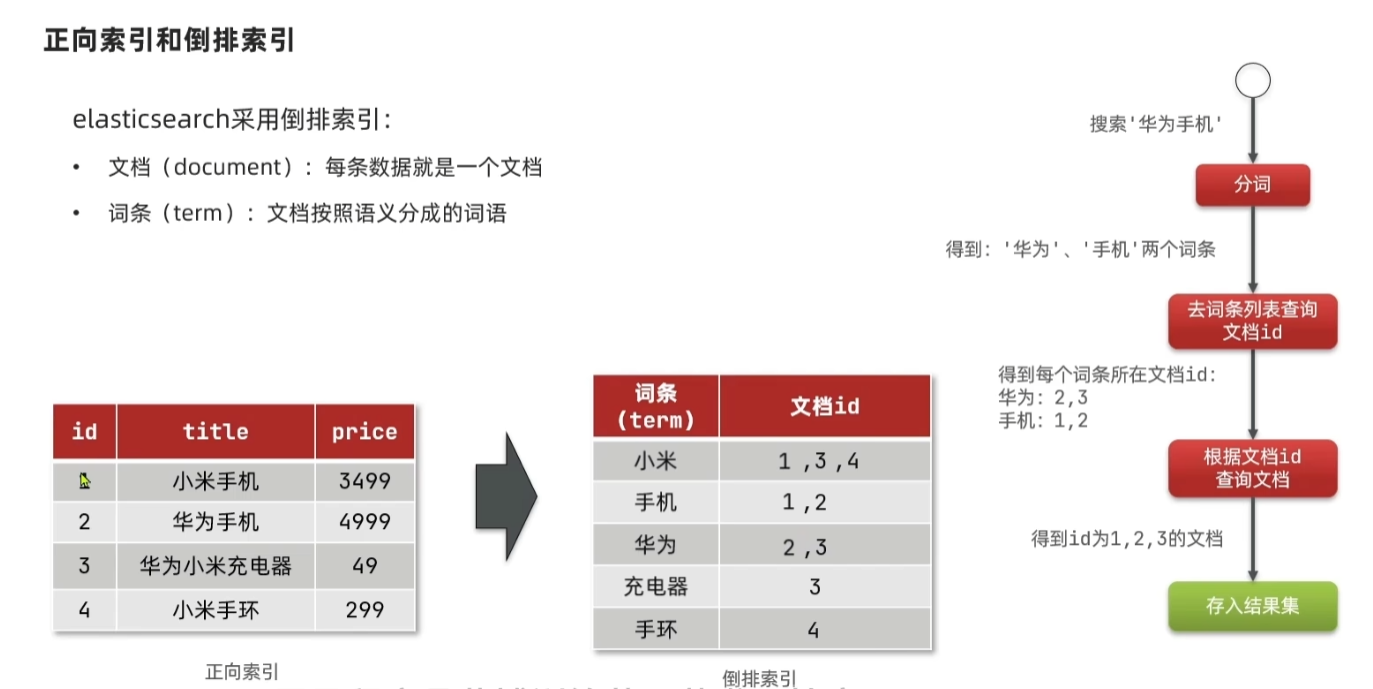
全文检索和倒排索引
全文检索
全文检索是指在全文数据中检索单个文档或文档集合的搜索技术,而Elasticsearch从这个意义上来说也可以理解为是一个全文数据库。
倒排索引
倒排索引先将文档中包含的关键字全部提取出来,然后再将关键字与文档的对应关系保存起来,最后再对关键字本身做索引排序。用户在检索某一关键字时,可以先对关键字的索引进行查找,再通过关键字与文档的对应关系找到所在文档。这类似于查字典一样,字典的拼音表和部首表就是关键字索引一,而拼音表和部首表中的内容就是关键字与文档的对应关系。
文档字段
1 字段索引

在默认情况下,文档的所有字段都会创建倒排索引。这可以通过字段的index参数来设置,其默认值为true,即字段会被编入索引。在编入索引时,一般不会将字段值整体编入。对于text类型的字段来说,它们会被解析为词项后再以词项为单位编入索引。
编入索引的信息包括文档ID、词项在字段中出现的频率、词项在字段中的次序、词项在字段中的起止偏移量等信息。
文档ID:是词项来源文档的编号,是文档的惟一标识,可用于存在性检索。文档ID由文档中的元字段id保存。
词频:词项在字段中出现的频率一般称为词频(Term Frequency),它可以反映检索结果的相关性,词项在文本中出现的频率越高与检索的相关性也就越高。
词序:词项在字段中的次序(以下简称词序)记录的是某一词项在所有词项中的次序,主要用于短语查询(PhraseQuery)。
偏移量:词项在字段中的起止偏移量(以下简称词项偏移量),给出了词项在字段中的实际位置,一般用于高亮检索结果。
默认情况下,只有text类型的字段会保存文档ID、词频、词序以外,其余类型字段均只保存文档ID。用户可以在映射字段时通过index_option参数来设置,它的可选值为 docs、freqs、positions、offsets,编入索引的信息依次增加,具体含义如下:
docs:只有文档ID会被编入索引;
freqs:文档ID、词频会被编入索引;
positions:文档ID、词频和词序会被编入索引;
offsets:文档ID、词频、词序和偏移量都会被编入索引。
由此也可以看出,尽管在默认情况下所有的字段都会被索引,但是这些字段的原始值是不会被编入索引中的。这意味着用户可以通过某一字段的词项检索到文档,但并不能直接取到这个字段的原始值。因为字段的索引最多只包含上述四项内容,并不包含字段原始值。
2 字段存储
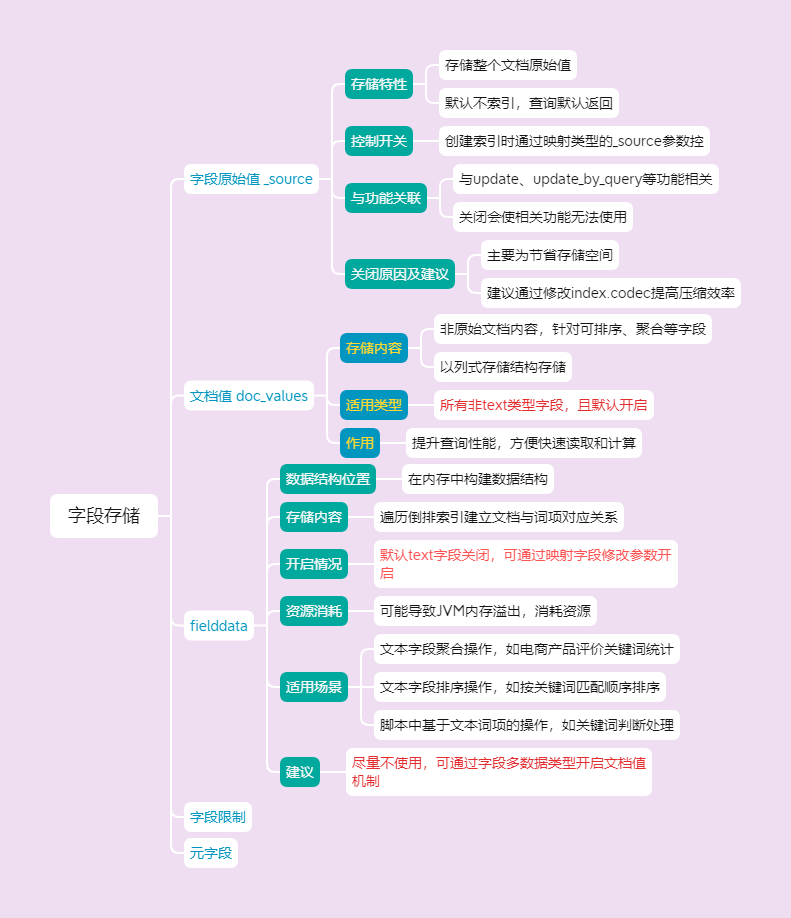
字段原始值 _source
索引提供了一个叫_source的字段用于存储整个文档的原始值。_source字段有一个特性,那就是这个字段在默认情况下是不会被索引的,但是每个查询默认都会带着_source字段返回。如果确定不需要使用_source字段保存源文档,也可以在创建索引通过映射类型的_source参数将其关闭
PUT /users
{
"mappings":{
_source":{
"enabled":false
}
}
}
这里mappings参数用于设置映射关系,_source则是控制_source字段的开关。不推荐关闭_source字段通常,因为_source字段与以下一些功能相关联:
-
使用update、update_by_query更新文档,使用reindex重新索引文档;
-
运行时高亮检索结果;
-
在不同的Elasticsearch实例间重新索引|文档;
-
使用源文档对检索和聚集做debug。
关闭_source字段后,上述功能也将无法使用,所以在考虑关闭_source字段时要权衡清楚。通常关闭_source字段的主要原因是出于节省存储空间,Elastic官方建议如果单纯只是考虑节省存储空间可以通过修改index.codec提高压缩效率.
文档值 doc_values
doc_values 存储的并非原始文档内容,而是针对文档中那些可以被用于排序、聚合、脚本操作等的字段(列),将其值以一种列式存储的结构进行存储,便于快速的数据读取和相应的计算操作。它实际上是 Elasticsearch 为了提升查询性能,对特定类型数据进行的一种优化存储方式。例如对于数值型字段(如文章的字数统计数值)、日期型字段(如发布时间)、布尔型字段等,会把这些字段的值按照 doc_values 的方式存储起来,方便后续快速查找和计算分析。
所有非
text类型的字段都支持文档值机制,并且都是开启的
fielddata
文档值doc_values机制的数据结构保存在硬盘中,而fielddata机制则是在内存中构建数据结构,所以使用fielddata机制有可能导致JVM内存溢出。不仅如此,fielddata机制保存的也不是字段原始值,而是通过遍历倒排索引建立文档与它所包含词项的对应关系。
具体来说,Elasticsearch会在首次对字段进行聚集、排序等请求时,遍历所有倒排索引并在内存中构建起文档与词项之间的对应关系。在默认情况下,text字段的fielddata机制是关闭的,可以通过在映射字段时修改fielddata参数开启。
在开启fielddata机制前要考虑清楚,因为这种机制显然非常消耗资源,而且使用text类型字段做聚集、排序也往往不是合理的需求。即便是真的有这样的需求,也可以通过字段多数据类型来开启文档值机制,而尽量不要使用fielddata机制。
- 文本字段聚合操作:对于文本类型的字段,若要进行诸如分组统计不同词汇出现的频次、按关键词进行分组等聚合分析时,就需要借助
fielddata。比如在一个电商产品索引中,对 “商品评价” 字段进行分析,统计用户提及最多的评价关键词,这时fielddata会帮助解析 “商品评价” 里的文本内容并用于聚合计算。- 文本字段排序操作:当要依据文本字段里的词项顺序等进行排序时,比如按照用户搜索关键词在文档中的匹配顺序来对搜索结果排序,
fielddata能提供相应的数据支持,让这种基于文本内容词项的排序得以实现。- 脚本中基于文本词项的操作:在自定义脚本里,如果需要对文本字段的词项进行逻辑判断、数值计算等操作(比如判断某个关键词是否在文档的文本字段中出现,出现次数达到一定数值就进行相应处理),
fielddata里存储的文本词项相关数据就可以被脚本访问和使用。
元字段

字段限制
index.mapping.total_fields.limit 参数定义了索引中最大字段数,它限制了字段、对象以及字段别名最大值,默认值是1000;
index.mapping.depth.limit 参数则定义了嵌套对象的最大深度,默认值是20;
index.mapping.nested_fields.limit 参数定义了索引l中嵌套字段的最大数量,默认值为50。这些限制出于安全角度出发,但在某些特定应用中可能会限制了需求,可以通过在创建索引修改这些参数满足需求。
3 字段数据类型

Elasticsearch支持的数据类型包括字符串、数值、日期、布尔、二进制、范围等核心数据类型,还支持数组、对象等衍生类型,也支持嵌套、关联、地理信息等特殊类型
1 字符串类型 text 和 keyword
字符串类型包括text和keyword两种类型,两者的区别在于text类型在存储前会做词项分析,而keyword类型则不会。所以text类型的字段可以通过analyzer参数设置该字段的分析器,而keyword类型字段则没有这个参数。
由于词项分析,text类型字段在编入索引后可通过词项做检索,但不能通过字段整体值做检索;而keyword类型字段则刚好相反,只能通过字段整体值来做检索而不能用词项做检索。所以text类型的字段一般用于存储全文数据,比如日志信息、文章正文、邮件内容等;而keyword类型则用于存储结构化的文本数据,如邮编、地址、电话等。
由于
text类型存储的是全文本数据,所以它编入索引的信息包括文档ID、词频、词序等信息,而keyword类型则只编入文档iD。
当然,
这可以通过index_option参数修改。在存储方面,keyword类型默认就支持通过文档值机制保存字段原始值,可通过doc_values参数关闭这个机制。text类型则不支持文档值机制,所以text类型不能参与文档排序、过滤、聚集等操作,除非打开它的fielddata机制。
2 数值类型

在这些类型中比较特殊的一类是scaled_float,它虽然是浮点数据类型,但在存储上却是使用long类型来表示。其基本思想是通过一个换算系数将浮点数放大为整型再保存,例如设置3.14的换算系数为100,则换算结果为3.14×100=314,最终保存的值就是314。
由于使用整型保存浮点数不仅不会损失精度还能提升运算效率,所以非常适合小数位数固定的数值,比如货币金额通常就只有两个小数位。设置scaled_float的换算系数时可使用scaling_factor,
PUT my_index
{
"mappings": {
"properties": {
"price": {
"type": "scaled_float",
"scaling_factor": 100
}
}
}
}
对于整型数据来说,应该在满足需求的前提下选择尽可能小的数据类型,这对于提升索引和搜索性能都有帮助。如果不清楚最终数值的范围,可以不显式设置它们的类型而由Elasticsearch自主判断,以防止实际数值范围溢出
3 日期类型
_
4 bool 类型
_
5 范围类型
范围类型要求字段的值描述的是一个数值、日期或IP地址的范围,
添加文档时可以使用gte、gt、lt、lte分别表示大于等于、大于、小于、小于等于。
数值范围类型包括integer_range、float_range、long_range、double_range,
日期范围类型和iP范围类型分别为date_range和ip_range。
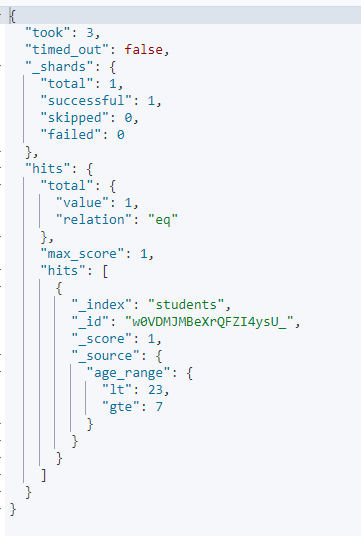
例如,在示例中先定义了age_range字段的类型为integer_range,然后又添加了一个age_range范围为[7,23)的文档。所以在检索age_range为10时就会返回添加的新文档。
PUT students
{
"mappings": {
"properties": {
"age_range": {
"type": "integer_range"
}
}
}
}
POST students/_doc
{
"age_range": {
"lt": 23,
"gte": 7
}
}
POST students/_search
{
"query": {
"term": {
"age_range": {
"value": 10
}
}
}
}
执行结果
分片与复制
分片
分片一般会均匀地分散到集群的不同节点上,这就将存储和检索负载分散到集群的不同节点上。索引分片数量是在创建索引l时通过number_of_shards参数设置的
number_of_shards: 10
副本
分片在解决了Elasticsearch文档存储容量问题的同时,也提升了文档处理的性能和吞吐量,但并不能解决容灾容错等高可用性问题。也就是说当集群中存储分片的节点发生故障,分片技术并不能保证文档存储、检索等服务依然可用,更不能保证分片中的数据不丢失。为了解决这个问题,Elasticsearch在存储上又引入了另一项称为副本(Replica)的技术。
副本是主分片的复制品,它与主分片的数据完全一致,能够在主分片故障时迅速恢复数据。所以主分片与副本分片永远不会在同一节点上,因为这样对于数据恢复没有任何意义。在默认情况下,Elasticsearch为每个索引都设置了1个副本分片,这意味着集群中应该至少有两个节点。如果集群中只有一个节点,副本分片就永远不会被创建,这时Elasticsearch就会将集群健康状态设置为黄色。索引的副本分片数量可以通过 number_of_replicas 参数设置,例如:
number_of_replicas: 2
索引与文档
别名
遇到以下场景:
场景1:面对PB级别的增量数据,对外提供服务的是基于日期切分的n个不同索引,每次检索都要指定数十个甚至数百个索引,非常麻烦。
场景2:线上提供服务的某个索引设计不合理,比如某字段分词定义不准确,那么如何保证对外提供服务不停止,也就是在不更改业务代码的前提下更换索引?
索引别名可以指向一个或多个索引,并且可以在任何需要索引名称的API中使用。别名提供了极大的灵活性,它允许用户执行以下操作:
在正在运行的集群上的一个索引和另一个索引之间进行透明切换。
对多个索引引进行分组组合。
在索引中的文档子集上创建“视图”,结合业务场景,缩小了检索范围,自然会提升检索效率。
多索引检索方案
多索引检索方案 - elasticsearch 基础知识 - 【唐】三三 - 博客园
ES Chrome 插件地址
Multi Elasticsearch Heads | Chrome扩展 - Crx搜搜
参考
Elastic Stack应用宝典

 浙公网安备 33010602011771号
浙公网安备 33010602011771号